Podemos abrir a caixa preta da inteligência artificial?
 Dean Pomerleau ainda se lembra da primeira vez que teve que lidar com o problema da caixa preta. Em 1991, ele fez uma das primeiras tentativas no campo que estão sendo estudadas por todos que estão tentando criar um carro robô: aprendendo a dirigir um computador.E isso significava que você precisava dirigir um Humvee especialmente preparado (veículo off-road do exército) e passear pelas ruas da cidade. É assim que Pomelo, então ex-aluno de robótica da Universidade Carnegie Mellon, fala sobre isso. Um computador programado para seguir através da câmera, interpretar o que está acontecendo na estrada e lembrar de todos os movimentos do motorista. Pomelo esperava que o carro acabasse por criar associações suficientes para uma direção independente.Para cada viagem, Pomelo treinou o sistema por vários minutos e, em seguida, deixou-o dirigir por conta própria. Tudo parecia estar indo bem - até que Humvee, tendo se aproximado da ponte, virou-se de repente para o lado. Um homem conseguiu evitar um acidente, agarrando rapidamente o volante e retornando o controle.No laboratório, Pomelo tentou descobrir um erro no computador. “Uma das tarefas do meu trabalho científico era abrir a 'caixa preta' e descobrir o que ele estava pensando”, explica ele. Mas como Ele programou o computador como uma "rede neural" - um tipo de inteligência artificial que imita o funcionamento do cérebro, prometendo ser melhor que os algoritmos padrão para lidar com situações complexas relacionadas ao mundo real. Infelizmente, essas redes são opacas como um cérebro real. Eles não armazenam tudo o que aprendemos em um bloco de memória organizado, mas espalham as informações para que seja muito difícil decifrar. Somente após uma ampla gama de testes de reação de software para vários parâmetros de entrada, Pomelo descobriu um problema: a rede usava grama ao longo das margens das estradas para determinar as direções e, portanto, a aparência da ponte a confundia.Após 25 anos, a decodificação de caixas pretas tornou-se exponencialmente mais difícil, aumentando a urgência dessa tarefa. Houve um aumento explosivo na complexidade e prevalência da tecnologia. Um pomelo, professor de robótica em período parcial na Carnegie Mellon, descreve seu sistema de longa data como uma “rede neural para os pobres”, em comparação com as enormes redes neurais vendidas em máquinas modernas. A técnica de aprendizado profundo (GI), na qual as redes treinam arquivos de "big data", encontra várias aplicações comerciais, de robomobiles a recomendações de produtos em sites com base no histórico de navegação.A tecnologia promete ser onipresente na ciência. Os futuros observatórios de rádio usarão o GO para procurar sinais significativos em matrizes de dados quecaso contrário, você não irá cobrar . Os detectores de ondas gravitacionais os usarão para entender e eliminar pequenos ruídos. Os editores os usarão para filtrar e etiquetar milhões de documentos e livros de pesquisa. Alguns acreditam que, eventualmente, os computadores com a ajuda do GO poderão demonstrar imaginação e habilidades criativas. "Você pode simplesmente inserir dados na máquina e ela retornará as leis da natureza para você", diz Jean-Roch Vlimant, físico do Instituto de Tecnologia da Califórnia.Mas esses avanços tornarão