Rede neural Pix2pix colore realisticamente desenhos a lápis e fotos em preto e branco
 Quatro exemplos do programa, cujo código é publicado em domínio público. As imagens de origem são mostradas à esquerda e o resultado do processamento automático é mostrado àdireita.Muitas tarefas de processamento de imagens, computação gráfica e visão computacional podem ser reduzidas à tarefa de "traduzir" uma imagem (na entrada) para outra (na saída). Assim como o mesmo texto pode ser representado em inglês ou russo, a imagem pode ser representada em cores RGB, em gradientes, como um mapa dos limites dos objetos, um mapa de rótulos semânticos etc. Com base no modelo de sistemas de tradução automática, desenvolvedores do Laboratório de Pesquisa em IA de Berkeley (BAIR) da Universidade da Califórnia em Berkeley criaram um aplicativopara transmitir imagens automaticamente de uma visualização para outra. Por exemplo, de um esboço em preto e branco a uma imagem colorida.Para uma pessoa não informada, o trabalho desse programa parecerá mágico, mas é baseado em um modelo de programa de redes adversárias generativas condicionais (cGAN) - variedades do tipo conhecido de redes adversárias generativas (GAN).Os autores do trabalho científico escrevem que a maioria dos problemas que surgem ao traduzir imagens está relacionada à tradução "muitos para um" (visão computacional - tradução de fotos em mapas semânticos, segmentos, limites de objetos etc.) ou "um para muitos" "(Computação gráfica - tradução de etiquetas ou dados de entrada do usuário em imagens realistas). Tradicionalmente, cada uma dessas tarefas é executada por um aplicativo especializado separado. Em seu trabalho, os autores tentaram criar uma única estrutura universal para todos esses problemas. E eles fizeram isso.As redes neurais convolucionais treinadas para minimizar a função de perda são ótimas para transmitir imagens., ou seja, uma medida da discrepância entre o valor real do parâmetro estimado e a estimativa do parâmetro. Embora o treinamento em si ocorra automaticamente, no entanto, é necessário um trabalho manual significativo para minimizar efetivamente a função de perda. Em outras palavras, ainda precisamos explicar e mostrar às redes neurais o que especificamente precisa ser minimizado. E aqui existem muitas armadilhas que afetam adversamente o resultado, se trabalharmos com uma função de perda de baixo nível como “minimizar a distância euclidiana entre os pixels previstos e os pixels reais” - isso levará à geração de imagens tremidas.
Quatro exemplos do programa, cujo código é publicado em domínio público. As imagens de origem são mostradas à esquerda e o resultado do processamento automático é mostrado àdireita.Muitas tarefas de processamento de imagens, computação gráfica e visão computacional podem ser reduzidas à tarefa de "traduzir" uma imagem (na entrada) para outra (na saída). Assim como o mesmo texto pode ser representado em inglês ou russo, a imagem pode ser representada em cores RGB, em gradientes, como um mapa dos limites dos objetos, um mapa de rótulos semânticos etc. Com base no modelo de sistemas de tradução automática, desenvolvedores do Laboratório de Pesquisa em IA de Berkeley (BAIR) da Universidade da Califórnia em Berkeley criaram um aplicativopara transmitir imagens automaticamente de uma visualização para outra. Por exemplo, de um esboço em preto e branco a uma imagem colorida.Para uma pessoa não informada, o trabalho desse programa parecerá mágico, mas é baseado em um modelo de programa de redes adversárias generativas condicionais (cGAN) - variedades do tipo conhecido de redes adversárias generativas (GAN).Os autores do trabalho científico escrevem que a maioria dos problemas que surgem ao traduzir imagens está relacionada à tradução "muitos para um" (visão computacional - tradução de fotos em mapas semânticos, segmentos, limites de objetos etc.) ou "um para muitos" "(Computação gráfica - tradução de etiquetas ou dados de entrada do usuário em imagens realistas). Tradicionalmente, cada uma dessas tarefas é executada por um aplicativo especializado separado. Em seu trabalho, os autores tentaram criar uma única estrutura universal para todos esses problemas. E eles fizeram isso.As redes neurais convolucionais treinadas para minimizar a função de perda são ótimas para transmitir imagens., ou seja, uma medida da discrepância entre o valor real do parâmetro estimado e a estimativa do parâmetro. Embora o treinamento em si ocorra automaticamente, no entanto, é necessário um trabalho manual significativo para minimizar efetivamente a função de perda. Em outras palavras, ainda precisamos explicar e mostrar às redes neurais o que especificamente precisa ser minimizado. E aqui existem muitas armadilhas que afetam adversamente o resultado, se trabalharmos com uma função de perda de baixo nível como “minimizar a distância euclidiana entre os pixels previstos e os