"Photoshop" para fala humana
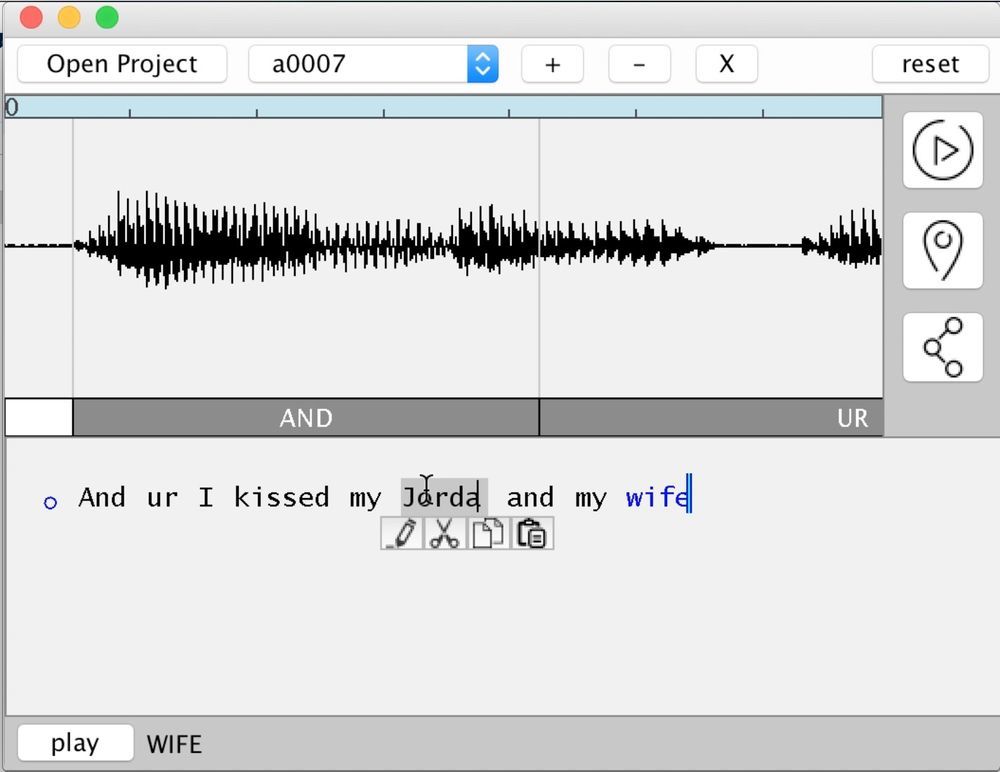 Em 3 de novembro de 2016, na conferência de tecnologia Adobe MAX, a Adobe apresentou um desenvolvimento científico e técnico muito interessante, que no futuro poderá se transformar em um aplicativo de software popular. Em resumo, a invenção é um programa para edição semântica da fala humana. Nesse caso, não apenas o método padrão de síntese de fonemas coletados (síntese de compilação) é usado, mas também métodos auxiliares que aumentam o realismo. Esta é uma escolha inteligente de trifons e o uso das características específicas da voz de amostra.Como resultado, o usuário escreve texto arbitrário - e o programa o expressa com a voz em que foi treinado. Você pode adicionar rapidamente quaisquer palavras ao discurso ou cortar palavras desnecessárias.Na prática, o programa apresentado como parte do projeto VoCo funciona da seguinte maneira. Primeiro, a base do fonema é montada para a voz de uma pessoa em particular em um idioma específico. Para resultados realistas, o programa precisa de um mínimo de 20 minutos de fala humana. Quanto mais, melhor. Com base nos fonemas coletados (trifons), o programa pode coletar quase todas as novas palavras como se fossem tijolos.Fragmento da apresentação da VoCo na conferência MAXDe certa forma, o VoCo funciona como o trabalho de um pincel de contexto no Photoshop. Ela também pega fragmentos de diferentes lugares da imagem - e coleta uma nova imagem desses fragmentos. Um pedaço de madeira de uma fotografia da floresta, um pedaço de grama de outra foto e uma garota da terceira fotografia - e recebemos um trabalho fotorrealista completamente novo com uma floresta, grama e uma garota em primeiro plano. Se o trabalho for feito profissionalmente, é muito difícil determinar a instalação. Assim, nos tempos soviéticos , as pessoas que de repente se tornaram inimigos do povo foram apagadas da história . Havia uma pessoa na fotografia - e agora há um vazio ou outra pessoa.Portanto, a tecnologia VoCo permite complementar a fala humana com palavras e frases arbitrárias.Na conferência MAX, um dos desenvolvedores, Zeyu Jin, fez uma apresentação. Em um artigo científico publicado anteriormente , ele é listado como funcionário da Universidade de Princeton, juntamente com o colega Adam Finkelstein. A tecnologia foi desenvolvida pela Adobe Research em colaboração com a Universidade de Princeton.Conforme concebida pela Adobe, a tecnologia ajudará os criadores de conteúdo a editar com mais facilidade a trilha de áudio: diálogos e texto de narração para corrigir rapidamente um erro ou fazer alterações na história.A Adobe enfatiza que, neste caso, é mais apropriado falar sobre "conversão de voz" do que na síntese de voz clássica. O objetivo da conversão de voz é transformar a voz original