IoT e hackathon Azure Machine Learning: como fizemos o projeto fora da competição
 Não faz muito tempo, ocorreu outro hackathon da Microsoft. Desta vez, ele se dedicou ao aprendizado de máquina . O tópico é muito relevante e promissor, para mim, bastante vago. No início do hackathon, eu tinha apenas uma idéia geral do que era, por que era necessário e vi os resultados dos modelos treinados algumas vezes. Depois de saber que o anúncio prometeu a muitos especialistas ajudar os iniciantes, decidi combinar negócios com prazer e tentar usar o aprendizado de máquina ao trabalhar com algum tipo de solução de IoT . Em seguida, vou lhe contar o que aconteceu.I têm sido envolvidos em sistemas de segurança de perímetro, com base na análise de vibrações da cerca, de modo que uma vez que a ideia de trabalhar com acelerômetro. A idéia era simples: ensinar o sistema a distinguir entre a vibração de vários telefones, com base nos dados do acelerômetro. Experiências semelhantes já foram realizadas com sucesso por meus colegas, então eu não tinha dúvida de que isso era possível.Inicialmente, eu queria fazer tudo no Raspberry Pi 2 e no Windows IoT . Um quadro especial foi preparado (na foto abaixo) com acelerômetros digitais e analógicos, mas não consegui experimentá-lo na prática, tendo decidido fazer tudo em uma hackathon. Por precaução, também capturei nosso sensor , que também permite que você aprenda dados "brutos" sobre flutuações.
Não faz muito tempo, ocorreu outro hackathon da Microsoft. Desta vez, ele se dedicou ao aprendizado de máquina . O tópico é muito relevante e promissor, para mim, bastante vago. No início do hackathon, eu tinha apenas uma idéia geral do que era, por que era necessário e vi os resultados dos modelos treinados algumas vezes. Depois de saber que o anúncio prometeu a muitos especialistas ajudar os iniciantes, decidi combinar negócios com prazer e tentar usar o aprendizado de máquina ao trabalhar com algum tipo de solução de IoT . Em seguida, vou lhe contar o que aconteceu.I têm sido envolvidos em sistemas de segurança de perímetro, com base na análise de vibrações da cerca, de modo que uma vez que a ideia de trabalhar com acelerômetro. A idéia era simples: ensinar o sistema a distinguir entre a vibração de vários telefones, com base nos dados do acelerômetro. Experiências semelhantes já foram realizadas com sucesso por meus colegas, então eu não tinha