pixels reais” - isso levará à geração de imagens tremidas. O efeito de várias funções de perda no resultadoSeria muito mais simples definir redes neurais para tarefas de alto nível, como "gerar uma imagem indistinguível da realidade", e depois treinar automaticamente a rede neural para minimizar a função de perda que melhor executa a tarefa. É assim que as redes contraditórias generativas (GANs) funcionam - uma das áreas mais promissoras no desenvolvimento de redes neurais atualmente. A rede GAN treina a função de perda, cuja tarefa é classificar a imagem como "real" ou "falsa", enquanto treina o modelo generativo para minimizar essa função. Aqui, as imagens borradas não podem ser produzidas de forma alguma, porque elas não serão aprovadas na verificação de classificação como "real".Os desenvolvedores usaram redes adversárias generativas condicionais (cGAN) para a tarefa, ou seja, GAN com um parâmetro condicional. Assim como o GAN assimila o modelo generativo de dados, o cGAN assimila o modelo generativo de acordo com uma determinada condição, o que o torna adequado para a transmissão de imagens “um a um”.
O efeito de várias funções de perda no resultadoSeria muito mais simples definir redes neurais para tarefas de alto nível, como "gerar uma imagem indistinguível da realidade", e depois treinar automaticamente a rede neural para minimizar a função de perda que melhor executa a tarefa. É assim que as redes contraditórias generativas (GANs) funcionam - uma das áreas mais promissoras no desenvolvimento de redes neurais atualmente. A rede GAN treina a função de perda, cuja tarefa é classificar a imagem como "real" ou "falsa", enquanto treina o modelo generativo para minimizar essa função. Aqui, as imagens borradas não podem ser produzidas de forma alguma, porque elas não serão aprovadas na verificação de classificação como "real".Os desenvolvedores usaram redes adversárias generativas condicionais (cGAN) para a tarefa, ou seja, GAN com um parâmetro condicional. Assim como o GAN assimila o modelo generativo de dados, o cGAN assimila o modelo generativo de acordo com uma determinada condição, o que o torna adequado para a transmissão de imagens “um a um”. Transmitir layouts de paisagens urbanas para fotos realistas. À esquerda está a marcação, no centro está o original e à direita está a imagem geradaNos últimos dois anos, muitas aplicações do GAN foram descritas e a base teórica de seu trabalho foi bem estudada. Mas em todas essas obras, a GAN é usada apenas para tarefas especializadas (por exemplo, a geração de imagens assustadoras ou a geração de fotos pornôs)) Não ficou totalmente claro como o GAN é adequado para a tradução eficiente de imagens individuais. O principal objetivo deste trabalho é demonstrar que essa rede neural é capaz de executar uma grande lista de várias tarefas, mostrando um resultado bastante aceitável.Por exemplo, a coloração de esboços a lápis preto e branco (coluna da esquerda) parece muito boa, com base nos quais a rede neural gera imagens fotorrealistas (coluna da direita). Em alguns casos, o resultado da operação da rede neural parece ainda mais realista do que uma fotografia real (a coluna central, para comparação).
Transmitir layouts de paisagens urbanas para fotos realistas. À esquerda está a marcação, no centro está o original e à direita está a imagem geradaNos últimos dois anos, muitas aplicações do GAN foram descritas e a base teórica de seu trabalho foi bem estudada. Mas em todas essas obras, a GAN é usada apenas para tarefas especializadas (por exemplo, a geração de imagens assustadoras ou a geração de fotos pornôs)) Não ficou totalmente claro como o GAN é adequado para a tradução eficiente de imagens individuais. O principal objetivo deste trabalho é demonstrar que essa rede neural é capaz de executar uma grande lista de várias tarefas, mostrando um resultado bastante aceitável.Por exemplo, a coloração de esboços a lápis preto e branco (coluna da esquerda) parece muito boa, com base nos quais a rede neural gera imagens fotorrealistas (coluna da direita). Em alguns casos, o resultado da operação da rede neural parece ainda mais realista do que uma fotografia real (a coluna central, para comparação). Faça esboços a lápis para fotos realistas. À esquerda, um desenho a lápis, no centro, o original, e à direita, uma imagem gerada:
Faça esboços a lápis para fotos realistas. À esquerda, um desenho a lápis, no centro, o original, e à direita, uma imagem gerada:
 tradução de esboços a lápis em fotos realistas.Como em outras redes generativas, neste GAN, as redes neurais estão em guerra entre si . Um deles (o gerador) está tentando criar uma imagem falsa para enganar o outro (discriminador). Com o tempo, o gerador aprende a enganar melhor o discriminador, ou seja, a gerar imagens mais realistas. Ao contrário dos GANs convencionais, no Pix2Pix, o discriminador e o gerador têm acesso à imagem original.
