Rede neural LipNet lê lábios com uma precisão de 93,4%
 O comandante Dave Bowman e o co-piloto Frank Poole, não confiando no computador, decidiram desconectá-lo do controle do navio. Para fazer isso, eles conferem em uma sala à prova de som, mas o HAL 9000 lê a conversa nos lábios. Filmado a partir do filme “Odisséia no Espaço de 2001” Aleitura labial desempenha um papel importante na comunicação. Mais experimentos em 1976 mostraram que as pessoas “ouvem” fonemas completamente diferentes se você aplicar o som errado ao movimento dos lábios (consulte "Ouvindo lábios e vendo vozes" , Nature 264, 746-748, 23 de dezembro de 1976, doi: 10.1038 / 264746a0) .Do ponto de vista prático, a leitura labial é uma habilidade importante e útil. Você pode entender o interlocutor sem desligar a música nos fones de ouvido, ler as conversas de todas as pessoas no campo de visão (por exemplo, todos os passageiros na sala de espera), ouvir as pessoas através de binóculos ou telescópio. O escopo da habilidade é muito amplo. Um profissional que a domina encontrará facilmente um emprego bem remunerado. Por exemplo, no campo da segurança ou inteligência competitiva.Os sistemas automáticos de leitura labial também têm um grande potencial prático. São os aparelhos auditivos médicos de nova geração com reconhecimento de fala, sistemas para palestras silenciosas em locais públicos, identificação biométrica, sistemas para transmissão secreta de informações para espionagem, reconhecimento de fala por vídeo de câmeras de vigilância, etc. No final, os computadores do futuro também lerão lábios, como o HAL 9000 .Portanto, os cientistas tentam há muitos anos desenvolver sistemas automáticos de leitura labial, mas sem muito sucesso. Mesmo para o inglês relativamente simples, em que o número de fonemas é muito menor que o russo, a precisão do reconhecimento é baixa.Compreender a fala com base em expressões faciais humanas é uma tarefa assustadora. As pessoas que dominam essa habilidade tentam reconhecer dezenas de fonemas consoantes, muitos dos quais têm aparência muito semelhante. É especialmente difícil para uma pessoa não treinada distinguir entre cinco categorias de fonemas visuais (isto é, visemes) do idioma inglês. Em outras palavras, distinguir a pronúncia de algumas consoantes pelos lábios é quase impossível. Não é de surpreender que as pessoas se saiam muito mal com a leitura exata dos lábios. Mesmo os melhores das pessoas com deficiência auditiva demonstram precisão de apenas 17 ± 12% de 30 monossílabos ou 21 ± 11% de palavras polissilábicas (daqui em diante os resultados para o idioma inglês).A leitura automática dos lábios é uma das tarefas da visão de máquina, que se resume ao processamento quadro a quadro de uma sequência de vídeo. A tarefa é muito complicada pela baixa qualidade da maioria