o problema da caixa preta ainda mais agudo. Como exatamente a máquina encontra sinais significativos? Como você pode ter certeza de que as conclusões dela estão corretas? Quanto as pessoas confiam no aprendizado profundo? "Acho que temos que ceder a esses algoritmos", diz o especialista em robótica Hod Lipson, da Columbia University, em Nova York. Ele compara a situação com uma reunião com alienígenas inteligentes cujos olhos vêem não apenas vermelho, verde e azul, mas também a quarta cor. Segundo ele, será muito difícil para as pessoas entenderem como esses alienígenas vêem o mundo, e para elas nos explicarem. Os computadores terão os mesmos problemas para explicar suas decisões, diz ele. "Em algum momento, começará a se parecer com tentativas de explicar Shakespeare ao cachorro."Tendo encontrado tais problemas, os pesquisadores de IA reagem da mesma maneira que Pomelo - eles abrem uma caixa preta e executam ações semelhantes à neurologia para entender o funcionamento das redes. As respostas não são intuitivas, diz Vincenzo Innocente, físico do CERN que foi o primeiro a usar a IA em seu campo. “Como cientista, não estou satisfeito com a simples capacidade de distinguir cães de gatos. Um cientista deve ser capaz de dizer: a diferença é isso e aquilo. ”
Dean Pomerleau ainda se lembra da primeira vez que teve que lidar com o problema da caixa preta. Em 1991, ele fez uma das primeiras tentativas no campo que estão sendo estudadas por todos que estão tentando criar um carro robô: aprendendo a dirigir um computador.E isso significava que você precisava dirigir um Humvee especialmente preparado (veículo off-road do exército) e passear pelas ruas da cidade. É assim que Pomelo, então ex-aluno de robótica da Universidade Carnegie Mellon, fala sobre isso. Um computador programado para seguir através da câmera, interpretar o que está acontecendo na estrada e lembrar de todos os movimentos do motorista. Pomelo esperava que o carro acabasse por criar associações suficientes para uma direção independente.Para cada viagem, Pomelo treinou o sistema por vários minutos e, em seguida, deixou-o dirigir por conta própria. Tudo parecia estar indo bem - até que Humvee, tendo se aproximado da ponte, virou-se de repente para o lado. Um homem conseguiu evitar um acidente, agarrando rapidamente o volante e retornando o controle.No laboratório, Pomelo tentou descobrir um erro no computador. “Uma das tarefas do meu trabalho científico era abrir a 'caixa preta' e descobrir o que ele estava pensando”, explica ele. Mas como Ele programou o computador como uma "rede neural" - um tipo de inteligência artificial que imita o funcionamento do cérebro, prometendo ser melhor que os algoritmos padrão para lidar com situações complexas relacionadas ao mundo real. Infelizmente, essas redes são opacas como um cérebro real. Eles não armazenam tudo o que aprendemos em um bloco de memória organizado, mas espalham as informações para que seja muito difícil decifrar. Somente após uma ampla gama de testes de reação de software para vários parâmetros de entrada, Pomelo descobriu um problema: a rede usava grama ao longo das margens das estradas para determinar as direções e, portanto, a aparência da ponte a confundia.Após 25 anos, a decodificação de caixas pretas tornou-se exponencialmente mais difícil, aumentando a urgência