tradução de esboços a lápis em fotos realistas.Como em outras redes generativas, neste GAN, as redes neurais estão em guerra entre si . Um deles (o gerador) está tentando criar uma imagem falsa para enganar o outro (discriminador). Com o tempo, o gerador aprende a enganar melhor o discriminador, ou seja, a gerar imagens mais realistas. Ao contrário dos GANs convencionais, no Pix2Pix, o discriminador e o gerador têm acesso à imagem original.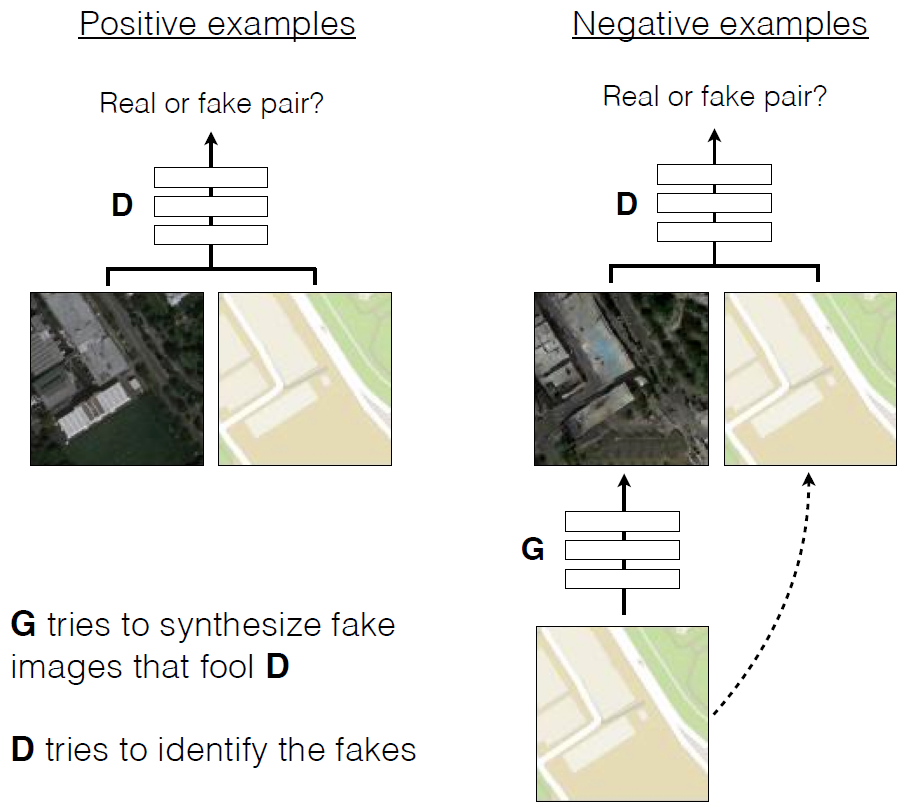 Treinando o cGAN para prever fotografias aéreas de mapas de terreno
Treinando o cGAN para prever fotografias aéreas de mapas de terreno Exemplos de trabalhos do cGAN na tradução de fotografias aéreas em mapas de terreno e vice-versa.Umartigo científico é publicado em domínio público, o código fonte do Pix2pix está no GitHub . Os autores oferecem a todos para experimentar o programa.
Exemplos de trabalhos do cGAN na tradução de fotografias aéreas em mapas de terreno e vice-versa.Umartigo científico é publicado em domínio público, o código fonte do Pix2pix está no GitHub . Os autores oferecem a todos para experimentar o programa.Source: https://habr.com/ru/post/pt399469/
All Articles