dos materiais de vídeo práticos, que não permitem uma leitura precisa do espaço-temporal, isto é, das características espaço-temporais de uma pessoa durante uma conversa. Os rostos se movem e giram em direções diferentes. Desenvolvimentos recentes no campo da visão de máquina estão tentando rastrear o movimento da face no quadro para resolver esse problema. Apesar dos sucessos, até recentemente, eles eram capazes de reconhecer apenas palavras individuais, mas não sentenças.Um avanço significativo nessa área foi alcançado pelos desenvolvedores da Universidade de Oxford. O LipNet que eles treinaramtornou-se o primeiro do mundo a reconhecer com êxito os lábios no nível de frases inteiras, processando imagens de vídeo. Mapas de saliência
O comandante Dave Bowman e o co-piloto Frank Poole, não confiando no computador, decidiram desconectá-lo do controle do navio. Para fazer isso, eles conferem em uma sala à prova de som, mas o HAL 9000 lê a conversa nos lábios. Filmado a partir do filme “Odisséia no Espaço de 2001” Aleitura labial desempenha um papel importante na comunicação. Mais experimentos em 1976 mostraram que as pessoas “ouvem” fonemas completamente diferentes se você aplicar o som errado ao movimento dos lábios (consulte "Ouvindo lábios e vendo vozes" , Nature 264, 746-748, 23 de dezembro de 1976, doi: 10.1038 / 264746a0) .Do ponto de vista prático, a leitura labial é uma habilidade importante e útil. Você pode entender o interlocutor sem desligar a música nos fones de ouvido, ler as conversas de todas as pessoas no campo de visão (por exemplo, todos os passageiros na sala de espera), ouvir as pessoas através de binóculos ou telescópio. O escopo da habilidade é muito amplo. Um profissional que a domina encontrará facilmente um emprego bem remunerado. Por exemplo, no campo da segurança ou inteligência competitiva.Os sistemas automáticos de leitura labial também têm um grande potencial prático. São os aparelhos auditivos médicos de nova geração com reconhecimento de fala, sistemas para palestras silenciosas em locais públicos, identificação biométrica, sistemas para transmissão secreta de informações para espionagem, reconhecimento de fala por vídeo de câmeras de vigilância, etc. No final, os computadores do futuro também lerão lábios, como o HAL 9000 .Portanto, os cientistas tentam há muitos anos desenvolver sistemas automáticos de leitura labial, mas sem muito sucesso. Mesmo para o inglês relativamente simples, em que o número de fonemas é muito menor que o russo, a precisão do reconhecimento é baixa.Compreender a fala com base em expressões faciais humanas é uma tarefa assustadora. As pessoas que dominam essa habilidade tentam reconhecer dezenas de fonemas consoantes, muitos dos quais têm aparência muito semelhante. É especialmente difícil para uma pessoa não