A rede neural de visão de máquina é treinada em jogos de computador realistas.
 Fotos do jogo de computador Grand Theft Auto V e marcação semântica para treinar umarede neural de visão de máquina As redes neurais estabelecem novos recordes em quase todas as competições de visão de computador e também são cada vez mais usadas em outras aplicações de IA. Um dos principais componentes desse desempenho incrível da rede neural é a disponibilidade de grandes conjuntos de dados para treinamento e avaliação. Por exemplo, o Desafio de reconhecimento visual de grande escala da Imagenet (ILSVRC), com mais de 1 milhão de imagens, é usado para avaliar redes neurais modernas. Mas, a julgar pelos resultados mais recentes (o ResNet mostra o resultado de apenas 3,57% dos erros), em breve os pesquisadores terão que compilar conjuntos de dados mais extensos. E então - ainda mais extenso. A propósito, anotar essas fotos é muito trabalhoso, parte do qual precisa ser feito manualmente.Alguns desenvolvedores de sistemas de visão por computador oferecem uma maneira alternativa de treinar e testar esses sistemas. Em vez de anotar fotos de treinamento manualmente, eles usam quadros sintetizados de jogos de computador realistas.Essa é uma abordagem completamente lógica. Nos jogos modernos, os gráficos atingiram um nível de realismo tão grande que as imagens sintetizadas são ligeiramente diferentes das fotografias do mundo real. Ao mesmo tempo, o mecanismo de jogo pode gerar um número infinito desses quadros - isso imediatamente resolve drasticamente o problema de coletar milhões de fotos para treinamento e avaliação da rede neural.Embora o mecanismo de jogo use um número finito de texturas, há uma grande variedade de combinações de ângulos de visão, iluminação, clima e nível de detalhe, o que fornece uma variedade suficiente de conjuntos de dados.Este ano, dois grupos de pesquisadores verificaram na prática se é possível usar os quadros gerados em jogos de computador para treinar redes neurais de visão computacional. Um grupo de pesquisadores do departamento de ciência da computação da Universidade da Colúmbia Britânica (Canadá) publicou um artigo científico para o qual foram coletados mais de 60.000 quadros de um jogo de computador com vistas da estrada semelhantes aos conjuntos de dados CamVid e Cityscapes . Os pesquisadores conseguiram provar que a rede neural após o treinamento em imagens sintéticas mostra um nível de erro semelhante ao após o treinamento em fotografias reais. Além disso, o treinamento em imagens sintetizadas usando fotos reais mostra um resultado ainda melhor.Todos os 60.000 quadros foram tirados em clima ensolarado virtual, no horário virtual às 11:00, com uma resolução de 1024 × 768 e configurações gráficas máximas (o nome do jogo não foi divulgado devido a preocupações com direitos autorais). Um veículo não tripulado acidentalmente dirigiu pelas ruas de jogos, observando as regras da estrada. Os quadros foram filmados uma vez por segundo. Cada um deles é acompanhado por segmentação semântica automática (céu, pedestre, carros, árvores, plano de fundo - a segmentação é absolutamente precisa e retirada do jogo), uma imagem profunda (imagem de profundidade, mapa com a marcação de objetos), bem como normais à superfície.Além do conjunto de dados básico do VG, os pesquisadores criaram outro conjunto de dados do VG + com muita informação semântica, não limitada a cinco rótulos - aqui a segmentação não é precisa. A marcação foi realizada automaticamente usando o SegNet .