para que, para o ouvinte, pareça ser a voz de outra pessoa, seguindo o modelo da voz desta última.Os fundamentos técnicos da conversão de voz são descritos em mais detalhes no trabalho científico acima mencionado .preparado em conjunto com a Universidade de Princeton. Seus autores mostram que a técnica CUTE desenvolvida é qualitativamente superior a outros métodos de conversão de voz. Métodos de conversão alternativos geralmente são baseados na análise paralela de frases idênticas da origem e do destino, seguidas pelo cálculo de certos vetores de transformação em qualquer espaço de endereço. Depois disso, qualquer fragmento arbitrário da voz original pode ser transformado usando os vetores obtidos. Mas esses métodos sofrem efeitos colaterais desagradáveis - o discurso sintetizado dessa maneira é surdo, arrastado.Os pesquisadores da Adobe foram capazes de superar as deficiências de outras técnicas usando o método híbrido CUTE. O título criptografa os quatro principais componentes dessa técnica: síntese de compilação (síntese concatenativa); seleção de unidade; seleção preliminar de trifons, ou seja, unidades de três fonemas (pré-seleção Triphone); Usando propriedades de amostra (recursos baseados em exemplos).A síntese de compilação é reduzida a compor uma mensagem de um dicionário pré-gravado de fonemas. Este é o principal método de trabalho com sintetizadores de fala, equipados com vários dispositivos: de aeronaves militares a dispositivos domésticos, nos serviços de ajuda de operadoras de telefonia móvel etc.Como o nome indica, a técnica híbrida desenvolvida combina vários métodos de síntese de fala e conversão de voz.O trabalho científico apresenta os resultados de testes comparativos com outros métodos de conversão de voz, nos quais o CUTE é significativamente superior aos concorrentes. Ao mesmo tempo, são mencionadas algumas de suas deficiências: ele, como todo mundo, sofre com um número insuficiente de fonemas no banco de dados ao sintetizar novas palavras, o que gera resultados foneticamente correctos, mas não muito realistas. Além disso, depende da operação do mecanismo de reconhecimento de fala para a correta segmentação fonética.Ainda não se sabe se a Adobe implementará esse desenvolvimento promissor na forma de um produto comercial real. Mas agora podemos dizer que esse programa se tornaria muito popular, desde que a síntese da voz a partir dos fonemas seja realista. Por exemplo, podcasters poderiam usá-lo para gerar podcasts a partir de texto. Também pode ser usado para expressar livros de áudio usando a voz de uma pessoa arbitrária (por exemplo, sua própria garota). É provável que essa tecnologia encontre aplicação em Hollywood para dublagem na ausência de um ator. Por exemplo, se um contrato foi quebrado com ele ou ele morreu no meio das filmagens.