dúvida de que isso era possível.Inicialmente, eu queria fazer tudo no Raspberry Pi 2 e no Windows IoT . Um quadro especial foi preparado (na foto abaixo) com acelerômetros digitais e analógicos, mas não consegui experimentá-lo na prática, tendo decidido fazer tudo em uma hackathon. Por precaução, também capturei nosso sensor , que também permite que você aprenda dados "brutos" sobre flutuações. No hackathon, todos os participantes foram solicitados a se dividir em equipes e resolver um dos três problemas usando dados pré-preparados. Minha tarefa acabou "fora da competição", mas a equipe se reuniu com rapidez suficiente:
No hackathon, todos os participantes foram solicitados a se dividir em equipes e resolver um dos três problemas usando dados pré-preparados. Minha tarefa acabou "fora da competição", mas a equipe se reuniu com rapidez suficiente: nenhum de nós tinha experiência com o aprendizado de máquina do Azure, portanto havia muito o que fazer! Obrigado aos colegas, entre os quais psfinaki , por seus esforços!Decidiu-se dividir em 3 direções:
nenhum de nós tinha experiência com o aprendizado de máquina do Azure, portanto havia muito o que fazer! Obrigado aos colegas, entre os quais psfinaki , por seus esforços!Decidiu-se dividir em 3 direções:- preparação de dados para análise
- fazer upload de dados para a nuvem
- trabalhar com o Azure Machine Learning
A preparação dos dados foi obtida no acelerômetro e depois apresentada em um formulário disponível para download na nuvem. O upload para a nuvem foi planejado através do Hub de Eventos . Bem, você precisava entender como usar esses dados no Azure Machine Learning.Os problemas começaram nos três pontos. Demorou muito tempo para configurar o Windows IoT no Raspberry. Ela não deu uma foto no monitor. Foi possível resolver isso apenas inserindo as seguintes linhas em config.txt:
Demorou muito tempo para configurar o Windows IoT no Raspberry. Ela não deu uma foto no monitor. Foi possível resolver isso apenas inserindo as seguintes linhas em config.txt:hdmi_ignore_edid=0xa5000080hdmi_drive=2hdmi_group=2hdmi_mode=16Isso ajustou o driver de vídeo no formato, resolução e frequência desejados. No entanto, o tempo gasto nesta lição deixou claro que talvez você não tenha tempo para organizar o recebimento de dados do acelerômetro. Portanto, foi decidido usar o sensor que eu tinha tomado em reserva.Muitas aplicações já foram escritas para o sensor. Um deles exibia na tela um gráfico de dados "brutos":
