A rede neural lê 46,8% das palavras nos lábios na televisão, enquanto apenas 12,4% das pessoas
 Os quadros dos quatro programas em que o programa foi estudado, bem como a palavra "tarde", proferida por dois alto-falantes diferentes.Há duas semanas, eles conversaram sobre a rede neural LipNet , que exibia uma qualidade recorde de 93,4% do reconhecimento de fala humana nos lábios. Mesmo assim, muitos aplicativos eram supostos para tais sistemas de computadores: uma nova geração de aparelhos auditivos médicos com reconhecimento de fala, sistemas para palestras silenciosas em locais públicos, identificação biométrica, sistemas para transmissão secreta de informações para espionagem, reconhecimento de fala por vídeo de câmeras de vigilância etc. E agora, especialistas da Universidade de Oxford, juntamente com um funcionário do Google DeepMind, contaram sobre seus próprios desenvolvimentos nessa área.A nova rede neural foi treinada em textos arbitrários de pessoas atuando no canal de televisão da BBC. Curiosamente, o treinamento foi realizado automaticamente, sem primeiro anotar o discurso manualmente. O próprio sistema reconheceu a fala, anotou o vídeo, encontrou rostos no quadro e aprendeu a determinar a relação entre palavras (sons) e movimento dos lábios.Como resultado, esse sistema reconhece efetivamente textos arbitrários , em vez de instâncias do corpus especial de frases GRID, como o LipNet. O caso GRID possui uma estrutura e vocabulário estritamente limitados; portanto, apenas 33.000 frases são possíveis. Assim, o número de opções é reduzido por ordens de magnitude e o reconhecimento é simplificado.O caso GRID especial é composto da seguinte maneira:comando (4) + cor (4) + preposição (4) + letra (25) + dígito (10) + advérbio (4), emque o número corresponde ao número de variantes de palavras para cada uma das seis categorias verbais.Ao contrário do LipNet, o desenvolvimento do DeepMind e especialistas da Universidade de Oxford trabalha com fluxos de fala arbitrários na qualidade da imagem da televisão. É muito mais como um sistema real, pronto para uso prático.A AI treinou 5.000 horas de vídeo gravadas em seis programas de televisão do canal britânico da BBC de janeiro de 2010 a dezembro de 2015: são comunicados regulares (1584 horas), notícias da manhã (1997 horas), transmissões do Newsnight (590 horas), World News (194) horas), tempo de perguntas (323 horas) e mundo hoje (272 horas). No total, os vídeos contêm 118.116 frases de fala humana contínua.Depois disso, o programa foi verificado nas transmissões que foram ao ar entre março e setembro de 2016.
Os quadros dos quatro programas em que o programa foi estudado, bem como a palavra "tarde", proferida por dois alto-falantes diferentes.Há duas semanas, eles conversaram sobre a rede neural LipNet , que exibia uma qualidade recorde de 93,4% do reconhecimento de fala humana nos lábios. Mesmo assim, muitos aplicativos eram supostos para tais sistemas de computadores: uma nova geração de aparelhos auditivos médicos com reconhecimento de fala, sistemas para palestras silenciosas em locais públicos, identificação biométrica, sistemas para transmissão secreta de informações para espionagem, reconhecimento de fala por vídeo de câmeras de vigilância etc. E agora, especialistas da Universidade de Oxford, juntamente com um funcionário do Google DeepMind, contaram sobre seus próprios desenvolvimentos nessa área.A nova rede neural foi treinada em textos arbitrários de pessoas atuando no canal de televisão da BBC. Curiosamente, o treinamento foi