AlphaGo tem uma chance no jogo contra Lee Sedol: opiniões e classificações de jogadores profissionais no
A 9ª partida go-pro do Google e a IA do Google ocorrerão em março
 Nenhum computador é capaz de vencer um jogador profissional no jogo de tabuleiro asiático. A questão é sobre os recursos do jogo: existem muitas posições e é difícil descrever a intuição humana por algoritmo. O mundo manteve opiniões semelhantes até 27 de janeiro. Alguns dias atrás, o Google publicou dados de pesquisa de sua divisão DeepMind . Ele fala sobre o sistema AlphaGo, que em outubro do ano passado conseguiu derrotar o segundo jogador profissional Dan Fan em cinco dos cinco jogos.No entanto, jogadores profissionais e conhecidos de go tinham dúvidas sobre a qualidade do jogo. Hui é tricampeão, mas é campeão europeu, onde o nível do jogo não é muito alto. Não é apenas a escolha do jogador demonstrar o poder do AlphaGo que levanta questões, mas também alguns movimentos nos jogos.
Nenhum computador é capaz de vencer um jogador profissional no jogo de tabuleiro asiático. A questão é sobre os recursos do jogo: existem muitas posições e é difícil descrever a intuição humana por algoritmo. O mundo manteve opiniões semelhantes até 27 de janeiro. Alguns dias atrás, o Google publicou dados de pesquisa de sua divisão DeepMind . Ele fala sobre o sistema AlphaGo, que em outubro do ano passado conseguiu derrotar o segundo jogador profissional Dan Fan em cinco dos cinco jogos.No entanto, jogadores profissionais e conhecidos de go tinham dúvidas sobre a qualidade do jogo. Hui é tricampeão, mas é campeão europeu, onde o nível do jogo não é muito alto. Não é apenas a escolha do jogador demonstrar o poder do AlphaGo que levanta questões, mas também alguns movimentos nos jogos.Algoritmo
Guo tem sido considerado um jogo para treinar no qual a inteligência artificial é difícil devido ao enorme espaço de pesquisa e à complexidade da escolha dos movimentos. Go pertence à classe de jogos com informações perfeitas, ou seja, os jogadores estão cientes de todos os movimentos que outros jogadores fizeram anteriormente. A solução para o problema de encontrar o resultado do jogo envolve calcular a função de valor ideal em uma árvore de pesquisa contendo aproximadamente d movimentos possíveis. Aqui b é o número de movimentos corretos em cada posição ed é a duração do jogo. No xadrez, esses valores são b 35 e d 80, e uma pesquisa completa não é possível. Portanto, as posições das figuras são avaliadas e, em seguida, a avaliação é levada em consideração na pesquisa. Em 1996, pela primeira vez, um computador ganhou xadrez contra um campeão e, desde 2005, nenhum campeão foi capaz de vencer um computador.Para go b ≈ 250, d ≈ 150. As posições possíveis das pedras em um tabuleiro padrão são mais do que googol (10 100 ) vezes mais que no xadrez. O número de posições possíveis é maior que os átomos no universo. Para complicar a situação, é difícil prever o valor dos estados devido à complexidade do jogo. Dois