O Google ouve melhor, a pesquisa é mais fácil
O Google anunciou que havia finalizado seu sistema de busca por voz, a fim de obter um melhor reconhecimento da fala do usuário em locais barulhentos. Sempre foi um dos melhores sistemas de reconhecimento de fala, especialmente conveniente ao pesquisar usando smartphones. Agora, a função de busca por voz tornou-se ainda mais desenvolvida do que nunca. O Blog de pesquisa do Google descreve as melhorias que foram feitas no sistema atualizado.Desde 2012, o gigante das buscas deixou de usar o Método Gaussian Mixes (MGS) há trinta anos no reconhecimento de fala. Os novos sistemas começaram a usar redes neurais profundas ( Deep Neural Networks ). O STS pode reconhecer melhor os sons que o usuário emite em um determinado momento, o que aumentou muito a precisão do reconhecimento.
Sempre foi um dos melhores sistemas de reconhecimento de fala, especialmente conveniente ao pesquisar usando smartphones. Agora, a função de busca por voz tornou-se ainda mais desenvolvida do que nunca. O Blog de pesquisa do Google descreve as melhorias que foram feitas no sistema atualizado.Desde 2012, o gigante das buscas deixou de usar o Método Gaussian Mixes (MGS) há trinta anos no reconhecimento de fala. Os novos sistemas começaram a usar redes neurais profundas ( Deep Neural Networks ). O STS pode reconhecer melhor os sons que o usuário emite em um determinado momento, o que aumentou muito a precisão do reconhecimento.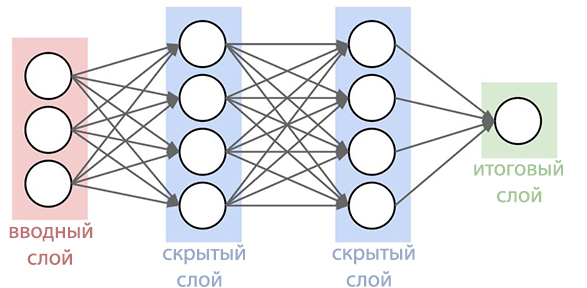 Agora, os especialistas do Google anunciaram que conseguiram criar uma rede neural mais avançada de modelos acústicos que usam classificação temporal conexionista e algoritmos discriminatórios de aprendizado . Esses modelos representam uma extensão especial de redes neurais periódicas que são mais precisas, especialmente em ambientes ruidosos e incrivelmente rápidas!No reconhecimento de fala tradicional, o formulário de voz preenchido pelo usuário era dividido em quadros (segmentos) consecutivos de 10 milissegundos. Cada quadro passou por uma análise de frequência e o vetor resultante com as características foi passado por modelos acústicos, como o GNS, que fornecem probabilidades para todas as correspondências sonoras. O Hidden Markov Model (SMM) ajuda a desvendar detalhes desconhecidos com base nos já obtidos, o que possibilita introduzir um tipo de estruturação dessa sequência de distribuições de probabilidade. Esse modelo é ainda mais combinado com outras fontes de conhecimento, como o Modelo de Pronúncia, que vincula as seqüências de sons com determinadas palavras, o idioma selecionado e o Modelo de Idioma, que, por sua vez, expressa o quanto a palavra se refere ao idioma selecionado.O reconhecedor então reconcilia todas essas informações para determinar a sentença que o usuário faz. Se o usuário disser, por exemplo, a palavra "museu" (mju: 'zɪəm é uma forma fonética), pode ser difícil determinar quando o som "j" termina e o som "u" começa. No entanto, na verdade, o determinante não se importa quando essa transição ocorre. A única coisa que o incomoda são precisamente os sons que foram proferidos.O novo modelo acústico aprimorado é baseado em redes neurais periódicas (PNS). Na topologia do PNS, existem loops de feedback que permitem simular a dependência de tempo. Quando o usuário pronuncia / U / no exemplo anterior, o aparelho de articulação da pessoa se move suavemente de som / J / para som / M / antes de tudo. Tente pronunciar a palavra "museu", para as pessoas que são fluentes em inglês, não será difícil e a palavra será pronunciada facilmente em um único fôlego, o PNS consegue captar esse momento.
