A sofisticada técnica de resposta aleatória foi usada pela primeira vez pelo Google para coletar estatísticas do Chrome. A Apple seguirá o exemplo?
. : , , 14 2016
WWDC Apple , , … . , Apple « » («Differential Privacy», : DP), .
Para a maioria das pessoas, isso causou uma pergunta idiota: “o que ... ???”, porque poucos ouviram falar em privacidade diferencial antes e, mais ainda, entendem o que isso significa. Infelizmente, a Apple não é clara quando se trata dos ingredientes secretos em que sua plataforma é executada, então só podemos esperar que no futuro ela decida publicar mais informações. Tudo o que sabemos no momento está contido no manual do Apple iOS 10 Preview.“A partir do iOS 10, a Apple usa tecnologia de privacidade diferencial para ajudar a identificar padrões de comportamento do usuário para um grande número de usuários, sem comprometer a privacidade de cada usuário. Para ocultar a identidade de uma pessoa, a privacidade diferencial adiciona ruído matemático a uma pequena amostra de um modelo de comportamento do usuário individual para um usuário específico. À medida que mais pessoas mostram o mesmo padrão, começam a surgir padrões comuns que podem nos informar e melhorar a experiência geral do usuário. No iOS 10, essa tecnologia ajudará a melhorar as dicas de QuickType e emoji, dicas do Spotlight e dicas de pesquisa no Notes. ”Em suma, parece que a Apple deseja coletar muito mais dados do seu telefone.Basicamente, eles fazem isso para melhorar seus serviços e não para coletar informações sobre os hábitos e características individuais de cada usuário. Para garantir isso, a Apple pretende usar técnicas estatísticas sofisticadas para garantir que a base agregada - o resultado do cálculo da função estatística após o processamento de todas as suas informações - não forneça participantes individuais. Em princípio, parece muito bom. Mas é claro que o diabo está sempre escondido nos detalhes.Embora não tenhamos esses detalhes, parece que agora é hora de pelo menos falar sobre o que é a privacidade diferencial, como ela pode ser implementada e o que isso pode significar para a Apple - e para o seu iPhone.Motivação
Nos últimos anos, o "usuário comum" se acostumou à idéia de que uma enorme quantidade de informações pessoais é enviada de seu dispositivo para os vários serviços que ele usa. Pesquisas de opinião também mostram que os cidadãos estão começando a se sentir desconfortáveis por esse motivo .Esse desconforto faz sentido se você pensar nas empresas que usam nossas informações pessoais para ganhar dinheiro conosco. No entanto, às vezes há um bom motivo para coletar informações sobre as ações do usuário. Por exemplo, a Microsoft introduziu recentemente uma ferramenta que pode diagnosticar câncer de pâncreas analisando suas consultas de pesquisa no Bing. O Google suporta o conhecido serviço Google Flu Trendsprever a propagação de doenças infecciosas pela frequência de consultas de pesquisa em diferentes áreas. E, é claro, todos nos beneficiamos de dados de crowdsourcing que melhoram a qualidade dos serviços que usamos, desde aplicativos de mapas até avaliações em restaurantes. Infelizmente, até a coleta de dados para bons propósitos pode ser prejudicial. Por exemplo, no final dos anos 2000, a Netflix anunciou uma competição para desenvolver o melhor algoritmo de recomendação para longas-metragens. Para ajudar os participantes do concurso, eles publicaram um conjunto de dados "anonimizado" com estatísticas das visualizações dos usuários de filmes, excluindo todas as informações pessoais de lá. Infelizmente, essa "desidentificação" não foi suficiente. No famoso trabalho científico de Narayan e Shmatikovmostrou que esses conjuntos de dados podem ser usados para desarmar o nome de usuários específicos - e até prever suas opiniões políticas! - simplesmente se você souber um pouco de informação extra sobre esses usuários.Tais coisas devem nos incomodar. Não apenas porque as empresas comerciais trocam habitualmente informações coletadas sobre os usuários (embora o façam), mas porque os hacks acontecem e porque mesmo as estatísticas sobre o banco de dados coletado podem de alguma forma esclarecer os detalhes dos registros individuais específicos que foram usados para compilar uma amostra agregada. Privacidade diferencial é um conjunto de ferramentas projetadas para resolver esse problema.O que é privacidade diferencial?