No entanto, o tempo gasto nesta lição deixou claro que talvez você não tenha tempo para organizar o recebimento de dados do acelerômetro. Portanto, foi decidido usar o sensor que eu tinha tomado em reserva.Muitas aplicações já foram escritas para o sensor. Um deles exibia na tela um gráfico de dados "brutos":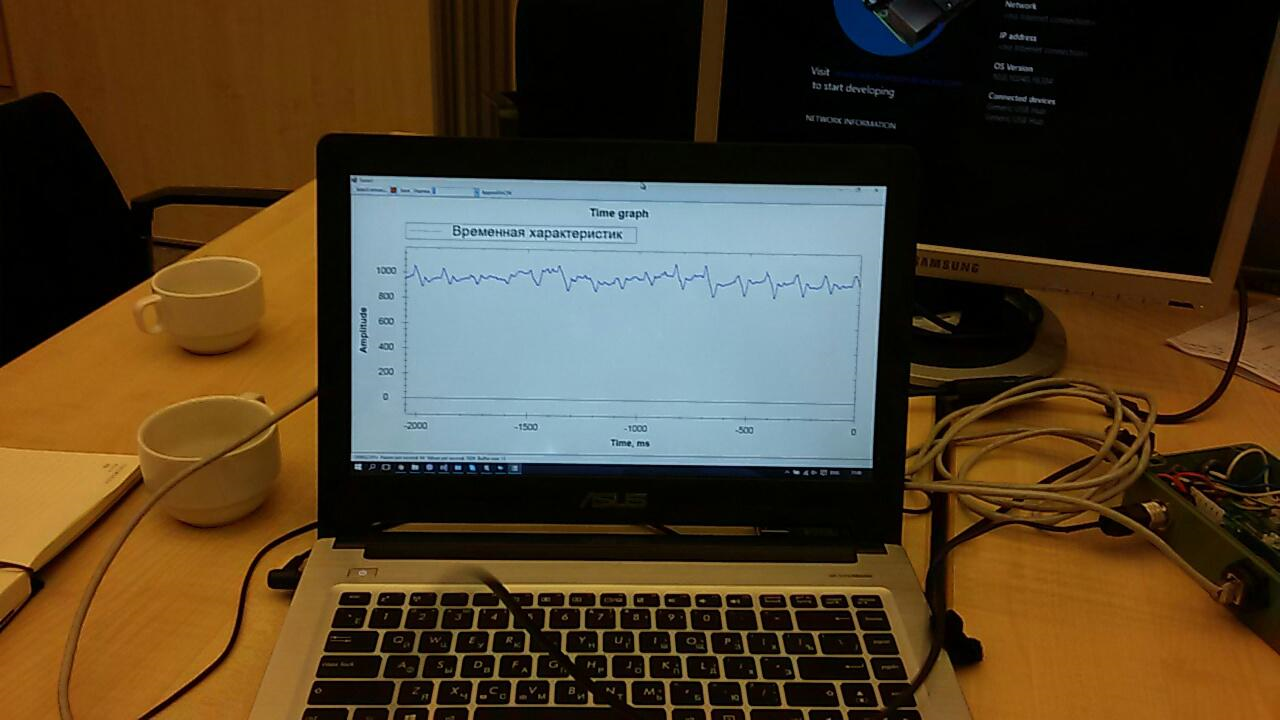 era necessário concluí-lo um pouco para preparar os dados para o envio para a nuvem.O Hub de Eventos também não funcionou imediatamente. Para começar, tentamos enviar para lá apenas uma sequência aleatória. Mas os dados não quiseram aparecer nos relatórios. Havia vários problemas e, como se viu, todos eram "infantis": em algum lugar eles configuraram errado, em algum lugar usaram a chave errada e assim por diante. O trabalho nessa direção foi difícil e consumiu muita energia:
era necessário concluí-lo um pouco para preparar os dados para o envio para a nuvem.O Hub de Eventos também não funcionou imediatamente. Para começar, tentamos enviar para lá apenas uma sequência aleatória. Mas os dados não quiseram aparecer nos relatórios. Havia vários problemas e, como se viu, todos eram "infantis": em algum lugar eles configuraram errado, em algum lugar usaram a chave errada e assim por diante. O trabalho nessa direção foi difícil e consumiu muita energia: mas, na noite do primeiro dia, conseguimos enviar e receber dados do sensor em tempo real ... É verdade que isso não foi necessário na solução final. Eu vou falar sobre os motivos um pouco mais tarde.Com o Machine Learning, nada ficou claro. No começo, estudamos juntos as belasartigo com um exemplo de uso de um aplicativo móvel como cliente. Depois descobrimos o formato dos dados e como trabalhar com eles. Então eles pensaram em criar sequências de treinamento.O Azure Mashine Learning possui muitos algoritmos para várias classificações. Esses algoritmos devem ser treinados em um conjunto de dados de teste. Em seguida, aqueles que oferecem o melhor resultado podem ser publicados como um serviço da Web e conectados a eles pelo aplicativo.Aprender um algoritmo é chamado de "experimento". Todas as ações são realizadas em um editor visual:
mas, na noite do primeiro dia, conseguimos enviar e receber dados do sensor em tempo real ... É verdade que isso não foi necessário na solução final. Eu vou falar sobre os motivos um pouco mais tarde.Com o Machine Learning, nada ficou claro. No começo, estudamos juntos as belasartigo com um exemplo de uso de um aplicativo móvel como cliente. Depois descobrimos o formato dos dados e como trabalhar com eles. Então eles pensaram em criar sequências de treinamento.O Azure Mashine Learning possui muitos algoritmos para várias classificações. Esses algoritmos devem ser treinados em um conjunto de dados de teste. Em seguida, aqueles que oferecem o melhor resultado podem ser publicados como um serviço da Web e conectados a eles pelo aplicativo.Aprender um algoritmo é chamado de "experimento". Todas as ações são realizadas em um editor visual: arrastar e soltar itens da lista à esquerda permite receber dados, modificá-los e transformá-los, treinar modelos e avaliar seu trabalho.É assim que um experimento típico se parece:
arrastar e soltar itens da lista à esquerda permite receber dados, modificá-los e transformá-los, treinar modelos e avaliar seu trabalho.É assim que um experimento típico se parece: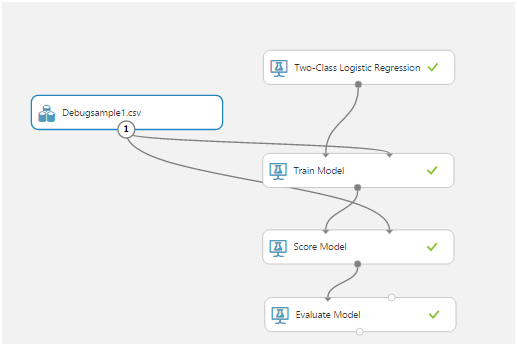 O Modelo de Trem, o Modelo de Pontuação e o Modelo de Avaliação acabaram sendo os mais importantes.O primeiro, usando os dados de entrada, treina o algoritmo, o segundo testa o algoritmo treinado no conjunto de dados, o terceiro avalia o resultado do teste.Os dados de origem no nosso caso são um arquivo csv. Mas o que deveria estar contido nela?O elemento sensível do nosso sensor é pesquisado 1024 vezes por segundo. Cada pesquisa é um valor de dois bytes correspondente à amplitude da oscilação atual. Além disso, a amplitude é medida não a partir de zero, mas a partir do número de referência correspondente a um sensor fixo.Após reflexão, decidimos usar fatias temporárias. Por exemplo, todas as pesquisas de sensor de 256 ms nos deram uma linha na tabela csv. Esses dados, em uma coluna adicional, podem ser marcados de uma maneira ou de outra, dependendo do que está acontecendo com o sensor. Por exemplo, usamos 0 para indicar ruído (sacudindo o sensor com as mãos, tocando, etc.) e 1 para indicar o sinal (há um telefone vibrando no sensor).Foi assim que registramos as seqüências de teste:
O Modelo de Trem, o Modelo de Pontuação e o Modelo de Avaliação acabaram sendo os mais importantes.O primeiro, usando os dados de entrada, treina o algoritmo, o segundo testa o algoritmo treinado no conjunto de dados, o terceiro avalia o resultado do teste.Os dados de origem no nosso caso são um arquivo csv. Mas o que deveria estar contido nela?O elemento sensível do nosso sensor é pesquisado 1024 vezes por segundo. Cada pesquisa é um valor de dois bytes correspondente à amplitude da oscilação atual. Além disso, a amplitude é medida não a partir de zero, mas a partir do número de referência correspondente a um sensor fixo.Após reflexão, decidimos usar fatias temporárias. Por exemplo, todas as pesquisas de sensor de 256 ms nos deram uma linha na tabela csv. Esses dados, em uma coluna adicional, podem ser marcados de uma maneira ou de outra, dependendo do que está acontecendo com o sensor. Por exemplo, usamos 0 para indicar ruído (sacudindo o sensor com as mãos, tocando, etc.) e 1 para indicar o sinal (há um telefone vibrando no sensor).Foi assim que registramos as seqüências de teste: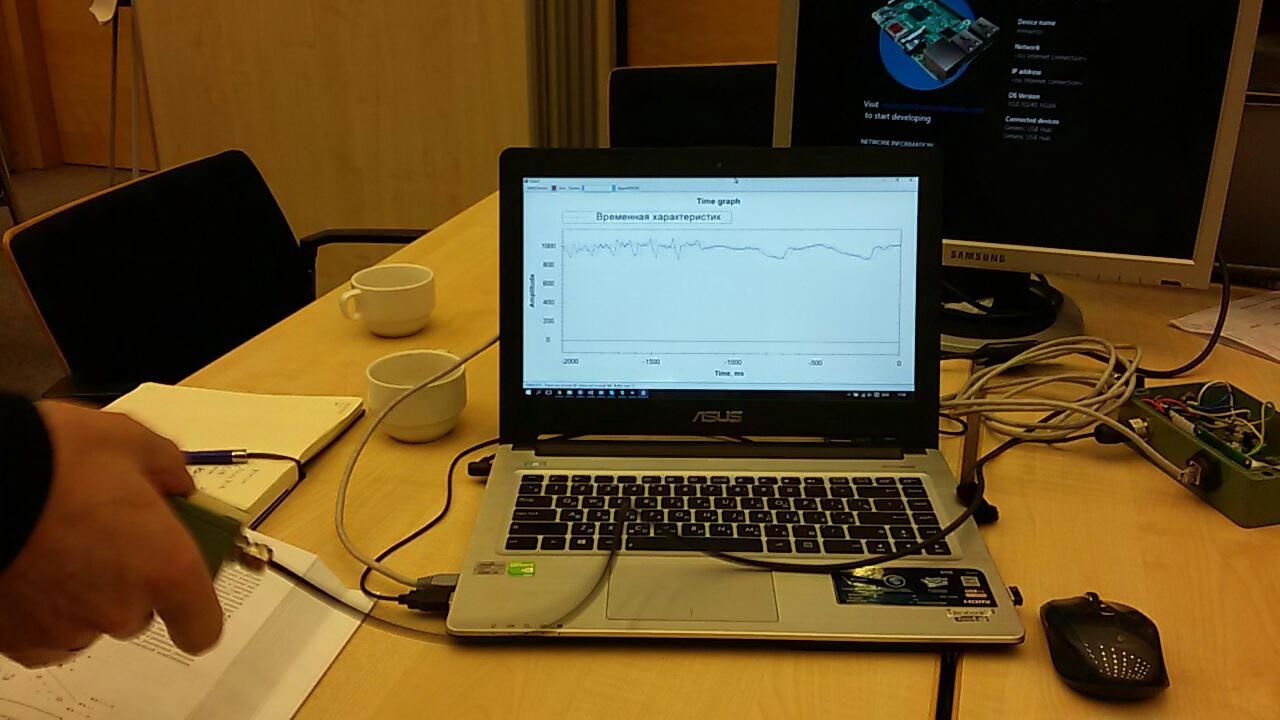 Após receber os dados e perceber o que precisa ser feito com eles, começamos a aprender o primeiro modelo:
Após receber os dados e perceber o que precisa ser feito com eles, começamos a aprender o primeiro modelo: A primeira panqueca acabou por ser irregular:
A primeira panqueca acabou por ser irregular: Naquele momento, nem o significado desses indicadores estava claro. Fomos salvos por um representante da equipe de suporte, Yevgeny Grigorenko, falando sobre as curvas do ROC. O principal foi que, se o gráfico estiver abaixo da linha média em algum lugar, o modelo funcionará ainda pior do que se desse um resultado aleatório! Eugene continuou a nos ajudar o máximo que pôde, pelos quais muito obrigado a ele!
Naquele momento, nem o significado desses indicadores estava claro. Fomos salvos por um representante da equipe de suporte, Yevgeny Grigorenko, falando sobre as curvas do ROC. O principal foi que, se o gráfico estiver abaixo da linha média em algum lugar, o modelo funcionará ainda pior do que se desse um resultado aleatório! Eugene continuou a nos ajudar o máximo que pôde, pelos quais muito obrigado a ele! Em seguida, reescrevemos a sequência de treinamento por um longo tempo e analisamos os resultados:
Em seguida, reescrevemos a sequência de treinamento por um longo tempo e analisamos os resultados: descobriu-se que trabalhar com uma gravação de 2 segundos (pesquisas com sensor de 2048) era menos ideal. Isso nos permitiu tornar as linhas da tabela CSV mais significativas. Mas o resultado ainda estava longe de ser bom.Isso terminou no primeiro dia.Passei a noite estudando o material. O artigo realmente ajudousobre classificação binária. Também li atentamente o artigo com dicas para este hackathon. Em geral, no início do trabalho, eu estava cheio de novas idéias.Passamos a primeira metade do segundo dia estudando diferentes modelos. O resultado do trabalho foi uma "folha":
descobriu-se que trabalhar com uma gravação de 2 segundos (pesquisas com sensor de 2048) era menos ideal. Isso nos permitiu tornar as linhas da tabela CSV mais significativas. Mas o resultado ainda estava longe de ser bom.Isso terminou no primeiro dia.Passei a noite estudando o material. O artigo realmente ajudousobre classificação binária. Também li atentamente o artigo com dicas para este hackathon. Em geral, no início do trabalho, eu estava cheio de novas idéias.Passamos a primeira metade do segundo dia estudando diferentes modelos. O resultado do trabalho foi uma "folha": nesse momento já estava claro que simplesmente não tínhamos tempo para distinguir entre dois anéis de vibração, pois a qualidade dos dados de treinamento deixava muito a desejar e não havia tempo suficiente para gravar novos. Portanto, focamos na separação de dados em "sinal" e "ruído".Para o trabalho, usamos três conjuntos de dados:
nesse momento já estava claro que simplesmente não tínhamos tempo para distinguir entre dois anéis de vibração, pois a qualidade dos dados de treinamento deixava muito a desejar e não havia tempo suficiente para gravar novos. Portanto, focamos na separação de dados em "sinal" e "ruído".Para o trabalho, usamos três conjuntos de dados:- Um conjunto de treinamento no qual houve um sinal (linhas do arquivo csv marcado como 1) e ruído (linhas marcadas como 0)
- Um conjunto que contém apenas ruído (linhas de 0)
- Um conjunto contendo apenas o sinal (linhas de 1)
Os modelos foram treinados primeiro, depois testados e avaliados em cada um dos conjuntos de dados. Os resultados foram animadores: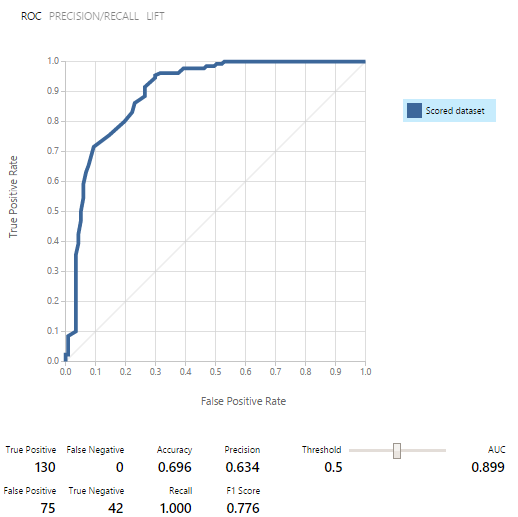 como resultado, dentre nove modelos de classificação binária, selecionamos cinco.Como se viu, usar o modelo como um serviço da Web é muito mais fácil do que parafusá-lo no hub de Eventos. Portanto, decidimos publicar todos os 5 modelos e trabalhar com eles por meio de REQUEST / RESPONSE, que é acompanhado por um exemplo muito bom.