dessa tarefa. Houve um aumento explosivo na complexidade e prevalência da tecnologia. Um pomelo, professor de robótica em período parcial na Carnegie Mellon, descreve seu sistema de longa data como uma “rede neural para os pobres”, em comparação com as enormes redes neurais vendidas em máquinas modernas. A técnica de aprendizado profundo (GI), na qual as redes treinam arquivos de "big data", encontra várias aplicações comerciais, de robomobiles a recomendações de produtos em sites com base no histórico de navegação.A tecnologia promete ser onipresente na ciência. Os futuros observatórios de rádio usarão o GO para procurar sinais significativos em matrizes de dados quecaso contrário, você não irá cobrar . Os detectores de ondas gravitacionais os usarão para entender e eliminar pequenos ruídos. Os editores os usarão para filtrar e etiquetar milhões de documentos e livros de pesquisa. Alguns acreditam que, eventualmente, os computadores com a ajuda do GO poderão demonstrar imaginação e habilidades criativas. "Você pode simplesmente inserir dados na máquina e ela retornará as leis da natureza para você", diz Jean-Roch Vlimant, físico do Instituto de Tecnologia da Califórnia.Mas esses avanços tornarão o problema da caixa preta ainda mais agudo. Como exatamente a máquina encontra sinais significativos? Como você pode ter certeza de que as conclusões dela estão corretas? Quanto as pessoas confiam no aprendizado profundo? "Acho que temos que ceder a esses algoritmos", diz o especialista em robótica Hod Lipson, da Columbia University, em Nova York. Ele compara a situação com uma reunião com alienígenas inteligentes cujos olhos vêem não apenas vermelho, verde e azul, mas também a quarta cor. Segundo ele, será muito difícil para as pessoas entenderem como esses alienígenas vêem o mundo, e para elas nos explicarem. Os computadores terão os mesmos problemas para explicar suas decisões, diz ele. "Em algum momento, começará a se parecer com tentativas de explicar Shakespeare ao cachorro."Tendo encontrado tais problemas, os pesquisadores de IA reagem da mesma maneira que Pomelo - eles abrem uma caixa preta e executam ações semelhantes à neurologia para entender o funcionamento das redes. As respostas não são intuitivas, diz Vincenzo Innocente, físico do CERN que foi o primeiro a usar a IA em seu campo. “Como cientista, não estou satisfeito com a simples capacidade de distinguir cães de gatos. Um cientista deve ser capaz de dizer: a diferença é isso e aquilo. ”Passeio agradável
A primeira rede neural foi criada no início dos anos 50, quase imediatamente após o advento de computadores capazes de trabalhar de acordo com os algoritmos necessários. A idéia é emular a operação de pequenos módulos contáveis - neurônios - dispostos em camadas e conectados a "sinapses" digitais. Cada módulo na camada inferior recebe dados externos, por exemplo, pixels da imagem e depois espalha essas informações para alguns dos módulos da próxima camada. Cada módulo na segunda camada integra a entrada da primeira camada de acordo com uma regra matemática simples e transmite o resultado. Como resultado, a camada superior fornece uma resposta - por exemplo, atribui a imagem original a "gatos" ou "cães".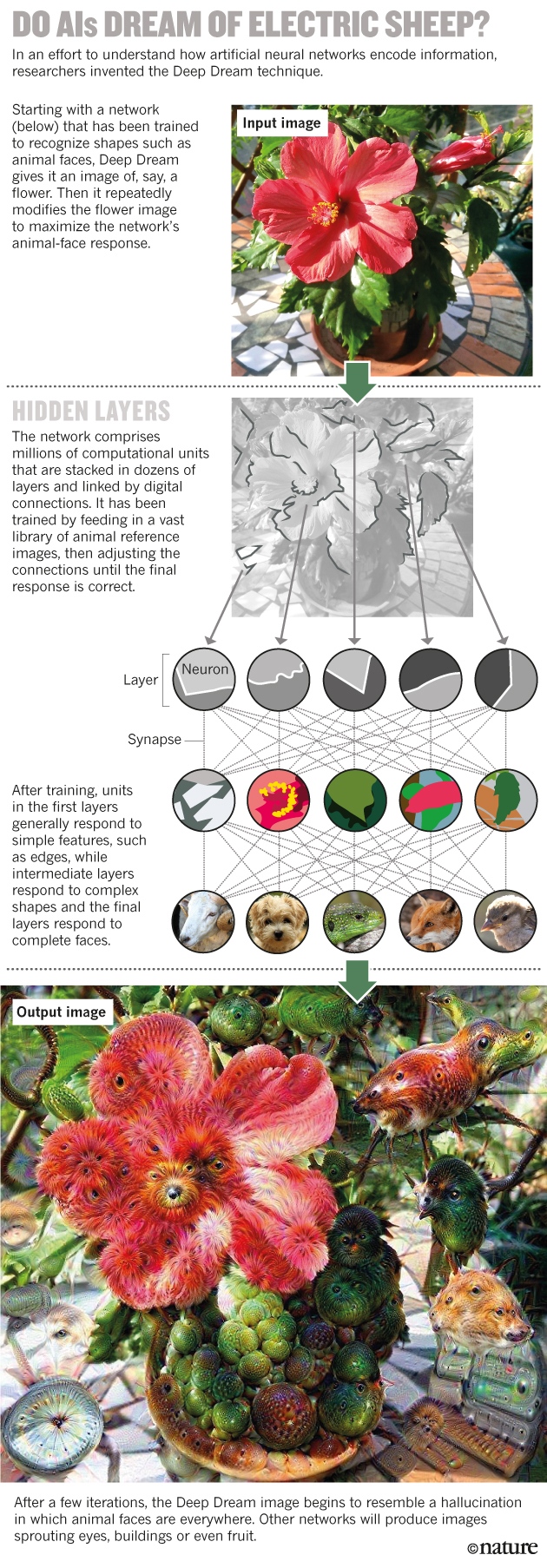 ? « » (Deep Dream) , , , , – , .
? « » (Deep Dream) , , , , – , .
, – , .