jogadores colocam pedras de duas cores em um tabuleiro de um determinado tamanho, o campo padrão é 19 × 19 linhas. As regras variam em detalhes, mas o objetivo principal do jogo é simples: você precisa cercar uma área maior no tabuleiro com pedras da sua cor do que o seu oponente.Os programas existentes podem ser reproduzidos no nível amador. Eles usam a pesquisa na árvore de Monte Carlo para avaliar o valor de cada estado na árvore de pesquisa. Os programas também incluem políticas que prevêem os movimentos de jogadores fortes.Recentemente, redes neurais convolucionais profundas conseguiram bons resultados no reconhecimento de faces e classificação de imagens. No Google, a IA até aprendeu a jogar 49 jogos antigos da Atari por conta própria . No AlphaGo, redes neurais semelhantes interpretam a posição das pedras no tabuleiro, o que ajuda a avaliar e selecionar movimentos. No Google, os pesquisadores adotaram a seguinte abordagem: eles usaram redes de valor e redes de políticas. Então essas redes neurais profundas são treinadas tanto em grupos de pessoas quanto em um jogo contra suas cópias. Uma busca também é nova, combinando o método de Monte Carlo com redes de política e valor. Esquema e arquitetura de treinamento de redes neurais.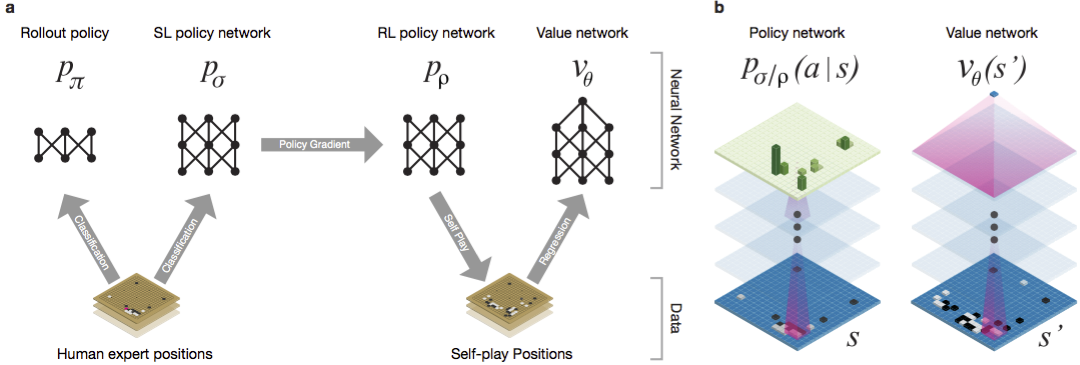 As redes neurais foram treinadas em várias etapas do aprendizado de máquina. A princípio, o treinamento controlado da rede de políticas era realizado diretamente, usando movimentos de jogadores humanos. Outra rede de políticas foi um aprendizado reforçado. O segundo jogou com o primeiro e o otimizou para que a política mudasse para uma vitória, e não apenas previsões de movimentos. Por fim, o treinamento foi realizado, reforçado por uma rede de valores que prevê o vencedor dos jogos disputados pelas redes de políticas. O resultado final é o AlphaGo, uma combinação do método de Monte Carlo e redes de política e valor. O resultado da previsão correta da próxima jogada foi alcançado em 57% dos casos. Antes do AlphaGo, o melhor resultado era de 44% .160 mil jogos com 29,4 milhões de posições do servidor KGS foram utilizados como entrada para treinamento. Os grupos de jogadores do sexto ao nono dan foram disputados. Um milhão de posições foram alocadas para testes e o próprio treinamento foi realizado para 28,4 milhões de posições. A força e a precisão das políticas e valores de rede.
Para que os algoritmos funcionem, eles exigem várias ordens de magnitude maior poder computacional do que na pesquisa tradicional. O AlphaGo é um programa multithread assíncrono que realiza simulação nos núcleos do processador central e executa redes de políticas e valores em chips de vídeo. A versão final parecia um aplicativo de 40 threads rodando em 48 processadores (provavelmente significava núcleos separados ou até hyperthreading) e 8 aceleradores gráficos. Também foi criada uma versão distribuída do AlphaGo, que utiliza várias máquinas, 40 fluxos de pesquisa, 1202 núcleos e 176 aceleradores de vídeo.
