 Aconteceu que o idioma principal para trabalhar com microcontroladores é C. Muitos projetos grandes estão escritos nele. Mas a vida não pára. Ferramentas de desenvolvimento modernas há muito tempo conseguem usar o C ++ no desenvolvimento de software para sistemas embarcados. No entanto, essa abordagem ainda é rara. Há pouco tempo, tentei usar C ++ ao trabalhar em outro projeto. Vou falar sobre essa experiência neste artigo.
Aconteceu que o idioma principal para trabalhar com microcontroladores é C. Muitos projetos grandes estão escritos nele. Mas a vida não pára. Ferramentas de desenvolvimento modernas há muito tempo conseguem usar o C ++ no desenvolvimento de software para sistemas embarcados. No entanto, essa abordagem ainda é rara. Há pouco tempo, tentei usar C ++ ao trabalhar em outro projeto. Vou falar sobre essa experiência neste artigo.Entrada
A maior parte do meu trabalho com microcontroladores está conectada ao C. Primeiro, foram os requisitos do cliente e depois se tornou apenas um hábito. Ao mesmo tempo, quando se tratava de aplicativos para Windows, o C ++ era usado primeiro e depois o C # em geral.Não há perguntas sobre C ou C ++ há muito tempo. Até o lançamento da próxima versão do MDK do Keil com suporte a C ++ para ARM não me incomodou muito. Se você olhar para os projetos de demonstração Keil, tudo está escrito lá em C. Ao mesmo tempo, o C ++ é movido para uma pasta separada junto com o projeto Blinky. CMSIS e LPCOpen também são escritos em C. E se "todos" usam C, então existem alguns motivos.Mas muita coisa mudou .Net Micro Framework. Se alguém não souber, essa é uma implementação .Net que permite escrever aplicativos para microcontroladores em C # no Visual Studio. Você pode aprender mais sobre ele emesses artigos.Portanto, o .Net Micro Framework é escrito usando C ++. Impressionado com isso, decidi tentar escrever outro projeto em C ++. Devo dizer imediatamente que não encontrei argumentos definidos a favor do C ++, mas há alguns pontos interessantes e úteis nessa abordagem.Qual é a diferença entre projetos C e C ++?
Uma das principais diferenças entre C e C ++ é que a segunda é uma linguagem orientada a objetos. Encapsulamento, polimorfismo e herança conhecidos são comuns aqui. C é uma linguagem processual. Existem apenas funções e procedimentos e, para o agrupamento lógico do código, são utilizados módulos (um par de .h + .c). Mas se você observar atentamente como o C é usado nos microcontroladores, poderá ver a abordagem orientada a objetos usual.Vejamos o código para trabalhar com LEDs do exemplo Keil para MCB1000 ( Keil_v5 \ ARM \ Boards \ Keil \ MCB1000 \ MCB11C14 \ CAN_Demo ):LED.h:#ifndef __LED_H
#define __LED_H
#define LED_NUM 8
extern void LED_init(void);
extern void LED_on (uint8_t led);
extern void LED_off (uint8_t led);
extern void LED_out (uint8_t led);
#endif
LED.c:#include "LPC11xx.h"
#include "LED.h"
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
void LED_init (void) {
LPC_SYSCON->SYSAHBCLKCTRL |= (1UL << 6);
LPC_GPIO2->DIR |= (led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
LPC_GPIO2->DATA &= ~(led_mask[0] | led_mask[1] | led_mask[2] | led_mask[3] |
led_mask[4] | led_mask[5] | led_mask[6] | led_mask[7] );
}
void LED_on (uint8_t num) {
LPC_GPIO2->DATA |= led_mask[num];
}
void LED_off (uint8_t num) {
LPC_GPIO2->DATA &= ~led_mask[num];
}
void LED_out(uint8_t value) {
int i;
for (i = 0; i < LED_NUM; i++) {
if (value & (1<<i)) {
LED_on (i);
} else {
LED_off(i);
}
}
}
Se você olhar atentamente, poderá fazer uma analogia com o OOP. LED é um objeto que possui uma constante pública, construtor, 3 métodos públicos e um campo privado:class LED
{
private:
const unsigned long led_mask[] = {1UL << 0, 1UL << 1, 1UL << 2, 1UL << 3,
1UL << 4, 1UL << 5, 1UL << 6, 1UL << 7 };
public:
unsigned char LED_NUM=8;
public:
LED();
void on (uint8_t led);
void off (uint8_t led);