treinada distinguir entre cinco categorias de fonemas visuais (isto é, visemes) do idioma inglês. Em outras palavras, distinguir a pronúncia de algumas consoantes pelos lábios é quase impossível. Não é de surpreender que as pessoas se saiam muito mal com a leitura exata dos lábios. Mesmo os melhores das pessoas com deficiência auditiva demonstram precisão de apenas 17 ± 12% de 30 monossílabos ou 21 ± 11% de palavras polissilábicas (daqui em diante os resultados para o idioma inglês).A leitura automática dos lábios é uma das tarefas da visão de máquina, que se resume ao processamento quadro a quadro de uma sequência de vídeo. A tarefa é muito complicada pela baixa qualidade da maioria dos materiais de vídeo práticos, que não permitem uma leitura precisa do espaço-temporal, isto é, das características espaço-temporais de uma pessoa durante uma conversa. Os rostos se movem e giram em direções diferentes. Desenvolvimentos recentes no campo da visão de máquina estão tentando rastrear o movimento da face no quadro para resolver esse problema. Apesar dos sucessos, até recentemente, eles eram capazes de reconhecer apenas palavras individuais, mas não sentenças.Um avanço significativo nessa área foi alcançado pelos desenvolvedores da Universidade de Oxford. O LipNet que eles treinaramtornou-se o primeiro do mundo a reconhecer com êxito os lábios no nível de frases inteiras, processando imagens de vídeo. Mapas de saliência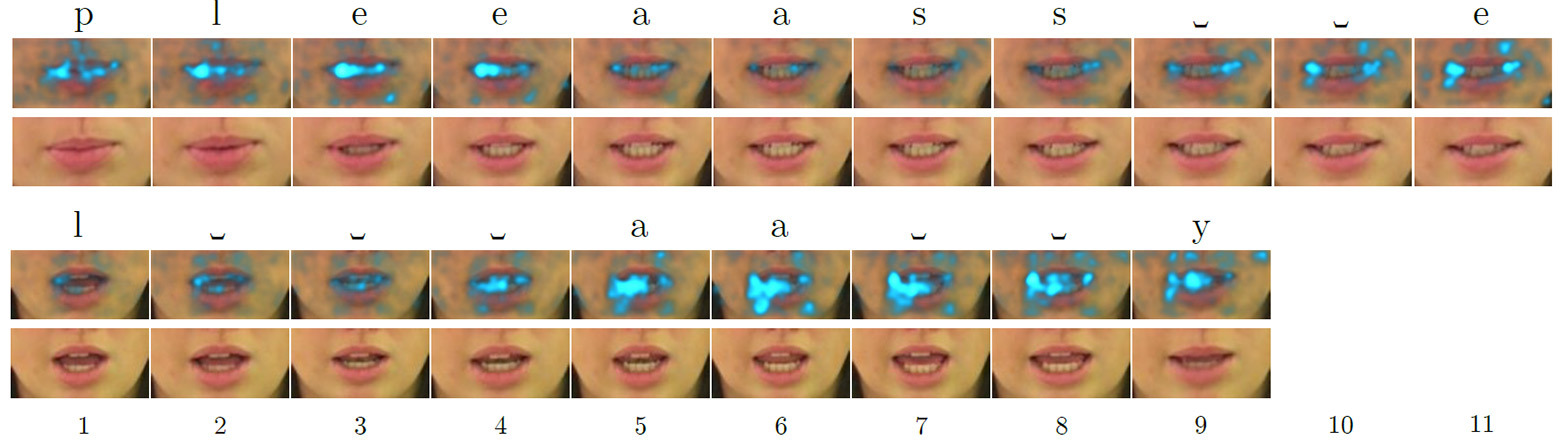 quadro a quadro para as palavras em inglês "please" (acima) e "lay" (abaixo) quando processados por uma rede neural que lê lábios, destacando os recursos mais atraentes (destacados) doLipNet - uma rede neural recorrente do tipo LSTM (memória de curto prazo). A arquitetura é mostrada na ilustração. A rede neural foi treinada usando o método Connectionist Temporal Classification (CTC), amplamente utilizado em sistemas modernos de reconhecimento de fala, pois elimina a necessidade de treinamento em um conjunto de dados de entrada sincronizados com o resultado correto.
quadro a quadro para as palavras em inglês "please" (acima) e "lay" (abaixo) quando processados por uma rede neural que lê lábios, destacando os recursos mais atraentes (destacados) doLipNet - uma rede neural recorrente do tipo LSTM (memória de curto prazo). A arquitetura é mostrada na ilustração. A rede neural foi treinada usando o método Connectionist Temporal Classification (CTC), amplamente utilizado em sistemas modernos de reconhecimento de fala, pois elimina a necessidade de treinamento em um conjunto de dados de entrada sincronizados com o resultado correto.