realizado automaticamente, sem primeiro anotar o discurso manualmente. O próprio sistema reconheceu a fala, anotou o vídeo, encontrou rostos no quadro e aprendeu a determinar a relação entre palavras (sons) e movimento dos lábios.Como resultado, esse sistema reconhece efetivamente textos arbitrários , em vez de instâncias do corpus especial de frases GRID, como o LipNet. O caso GRID possui uma estrutura e vocabulário estritamente limitados; portanto, apenas 33.000 frases são possíveis. Assim, o número de opções é reduzido por ordens de magnitude e o reconhecimento é simplificado.O caso GRID especial é composto da seguinte maneira:comando (4) + cor (4) + preposição (4) + letra (25) + dígito (10) + advérbio (4), emque o número corresponde ao número de variantes de palavras para cada uma das seis categorias verbais.Ao contrário do LipNet, o desenvolvimento do DeepMind e especialistas da Universidade de Oxford trabalha com fluxos de fala arbitrários na qualidade da imagem da televisão. É muito mais como um sistema real, pronto para uso prático.A AI treinou 5.000 horas de vídeo gravadas em seis programas de televisão do canal britânico da BBC de janeiro de 2010 a dezembro de 2015: são comunicados regulares (1584 horas), notícias da manhã (1997 horas), transmissões do Newsnight (590 horas), World News (194) horas), tempo de perguntas (323 horas) e mundo hoje (272 horas). No total, os vídeos contêm 118.116 frases de fala humana contínua.Depois disso, o programa foi verificado nas transmissões que foram ao ar entre março e setembro de 2016.Um exemplo de leitura labial de uma tela de televisão O programa mostrou uma qualidade de leitura bastante alta. Ela reconheceu corretamente até frases muito complexas com construções gramaticais incomuns e o uso de nomes próprios. Exemplos de frases perfeitamente reconhecidas:- MUITAS PESSOAS QUE ESTÃO ENVOLVIDAS NOS ATAQUES
- CLOSE TO THE EUROPEAN COMMISSION’S MAIN BUILDING
- WEST WALES AND THE SOUTH WEST AS WELL AS WESTERN SCOTLAND
- WE KNOW THERE WILL BE HUNDREDS OF JOURNALISTS HERE AS WELL
- ACCORDING TO PROVISIONAL FIGURES FROM THE ELECTORAL COMMISSION
- THAT’S THE LOWEST FIGURE FOR EIGHT YEARS
- MANCHESTER FOOTBALL CORRESPONDENT FOR THE DAILY MIRROR
- LAYING THE GROUNDS FOR A POSSIBLE SECOND REFERENDUM
- ACCORDING TO THE LATEST FIGURES FROM THE OFFICE FOR NATIONAL STATISTICS
- IT COMES AFTER A DAMNING REPORT BY THE HEALTH WATCHDOG
A IA excedeu significativamente a eficácia do trabalho de uma pessoa, especialista em leitura labial, que tentou reconhecer 200 videoclipes aleatórios de um arquivo de verificação de vídeo gravado.O profissional conseguiu anotar, sem um único erro, apenas 12,4% das palavras, enquanto a IA registrou corretamente 46,8%. Os pesquisadores observam que muitos erros podem ser chamados de menores. Por exemplo, os "s" ausentes no final das palavras. Se abordarmos a análise dos resultados com menos rigor, então, na realidade, o sistema reconheceu muito mais da metade das palavras no ar.Com esse resultado, o DeepMind é significativamente superior a todos os outros leitores de lábios, incluindo o mencionado LipNet, que também é desenvolvido na Universidade de Oxford. No entanto, é muito cedo para falar sobre a superioridade máxima, porque o LipNet não foi treinado em um conjunto de dados tão grande.Segundo especialistas , o DeepMind é um grande passo para o desenvolvimento de um sistema de leitura labial totalmente automático.