As redes neurais foram treinadas em várias etapas do aprendizado de máquina. A princípio, o treinamento controlado da rede de políticas era realizado diretamente, usando movimentos de jogadores humanos. Outra rede de políticas foi um aprendizado reforçado. O segundo jogou com o primeiro e o otimizou para que a política mudasse para uma vitória, e não apenas previsões de movimentos. Por fim, o treinamento foi realizado, reforçado por uma rede de valores que prevê o vencedor dos jogos disputados pelas redes de políticas. O resultado final é o AlphaGo, uma combinação do método de Monte Carlo e redes de política e valor. O resultado da previsão correta da próxima jogada foi alcançado em 57% dos casos. Antes do AlphaGo, o melhor resultado era de 44% .160 mil jogos com 29,4 milhões de posições do servidor KGS foram utilizados como entrada para treinamento. Os grupos de jogadores do sexto ao nono dan foram disputados. Um milhão de posições foram alocadas para testes e o próprio treinamento foi realizado para 28,4 milhões de posições. A força e a precisão das políticas e valores de rede.
Para que os algoritmos funcionem, eles exigem várias ordens de magnitude maior poder computacional do que na pesquisa tradicional. O AlphaGo é um programa multithread assíncrono que realiza simulação nos núcleos do processador central e executa redes de políticas e valores em chips de vídeo. A versão final parecia um aplicativo de 40 threads rodando em 48 processadores (provavelmente significava núcleos separados ou até hyperthreading) e 8 aceleradores gráficos. Também foi criada uma versão distribuída do AlphaGo, que utiliza várias máquinas, 40 fluxos de pesquisa, 1202 núcleos e 176 aceleradores de vídeo.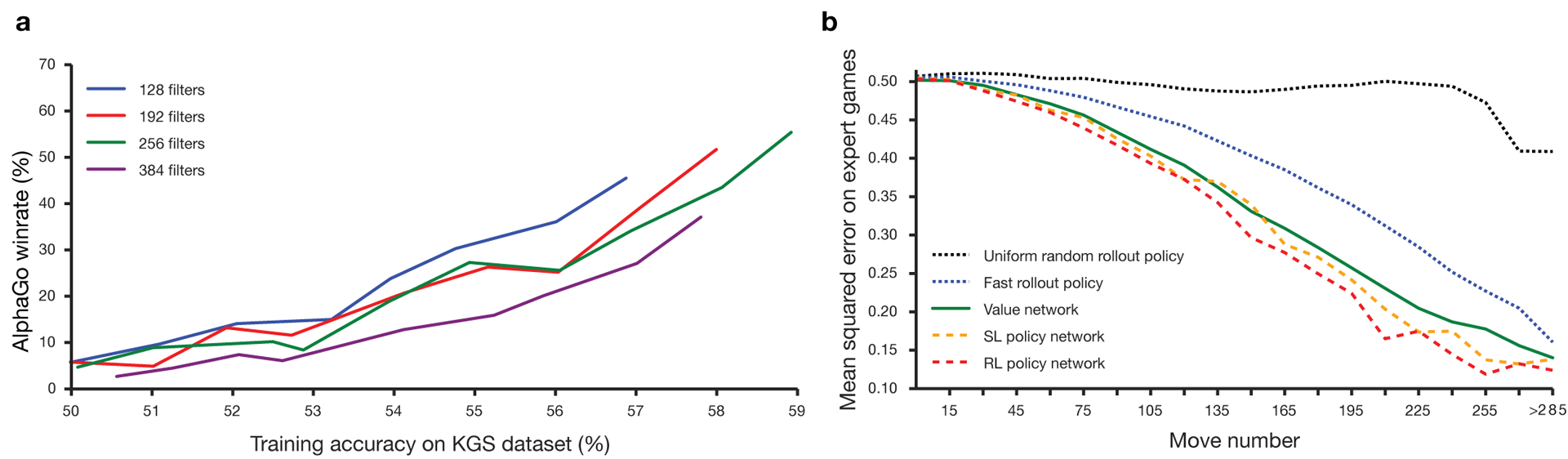 O relatório completo do DeepMind pode ser encontrado no documento . Procure por Monte Carlo no AlphaGo.