Em 3 de novembro de 2016, na conferência de tecnologia Adobe MAX, a Adobe apresentou um desenvolvimento científico e técnico muito interessante, que no futuro poderá se transformar em um aplicativo de software popular. Em resumo, a invenção é um programa para edição semântica da fala humana. Nesse caso, não apenas o método padrão de síntese de fonemas coletados (síntese de compilação) é usado, mas também métodos auxiliares que aumentam o realismo. Esta é uma escolha inteligente de trifons e o uso das características específicas da voz de amostra.Como resultado, o usuário escreve texto arbitrário - e o programa o expressa com a voz em que foi treinado. Você pode adicionar rapidamente quaisquer palavras ao discurso ou cortar palavras desnecessárias.Na prática, o programa apresentado como parte do projeto VoCo funciona da seguinte maneira. Primeiro, a base do fonema é montada para a voz de uma pessoa em particular em um idioma específico. Para resultados realistas, o programa precisa de um mínimo de 20 minutos de fala humana. Quanto mais, melhor. Com base nos fonemas coletados (trifons), o programa pode coletar quase todas as novas palavras como se fossem tijolos.Fragmento da apresentação da VoCo na conferência MAXDe certa forma, o VoCo funciona como o trabalho de um pincel de contexto no Photoshop. Ela também pega fragmentos de diferentes lugares da imagem - e coleta uma nova imagem desses fragmentos. Um pedaço de madeira de uma fotografia da floresta, um pedaço de grama de outra foto e uma garota da terceira fotografia - e recebemos um trabalho fotorrealista completamente novo com uma floresta, grama e uma garota em primeiro plano. Se o trabalho for feito profissionalmente, é muito difícil determinar a instalação. Assim, nos tempos soviéticos , as pessoas que de repente se tornaram inimigos do povo foram apagadas da história . Havia uma pessoa na fotografia - e agora há um vazio ou outra pessoa.Portanto, a tecnologia VoCo permite complementar a fala humana com palavras e frases arbitrárias.Na conferência MAX, um dos desenvolvedores, Zeyu Jin, fez uma apresentação. Em um artigo científico publicado anteriormente , ele é listado como funcionário da Universidade de Princeton, juntamente com o colega Adam Finkelstein. A tecnologia foi desenvolvida pela Adobe Research em colaboração com a Universidade de Princeton.Conforme concebida pela Adobe, a tecnologia ajudará os criadores de conteúdo a editar com mais facilidade a trilha de áudio: diálogos e texto de narração para corrigir rapidamente um erro ou fazer alterações na história.A Adobe enfatiza que, neste caso, é mais apropriado falar sobre "conversão de voz" do que na síntese de voz clássica. O objetivo da conversão de voz é transformar a voz original para que, para o ouvinte, pareça ser a voz de outra pessoa, seguindo o modelo da voz desta última.Os fundamentos técnicos da conversão de voz são descritos em mais detalhes no trabalho científico acima mencionado .preparado em conjunto com a Universidade de Princeton. Seus autores mostram que a técnica CUTE desenvolvida é qualitativamente superior a outros métodos de conversão de voz. Métodos de conversão alternativos geralmente são baseados na análise paralela de frases idênticas da origem e do destino, seguidas pelo cálculo de certos vetores de transformação em qualquer espaço de endereço. Depois disso, qualquer fragmento arbitrário da voz original pode ser transformado usando os vetores obtidos. Mas esses métodos sofrem efeitos colaterais desagradáveis - o discurso sintetizado dessa maneira é surdo, arrastado.Os pesquisadores da Adobe foram capazes de superar as deficiências de outras técnicas usando o método híbrido CUTE. O título criptografa os quatro principais componentes dessa técnica: síntese de compilação (síntese concatenativa); seleção de unidade; seleção preliminar de trifons, ou seja, unidades de três fonemas (pré-seleção Triphone); Usando propriedades de amostra (recursos baseados em exemplos).A síntese de compilação é reduzida a compor uma mensagem de um dicionário pré-gravado de fonemas. Este é o principal método de trabalho com sintetizadores de fala, equipados com vários dispositivos: de aeronaves militares a dispositivos domésticos, nos serviços de ajuda de operadoras de telefonia móvel etc.Como o nome indica, a técnica híbrida desenvolvida combina vários métodos de síntese de fala e conversão de voz.O trabalho científico apresenta os resultados de testes comparativos com outros métodos de conversão de voz, nos quais o CUTE é significativamente superior aos concorrentes. Ao mesmo tempo, são mencionadas algumas de suas deficiências: ele, como todo mundo, sofre com um número insuficiente de fonemas no banco de dados ao sintetizar novas palavras, o que gera resultados foneticamente correctos, mas não muito realistas. Além disso, depende da operação do mecanismo de reconhecimento de fala para a correta segmentação fonética.Ainda não se sabe se a Adobe implementará esse desenvolvimento promissor na forma de um produto comercial real. Mas agora podemos dizer que esse programa se tornaria muito popular, desde que a síntese da voz a partir dos fonemas seja realista. Por exemplo, podcasters poderiam usá-lo para gerar podcasts a partir de texto. Também pode ser usado para expressar livros de áudio usando a voz de uma pessoa arbitrária (por exemplo, sua própria garota). É provável que essa tecnologia encontre aplicação em Hollywood para dublagem na ausência de um ator. Por exemplo, se um contrato foi quebrado com ele ou ele morreu no meio das filmagens.Source: https://habr.com/ru/post/pt398865/
All Articles