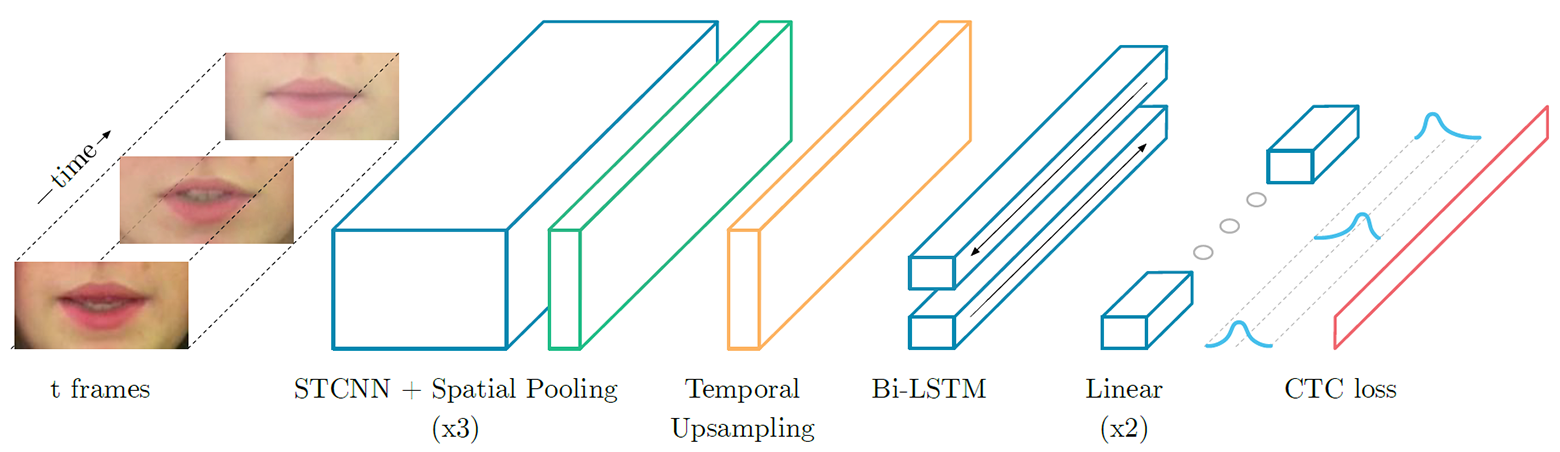 Arquitetura de rede neural LipNet. Na entrada, é fornecida uma sequência de quadros T, que são processados por três camadas da rede neural convolucional espaço-temporal (espaço-temporal) (STCNN), cada uma das quais é acompanhada por uma camada de amostragem espacial. Para os recursos extraídos, a taxa de amostragem na linha do tempo (upsampling) é aumentada e eles são processados por LTSM duplo. Cada vez que a etapa LTSM é processada por uma rede de distribuição direta de duas camadas e a última camada SoftMax.Emum pacote especial de ofertas GRID, a rede neural mostra uma precisão de reconhecimento de 93,4%. Isso não apenas excede a precisão do reconhecimento de outros desenvolvimentos de software (que são indicados na tabela abaixo), mas também excede a eficiência da leitura na boca de pessoas especialmente treinadas.
Arquitetura de rede neural LipNet. Na entrada, é fornecida uma sequência de quadros T, que são processados por três camadas da rede neural convolucional espaço-temporal (espaço-temporal) (STCNN), cada uma das quais é acompanhada por uma camada de amostragem espacial. Para os recursos extraídos, a taxa de amostragem na linha do tempo (upsampling) é aumentada e eles são processados por LTSM duplo. Cada vez que a etapa LTSM é processada por uma rede de distribuição direta de duas camadas e a última camada SoftMax.Emum pacote especial de ofertas GRID, a rede neural mostra uma precisão de reconhecimento de 93,4%. Isso não apenas excede a precisão do reconhecimento de outros desenvolvimentos de software (que são indicados na tabela abaixo), mas também excede a eficiência da leitura na boca de pessoas especialmente treinadas.| Método | Conjunto de dados | Tamanho | Edição | Precisão |
|---|
| Fu et al. (2008) | AVICAR | 851 | | 37,9% |
| Zhao et al. (2009) | AVLetter | 78 | | 43,5% |
| Papandreou et al. (2009) | CUAVE | 1800 | | 83,0% |
| Chung & Zisserman (2016a) | OuluVS1 | 200 | | 91,4% |
| Chung & Zisserman (2016b) | OuluVS2 | 520 | | 94,1% |
| Chung & Zisserman (2016a) | BBC TV | >400000 | | 65,4% |
| Wand et al. (2016) | GRID | 9000 | | 79,6% |
| LipNet | GRID | 28853 | | 93,4% |
O caso GRID especial é composto de acordo com o seguinte modelo:comando (4) + cor (4) + preposição (4) + letra (25) + dígito (10) + advérbio (4), emque o número corresponde ao número de variantes de palavras para cada uma das seis categorias verbais .Em outras palavras, a precisão de 93,4% ainda é o resultado obtido em condições de laboratório em estufa. Obviamente, com o reconhecimento de discurso humano arbitrário, o resultado será muito pior. Sem mencionar a análise de dados de vídeo real, em que o rosto de uma pessoa não é fotografado em close com excelente iluminação e alta resolução.A operação da rede neural LipNet é mostrada no vídeo de demonstração.O artigo científico foi preparado para a conferência ICLR 2017 e publicado em 4 de novembro de 2016 em domínio público.Source: https://habr.com/ru/post/pt398901/
All Articles