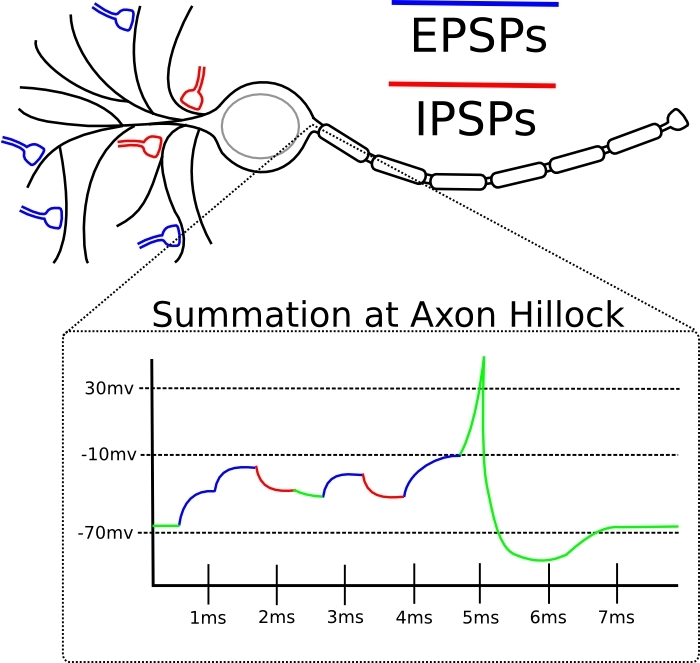
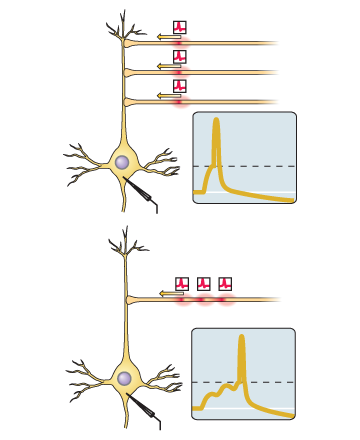
Se o pico de entrada nessa sinapse tende a ocorrer logo antes do próprio neurônio gerar o pico, a sinapse é amplificada.Se o pico de entrada nessa sinapse tende a ocorrer imediatamente após a geração do pico pelo próprio neurônio, a sinapse é enfraquecida.
Source: https://habr.com/ru/post/pt390385/More articles:15 anos do primeiro contato do aparato terrestre com um asteróideO número de usuários de sites e aplicativos para namoro online está crescendo rapidamenteUbuntu Tablet: "tudo o que você precisa de um PC está em um tablet"Você trabalha demais? Férias não vão ajudar14 de fevereiro - Lawrence Day: presentes para o seu ente queridoOs titulares de direitos inventam novas maneiras de converter piratas em usuários pagantesTecnologia FRAMQualidade da comunicação - aplicativo Android do Ministério das ComunicaçõesComo despertar jogos de interesse na história ou na mesa redonda do WargamingO Trojan bancário inteligente permite que você retire uma quantia quase ilimitada de dinheiro nos caixas eletrônicosAll Articles