Para avaliar as habilidades do AlphaGo, foram realizadas partidas internas contra outras versões do programa, além de outros produtos similares. A comparação foi realizada com programas comerciais populares como Crazy Stone e Zen, e os mais fortes projetos de código aberto, Pachi e Fuego. Todos eles são baseados em algoritmos de Monte Carlo de alto desempenho. Mas também o AlphaGo comparado com o GnuGo que não é de Monte Carlo. Os programas receberam 5 segundos por movimento. Foi feita uma comparação entre o AlphaGo em execução em uma única máquina e a versão distribuída do algoritmo.
O relatório completo do DeepMind pode ser encontrado no documento . Procure por Monte Carlo no AlphaGo.
Para avaliar as habilidades do AlphaGo, foram realizadas partidas internas contra outras versões do programa, além de outros produtos similares. A comparação foi realizada com programas comerciais populares como Crazy Stone e Zen, e os mais fortes projetos de código aberto, Pachi e Fuego. Todos eles são baseados em algoritmos de Monte Carlo de alto desempenho. Mas também o AlphaGo comparado com o GnuGo que não é de Monte Carlo. Os programas receberam 5 segundos por movimento. Foi feita uma comparação entre o AlphaGo em execução em uma única máquina e a versão distribuída do algoritmo.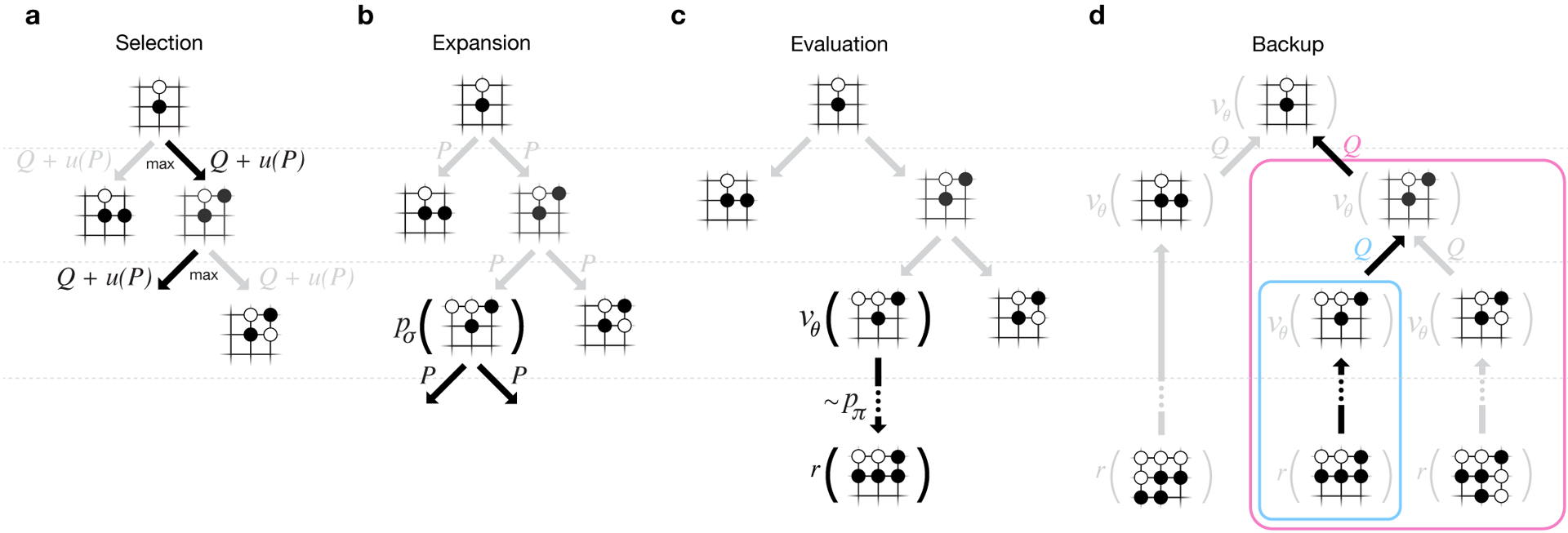 Segundo os desenvolvedores, os resultados mostraram que o AlphaGo é muito mais forte do que qualquer programa anterior. AlphaGo venceu 494 de 495 jogos, que são 99,8% das partidas contra outros produtos similares. As regras de ir permitem um handicap , handicap: até 9 pedras negras podem ser colocadas no campo antes do branco se mover. Mas mesmo com quatro pedras de desvantagem, a máquina single AlphaGo ganhou 77%, 86% e 99% do tempo contra Crazy Stone, Zen e Pachi, respectivamente. A versão distribuída do AlphaGo foi significativamente mais forte: em 77% dos jogos, derrotou a versão de máquina única e em 100% dos jogos - todos os outros programas. AlphaGo vs outros programas.