Deep Dream .Os recursos de tais redes decorrem de sua capacidade de aprender. Aprendendo com o conjunto de dados inicial com as respostas corretas fornecidas, eles melhoram gradualmente suas características, ajustando a influência de todos os links para produzir os resultados corretos. O processo emula o treinamento do cérebro, o que fortalece e enfraquece as sinapses e fornece uma saída de rede capaz de classificar dados que não foram originalmente incluídos no conjunto de treinamento.A possibilidade de treinar seduziu físicos do CERN nos anos 90, quando foram os primeiros a adaptar grandes redes neurais ao trabalho científico. As redes neurais ajudaram muito na reconstrução das trajetórias dos estilhaços subatômicos, espalhando-se para os lados em colisões de partículas no Large Hadron Collider.Essa forma de treinamento também é a razão pela qual a informação é muito espalhada pela rede: como no cérebro, sua memória é codificada na força de vários compostos e não é armazenada em determinados lugares, como em um banco de dados familiar. “Onde está o primeiro dígito do seu número de telefone armazenado no seu cérebro? Talvez no conjunto das sinapses, talvez não muito longe do resto dos números ”, disse Pierre Baldi, especialista em aprendizado de máquina (MO) da Universidade da Califórnia. Mas não há uma sequência definida de bits que codifica o número. Como resultado, como afirma o especialista em TI Jeff Clune, da Universidade de Wyoming, "apesar de criarmos essas redes, não podemos entendê-las melhor do que o cérebro humano".Para cientistas que trabalham com big data, isso significa que o GO deve ser usado com cuidado. Andrea Vedaldi, especialista em informática da Universidade de Oxford, explica: Imagine que, no futuro, a rede neural será treinada em mamografias para indicar se o câncer de mama está sendo estudado nas mulheres estudadas. Depois disso, suponha que os tecidos de uma mulher saudável pareçam ser suscetíveis a doenças. "A rede neural pode aprender a reconhecer marcadores tumorais - aqueles que não conhecemos, mas que podem prever câncer".Mas se a máquina não puder explicar como a determina, então, de acordo com Vedaldi, esse será um dilema sério para médicos e pacientes. Não é fácil para uma mulher se submeter à remoção preventiva da mama devido à presença de características genéticas que podem levar ao câncer. E fazer essa escolha será ainda mais difícil, porque nem se saberá qual é esse fator - mesmo que as previsões da máquina sejam precisas."O problema é que o conhecimento está incorporado na rede, não em nós", diz Michael Tyka, biofísico e programador do Google. “Nós entendemos alguma coisa? Não - esta é a rede entendida. ”Vários grupos de cientistas abordaram o problema da caixa preta em 2012. Uma equipe liderada por Geoffrey Hinton, especialista em MO da Universidade de Toronto, participou de um concurso de visão computacional e, pela primeira vez, demonstrou que o uso do GO para classificar fotografias de um banco de dados de 1,2 milhão de imagens superou qualquer outra abordagem. usando AI.Entendendo como isso é possível, o grupo Vedaldi pegou os algoritmos de Hinton projetados para melhorar a rede neural e os retrocedeu. Em vez de treinar a rede para interpretar corretamente a resposta, a equipe pegou redes pré-treinadas e tentou recriar as imagens, graças às quais treinou. Isso ajudou os pesquisadores a determinar como a máquina apresenta alguns dos recursos - era como se eles estivessem perguntando algum tipo de rede neural hipotética que prediz câncer: "Que parte da mamografia levou você à marca de risco de câncer?"Taika e seus colegas do Google usaram uma abordagem semelhante no ano passado. O algoritmo deles, que eles chamaram de Sonho Profundo, começa com uma imagem, digamos, de uma flor, e a modifica para melhorar a resposta de um neurônio de nível superior específico. Se um neurônio gosta de marcar imagens de, digamos, pássaros, então a imagem alterada começará a mostrar pássaros em todos os lugares. As imagens resultantes lembram visões sob LSD, onde os pássaros são visíveis em rostos, edifícios e muito mais. "Eu acho que isso é muito parecido com uma alucinação", diz Taika, que também é artista. Quando ele e seus colegas viram o potencial do algoritmo no campo criativo, eles decidiram torná-lo gratuito para download. Dentro de alguns dias, esse tópico se tornou viral.Usando técnicas que maximizam a produção de qualquer neurônio, e