A lógica do spin-off 2: alguns algoritmos de encadeamento
Desafio:
separar as seqüências de eventos frequentemente repetidas em uma cadeia separada na qual não haverá nada supérfluo.Esta tarefa tem muitas soluções. Freqüentemente usado "cozimento" - os relacionamentos que são freqüentemente usados são fixos, enquanto outros são enfraquecidos. Na final, você deve ter uma cadeia na qual os eventos repetidos com mais frequência tenham fortes laços. Esta solução tem muitas deficiências, entre as quais - baixa velocidade. Mas temos ondas de identificação de Redozubov, podemos usar outros algoritmos que podem formar uma nova cadeia após a primeira repetição. Vamos começar com um simples.Na última notaUm método para registrar todos os eventos em uma cadeia de memória é descrito. Deixe o sistema ler uma vez a palavra "decadência" e, em outro momento - a palavra "cachoeira". Essas duas palavras têm a mesma parte - o final de três letras. De acordo com as condições do problema, é necessário destacar a "almofada" da corrente. Essa cadeia não possui pré-condições, ou seja, reconhece facilmente a entrada correspondente.Uma solução
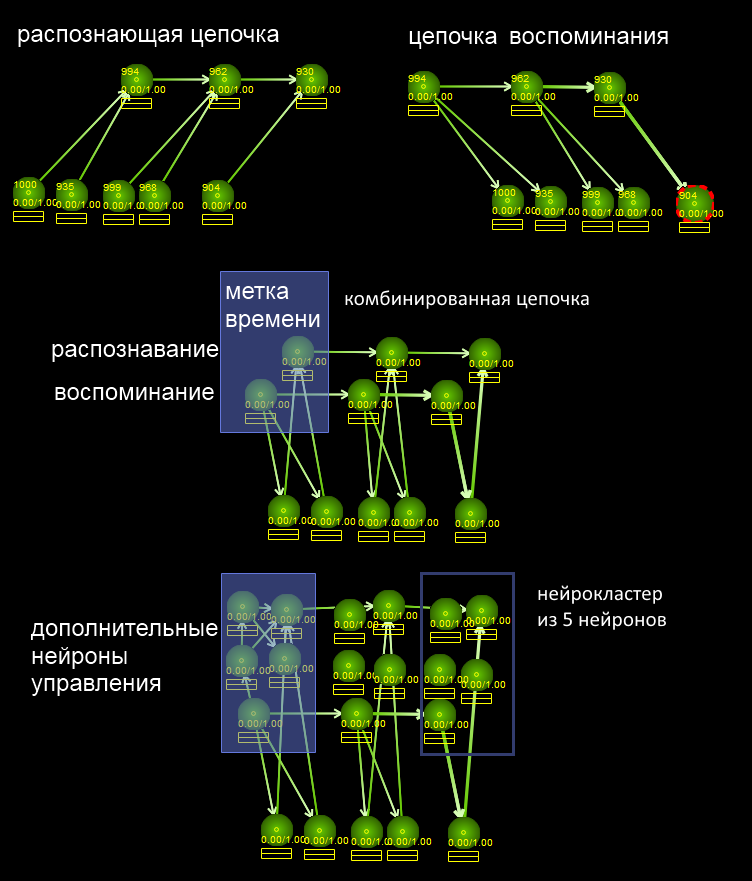 Dividimos a tarefa em duas:1) encontre duas séries semelhantes de eventos (você precisa entender que aproximadamente essas duas palavras contêm sequências semelhantes)2) selecione-as em uma cadeia separada (“pad”)Vamos começar com a parte 2. Complicamos o neurocluster com carimbos de data e hora, que armazenam todos os eventos na cadeia de memória, como mostra a figura. Graças à parte de reconhecimento (a direção das conexões dos atributos até o registro de data e hora generalizado), a subtarefa 1 será resolvida - para encontrar uma posição com atributos comuns e, graças à cadeia de memória com links desativados, a subtarefa 2 será resolvida. A solução para a subtarefa 2 é a seguinte: começaremos a chamar duas palavras ao mesmo tempo onde eles têm em comum. Ou seja, o sistema enviará ativação por neurônios que correspondem a essas letras. Se a letra for encontrada nas duas palavras, ela deverá ser lembrada. Para fazer isso, deixe a memória acontecer com metade da força. Se o limiar de ativação do neurônio for T, a cadeia de memória deverá enviar 0,5 T do potencial de ação. O limite de ativação será excedido somente sequando o sintoma se encontrou nas duas cadeias. Depois disso, o sintoma é ativado. Então você pode usar o algoritmo usual de memorização com o código do artigo anterior - o hipocampo criará uma cadeia de memória, atribuindo a ele os sinais comuns às duas cadeias. Reduzimos a solução para a anterior.No ENS (NS natural), a “meia ativação” pode ser alcançada variando o tempo de envio (o número de picos que chegaram), o número de neurotransmissores ou talvez usando conexões inibitórias (para transformar 1T em 0,5T).A subtarefa 1 é um pouco mais complicada, pois deve funcionar com reconhecimento difuso. Ou seja, mesmo se houver apenas alguns sinais comuns na cadeia que estão perdidos em algum lugar no meio da cadeia, você ainda deve perceber essa situação. Deixe-me lembrá-lo de que, relativamente falando, os neurônios podem estar em três modos - descanso, enviando um único sinal e modo de ativação de alta frequência. Pode-se aceitar que o "reconhecimento total" leva à transição do neurônio para o modo de ativação de alta frequência, e o reconhecimento difuso leva a uma única transmissão de sinal. Ou podemos assumir que haverá neurônios especializados no neurocluster, alguns dos quais funcionarão apenas com completa coincidência e reconhecimento confiante, e o outro neurônio funcionará se apenas parte dos recursos forem reconhecidos. Existem muitas soluções, o principal é perceber de alguma forma a aparência da ativação nos clusters desejados.