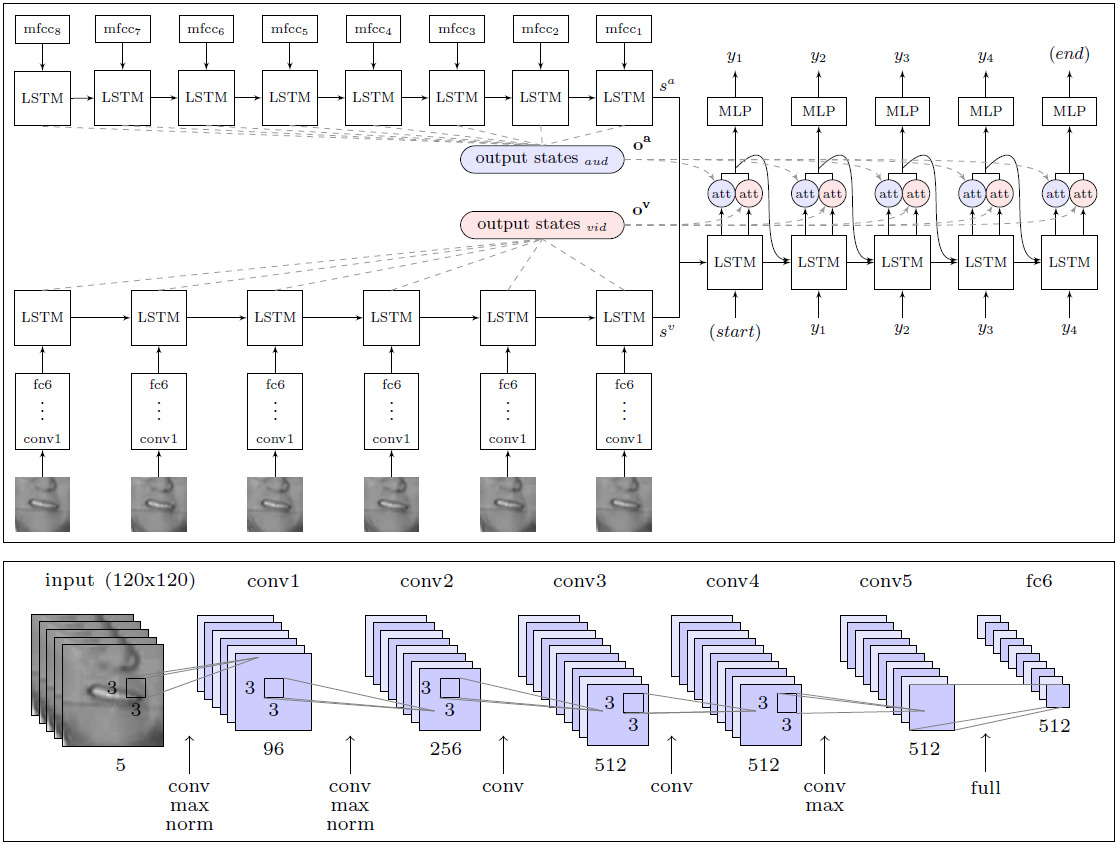 A arquitetura do módulo WLAS (Observar, Ouvir, Participar e Soletrar) e uma rede neural convolucional para leitura labialO grande mérito dos pesquisadores reside no fato de que eles compilaram um gigantesco conjunto de dados para treinar e testar o sistema com 17.500 palavras únicas. Afinal, não são apenas cinco anos de gravação contínua de programas de televisão em bom inglês, mas também uma sincronização clara de vídeo e som (na TV geralmente há uma sincronização de até 1 segundo, mesmo na televisão profissional em inglês), bem como o desenvolvimento de um módulo para reconhecimento de fala, sobreposto em vídeo e é usado no ensino do sistema de leitura labial (módulo WLAS, veja o diagrama acima).No caso do menor rassincronismo, o treinamento do sistema se torna praticamente inútil, pois o programa não pode determinar a correspondência correta de sons e movimentos labiais. Após um trabalho preparatório completo, o treinamento do programa foi totalmente automático - ele processou independentemente todos os 5000 vídeos.Anteriormente, esse conjunto simplesmente não existia, portanto os mesmos autores do LipNet foram forçados a se limitar à base GRID. Para crédito dos desenvolvedores do DeepMind, eles prometeram publicar um conjunto de dados em domínio público para treinar outras IAs. Colegas da equipe de desenvolvimento LipNet já disseram que estão ansiosos por isso.O trabalho científico é publicado em domínio público no site da arXiv (arXiv: 1611.05358v1).Se os sistemas comerciais de leitura labial aparecerem no mercado, a vida das pessoas comuns será muito mais simples. Pode-se supor que esses sistemas sejam incorporados imediatamente a televisões e outros aparelhos domésticos para melhorar o controle de voz e o reconhecimento de fala quase sem erros.
A arquitetura do módulo WLAS (Observar, Ouvir, Participar e Soletrar) e uma rede neural convolucional para leitura labialO grande mérito dos pesquisadores reside no fato de que eles compilaram um gigantesco conjunto de dados para treinar e testar o sistema com 17.500 palavras únicas. Afinal, não são apenas cinco anos de gravação contínua de programas de televisão em bom inglês, mas também uma sincronização clara de vídeo e som (na TV geralmente há uma sincronização de até 1 segundo, mesmo na televisão profissional em inglês), bem como o desenvolvimento de um módulo para reconhecimento de fala, sobreposto em vídeo e é usado no ensino do sistema de leitura labial (módulo WLAS, veja o diagrama acima).No caso do menor rassincronismo, o treinamento do sistema se torna praticamente inútil, pois o programa não pode determinar a correspondência correta de sons e movimentos labiais. Após um trabalho preparatório completo, o treinamento do programa foi totalmente automático - ele processou independentemente todos os 5000 vídeos.Anteriormente, esse conjunto simplesmente não existia, portanto os mesmos autores do LipNet foram forçados a se limitar à base GRID. Para crédito dos desenvolvedores do DeepMind, eles prometeram publicar um conjunto de dados em domínio público para treinar outras IAs. Colegas da equipe de desenvolvimento LipNet já disseram que estão ansiosos por isso.O trabalho científico é publicado em domínio público no site da arXiv (arXiv: 1611.05358v1).Se os sistemas comerciais de leitura labial aparecerem no mercado, a vida das pessoas comuns será muito mais simples. Pode-se supor que esses sistemas sejam incorporados imediatamente a televisões e outros aparelhos domésticos para melhorar o controle de voz e o reconhecimento de fala quase sem erros.Source: https://habr.com/ru/post/pt399429/
All Articles