Segundo os desenvolvedores, os resultados mostraram que o AlphaGo é muito mais forte do que qualquer programa anterior. AlphaGo venceu 494 de 495 jogos, que são 99,8% das partidas contra outros produtos similares. As regras de ir permitem um handicap , handicap: até 9 pedras negras podem ser colocadas no campo antes do branco se mover. Mas mesmo com quatro pedras de desvantagem, a máquina single AlphaGo ganhou 77%, 86% e 99% do tempo contra Crazy Stone, Zen e Pachi, respectivamente. A versão distribuída do AlphaGo foi significativamente mais forte: em 77% dos jogos, derrotou a versão de máquina única e em 100% dos jogos - todos os outros programas. AlphaGo vs outros programas.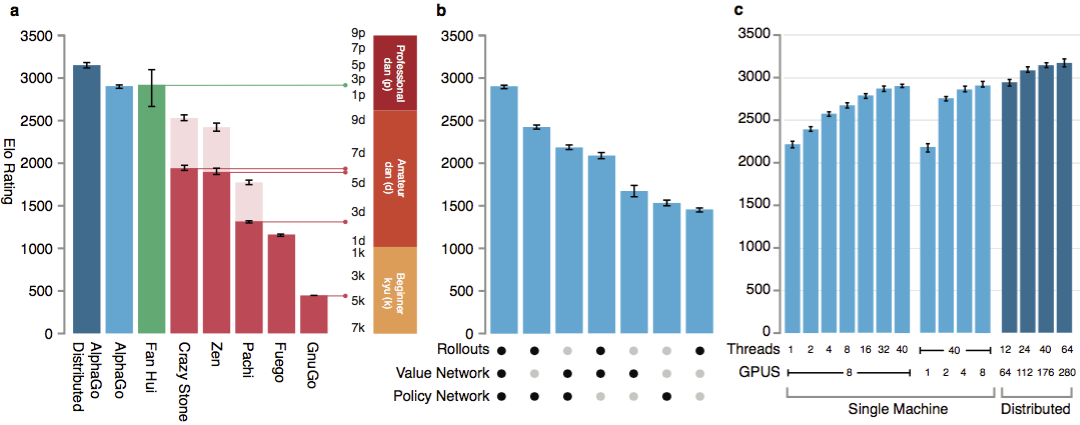 Finalmente, o produto criado foi comparado com uma pessoa. O jogador profissional 2 dan lutou contra a versão distribuída do AlphaGo, Fan Hui, vencedor do European Go Championship em 2013, 2014 e 2015. Os jogos foram realizados com a participação de um juiz da Federação Britânica de go e o editor da revista Nature. Foram realizados 5 jogos no período de 5 a 9 de outubro de 2015. Todos eles venceram o algoritmo de desenvolvimento do Google DeepMind. Foram esses jogos que levaram à afirmação de que o computador foi o primeiro a vencer um jogador profissional. Além de 5 partes oficiais, foram realizadas 5 partes não oficiais, o que não contou. Fan venceu dois deles.Disponível gravação move cinco jogos , vendo em um widget web e vídeos no YouTube .