Dividimos a tarefa em duas:1) encontre duas séries semelhantes de eventos (você precisa entender que aproximadamente essas duas palavras contêm sequências semelhantes)2) selecione-as em uma cadeia separada (“pad”)Vamos começar com a parte 2. Complicamos o neurocluster com carimbos de data e hora, que armazenam todos os eventos na cadeia de memória, como mostra a figura. Graças à parte de reconhecimento (a direção das conexões dos atributos até o registro de data e hora generalizado), a subtarefa 1 será resolvida - para encontrar uma posição com atributos comuns e, graças à cadeia de memória com links desativados, a subtarefa 2 será resolvida. A solução para a subtarefa 2 é a seguinte: começaremos a chamar duas palavras ao mesmo tempo onde eles têm em comum. Ou seja, o sistema enviará ativação por neurônios que correspondem a essas letras. Se a letra for encontrada nas duas palavras, ela deverá ser lembrada. Para fazer isso, deixe a memória acontecer com metade da força. Se o limiar de ativação do neurônio for T, a cadeia de memória deverá enviar 0,5 T do potencial de ação. O limite de ativação será excedido somente sequando o sintoma se encontrou nas duas cadeias. Depois disso, o sintoma é ativado. Então você pode usar o algoritmo usual de memorização com o código do artigo anterior - o hipocampo criará uma cadeia de memória, atribuindo a ele os sinais comuns às duas cadeias. Reduzimos a solução para a anterior.No ENS (NS natural), a “meia ativação” pode ser alcançada variando o tempo de envio (o número de picos que chegaram), o número de neurotransmissores ou talvez usando conexões inibitórias (para transformar 1T em 0,5T).A subtarefa 1 é um pouco mais complicada, pois deve funcionar com reconhecimento difuso. Ou seja, mesmo se houver apenas alguns sinais comuns na cadeia que estão perdidos em algum lugar no meio da cadeia, você ainda deve perceber essa situação. Deixe-me lembrá-lo de que, relativamente falando, os neurônios podem estar em três modos - descanso, enviando um único sinal e modo de ativação de alta frequência. Pode-se aceitar que o "reconhecimento total" leva à transição do neurônio para o modo de ativação de alta frequência, e o reconhecimento difuso leva a uma única transmissão de sinal. Ou podemos assumir que haverá neurônios especializados no neurocluster, alguns dos quais funcionarão apenas com completa coincidência e reconhecimento confiante, e o outro neurônio funcionará se apenas parte dos recursos forem reconhecidos. Existem muitas soluções, o principal é perceber de alguma forma a aparência da ativação nos clusters desejados.Quando fazer
a questão é a que horas fazer essa pesquisa. Pode haver várias abordagens:1) um modo de suspensão especializado - mais precisamente, “suspensão lenta”. O sistema passa por todos os eventos que aprendeu em um dia e procura correspondências com suas outras memórias. Nesse caso, o sistema usa a memória - enviando em uma cadeia descendente e, em seguida, dá tempo para os neurônios dos sinais enviarem sinais que já estão "subindo" para outras memórias. Depois disso, ele resume e procura as memórias que têm a maior quantidade de ativação total. Em seguida, ele seleciona um desses locais e lança a subtarefa 2 - "selecione a cadeia".2) sem um regime de sono especializado. O sistema pode realizar uma pesquisa em tempo real, durante a percepção - e como é a situação atual? Na verdade, a busca ocorre automaticamente durante o pensamento normal, devido ao envio de sinais pelos neurônios, o sistema pode apenas prestar atenção às memórias que têm muito em comum com a situação atual e, se necessário, executar a análise - destaque a sub-cadeia geral.Algoritmos similares
Esses algoritmos parecem simples, mas contêm muitas sutilezas, ainda mais do que no algoritmo de classificação rápida, que, como você sabe, não pode ser escrito por muito tempo sem erros.Essa tarefa é semelhante às tarefas conhecidas, por exemplo, procurando subsequências de DNA comuns. Somente o DNA em cada etapa pode ter apenas um nucleotídeo e, na rede neural de cada registro de data e hora, pode haver um número arbitrário de caracteres. Portanto, essa tarefa é um caso mais geral em comparação com a pesquisa de DNA. Se você tentar transferir algoritmos existentes e resolver esse problema de "brecha", sem redes neurais, manipulando as listas de sinais, sua cabeça começará a girar - todas essas listas aninhadas de correspondências, listas de sequências de correspondências, outras perguntas. Resolver esse problema enviando ativações para neurônios é muito mais fácil - os neurônios já existem, eles fazem tudo automaticamente, a memória já é alocada a eles, nenhuma lista aninhada é necessária, resta apenas analisar alguns neurônios e executar os algoritmos necessários.Eu chamo as subtarefas 1 e 2 modos com uma e duas cadeias principais, respectivamente. Ou seja, "quantos neurônios descendentes ativos nas cadeias de memória enviam sinais na tentativa de destacar correspondências". Se houver apenas uma dessas cadeias recuperadas, ela estará procurando um segundo candidato para verificação. E se o candidato já foi encontrado, você pode ativá-lo e começar a destacar os sinais. Esses nomes - "1 ou 2 cadeias principais" - tornarão possível fazer referência a esses algoritmos por nome, em vez de "subtarefa 1 ou 2". O modo com uma cadeia principal também pode ser chamado de "modo de busca por coincidência" e as duas cadeias principais podem ser chamadas de modo de destaque por coincidência.Pesquisar correspondências ...