void out (uint8_t led);
}
Apesar do código estar escrito em C, ele usa o paradigma da programação de objetos. Um arquivo .C é um objeto que permite encapsular dentro dos mecanismos de implementação dos métodos públicos descritos no arquivo .h. Mas não há herança aqui e, portanto, polimorfismo também.A maior parte do código nos projetos que conheci é escrita no mesmo estilo. E se a abordagem OOP for usada, por que não usar uma linguagem que a suporte totalmente? Ao mesmo tempo, ao mudar para C ++, em geral, apenas a sintaxe será alterada, mas não os princípios de desenvolvimento.Considere outro exemplo. Suponha que tenhamos um dispositivo que use um sensor de temperatura conectado via I2C. Mas uma nova revisão do dispositivo foi lançada e o mesmo sensor agora está conectado ao SPI. O que fazer É necessário suportar a primeira e a segunda revisão do dispositivo, o que significa que o código deve levar em consideração essas alterações de maneira flexível. Em C, você pode usar #define predefinitions para evitar a gravação de dois arquivos quase idênticos. Por exemplo#ifdef REV1
#include “i2c.h”
#endif
#ifdef REV2
#include “spi.h”
#endif
void TEMPERATURE_init()
{
#ifdef REV1
I2C_int()
#endif
#ifdef REV2
SPI_int()
#endif
}
e assim por dianteNo C ++, você pode resolver esse problema de maneira um pouco mais elegante. Faça interfaceclass ITemperature
{
public:
virtual unsigned char GetValue() = 0;
}
e faça 2 implementaçõesclass Temperature_I2C: public ITemperature
{
public:
virtual unsigned char GetValue();
}
class Temperature_SPI: public ITemperature
{
public:
virtual unsigned char GetValue();
}
E, em seguida, use esta ou aquela implementação, dependendo da revisão:class TemperatureGetter
{
private:
ITemperature* _temperature;
pubic:
Init(ITemperature* temperature)
{
_temperature = temperature;
}
private:
void GetTemperature()
{
_temperature->GetValue();
}
#ifdef REV1
Temperature_I2C temperature;
#endif
#ifdef REV2
Temperature_SPI temperature;
#endif
TemperatureGetter tGetter;
void main()
{
tGetter.Init(&temperature);
}
Parece que a diferença não é muito grande entre o código C e C ++. A opção orientada a objetos parece ainda mais complicada. Mas permite que você tome uma decisão mais flexível.Ao usar C, duas soluções principais podem ser distinguidas:- Use #define como mostrado acima. Essa opção não é muito boa porque "erode" a responsabilidade do módulo. Acontece que ele é responsável por várias revisões do projeto. Quando existem muitos desses arquivos, torna-se bastante difícil mantê-los.
- 2 , C++. “” , . , #ifdef. , , . , . , , .
O uso do polimorfismo fornece um resultado mais bonito. Por um lado, cada classe resolve um problema atômico claro; por outro lado, o código não é desarrumado e fácil de ler.A “ramificação” do código na revisão ainda terá que ser feita no primeiro e no segundo casos, mas o uso do polimorfismo facilita a transferência do local de ramificação entre as camadas do programa, sem sobrecarregar o código com #ifdef.O uso do polimorfismo facilita a tomada de uma decisão ainda mais interessante.Digamos que uma nova revisão seja lançada, na qual os dois sensores de temperatura estão instalados.O mesmo código com alterações mínimas permite escolher uma implementação SPI e I2C em tempo real, simplesmente usando o método Init (& temperature).O exemplo é muito simplificado, mas em um projeto real eu usei a mesma abordagem para implementar o mesmo protocolo sobre duas interfaces físicas diferentes de transferência de dados. Isso facilitou a escolha da interface nas configurações do dispositivo.No entanto, com todas as opções acima, a diferença entre o uso de C e C ++ permanece não muito grande. As vantagens do C ++ relacionadas ao POO não são tão óbvias e pertencem à categoria "amador". Mas o uso de C ++ em microcontroladores tem problemas bastante sérios.Qual é o perigo de usar C ++?