Finalmente, o produto criado foi comparado com uma pessoa. O jogador profissional 2 dan lutou contra a versão distribuída do AlphaGo, Fan Hui, vencedor do European Go Championship em 2013, 2014 e 2015. Os jogos foram realizados com a participação de um juiz da Federação Britânica de go e o editor da revista Nature. Foram realizados 5 jogos no período de 5 a 9 de outubro de 2015. Todos eles venceram o algoritmo de desenvolvimento do Google DeepMind. Foram esses jogos que levaram à afirmação de que o computador foi o primeiro a vencer um jogador profissional. Além de 5 partes oficiais, foram realizadas 5 partes não oficiais, o que não contou. Fan venceu dois deles.Disponível gravação move cinco jogos , vendo em um widget web e vídeos no YouTube .Críticas de jogadores profissionais
A escolha de um jogador profissional e o jogo fraco do campeão estão sendo questionados. As regras escolhidas também não são claras: uma hora por jogo, em vez de várias horas de jogos sérios. No entanto, o formato foi escolhido pelo próprio Hui. Em março, o AlphaGo jogará contra Lee Sedola. O algoritmo pode vencer o profissional coreano do nono dan, considerado um dos melhores jogadores do mundo? Está em jogo um milhão de dólares. Se uma pessoa vencer, Li Sedol o receberá; se o algoritmo vencer, ele irá para a caridade.Os pesquisadores dizem que durante a batalha de outubro com humanos, o sistema AlphaGo considerou milhares de vezes menos posições do que o Deep Blue durante uma partida histórica com Kasparov. Em vez disso, o programa usou uma rede de políticas para escolhas mais inteligentes e uma rede de valores para medir com mais precisão as posições. Talvez essa abordagem esteja mais próxima de como as pessoas jogam, dizem os pesquisadores. Além disso, o sistema de classificação Deep Blue foi programado manualmente, enquanto as redes neurais AlphaGo foram treinadas diretamente a partir dos jogos usando algoritmos universais de aprendizado supervisionado e aprendizado por reforço. Lee Sedoll tentará sua mão contra o AlphaGo em março. Jogadores profissionais têm diferentes pontos de vista. Parece para alguns que o Google não escolheu especificamente um jogador muito forte, alguém tem certeza de que o Sedol perderá em março deste ano.Um dos jogadores profissionais mais fortes que falam inglês, Kim Mengwang (nono dan) acredita que Fan Hui não jogou com força total. No 51º minuto do vídeo, ele dá um exemplo concreto da segunda parte. O fã pode ter jogado os dois com um mais fraco para testar o poder do computador, diz Kim. Mengwan admitiu que o AlphaGo é um programa chocantemente poderoso, mas é improvável que derrote Lee Sedol.O árbitro da partida, Toby Manning, disse ao British Go Journal sobre a partida. Ele analisou todos os cinco jogos e destacou alguns pontos. AlphaGo cometeu erros no segundo, terceiro e quarto jogos, mas Fan não os usou. O tricampeão europeu respondeu com o seu. O artigo da revista termina com uma avaliação positiva geral da AlphaGo: o programa é forte, mas não está claro quanto.Além disso, ao preparar o material, recebi comentários de profissionais russos e amadores. Alexander Dinerstein (Kazan), terceiro dan (profissional), sete vezes campeão europeu:
Jogadores profissionais têm diferentes pontos de vista. Parece para alguns que o Google não escolheu especificamente um jogador muito forte, alguém tem certeza de que o Sedol perderá em março deste ano.Um dos jogadores profissionais mais fortes que falam inglês, Kim Mengwang (nono dan) acredita que Fan Hui não jogou com força total. No 51º minuto do vídeo, ele dá um exemplo concreto da segunda parte. O fã pode ter jogado os dois com um mais fraco para testar o poder do computador, diz Kim. Mengwan admitiu que o AlphaGo é um programa chocantemente poderoso, mas é improvável que derrote Lee Sedol.O árbitro da partida, Toby Manning, disse ao British Go Journal sobre a partida. Ele analisou todos os cinco jogos e destacou alguns pontos. AlphaGo cometeu erros no segundo, terceiro e quarto jogos, mas Fan não os usou. O tricampeão europeu respondeu com o seu. O artigo da revista termina com uma avaliação positiva geral da AlphaGo: o programa é forte, mas não está claro quanto.Além disso, ao preparar o material, recebi comentários de profissionais russos e amadores. Alexander Dinerstein (Kazan), terceiro dan (profissional), sete vezes campeão europeu:Deep Blue . , , , . Google . .
