Outro passo no auto-aprendizado de máquinas
 Obviamente, existem muitos modelos de autoaprendizagem na Ciência de Dados, mas eles são mesmo? Na verdade, não: agora no aprendizado de máquina há uma situação em que o fator humano desempenha um papel decisivo na construção de modelos eficazes.A ciência de dados agora é uma espécie de fusão de ciência e intuição, porque não há conhecimento formal de como prever corretamente os preditores, qual modelo escolher entre dezenas de existentes e como configurar muitos parâmetros nesse modelo. Tudo isso é difícil de formalizar e, portanto, surge uma situação paradoxal - o aprendizado de máquina requer um fator humano .É a pessoa que precisa construir a cadeia de aprendizado e ajustar os parâmetros que podem facilmente transformar o melhor modelo em absolutamente inútil. A construção dessa cadeia, que transforma os dados iniciais em um modelo preditivo, pode levar várias semanas, dependendo da complexidade da tarefa, e geralmente é feita simplesmente por tentativa e erro.Essa é uma falha séria e, portanto, surgiu a idéia: o aprendizado de máquina - pode se educar da mesma maneira que uma pessoa? Esse sistema foi criado, e é surpreendente que essas notícias ainda não tenham chegado à habrasociety!
Obviamente, existem muitos modelos de autoaprendizagem na Ciência de Dados, mas eles são mesmo? Na verdade, não: agora no aprendizado de máquina há uma situação em que o fator humano desempenha um papel decisivo na construção de modelos eficazes.A ciência de dados agora é uma espécie de fusão de ciência e intuição, porque não há conhecimento formal de como prever corretamente os preditores, qual modelo escolher entre dezenas de existentes e como configurar muitos parâmetros nesse modelo. Tudo isso é difícil de formalizar e, portanto, surge uma situação paradoxal - o aprendizado de máquina requer um fator humano .É a pessoa que precisa construir a cadeia de aprendizado e ajustar os parâmetros que podem facilmente transformar o melhor modelo em absolutamente inútil. A construção dessa cadeia, que transforma os dados iniciais em um modelo preditivo, pode levar várias semanas, dependendo da complexidade da tarefa, e geralmente é feita simplesmente por tentativa e erro.Essa é uma falha séria e, portanto, surgiu a idéia: o aprendizado de máquina - pode se educar da mesma maneira que uma pessoa? Esse sistema foi criado, e é surpreendente que essas notícias ainda não tenham chegado à habrasociety!TROT (Ferramenta de otimização de pipeline baseada em árvore)
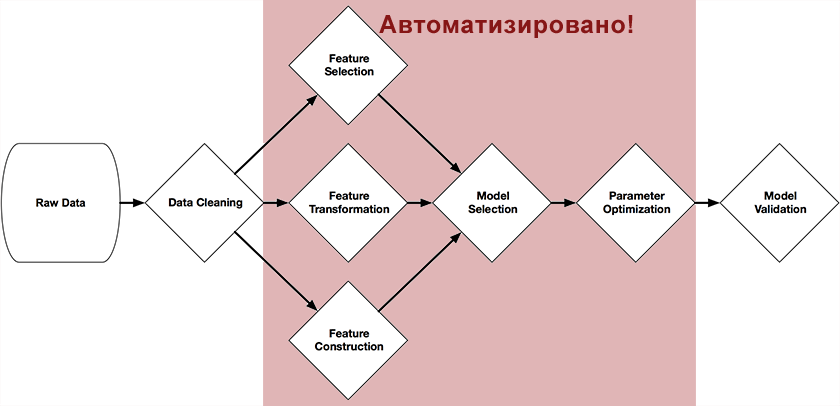
Randy Olson, um estudante de graduação do Laboratório de Genética Computacional (Universidade da Pensilvânia), desenvolveu uma Ferramenta de Otimização de Pipeline baseada em Árvore como parte de seu projeto de graduação .Este sistema está posicionado como um assistente de ciência de dados. Ele automatiza a parte mais tediosa do aprendizado de máquina, estudando e selecionando dentre as milhares de possíveis cadeias de construção, exatamente a mais adequada para o processamento de seus dados.O sistema foi escrito em Python usando a biblioteca scikit-learn e, através de algoritmos genéticos, constrói independentemente uma cadeia completa de preparação e construção de modelos. A figura no início deste artigo apresenta as partes da cadeia que podem ser automatizadas com sua ajuda: pré-processamento e seleção de preditores, seleção de modelos, otimização de seus parâmetros.A ideia é bastante simples - um algoritmo genético .Este é um algoritmo para encontrar a cadeia que precisamos por seleção aleatória, usando mecanismos semelhantes à seleção natural na natureza. Eles são escritos com detalhes suficientes sobre eles na Wikipedia , no Habr ou no livro "Sistemas de auto-aprendizagem"(Eu recomendo para os interessados neste tópico, existe uma rede em formato eletrônico).Em função da seleção (função Fitness), é usada a precisão da previsão na amostra de teste, como objeto da população são os métodos de scikit e seus parâmetros.Resultados
O autor apresenta um exemplo simples de como usar o TPOT para resolver o problema de referência para a classificação de dígitos manuscritos do conjunto MNISTfrom tpot import TPOT
from sklearn.datasets import load_digits
from sklearn.cross_validation import train_test_split
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target, train_size=0.75)
tpot = TPOT(generations=5, verbosity=2)
tpot.fit(X_train, y_train)
print( tpot.score(X_train, y_train, X_test, y_test) )
tpot.export('tpot_exported_pipeline.py')
Quando você executa o código, após alguns minutos, o TPOT pode obter a cadeia de construção de modelos, cuja precisão atinge 98%. Isso acontecerá quando o TPOT descobrir que o classificador Random Forest funciona perfeitamente em dados MNIST.No entanto, como esse processo é probabilístico, é recomendável definir o parâmetro random_state para resultados repetíveis - por exemplo, por 5 gerações, encontrei apenas uma cadeia com SVC e KNeighborsClassifier.Testar o sistema em outro problema clássico, a íris de Fisher , deu uma precisão de 97% em 10 gerações.O futuro
Trot é um projeto de código aberto que surgiu há um mês (que geralmente é a idade de uma criança para esses sistemas) e agora está se desenvolvendo ativamente. No site do projeto, o autor incentiva a comunidade de cientistas de dados a participar do desenvolvimento de um sistema cujo código está disponível no github (https://github.com/rhiever/tpot)Obviamente, agora o sistema está muito longe do ideal, mas a ideia desse sistema parece extremamente lógica - automação total todo o processo de aprendizado de máquina. E se a idéia se desenvolver, talvez em breve os sistemas apareçam onde uma pessoa só precisa baixar dados e obter um resultado. E então surge outra pergunta: é necessária uma pessoa para construir modelos de auto-aprendizado?