A segunda diferença importante entre C e C ++ é o uso de memória. A linguagem C é principalmente estática. Todas as funções e procedimentos têm endereços fixos e o trabalho com um grupo é realizado apenas quando necessário. C ++ é uma linguagem mais dinâmica. Geralmente, seu uso implica trabalho ativo com alocação e liberação de memória. É isso que C ++ é perigoso. Os microcontroladores têm muito poucos recursos, portanto, o controle sobre eles é importante. O uso não controlado da RAM está repleto de danos aos dados armazenados lá e de tais "milagres" no trabalho do programa que ninguém vai pensar. Muitos desenvolvedores encontraram esses problemas.Se você observar atentamente os exemplos acima, pode-se notar que as classes não possuem construtores e destruidores. Isso ocorre porque eles nunca são criados dinamicamente.Ao usar memória dinâmica (e ao usar novo), a função malloc é sempre chamada, que aloca o número necessário de bytes do heap. Mesmo se você pensar bem (embora seja muito difícil) e controlar o uso da memória, poderá encontrar o problema da fragmentação.Um monte pode ser representado como uma matriz. Por exemplo, selecionamos 20 bytes para isso: Cada vez que a memória é alocada, toda a memória é varrida (da esquerda para a direita ou da direita para a esquerda - isso não é tão importante) para a presença de um número determinado de bytes desocupados. Além disso, todos esses bytes devem estar localizados nas proximidades:
Cada vez que a memória é alocada, toda a memória é varrida (da esquerda para a direita ou da direita para a esquerda - isso não é tão importante) para a presença de um número determinado de bytes desocupados. Além disso, todos esses bytes devem estar localizados nas proximidades: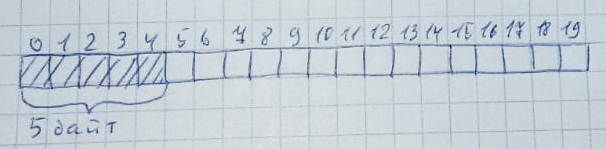 Quando a memória não é mais necessária, ela retorna ao seu estado original:Com muita facilidade, isso pode acontecer quando há bytes livres suficientes, mas eles não são organizados em uma linha. Permita que 10 zonas de 2 bytes sejam alocadas:
Quando a memória não é mais necessária, ela retorna ao seu estado original:Com muita facilidade, isso pode acontecer quando há bytes livres suficientes, mas eles não são organizados em uma linha. Permita que 10 zonas de 2 bytes sejam alocadas: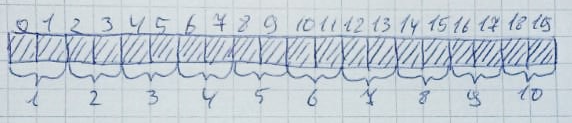 Em seguida, 2,4,6,8,10 zonas serão liberadas:
Em seguida, 2,4,6,8,10 zonas serão liberadas: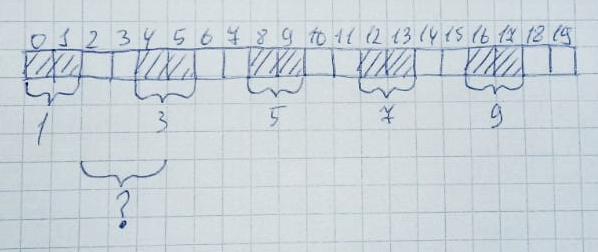 Formalmente, metade da pilha inteira (10 bytes) permanece livre. No entanto, alocar uma área de memória de 3 bytes de tamanho ainda não funciona, pois a matriz não possui três células livres em uma linha. Isso é chamado de fragmentação de memória.E lidar com isso em sistemas sem virtualização de memória é bastante difícil. Especialmente em grandes projetos.Esta situação pode ser facilmente emulada. Fiz isso no Keil mVision no microcontrolador LPC11C24.Defina o tamanho da pilha como 256 bytes:
Formalmente, metade da pilha inteira (10 bytes) permanece livre. No entanto, alocar uma área de memória de 3 bytes de tamanho ainda não funciona, pois a matriz não possui três células livres em uma linha. Isso é chamado de fragmentação de memória.E lidar com isso em sistemas sem virtualização de memória é bastante difícil. Especialmente em grandes projetos.Esta situação pode ser facilmente emulada. Fiz isso no Keil mVision no microcontrolador LPC11C24.Defina o tamanho da pilha como 256 bytes: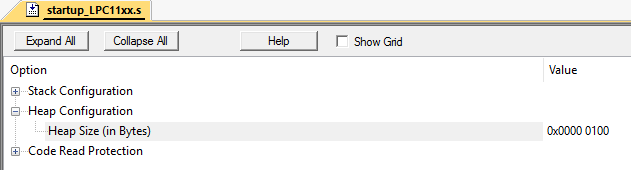 suponha que tenhamos 2 classes:
suponha que tenhamos 2 classes:#include <stdint.h>
class foo
{
private:
int32_t _pr1;
int32_t _pr2;
int32_t _pr3;
int32_t _pr4;
int32_t _pb1;
int32_t _pb2;
int32_t _pb3;
int32_t _pb4;
int32_t _pc1;
int32_t _pc2;
int32_t _pc3;
int32_t _pc4;
public:
foo()
{
_pr1 = 100;
_pr2 = 200;
_pr3 = 300;
_pr4 = 400;
_pb1 = 100;
_pb2 = 200;
_pb3 = 300;
_pb4 = 400;
_pc1 = 100;
_pc2 = 200;
_pc3 = 300;
_pc4 = 400;
}
~foo(){};
int32_t F1(int32_t a)
{
return _pr1*a;
};
int32_t F2(int32_t a)
{
return _pr1/a;
};
int32_t F3(int32_t a)
{
return _pr1+a;
};
int32_t F4(int32_t a)
{
return _pr1-a;
};
};
class bar
{
private:
int32_t _pr1;
int8_t _pr2;
public:
bar()
{
_pr1 = 100;
_pr2 = 10;
}
~bar() {};
int32_t F1(int32_t a)
{
return _pr2/a;
}
int16_t F2(int32_t a)
{
return _pr2*a;
}
};
Como você pode ver, a classe bar ocupa mais memória do que foo.14 instâncias da classe bar são colocadas no heap e a instância da classe foo não se encaixa mais:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
f = new foo();
}
Se você criar apenas 7 instâncias de barra, o foo também será criado normalmente:int main(void)
{
foo *f;
bar *b[14];
b[1] = new bar();
b[3] = new bar();
b[5] = new bar();
b[7] = new bar();
b[9] = new bar();
b[11] = new bar();
b[13] = new bar();
f = new foo();
}
No entanto, se você primeiro criar 14 instâncias de barra, excluir 0,2,4,6,8,10 e 12 instâncias, o foo não poderá alocar memória devido à fragmentação do heap:int main(void)
{
foo *f;
bar *b[14];
b[0] = new bar();
b[1] = new bar();
b[2] = new bar();
b[3] = new bar();
b[4] = new bar();
b[5] = new bar();
b[6] = new bar();
b[7] = new bar();
b[8] = new bar();
b[9] = new bar();
b[10] = new bar();
b[11] = new bar();
b[12] = new bar();
b[13] = new bar();
delete b[0];
delete b[2];
delete b[4];
delete b[6];
delete b[8];
delete b[10];
delete b[12];
f = new foo();
}
Acontece que você não pode usar o C ++ completamente, e esse é um sinal de menos. Do ponto de vista arquitetônico, C ++, embora superior a C, é insignificante. Como resultado, a transição para o C ++ não traz benefícios significativos (embora também não haja grandes pontos negativos). Assim, devido a uma pequena diferença, a escolha do idioma permanecerá simplesmente a preferência pessoal do desenvolvedor.Mas, para mim, encontrei um ponto positivo significativo no uso de C ++. O fato é que, com a abordagem C ++ correta, o código para microcontroladores pode ser facilmente coberto com testes de unidade no Visual Studio.Uma grande vantagem do C ++ é a capacidade de usar o Visual Studio.