Fotos do jogo de computador Grand Theft Auto V e marcação semântica para treinar umarede neural de visão de máquina As redes neurais estabelecem novos recordes em quase todas as competições de visão de computador e também são cada vez mais usadas em outras aplicações de IA. Um dos principais componentes desse desempenho incrível da rede neural é a disponibilidade de grandes conjuntos de dados para treinamento e avaliação. Por exemplo, o Desafio de reconhecimento visual de grande escala da Imagenet (ILSVRC), com mais de 1 milhão de imagens, é usado para avaliar redes neurais modernas. Mas, a julgar pelos resultados mais recentes (o ResNet mostra o resultado de apenas 3,57% dos erros), em breve os pesquisadores terão que compilar conjuntos de dados mais extensos. E então - ainda mais extenso. A propósito, anotar essas fotos é muito trabalhoso, parte do qual precisa ser feito manualmente.Alguns desenvolvedores de sistemas de visão por computador oferecem uma maneira alternativa de treinar e testar esses sistemas. Em vez de anotar fotos de treinamento manualmente, eles usam quadros sintetizados de jogos de computador realistas.Essa é uma abordagem completamente lógica. Nos jogos modernos, os gráficos atingiram um nível de realismo tão grande que as imagens sintetizadas são ligeiramente diferentes das fotografias do mundo real. Ao mesmo tempo, o mecanismo de jogo pode gerar um número infinito desses quadros - isso imediatamente resolve drasticamente o problema de coletar milhões de fotos para treinamento e avaliação da rede neural.Embora o mecanismo de jogo use um número finito de texturas, há uma grande variedade de combinações de ângulos de visão, iluminação, clima e nível de detalhe, o que fornece uma variedade suficiente de conjuntos de dados.Este ano, dois grupos de pesquisadores verificaram na prática se é possível usar os quadros gerados em jogos de computador para treinar redes neurais de visão computacional. Um grupo de pesquisadores do departamento de ciência da computação da Universidade da Colúmbia Britânica (Canadá) publicou um artigo científico para o qual foram coletados mais de 60.000 quadros de um jogo de computador com vistas da estrada semelhantes aos conjuntos de dados CamVid e Cityscapes . Os pesquisadores conseguiram provar que a rede neural após o treinamento em imagens sintéticas mostra um nível de erro semelhante ao após o treinamento em fotografias reais. Além disso, o treinamento em imagens sintetizadas usando fotos reais mostra um resultado ainda melhor.Todos os 60.000 quadros foram tirados em clima ensolarado virtual, no horário virtual às 11:00, com uma resolução de 1024 × 768 e configurações gráficas máximas (o nome do jogo não foi divulgado devido a preocupações com direitos autorais). Um veículo não tripulado acidentalmente dirigiu pelas ruas de jogos, observando as regras da estrada. Os quadros foram filmados uma vez por segundo. Cada um deles é acompanhado por segmentação semântica automática (céu, pedestre, carros, árvores, plano de fundo - a segmentação é absolutamente precisa e retirada do jogo), uma imagem profunda (imagem de profundidade, mapa com a marcação de objetos), bem como normais à superfície.Além do conjunto de dados básico do VG, os pesquisadores criaram outro conjunto de dados do VG + com muita informação semântica, não limitada a cinco rótulos - aqui a segmentação não é precisa. A marcação foi realizada automaticamente usando o SegNet . Quadros firmemente etiquetados do conjunto VG +Para comparar a eficácia do treinamento em rede neural, foram preparados conjuntos de dados CamVid e Cityscapes (cinco tags), bem como CamVid + e Cityscapes + com conjuntos de tags estendidos.
Quadros firmemente etiquetados do conjunto VG +Para comparar a eficácia do treinamento em rede neural, foram preparados conjuntos de dados CamVid e Cityscapes (cinco tags), bem como CamVid + e Cityscapes + com conjuntos de tags estendidos. Fotos originais do CamVid com anotações
Fotos originais do CamVid com anotações Foram usadas duas imagens aleatórias do Cityscapes + com anotações detalhadas.Paraa classificação semântica, foi utilizada uma rede neural convolucional longa com arquitetura FCN8 simples no topo da rede VGG de 16 camadas de Simonyan e Sisserman..Os pesquisadores realizaram vários experimentos para avaliar a eficiência do reconhecimento de objetos por uma rede neural treinada em diferentes conjuntos de dados. Em quase todos os casos, uma rede neural treinada em dados sintéticos mostrou um resultado melhor do que uma rede neural treinada em fotografias reais. Ela mostrou o melhor resultado, mesmo ao verificar fotos reais.Por exemplo, a tabela mostra o desempenho de redes neurais idênticas treinadas em três conjuntos de dados (fotos reais, dados sintéticos do jogo, conjunto misto) quando objetos são reconhecidos em fotos reais dos conjuntos CamVid + e Cityscapes +.