(1 × 2, 1 cadeia principal) pode ser realizada das seguintes maneiras:1) visualize linearmente todas as memórias que se encontraram durante o dia. A transição para este modo para fins de depuração pode ser feita da seguinte forma: um caractere Unicode especial ou uma palavra especial é inserida nos conjuntos de testes de dados de entrada para a RNA; após a leitura, a RNA muda para o modo "suspensão lenta" e começa a procurar correspondências. O significado é este: eles encheram a RNA com dados reais, lançaram algoritmos de depuração para encontrar generalizações.2) usar não uma pesquisa linear, mas iniciar a análise com as situações mais interessantes - com as que apresentavam a maior cor emocional. Essa otimização é necessária, pois esses algoritmos são muito vorazes. Em ratos, parece que a lembrança do que era dia ocorre apenas 10 vezes mais rápido do que durante o dia. O sono leva menos tempo que a vigília. Portanto, com uma distribuição uniforme do tempo em todas as memórias, cada memória pode ser gerenciada para comparar apenas algumas situações semelhantes, a maioria das quais serão lixo e coincidências insignificantes. Portanto, é benéfico concentrar-se no mais importante e começar a trabalhar com ele. Podemos dizer que o algoritmo adiciona mais uma etapa - 0 cadeias principais; nessa etapa, o sistema deve selecionar o próximo evento na memória com a máxima importância,e passe para a próxima etapa - faça dela a cadeia principal para encontrar correspondências.3) é possível fazer serifas a partir do momento da vigília - com antecedência para criar conexões com os lugares mais interessantes que precisam ser comparados à noite.Cadeias selecionadas com coincidências são lembradas, mas no futuro elas podem ser esquecidas se sua importância desaparecer com o tempo.Esquecendo
O esquecimento faz com que o neurocluster seja excluído - a operação removeNC, o inverso da operação newNC. No ENS, os neurônios não vão a lugar algum, eles não morrem, suas conexões simplesmente se enfraquecem a tal ponto que eles não reagem mais aos seus sinais e estarão prontos para se reajustar para se lembrar de outra combinação. Em nosso modelo, esses neurônios não precisam ser armazenados, podem ser removidos imediatamente - isso acelerará a operação da RNA, reduzirá o consumo de memória e simplificará a depuração. Isso permite que você talvez reduza os requisitos de consumo de memória em uma ordem de magnitude.Paralelização
Para fazer a transição do modo 1 para 2, primeiro tentei criar neurônios de controle que produzissem comutação de sinal, análise e mudança de modo. Mas achei esse trabalho de nível muito baixo e comecei a escrever códigos C ++ imperativos - códigos como “percorra todos os clusters, analise-os, selecione o que você precisa, pense em mudar o modo de operação”.A questão do desempenho de um sistema desse tipo: se você criar hardware para neurônios, poderá paralelizá-los (sim, pelo menos em placas de vídeo). Em seguida, o código com controle de neurônios e conexões dentro do cluster é paralelo fácil e automaticamente (este é apenas um pacote de ativação que é paralelo de acordo com as condições da tarefa), mas o código C ++ imperativo precisa ser paralelizado a cada vez independentemente. Portanto, para pequenas redes neurais de thread único, é mais fácil escrever código C ++ e para RNAs massivamente paralelas, é melhor transferir esse trabalho dentro da própria RNA para os ombros dos neurônios e as conexões entre eles. Não devemos esquecer que o "ciclo através de todos os neurônios" ou o "ciclo através de todos os neuroclusters" em C ++ do ponto de vista do hardware RNA é O (1), uma única etapa do envio da ativação. Portanto, pode ser visto1VTs e 2VTs (cadeias principais) para RNAs idealmente paralelizadas têm a mesma complexidade computacional.Continuação: previsão primitiva na RNASource: https://habr.com/ru/post/pt388725/
All Articles