4-4 ( -, starpoint ). . : 3-3, 3-4, 5-3, , , , . , . .
, , . . – , . , - . . 20-30 , , , , . , . , . .
, - 2016 (EGC), no âmbito do qual sempre ocorre um torneio de programa de computador. A Federação Russa de Go convidou todos os programas mais fortes para participar do torneio. Se eles aceitarem o convite, talvez seja nesse torneio pela primeira vez que os programas do Google e do Facebook serão exibidos entre si. Este último, diferentemente de seu concorrente, está seguindo um caminho honesto. O bot DarkForest joga milhares de jogos no servidor KGS . A versão mais forte está se aproximando do sexto dan no servidor. Este é um nível muito bom. Fan Hui e jogadores do seu nível - este é o oitavo dan no servidor (de nove possíveis). A diferença é de duas desvantagens de pedra. Com essa diferença, um programa às vezes pode realmente derrotar uma pessoa. Se em termos iguais, aproximadamente um lote de dez.
Maxim Podolyak, (São Petersburgo), vice-presidente da Federação Russa de Go:, , , , , , , , . , Google : , . , . : , , , . , : , . Google . , . ? ?
Alexander Krainov (Moscow), amante do jogo:Devido à minha atividade profissional, conheço a situação muito bem "do outro lado".
Em 2012, houve um salto quântico no aprendizado de máquina em geral. A quantidade de dados para treinamento, o nível de algoritmos e a capacidade de treinamento atingiram um nível tal que as redes neurais artificiais (desenvolvidas como princípio por um longo tempo) começaram a dar resultados fantásticos.
A diferença fundamental entre o treinamento em redes neurais é que elas não precisam receber fatores de entrada (no caso de ir, explique, por exemplo, quais formas são boas). No limite, mesmo as regras não podem ser explicadas a eles. O principal é dar um grande número de exemplos positivos (movimentos do lado vencedor) e negativos (movimentos do lado perdedor). E a rede vai aprender a si mesma.
, , . . : , , ( ) , .
, .
, , , . . . . , , .
O que o próprio Lee Sedol diz
Os jogadores profissionais competem não pelo título mundial, mas pelos títulos. O reconhecimento e o status do mestre são determinados pelo número de títulos que ele conseguiu obter durante o ano. Lee Sedol é um dos cinco jogadores mais fortes do mundo, e em março deste ano ele terá que lutar com o sistema AlphaGo.O próprio campeão coreano prevê que vencerá com uma pontuação de 4-1 ou 5-0. Mas, depois de 2 a 3 anos, o Google vai querer se vingar, e o jogo com a versão atualizada do AlphaGo será mais interessante, diz Lee.
A tarefa de criar esse algoritmo coloca novas questões sobre o que são aprendizado e pensamento. Como o Sr. Emelyanov lembra , o terceiro nível de habilidade (pino) do topo, de acordo com a classificação chinesa antiga, é chamado de "clareza completa". Tal nível do jogo sugere que as decisões são tomadas intuitivamente, com poucas ou nenhuma opção. Um dos mestres mais fortes do século XX, Guo Seigen, disse que lhe parecia que ele teria vencido contra o "go-god" ao pegar duas ou três pedras de handicap. Seigan acreditava que ele quase alcançara o limite de entender o jogo. Uma rede neural pode conseguir isso? Talvez a intuição humana seja um algoritmo estabelecido pela natureza?O autor agradece a Alexander Dinerstein e ao público go_secrets pelos comentários e ajuda na publicação.Source: https://habr.com/ru/post/pt389825/
All Articles