Foram usadas duas imagens aleatórias do Cityscapes + com anotações detalhadas.Paraa classificação semântica, foi utilizada uma rede neural convolucional longa com arquitetura FCN8 simples no topo da rede VGG de 16 camadas de Simonyan e Sisserman..Os pesquisadores realizaram vários experimentos para avaliar a eficiência do reconhecimento de objetos por uma rede neural treinada em diferentes conjuntos de dados. Em quase todos os casos, uma rede neural treinada em dados sintéticos mostrou um resultado melhor do que uma rede neural treinada em fotografias reais. Ela mostrou o melhor resultado, mesmo ao verificar fotos reais.Por exemplo, a tabela mostra o desempenho de redes neurais idênticas treinadas em três conjuntos de dados (fotos reais, dados sintéticos do jogo, conjunto misto) quando objetos são reconhecidos em fotos reais dos conjuntos CamVid + e Cityscapes +.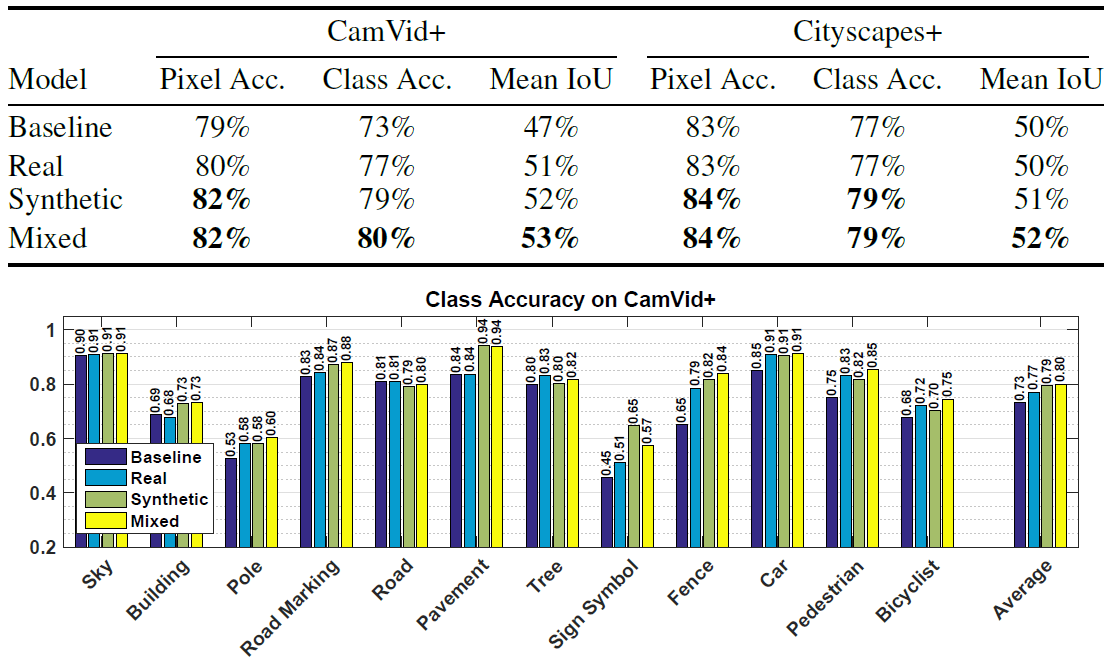 Como você pode ver, ao treinar uma rede neural, é melhor complementar as imagens sintéticas de um jogo de computador com fotografias reais.Artigo científicopublicada em 5 de agosto de 2016 no arXiv.org, a segunda versão é 15 de agosto ( pdf ).Além de pesquisadores da Universidade da Colúmbia Britânica, quase simultaneamente o mesmo trabalho foi realizado por outro grupo de cientistas da Universidade Técnica de Darmstadt (Alemanha) e do Intel Labs . Eles tiraram 24.966 quadros do jogo de computador em mundo aberto Grand Theft Auto V. para treinamento.Pesquisadores chegaram ao mesmo resultado: ao usar um conjunto de dados de treinamento composto por 2/3 de imagens sintéticas e 1/3 de fotos do CamVid, precisão o reconhecimento é maior do que apenas ao usar fotos do CamVid.
Como você pode ver, ao treinar uma rede neural, é melhor complementar as imagens sintéticas de um jogo de computador com fotografias reais.Artigo científicopublicada em 5 de agosto de 2016 no arXiv.org, a segunda versão é 15 de agosto ( pdf ).Além de pesquisadores da Universidade da Colúmbia Britânica, quase simultaneamente o mesmo trabalho foi realizado por outro grupo de cientistas da Universidade Técnica de Darmstadt (Alemanha) e do Intel Labs . Eles tiraram 24.966 quadros do jogo de computador em mundo aberto Grand Theft Auto V. para treinamento.Pesquisadores chegaram ao mesmo resultado: ao usar um conjunto de dados de treinamento composto por 2/3 de imagens sintéticas e 1/3 de fotos do CamVid, precisão o reconhecimento é maior do que apenas ao usar fotos do CamVid.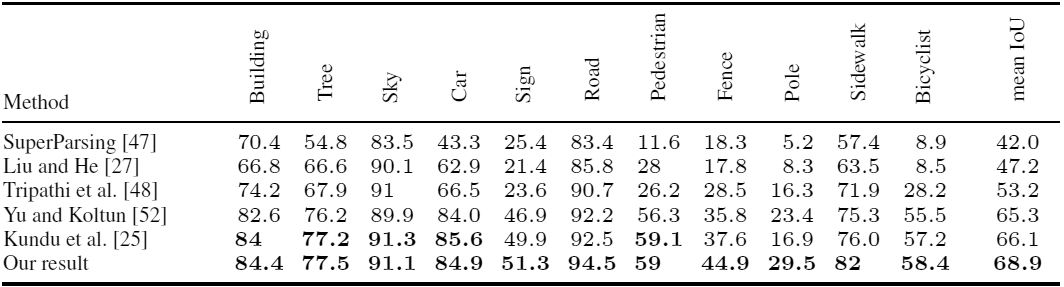 Precisão do reconhecimento de vários objetos nas fotos do conjunto CamVid ao aprender usando métodos convencionais e ao usar quadros do GTA V (linha inferior)Ao mesmo tempo, a anotação semi-automática em um editor especialmente desenvolvido reduz significativamente o tempo necessário para preparar um conjunto de dados para treinar uma rede neural. Por exemplo, fazer anotações em uma foto do CamVid leva 60 minutos, uma foto em Cityscapes leva 90 minutos e a anotação semi-automática do quadro GTA V leva apenas 7 segundos, em média ( vídeo, demonstração do editor ).O trabalho de pesquisadores da Universidade Técnica de Darmstadt e da Intel Labs foi preparado para a Conferência Europeia sobre Visão Computacional ECCV'16 (11 a 14 de outubro) e publicado no site da universidade. Os autores estabeleceram o código-fonte para a leitura de etiquetas e conjuntos completos de dados : fotografias de origem e imagens detalhadas com marcação semântica. O código-fonte do editor para anotação provavelmente será publicado no futuro.Graças ao progresso na criação de jogos de computador realistas, os desenvolvedores de sistemas de inteligência artificial terão à sua disposição uma excelente plataforma para o aprendizado de sistemas de visão de máquina. Esses sistemas serão utilizados em veículos não tripulados e robôs.Talvez jogos de computador possam ser usados não apenas para visão de máquina, mas também para criar padrões naturais de comportamento na sociedade. Somente com o treinamento em IA você deve ter cuidado ao escolher um jogo.
Precisão do reconhecimento de vários objetos nas fotos do conjunto CamVid ao aprender usando métodos convencionais e ao usar quadros do GTA V (linha inferior)Ao mesmo tempo, a anotação semi-automática em um editor especialmente desenvolvido reduz significativamente o tempo necessário para preparar um conjunto de dados para treinar uma rede neural. Por exemplo, fazer anotações em uma foto do CamVid leva 60 minutos, uma foto em Cityscapes leva 90 minutos e a anotação semi-automática do quadro GTA V leva apenas 7 segundos, em média ( vídeo, demonstração do editor ).O trabalho de pesquisadores da Universidade Técnica de Darmstadt e da Intel Labs foi preparado para a Conferência Europeia sobre Visão Computacional ECCV'16 (11 a 14 de outubro) e publicado no site da universidade. Os autores estabeleceram o código-fonte para a leitura de etiquetas e conjuntos completos de dados : fotografias de origem e imagens detalhadas com marcação semântica. O código-fonte do editor para anotação provavelmente será publicado no futuro.Graças ao progresso na criação de jogos de computador realistas, os desenvolvedores de sistemas de inteligência artificial terão à sua disposição uma excelente plataforma para o aprendizado de sistemas de visão de máquina. Esses sistemas serão utilizados em veículos não tripulados e robôs.Talvez jogos de computador possam ser usados não apenas para visão de máquina, mas também para criar padrões naturais de comportamento na sociedade. Somente com o treinamento em IA você deve ter cuidado ao escolher um jogo.Source: https://habr.com/ru/post/pt397557/
All Articles