como resultado, dentre nove modelos de classificação binária, selecionamos cinco.Como se viu, usar o modelo como um serviço da Web é muito mais fácil do que parafusá-lo no hub de Eventos. Portanto, decidimos publicar todos os 5 modelos e trabalhar com eles por meio de REQUEST / RESPONSE, que é acompanhado por um exemplo muito bom.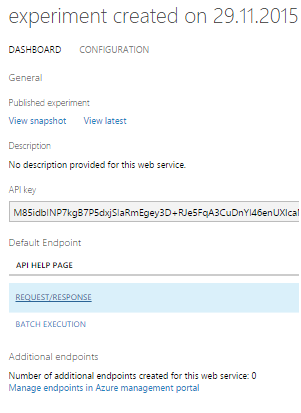 A solicitação é uma matriz de entrada de 2048 valores obtidos no sensor. A resposta é assim:
A solicitação é uma matriz de entrada de 2048 valores obtidos no sensor. A resposta é assim: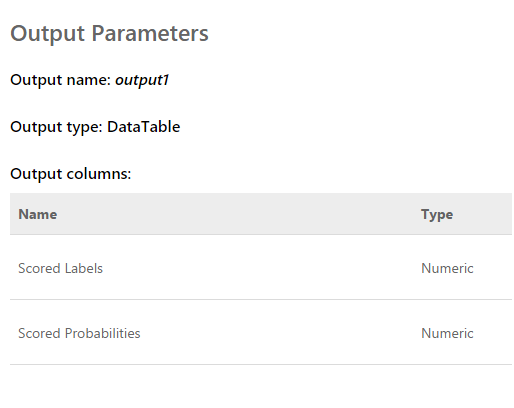 Os marcadores marcados são 0 ou 1. Ou seja, o resultado da classificação. Probabilidades pontuadas - um número decimal que reflete a correção da avaliação. Pelo que entendi, o primeiro valor é arredondar o segundo. Ou seja, quanto mais próximo o segundo valor de 0, maior a probabilidade de 0 e vice-versa. Quanto mais próximo o valor estiver de 1, maior será a pontuação 1.Tendo finalizado o programa que exibe o gráfico de “dados brutos” na tela, conseguimos receber simultaneamente dados de todos os cinco serviços da Web de vários fluxos. Além disso, depois de observar um pouco as estimativas, excluímos uma, pois ela dava um resultado completamente diferente dos outros e estragava todo o cenário.O resultado é o seguinte:
Os marcadores marcados são 0 ou 1. Ou seja, o resultado da classificação. Probabilidades pontuadas - um número decimal que reflete a correção da avaliação. Pelo que entendi, o primeiro valor é arredondar o segundo. Ou seja, quanto mais próximo o segundo valor de 0, maior a probabilidade de 0 e vice-versa. Quanto mais próximo o valor estiver de 1, maior será a pontuação 1.Tendo finalizado o programa que exibe o gráfico de “dados brutos” na tela, conseguimos receber simultaneamente dados de todos os cinco serviços da Web de vários fluxos. Além disso, depois de observar um pouco as estimativas, excluímos uma, pois ela dava um resultado completamente diferente dos outros e estragava todo o cenário.O resultado é o seguinte: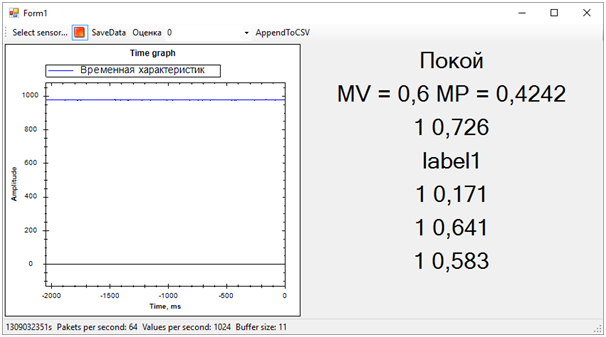
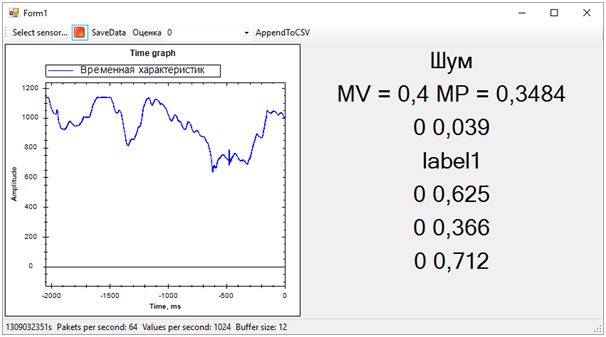
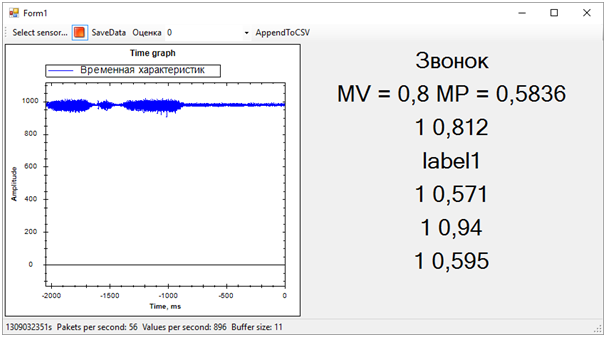 Então todos os problemas da sequência de treinamento saíram imediatamente. Embora tenhamos tentado separar o alerta de vibração de todo o resto (ruído e repouso), o estado de repouso acabou muito próximo da chamada, isso estava longe de ser sempre determinado. A diferença entre a chamada e o restante, foi determinada pelo número médio de probabilidades para cada modelo. Um valor mais próximo de 1 significa uma chamada, um valor de cerca de 0,5 com uma pontuação de 1 é paz. Bem, se a pontuação é 0 - isso é definitivamente barulho.Nesse momento, o hackathon chegou ao fim. Nem tivemos tempo de mostrar os resultados aos especialistas, pois eles estavam ocupados avaliando as entradas.Mas tudo isso não era mais de particular importância. Mais importante ainda, alcançamos um resultado completamente sadio e, ao mesmo tempo, aprendemos muito!Em dois dias de trabalho duro, concluímos, embora parcialmente, a tarefa. Obrigado aos colegas da equipe e aos especialistas que nos ajudaram!Agora podemos observar os caminhos de desenvolvimento do nosso projeto. Usamos características de tempo para separar eventos. No entanto, se passarmos para o domínio da frequência, a eficiência dos algoritmos deve ser maior. Ruído, paz e sino têm características espectrais visivelmente diferentes.Além disso, pessoas experientes sugeriram que os dados deveriam ser normalizados. Ou seja, os números da sequência de entrada devem estar no intervalo de -1 a +1. Os algoritmos funcionam com mais eficiência com esses dados.Bem e ainda, é necessário trabalhar na formação de sequências de treinamento para separar mais claramente o sinal do ruído.Essas melhorias devem aumentar significativamente a precisão da determinação do estado, que eu quero verificar no futuro.
Então todos os problemas da sequência de treinamento saíram imediatamente. Embora tenhamos tentado separar o alerta de vibração de todo o resto (ruído e repouso), o estado de repouso acabou muito próximo da chamada, isso estava longe de ser sempre determinado. A diferença entre a chamada e o restante, foi determinada pelo número médio de probabilidades para cada modelo. Um valor mais próximo de 1 significa uma chamada, um valor de cerca de 0,5 com uma pontuação de 1 é paz. Bem, se a pontuação é 0 - isso é definitivamente barulho.Nesse momento, o hackathon chegou ao fim. Nem tivemos tempo de mostrar os resultados aos especialistas, pois eles estavam ocupados avaliando as entradas.Mas tudo isso não era mais de particular importância. Mais importante ainda, alcançamos um resultado completamente sadio e, ao mesmo tempo, aprendemos muito!Em dois dias de trabalho duro, concluímos, embora parcialmente, a tarefa. Obrigado aos colegas da equipe e aos especialistas que nos ajudaram!Agora podemos observar os caminhos de desenvolvimento do nosso projeto. Usamos características de tempo para separar eventos. No entanto, se passarmos para o domínio da frequência, a eficiência dos algoritmos deve ser maior. Ruído, paz e sino têm características espectrais visivelmente diferentes.Além disso, pessoas experientes sugeriram que os dados deveriam ser normalizados. Ou seja, os números da sequência de entrada devem estar no intervalo de -1 a +1. Os algoritmos funcionam com mais eficiência com esses dados.Bem e ainda, é necessário trabalhar na formação de sequências de treinamento para separar mais claramente o sinal do ruído.Essas melhorias devem aumentar significativamente a precisão da determinação do estado, que eu quero verificar no futuro.Source: https://habr.com/ru/post/pt387857/
All Articles