Privacidade diferencial é uma definição de proteção de dados do usuário proposta originalmente por Cynthia Dwork em 2006. Grosso modo, pode ser descrito brevemente da seguinte forma:Imagine que você tem dois bancos de dados idênticos em todos os outros aspectos, um com suas informações internas e outro sem elas. A privacidade diferencial garante que uma consulta estatística para um e o segundo banco de dados produza um resultado específico com (quase) a mesma probabilidade.Isso pode ser representado da seguinte maneira: O DP possibilita entender se seus dados têm algum efeito estatisticamente significativo no resultado da consulta. Caso contrário, eles podem ser adicionados com segurança ao banco de dados, porque praticamente não haverá danos. Considere este exemplo bobo:imagine que você ativou no seu iPhone a opção de informar à Apple que costuma usar emojis  nas sessões de bate-papo do iMessage. Este relatório consiste em um pouco de informação: 1 significa que você gosta e 0 significa que você não. A Apple pode receber esses relatórios e inseri-los em um banco de dados gigantesco. Como resultado, a empresa deseja descobrir o número de usuários que gostam de um determinado emoji.Escusado será dizer que o processo simples de resumir os resultados e publicá-los não satisfaz a definição de DP, porque a operação aritmética de somar valores em um banco de dados que contém suas informações produzirá potencialmente um resultado diferente do que somar valores de um banco de dados em que suas informações estão ausentes. Portanto, embora esses valores forneçam um pouco de informação sobre você, ainda assim algumas informações pessoais vazarão. A principal conclusão do estudo da privacidade diferencial é que, em muitos casos, o princípio DP pode ser alcançado adicionando ruído aleatóriopara o resultado. Por exemplo, em vez de simplesmente relatar o resultado final, a parte do relatório pode implementar uma distribuição Gaussiana ou Laplace, para que o resultado não seja tão preciso - mas irá mascarar todos os valores específicos no banco de dados. (Existem muitas outras técnicas para outros recursos interessantes ).Ainda mais valioso, o cálculo da quantidade de ruído adicionado pode ser feito sem conhecer o conteúdo do próprio banco de dados (ou mesmo o seu tamanho) . Ou seja, o cálculo com ruído pode ser realizado com base apenas no conhecimento da própria função, que é executada, e em um nível aceitável de vazamento de dados.
nas sessões de bate-papo do iMessage. Este relatório consiste em um pouco de informação: 1 significa que você gosta e 0 significa que você não. A Apple pode receber esses relatórios e inseri-los em um banco de dados gigantesco. Como resultado, a empresa deseja descobrir o número de usuários que gostam de um determinado emoji.Escusado será dizer que o processo simples de resumir os resultados e publicá-los não satisfaz a definição de DP, porque a operação aritmética de somar valores em um banco de dados que contém suas informações produzirá potencialmente um resultado diferente do que somar valores de um banco de dados em que suas informações estão ausentes. Portanto, embora esses valores forneçam um pouco de informação sobre você, ainda assim algumas informações pessoais vazarão. A principal conclusão do estudo da privacidade diferencial é que, em muitos casos, o princípio DP pode ser alcançado adicionando ruído aleatóriopara o resultado. Por exemplo, em vez de simplesmente relatar o resultado final, a parte do relatório pode implementar uma distribuição Gaussiana ou Laplace, para que o resultado não seja tão preciso - mas irá mascarar todos os valores específicos no banco de dados. (Existem muitas outras técnicas para outros recursos interessantes ).Ainda mais valioso, o cálculo da quantidade de ruído adicionado pode ser feito sem conhecer o conteúdo do próprio banco de dados (ou mesmo o seu tamanho) . Ou seja, o cálculo com ruído pode ser realizado com base apenas no conhecimento da própria função, que é executada, e em um nível aceitável de vazamento de dados.A troca entre privacidade e precisão
Agora é óbvio que contar o número de fãs entre os usuários é um exemplo muito ruim. No caso do DP, é importante que a mesma abordagem geral possa ser aplicada a funções muito mais interessantes, incluindo cálculos estatísticos complexos, como os utilizados em sistemas de aprendizado de máquina. Pode ser aplicada mesmo que muitas funções diferentes sejam calculadas no mesmo banco de dados.Mas há um problema. O fato é que o tamanho do "vazamento de informações" de uma única solicitação pode ser minimizado dentro de pequenos limites, mas não será zero. Cada vez que você envia uma consulta a um banco de dados com alguma função, o "vazamento" total aumenta - e nunca pode ser reduzido. Com o tempo, à medida que o número de solicitações aumenta, o vazamento pode começar a crescer.Este é um dos aspectos mais difíceis da DP. Manifesta-se de duas maneiras principais:- Quanto mais você pretende "pedir" o banco de dados, mais ruído precisará adicionar para minimizar o vazamento de informações . Isso significa que o DP, de fato, é um compromisso fundamental entre precisão e proteção de dados pessoais, o que pode levar a um grande problema ao treinar modelos complexos de aprendizado de máquina.
- , . , , , — , . . .
A quantidade total de vazamentos permitidos é geralmente chamada de "orçamento de privacidade" e determina quantas solicitações podem ser feitas (e quão precisos serão os resultados). A principal lição do PD é que o diabo está escondido em um orçamento. Defina muito alto e dados importantes vazarão. Defina-o como muito baixo e os resultados da consulta podem ser inúteis.Agora, em alguns aplicativos, como a maioria dos aplicativos em nossos iPhones, a precisão insuficiente não se tornará um problema específico. Estamos acostumados ao fato de que nossos smartphones cometem erros. Porém, quando o DP é usado em aplicações complexas, como o treinamento de modelos de aprendizado de máquina, isso é realmente importante.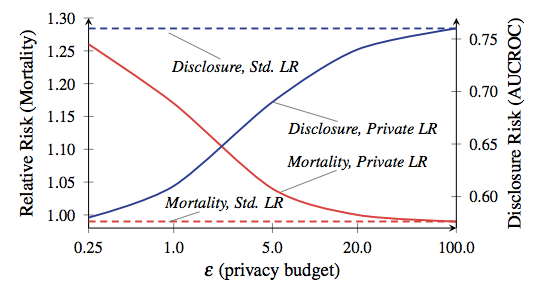 A razão de mortalidade e divulgação, do trabalho de Frederickson et al. A partir de 2014. A linha vermelha corresponde à mortalidade dos pacientes.Para dar um exemplo absolutamente louco de quão importante pode ser um compromisso entre privacidade e precisão, veja este artigo científico de 2014 de Frederickson et al . Os autores começaram correlacionando os dados de dosagem do medicamentonobanco de dados aberto Warfarin com marcadores genéticos específicos. Em seguida, eles aplicaram técnicas de aprendizado de máquina para desenvolver um modelo para calcular dosagens no banco de dados - mas usaram o DP com várias opções de orçamento de privacidade durante o treinamento do modelo. Em seguida, eles avaliaram o nível de vazamento de informações e o sucesso do uso do modelo para o tratamento de “pacientes” virtuais.Os resultados mostraram que a precisão do modelo depende fortemente do orçamento de privacidade estabelecido durante o treinamento. Se o orçamento for muito alto, uma quantidade significativa de informações confidenciais do paciente vazará do banco de dados - mas o modelo resultante toma decisões de dosagem tão seguras quanto a prática clínica padrão. Por outro lado, quando o orçamento é reduzido a um nível que significa privacidade aceitável, um modelo treinado em dados ruidosos tende a matar seus “pacientes”.Antes de começar a entrar em pânico, deixe-me explicar: seu iPhone não vai te matar. Ninguém diz que este exemplo é nem remotamente parecido com o que a Apple fará nos smartphones. A conclusão deste estudo reside simplesmente no fato de que existe um compromisso interessante entre eficiência e proteção da privacidade em cada sistema baseado em DP - esse compromisso depende em grande parte das decisões específicas tomadas pelos desenvolvedores do sistema, dos parâmetros operacionais selecionados etc. esperamos que a Apple em breve nos diga quais eram essas opções.
A razão de mortalidade e divulgação, do trabalho de Frederickson et al. A partir de 2014. A linha vermelha corresponde à mortalidade dos pacientes.Para dar um exemplo absolutamente louco de quão importante pode ser um compromisso entre privacidade e precisão, veja este artigo científico de 2014 de Frederickson et al . Os autores começaram correlacionando os dados de dosagem do medicamentonobanco de dados aberto Warfarin com marcadores genéticos específicos. Em seguida, eles aplicaram técnicas de aprendizado de máquina para desenvolver um modelo para calcular dosagens no banco de dados - mas usaram o DP com várias opções de orçamento de privacidade durante o treinamento do modelo. Em seguida, eles avaliaram o nível de vazamento de informações e o sucesso do uso do modelo para o tratamento de “pacientes” virtuais.Os resultados mostraram que a precisão do modelo depende fortemente do orçamento de privacidade estabelecido durante o treinamento. Se o orçamento for muito alto, uma quantidade significativa de informações confidenciais do paciente vazará do banco de dados - mas o modelo resultante toma decisões de dosagem tão seguras quanto a prática clínica padrão. Por outro lado, quando o orçamento é reduzido a um nível que significa privacidade aceitável, um modelo treinado em dados ruidosos tende a matar seus “pacientes”.Antes de começar a entrar em pânico, deixe-me explicar: seu iPhone não vai te matar. Ninguém diz que este exemplo é nem remotamente parecido com o que a Apple fará nos smartphones. A conclusão deste estudo reside simplesmente no fato de que existe um compromisso interessante entre eficiência e proteção da privacidade em cada sistema baseado em DP - esse compromisso depende em grande parte das decisões específicas tomadas pelos desenvolvedores do sistema, dos parâmetros operacionais selecionados etc. esperamos que a Apple em breve nos diga quais eram essas opções.De qualquer forma, como coletar dados?
Você notou que em todos os exemplos acima, assumi que as consultas são realizadas por um operador de banco de dados confiável que tem acesso a todos os dados subjacentes "brutos" originais. Eu escolhi esse modelo porque é uma versão tradicional do modelo usada em quase toda a literatura, e não porque é uma boa ideia.De fato, haverá motivo de alarme se a Apple realmente implementarseu sistema de maneira semelhante. Isso exigirá que a Apple colete todas as informações iniciais sobre as ações do usuário em um grande banco de dados centralizado e, em seguida (“confie em nós!”), Calcule as estatísticas sobre ele de uma maneira segura e proteja a privacidade do usuário. No mínimo, esse método disponibiliza informações para obtenção de intimação judicial, bem como para hackers estrangeiros, altos executivos curiosos da Apple e assim por diante.Felizmente, essa não é a única maneira de implementar um sistema diferencial de privacidade. Teoricamente, as estatísticas podem ser computadas usando técnicas criptográficas sofisticadas (como um protocolo de computação confidencial ou criptografia totalmente homomórfica) Infelizmente, essas técnicas são provavelmente ineficientes demais para serem usadas na escala que a Apple precisa.Uma abordagem muito mais promissora parece não ser a coleta de dados brutos . Essa abordagem foi recentemente a primeira dentre todas a usar o Google para coletar estatísticas no navegador Chrome . Seu sistema, chamado RAPPOR, é baseado em uma técnica de resposta aleatória de 50 anos . A resposta aleatória funciona da seguinte maneira:- ( : « Bing?»), , «», — . .
- ( , «»), «» .
Em um nível intuitivo, uma resposta aleatória protege a privacidade dos relatórios de usuários individuais, porque a resposta "sim" pode significar "Sim, eu uso o Bing" ou simplesmente ser o resultado de quedas aleatórias de moedas. No nível formal, uma resposta aleatória fornece privacidade diferenciada , com garantias específicas que podem ser personalizadas ajustando as características das moedas.O RAPPOR pega essa técnica relativamente antiga e a transforma em algo muito mais poderoso. Em vez de simplesmente responder a uma pergunta, o sistema pode compilar um relatório sobre um vetor complexo de perguntas e até mesmo retornar respostas complexas, como strings - por exemplo, qual é a sua página inicial no navegador. O último é alcançado para que a cadeia seja passada primeiro pelaFiltro Bloom - uma sequência de bits gerados usando funções hash de uma maneira muito específica. Os bits recebidos são então misturados ao ruído e somados, e as respostas são restauradas usando um processo de decodificação (bastante complexo). Embora não haja evidências claras de que a Apple use um sistema como o RAPPOR, algumas pequenas dicas apontam para isso. Por exemplo, Craig Federighi (na vida, ele se parece exatamente com a foto) descreve a privacidade diferenciada como “usar hash, subamostragem e ruído para ativar ... treinamento de crowdsourcing, mantendo os dados de usuários individuais completamente privados”. Provavelmente, isso é uma evidência fraca de qualquer coisa, mas a presença de "hash" nesta citação sugere pelo menos o uso de filtros no estilo RAPPOR.A principal dificuldade dos sistemas de resposta aleatória é que eles podem fornecer dados confidenciais se o usuário responder à mesma pergunta várias vezes. O RAPPOR tenta resolver esse problema de várias maneiras. Uma delas é determinar a parte estática da informação e, assim, calcular a "resposta permanente" em vez de repeti-la novamente a cada vez. Mas é possível imaginar situações em que essa proteção não funcione. Mais uma vez, o diabo geralmente se esconde nos detalhes - você só precisa vê-los. Estou certo de que muitos artigos científicos fascinantes serão publicados de qualquer maneira.
Embora não haja evidências claras de que a Apple use um sistema como o RAPPOR, algumas pequenas dicas apontam para isso. Por exemplo, Craig Federighi (na vida, ele se parece exatamente com a foto) descreve a privacidade diferenciada como “usar hash, subamostragem e ruído para ativar ... treinamento de crowdsourcing, mantendo os dados de usuários individuais completamente privados”. Provavelmente, isso é uma evidência fraca de qualquer coisa, mas a presença de "hash" nesta citação sugere pelo menos o uso de filtros no estilo RAPPOR.A principal dificuldade dos sistemas de resposta aleatória é que eles podem fornecer dados confidenciais se o usuário responder à mesma pergunta várias vezes. O RAPPOR tenta resolver esse problema de várias maneiras. Uma delas é determinar a parte estática da informação e, assim, calcular a "resposta permanente" em vez de repeti-la novamente a cada vez. Mas é possível imaginar situações em que essa proteção não funcione. Mais uma vez, o diabo geralmente se esconde nos detalhes - você só precisa vê-los. Estou certo de que muitos artigos científicos fascinantes serão publicados de qualquer maneira.Então, o uso do DP pela Apple é bom ou ruim?
Como cientista e especialista em segurança da informação, tenho sentimentos contraditórios sobre isso. Por um lado, como cientista, entendo como é interessante observar a implementação de desenvolvimentos científicos avançados em um produto real. E a Apple fornece uma plataforma muito grande para tais experimentos.Por outro lado, como especialista prático em segurança, é meu dever permanecer cético - a empresa deve, na menor dúvida, exibir um código crítico para a segurança (como o Google fez com o RAPPOR ), ou pelo menos declarar explicitamente o que implementa. Se a Apple planeja coletar grandes quantidades de novos dados de dispositivos dos quais tanto dependemos, devemos realmenteCertifique-se de que eles estão fazendo tudo certo - e não os aplaudam violentamente pela implementação de idéias tão legais. (Eu já cometi esse erro uma vez e ainda me sinto um tolo por causa disso).Mas talvez todos esses sejam detalhes muito profundos. No final, parece definitivamente que a Apple está honestamente tentando fazer algo para proteger as informações confidenciais dos usuários e, levando em conta alternativas, isso pode ser a coisa mais importante.