Agora, os especialistas do Google anunciaram que conseguiram criar uma rede neural mais avançada de modelos acústicos que usam classificação temporal conexionista e algoritmos discriminatórios de aprendizado . Esses modelos representam uma extensão especial de redes neurais periódicas que são mais precisas, especialmente em ambientes ruidosos e incrivelmente rápidas!No reconhecimento de fala tradicional, o formulário de voz preenchido pelo usuário era dividido em quadros (segmentos) consecutivos de 10 milissegundos. Cada quadro passou por uma análise de frequência e o vetor resultante com as características foi passado por modelos acústicos, como o GNS, que fornecem probabilidades para todas as correspondências sonoras. O Hidden Markov Model (SMM) ajuda a desvendar detalhes desconhecidos com base nos já obtidos, o que possibilita introduzir um tipo de estruturação dessa sequência de distribuições de probabilidade. Esse modelo é ainda mais combinado com outras fontes de conhecimento, como o Modelo de Pronúncia, que vincula as seqüências de sons com determinadas palavras, o idioma selecionado e o Modelo de Idioma, que, por sua vez, expressa o quanto a palavra se refere ao idioma selecionado.O reconhecedor então reconcilia todas essas informações para determinar a sentença que o usuário faz. Se o usuário disser, por exemplo, a palavra "museu" (mju: 'zɪəm é uma forma fonética), pode ser difícil determinar quando o som "j" termina e o som "u" começa. No entanto, na verdade, o determinante não se importa quando essa transição ocorre. A única coisa que o incomoda são precisamente os sons que foram proferidos.O novo modelo acústico aprimorado é baseado em redes neurais periódicas (PNS). Na topologia do PNS, existem loops de feedback que permitem simular a dependência de tempo. Quando o usuário pronuncia / U / no exemplo anterior, o aparelho de articulação da pessoa se move suavemente de som / J / para som / M / antes de tudo. Tente pronunciar a palavra "museu", para as pessoas que são fluentes em inglês, não será difícil e a palavra será pronunciada facilmente em um único fôlego, o PNS consegue captar esse momento.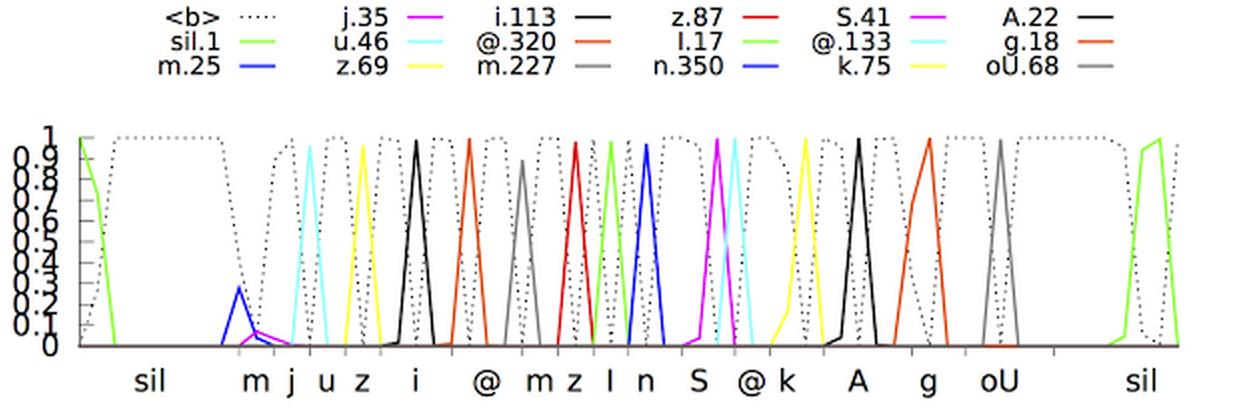 Um tipo de rede neural periódica nesse sistema é uma memória de longo prazo, que, com a ajuda de células de memória e um complexo mecanismo de bloqueio, lembra melhor as informações do que outros PNS. Gating é um método de alocar um determinado intervalo de tempo para aumentar a probabilidade de detectar sinais úteis contra um fundo de interferência. A adoção de tais modelos já melhorou significativamente a qualidade do reconhecimento de voz.O próximo passo foi ensinar o modelo acústico a reconhecer fonemas (sons) na fala entregue sem fazer uma previsão para cada quadro. Os modelos com a Classificação de tempo associativa preparam um gráfico com uma sequência de "picos" que exibem a sequência de sons no sinal recebido e podem fazer isso até que a sequência seja quebrada.De fato, o sistema de reconhecimento de voz do Google agora pode examinar o contexto em que a palavra foi dita, afastando-se dos sons de fundo.
Um tipo de rede neural periódica nesse sistema é uma memória de longo prazo, que, com a ajuda de células de memória e um complexo mecanismo de bloqueio, lembra melhor as informações do que outros PNS. Gating é um método de alocar um determinado intervalo de tempo para aumentar a probabilidade de detectar sinais úteis contra um fundo de interferência. A adoção de tais modelos já melhorou significativamente a qualidade do reconhecimento de voz.O próximo passo foi ensinar o modelo acústico a reconhecer fonemas (sons) na fala entregue sem fazer uma previsão para cada quadro. Os modelos com a Classificação de tempo associativa preparam um gráfico com uma sequência de "picos" que exibem a sequência de sons no sinal recebido e podem fazer isso até que a sequência seja quebrada.De fato, o sistema de reconhecimento de voz do Google agora pode examinar o contexto em que a palavra foi dita, afastando-se dos sons de fundo. Uma questão completamente diferente: como tornar tudo acessível e conveniente em tempo real? Após um grande número de iterações, os programadores do Google conseguiram criar modelos de fluxo único que processam sinais recebidos com blocos maiores que os blocos de modelos acústicos padrão, mas ao mesmo tempo fazem menos cálculos reais. Reduzir o número de operações computacionais acelera significativamente o processo de reconhecimento. Além disso, ruído artificial e reverberação (redução artificial de sons) foram adicionados ao programa de treinamento do sistema para tornar o sistema de reconhecimento mais resistente a ruídos estranhos. No vídeo abaixo, você pode assistir ao sistema aprender a frase.No entanto, mais um problema ainda não havia sido resolvido: o sistema produz menos previsões, mas, ao mesmo tempo, atrasa aproximadamente 300 milissegundos. Ao produzir o resultado após a conclusão completa da sentença, o nível de reconhecimento aumentou, mas, ao mesmo tempo, atrasos adicionais foram criados para os usuários, o que é completamente inaceitável para os especialistas do Goolge. Para resolver o problema, o sistema foi treinado para analisar e produzir o resultado para cada frase antes de ser concluída. Isso tornou o processo de reconhecimento mais sincronizado com a taxa normal de pronúncia de uma pessoa. O usuário não precisa mais esperar até que o programa exiba sua própria versão da frase falada.Novos modelos acústicos já são usados para pesquisa por voz e comandos no aplicativo Google(no Android e iOS) e para ditado em dispositivos Android. Novos modelos começaram a exigir menos recursos, tornaram-se mais resistentes ao ruído ambiente e foram capazes de produzir resultados muito mais rapidamente do que seus antecessores. Isso torna a pesquisa por voz mais agradável para o usuário.
Uma questão completamente diferente: como tornar tudo acessível e conveniente em tempo real? Após um grande número de iterações, os programadores do Google conseguiram criar modelos de fluxo único que processam sinais recebidos com blocos maiores que os blocos de modelos acústicos padrão, mas ao mesmo tempo fazem menos cálculos reais. Reduzir o número de operações computacionais acelera significativamente o processo de reconhecimento. Além disso, ruído artificial e reverberação (redução artificial de sons) foram adicionados ao programa de treinamento do sistema para tornar o sistema de reconhecimento mais resistente a ruídos estranhos. No vídeo abaixo, você pode assistir ao sistema aprender a frase.No entanto, mais um problema ainda não havia sido resolvido: o sistema produz menos previsões, mas, ao mesmo tempo, atrasa aproximadamente 300 milissegundos. Ao produzir o resultado após a conclusão completa da sentença, o nível de reconhecimento aumentou, mas, ao mesmo tempo, atrasos adicionais foram criados para os usuários, o que é completamente inaceitável para os especialistas do Goolge. Para resolver o problema, o sistema foi treinado para analisar e produzir o resultado para cada frase antes de ser concluída. Isso tornou o processo de reconhecimento mais sincronizado com a taxa normal de pronúncia de uma pessoa. O usuário não precisa mais esperar até que o programa exiba sua própria versão da frase falada.Novos modelos acústicos já são usados para pesquisa por voz e comandos no aplicativo Google(no Android e iOS) e para ditado em dispositivos Android. Novos modelos começaram a exigir menos recursos, tornaram-se mais resistentes ao ruído ambiente e foram capazes de produzir resultados muito mais rapidamente do que seus antecessores. Isso torna a pesquisa por voz mais agradável para o usuário. Source: https://habr.com/ru/post/pt384747/
All Articles