não apenas um dos principais, a equipe de Klun em 2014 descobriu que o problema da caixa preta poderia ser mais complicado do que parecia antes. As redes neurais são muito fáceis de enganar com a ajuda de imagens percebidas pelas pessoas como ruído aleatório ou padrões abstratos. Por exemplo, uma rede pode pegar linhas onduladas e decidir que é uma estrela do mar ou misturar listras em preto e branco com um ônibus escolar. Além disso, as mesmas tendências surgiram em redes treinadas em outros conjuntos de dados.Os pesquisadores sugeriram várias soluções para o problema de enganar as redes, mas ainda não foi encontrada uma solução geral. Em aplicações reais, isso pode ser perigoso. Um dos cenários assustadores, segundo Clun, é que os hackers aprendem a tirar proveito dessas falhas de rede. Eles podem enviar o robomóvel para um outdoor que levará para a estrada ou enganar o scanner de retina na entrada da Casa Branca. "Precisamos arregaçar as mangas e realizar pesquisas científicas profundas para tornar o MO mais confiável e inteligente", conclui Klyun.Tais problemas levaram alguns cientistas da computação a pensar que você não deveria se concentrar apenas nas redes neurais. Zoubin Ghahramani, pesquisador de MO da Universidade de Cambridge, diz que se a IA tiver que dar respostas que as pessoas possam interpretar facilmente, isso levará a "muitos problemas com os quais o GO não pode ajudar a lidar". Uma abordagem científica razoavelmente compreensível foi mostrada pela primeira vez em 2009 por Lipson e pelo biólogo computacional Michael Schmidt, que trabalhava na Cornell University. Seu algoritmo Eureqa demonstrou o processo de redescoberta das leis de Newton observando um simples objeto mecânico - um sistema de pêndulos - em movimento.Começando com uma combinação aleatória de tijolos matemáticos como +, -, seno e cosseno, o Eureqa o altera por tentativa e erro, semelhante à evolução darwiniana, até chegar às fórmulas que descrevem esses dados. Ela então oferece experimentos para testar modelos. Um de seus benefícios é a simplicidade, diz Lipson. “Um modelo desenvolvido pela Eureqa geralmente possui uma dúzia de parâmetros. A rede neural tem milhões deles. ”No piloto automático
No ano passado, Garakhmani publicou um algoritmo para automatizar o trabalho de um cientista de acordo com os dados, desde dados brutos até trabalhos científicos concluídos. Seu software Automatic Statistician, observa tendências e anomalias nos conjuntos de dados e fornece uma opinião, incluindo uma explicação detalhada do raciocínio. Essa transparência, disse ele, é "completamente crítica" para uso na ciência, mas também importante para uso comercial. Por exemplo, em muitos países, os bancos que recusam empréstimos são legalmente obrigados a explicar o motivo da recusa - e isso pode não ser possível com o algoritmo GO.Diferentes organizações têm as mesmas dúvidas, explica Ellie Dobson, diretora de ciência de dados da Arundo Analytics em Oslo. Se, por exemplo, algo der errado na Grã-Bretanha devido a uma alteração na taxa básica, o Banco da Inglaterra não pode simplesmente dizer "é tudo por causa da caixa preta".Mas, apesar de todos esses medos, os cientistas da computação dizem que as tentativas de criar uma IA transparente devem ser um complemento à defesa civil, e não um substituto para essa tecnologia. Algumas técnicas transparentes podem funcionar bem em áreas já descritas como um conjunto de dados abstratos, mas não lidam com a percepção - o processo de extrair fatos de dados brutos.Como resultado, segundo eles, as respostas complexas recebidas graças ao Ministério da Defesa devem fazer parte das ferramentas da ciência, uma vez que o mundo real é complexo. Para fenômenos como o clima ou o mercado financeiro, descrições reducionistas e sintéticas podem simplesmente não existir. "Há coisas que não podem ser descritas em palavras", diz Stephane Mallat, matemático aplicado na Politécnica de Paris. "Quando você pergunta a um médico por que ele fez esse diagnóstico, ele descreverá os motivos para você", diz ele. - Mas por que você precisa de 20 anos para se tornar um bom médico? Porque a informação é obtida não apenas dos livros. ”Segundo Baldi, o cientista deve aceitar o GO e não se deixar levar pelas caixas pretas. Eles têm uma caixa preta na cabeça. "Você usa constantemente o cérebro, sempre confia nele e não entende como ele funciona".Source: https://habr.com/ru/post/pt398451/
All Articles