Para mim, pessoalmente, o tópico de teste de código para microcontroladores sempre foi bastante complicado. Naturalmente, o código foi verificado de todas as maneiras possíveis, mas a criação de um sistema de teste automático completo sempre exigia custos enormes, pois era necessário montar um suporte de hardware e escrever um firmware especial para ele. Especialmente quando se trata de um sistema IoT distribuído que consiste em centenas de dispositivos.Quando comecei a escrever um projeto em C ++, imediatamente quis tentar colocar o código no Visual Studio e usar o Keil mVision apenas para depuração. Primeiro, no Visual Studio, um editor de código muito poderoso e conveniente; em segundo lugar, no Keil mVision, não é uma integração conveniente com os sistemas de controle de versão; no Visual Studio, tudo é elaborado para ser automático. Em terceiro lugar, eu esperava conseguir cobrir pelo menos parte do código com testes de unidade, que também são bem suportados no Visual Studio. E em quarto lugar, é o surgimento do Resharper C ++ - uma extensão do Visual Studio para trabalhar com código C ++, graças ao qual você pode evitar muitos erros em potencial com antecedência e monitorar o estilo do código.Criar um projeto no Visual Studio e conectá-lo ao sistema de controle de versão não causou problemas. Mas eu tive que mexer com testes de unidade.Classes abstraídas do hardware (por exemplo, analisadores de protocolo) eram fáceis de testar. Mas eu queria mais! Nos meus projetos periféricos, eu uso os arquivos de cabeçalho do Keil. Por exemplo, para LPC11C24, é LPC11xx.h. Esses arquivos descrevem todos os registros necessários de acordo com o padrão CMSIS. A definição direta de um registro específico é feita através de #define:#define LPC_I2C_BASE (LPC_APB0_BASE + 0x00000)
#define LPC_I2C ((LPC_I2C_TypeDef *) LPC_I2C_BASE )
Aconteceu que, se você substituir corretamente os registros e criar alguns stubs, o código que usa periféricos poderá muito bem ser compilado no VisualStudio. Além disso, se você criar uma classe estática e especificar seus campos como endereços de registro, obterá um emulador de microcontrolador completo, que permite testar totalmente o trabalho com periféricos:#include <LPC11xx.h>
class LPC11C24Emulator
{
public:
static class Registers
{
public:
static LPC_ADC_TypeDef ADC;
public:
static void Init()
{
memset(&ADC, 0x00, sizeof(LPC_ADC_TypeDef));
}
};
}
#undef LPC_ADC
#define LPC_ADC ((LPC_ADC_TypeDef *) &LPC11C24Emulator::Registers::ADC)
E então faça o seguinte:#if defined ( _M_IX86 )
#include "..\Emulator\LPC11C24Emulator.h"
#else
#include <LPC11xx.h>
#endif
Dessa forma, você pode compilar e testar todo o código do projeto para microcontroladores no VisualStudio com alterações mínimas.No processo de desenvolvimento de um projeto em C ++, escrevi mais de 300 testes cobrindo aspectos puramente de hardware e código abstraído do hardware. Além disso, aproximadamente 20 erros bastante sérios foram encontrados com antecedência, o que, devido ao tamanho do projeto, não seria fácil de detectar sem testes automáticos.Conclusões
Usar ou não usar C ++ ao trabalhar com microcontroladores é uma questão bastante complicada. Eu mostrei acima que, por um lado, as vantagens arquitetônicas de uma OOP completa não são tão grandes, e a incapacidade de trabalhar totalmente com um monte é um problema bastante grande. Dado esses aspectos, não há grande diferença entre C e C ++ para trabalhar com microcontroladores, a escolha entre eles pode muito bem ser justificada pelas preferências pessoais do desenvolvedor.No entanto, consegui encontrar um grande ponto positivo no uso do C ++ ao trabalhar com o Visaul Studio. Isso permite aumentar significativamente a confiabilidade do desenvolvimento devido ao trabalho completo com sistemas de controle de versão, ao uso de testes de unidade completos (incluindo testes para trabalhar com periféricos) e outras vantagens do Visual Studio.Espero que minha experiência seja útil e ajude alguém a aumentar a eficácia de seu trabalho.Atualização :nos comentários sobre a versão em inglês deste artigo, foram apresentados links úteis sobre este tópico: