Programa DeepStack Poker bate profissionais individuais
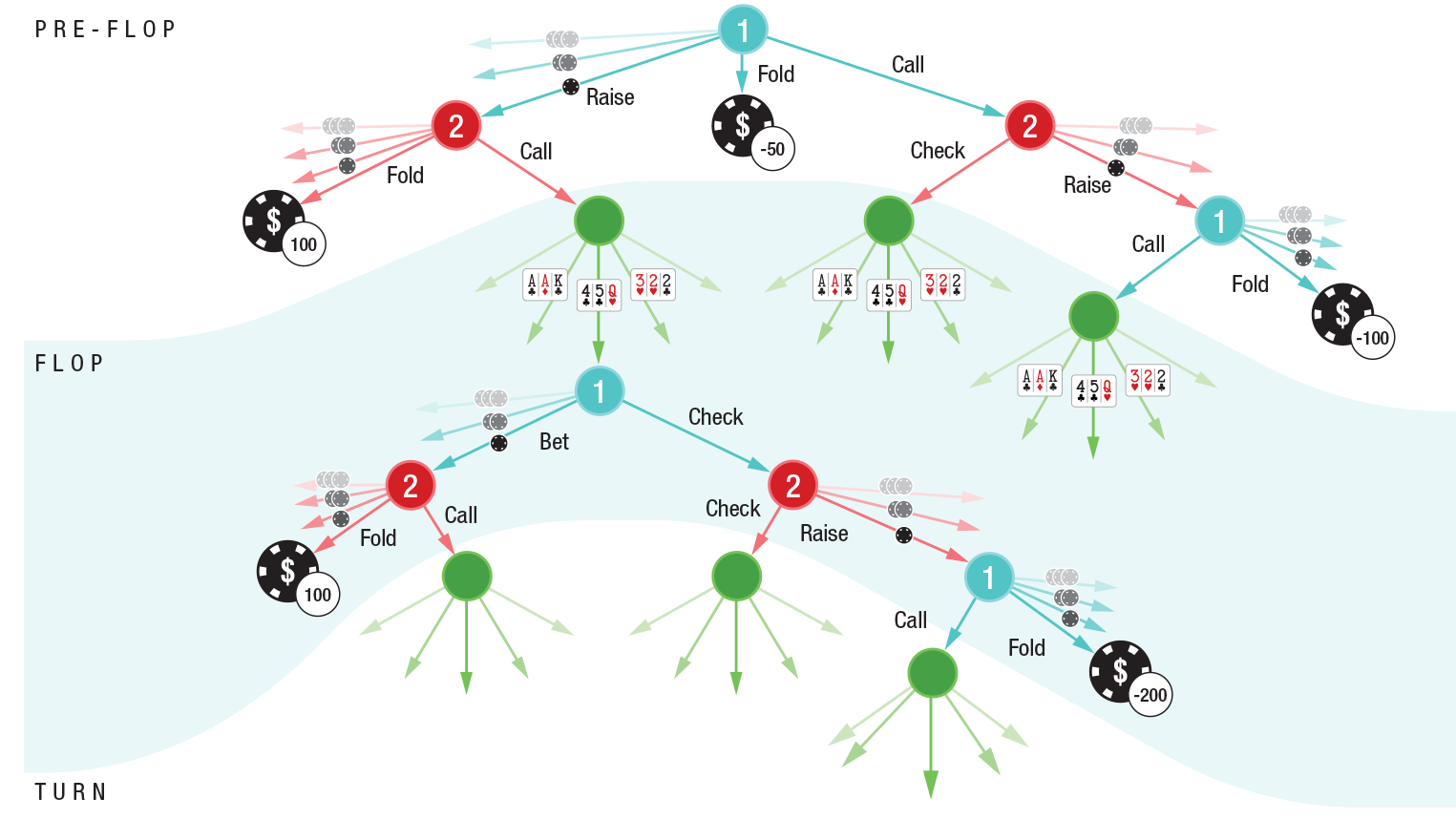 A árvore de decisão do DeepStack no heads-up (jogo one-on-one) pré-flop e flop no-limit hold'emPioneiro da moderna teoria dos jogos John von Neumann disse: “A vida real é sobre blefar, pequenos truques de decepção, pensando em quais ações esperar outra pessoa sua. É isso que o jogo representa na minha teoria ”(citação da 13ª série da série de documentários“ A Exaltação da Humanidade ”).Em outras palavras, John von Neumann previu que, para criar uma IA forte, um computador precisa aprender a jogar com informações incompletas que melhor correspondem ao comportamento humano na vida real. Jogos como poker.Jogos de tabuleiro são uma área tradicional de experimentação no campo da inteligência artificial. Todo ano, a IA derrota uma pessoa em diferentes jogos. Primeiro, as damas se renderam, depois o xadrez, depois os videogames da Atari, o último jogo acabou. Mas todos esses são jogos com informações completas, nos quais todos os jogadores têm informações completas sobre o estado do jogo. O poker é uma questão completamente diferente.Os cientistas há muito tentam desenvolver um programa que poderia derrotar uma pessoa no Texas Holdem ilimitado. Diferentemente de outras aplicações de IA fraca, o desenvolvimento bem-sucedido será recompensado instantaneamente aqui, porque bilhões de dólares podem ser ganhos nas salas de pôquer online todos os dias.John von Neumann disse que o poker o encanta, e isso não é surpreendente, dadas as características únicas deste jogo com informações incompletas. Cada jogador possui apenas parte das informações sobre o estado do jogo - e ele age com base nessas informações parciais, além de avaliar as ações de outros jogadores.Anteriormente, a IA alcançava algum sucesso apenas ao jogar limit hold'em, a versão mais primitiva do jogo, com um passo limitado no aumento das apostas. Na versão limitada, o jogador possui apenas 10 14 opções de desenvolvimento. Para comparação, em no-limit hold'em, essas opções para 10 160 . A propósito, o jogo tem 10.170 opções de desenvolvimento , mas há um jogo com informações completas, ou seja, uma tarefa fundamentalmente mais simples.Jogos com informações incompletas exigem um nível de pensamento recursivo completamente mais complexo do que jogos com informações completas. Aqui, a ação correta da IA depende, inter alia, das informações que a IA recebeu das ações do oponente. Mas as informações que o oponente forneceu, por sua vez, são uma função derivada das ações anteriores da IA e as informações que a IA deu ao oponente com suas ações. Esse é o pensamento recursivo com o qual o DeepStack lida. E ela lida muito bem, a julgar pelos resultados de jogos com profissionais (ver tabela).
A árvore de decisão do DeepStack no heads-up (jogo one-on-one) pré-flop e flop no-limit hold'emPioneiro da moderna teoria dos jogos John von Neumann disse: “A vida real é sobre blefar, pequenos truques de decepção, pensando em quais ações esperar outra pessoa sua. É isso que o jogo representa na minha teoria ”(citação da 13ª série da série de documentários“ A Exaltação da Humanidade ”).Em outras palavras, John von Neumann previu que, para criar uma IA forte, um computador precisa aprender a jogar com informações incompletas que melhor correspondem ao comportamento humano na vida real. Jogos como poker.Jogos de tabuleiro são uma área tradicional de experimentação no campo da inteligência artificial. Todo ano, a IA derrota uma pessoa em diferentes jogos. Primeiro, as damas se renderam, depois o xadrez, depois os videogames da Atari, o último jogo acabou. Mas todos esses são jogos com informações completas, nos quais todos os jogadores têm informações completas sobre o estado do jogo. O poker é uma questão completamente diferente.Os cientistas há muito tentam desenvolver um programa que poderia derrotar uma pessoa no Texas Holdem ilimitado. Diferentemente de outras aplicações de IA fraca, o desenvolvimento bem-sucedido será recompensado instantaneamente aqui, porque bilhões de dólares podem ser ganhos nas salas de pôquer online todos os dias.John von Neumann disse que o poker o encanta, e isso não é surpreendente, dadas as características únicas deste jogo com informações incompletas. Cada jogador possui apenas parte das informações sobre o estado do jogo - e ele age com base nessas informações parciais, além de avaliar as ações de outros jogadores.Anteriormente, a IA alcançava algum sucesso apenas ao jogar limit hold'em, a versão mais primitiva do jogo, com um passo limitado no aumento das apostas. Na versão limitada, o jogador possui apenas 10 14 opções de desenvolvimento. Para comparação, em no-limit hold'em, essas opções para 10 160 . A propósito, o jogo tem 10.170 opções de desenvolvimento , mas há um jogo com informações completas, ou seja, uma tarefa fundamentalmente mais simples.Jogos com informações incompletas exigem um nível de pensamento recursivo completamente mais complexo do que jogos com informações completas. Aqui, a ação correta da IA depende, inter alia, das informações que a IA recebeu das ações do oponente. Mas as informações que o oponente forneceu, por sua vez, são uma função derivada das ações anteriores da IA e as informações que a IA deu ao oponente com suas ações. Esse é o pensamento recursivo com o qual o DeepStack lida. E ela lida muito bem, a julgar pelos resultados de jogos com profissionais (ver tabela).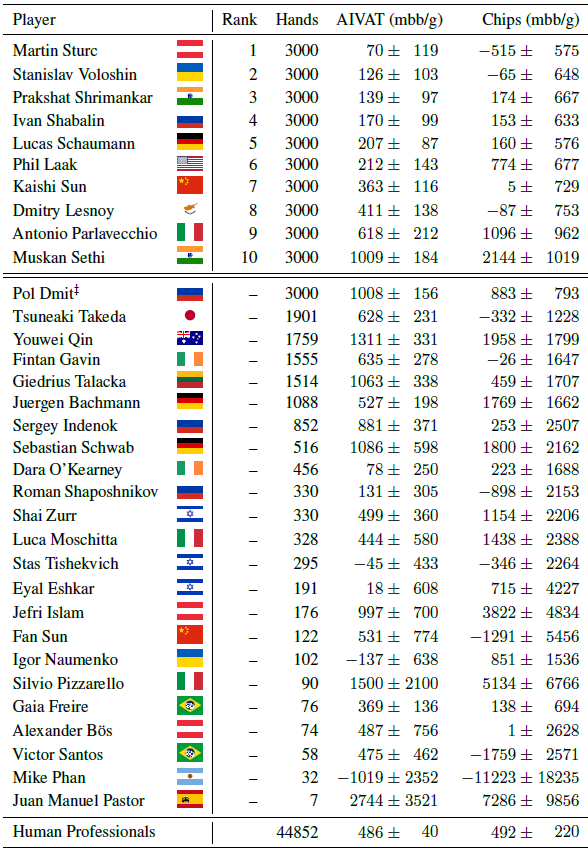 Resultados heads-up com jogadores profissionaisA arquitetura do programa DeepStack é mostrada na ilustração. O programa reavalia suas ações em cada estágio quando uma decisão é necessária. Para calcular o valor de cada aposta, é usada uma árvore lookahead, cujos valores são destacados são calculados usando uma rede neural previamente treinada em situações aleatórias de jogo.
Resultados heads-up com jogadores profissionaisA arquitetura do programa DeepStack é mostrada na ilustração. O programa reavalia suas ações em cada estágio quando uma decisão é necessária. Para calcular o valor de cada aposta, é usada uma árvore lookahead, cujos valores são destacados são calculados usando uma rede neural previamente treinada em situações aleatórias de jogo.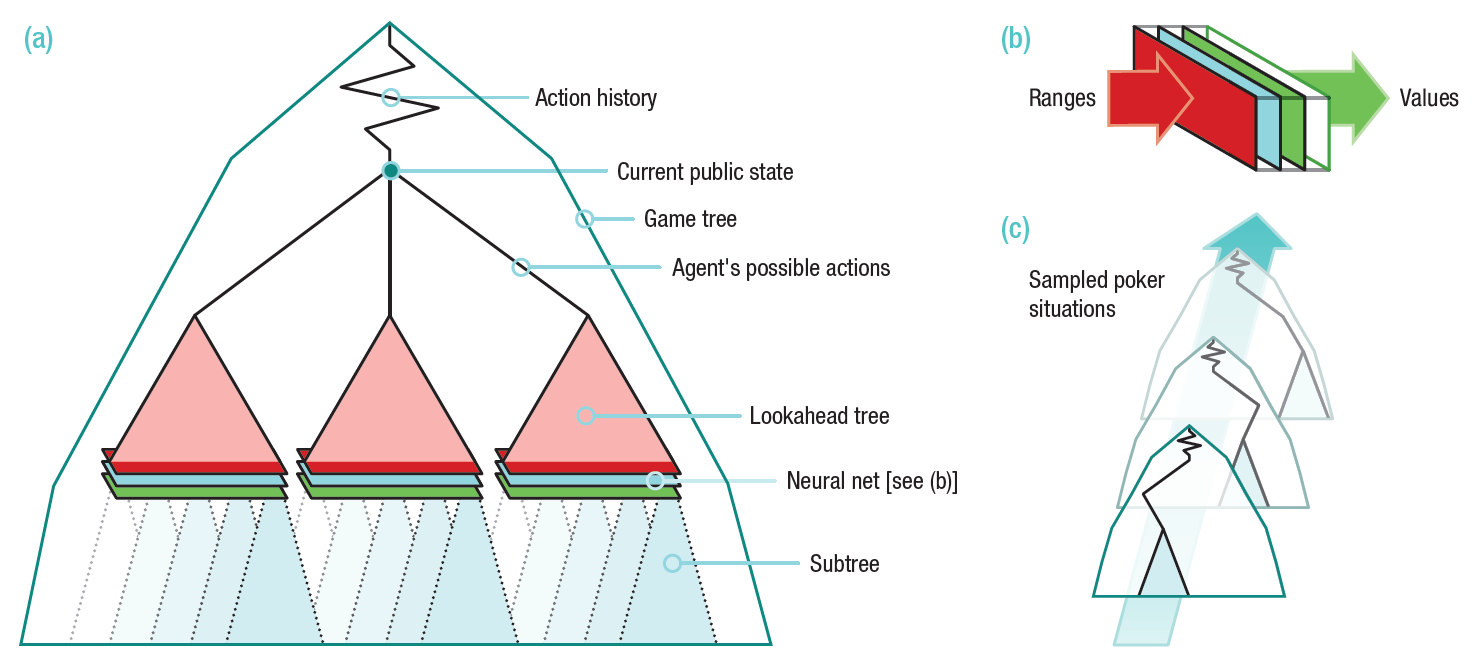 A estrutura da rede neural demonstra que o tamanho do pote, as cartas abertas e os intervalos de jogadores (combinações possíveis com as quais o jogador pode entrar no jogo da maneira como ele entrou (call, raise, 3-bet, etc.) são servidos na entrada, a probabilidade de cada combinação). Uma rede neural consiste em sete camadas ocultas totalmente conectadas. Os valores de saída são então processados por outra rede neural, que verifica se as ações atendem ao limite de soma zero.
A estrutura da rede neural demonstra que o tamanho do pote, as cartas abertas e os intervalos de jogadores (combinações possíveis com as quais o jogador pode entrar no jogo da maneira como ele entrou (call, raise, 3-bet, etc.) são servidos na entrada, a probabilidade de cada combinação). Uma rede neural consiste em sete camadas ocultas totalmente conectadas. Os valores de saída são então processados por outra rede neural, que verifica se as ações atendem ao limite de soma zero.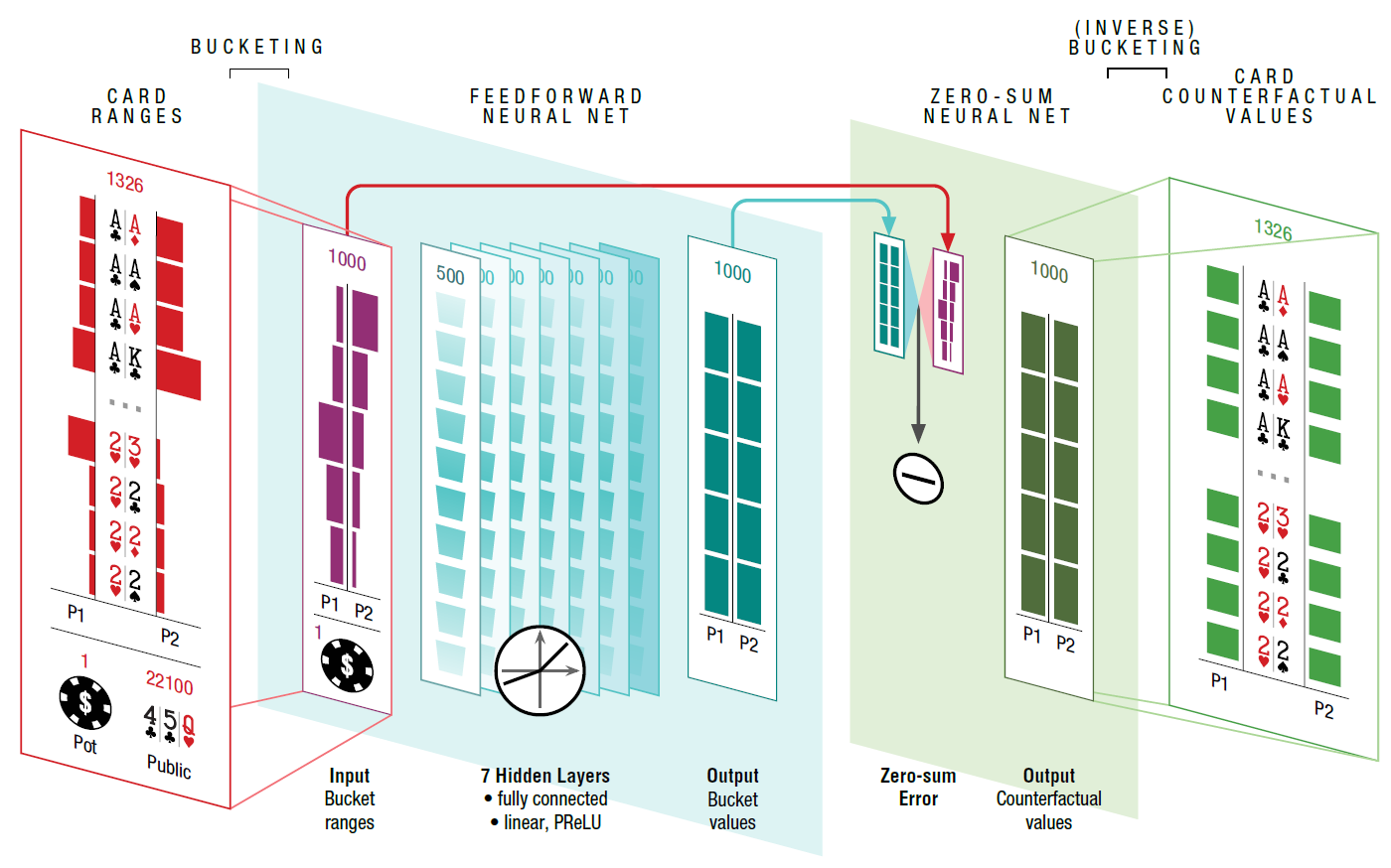 Uma característica do programa é que ele resiste ativamente à análise de sua estratégia pelo oponente. Em outras palavras, o programa usa o equilíbrio de Nash , um conceito-chave na teoria dos jogos. O equilíbrio de Nash se refere a um conjunto de estratégias que nenhum participante pode aumentar seus ganhos alterando sua estratégia se outros participantes em suas estratégias não mudarem. Do ponto de vista de um jogo de pôquer antagônico, a principal tarefa do DeepStack é encontrar o equilíbrio de Nash, ou seja, minimizar a possibilidade de explorar sua estratégia por outro jogador para obter lucro. Absolutamente todos os programas de pôquer desenvolvidos até agora foram facilmente explorados após testar sua estratégia usando a técnica LBR (melhor resposta local) - veja recenteUma visão geral dos mais recentes bots de poker .Portanto, o DeepStack não é completamente explorado usando LBR. Juntamente com os resultados reais que o bot mostrou no jogo com profissionais, há apenas uma pergunta: por que os desenvolvedores publicaram informações sobre essa arquitetura em domínio público?O trabalho científico foi publicado em 6 de janeiro de 2017 no site arXiv.org, onde os artigos são dispostos antes de serem publicados no jornal oficial.A equipe de desenvolvimento é liderada pelo professor de ciência da computação Michael Bowling da Universidade de Alberta (EUA).
Uma característica do programa é que ele resiste ativamente à análise de sua estratégia pelo oponente. Em outras palavras, o programa usa o equilíbrio de Nash , um conceito-chave na teoria dos jogos. O equilíbrio de Nash se refere a um conjunto de estratégias que nenhum participante pode aumentar seus ganhos alterando sua estratégia se outros participantes em suas estratégias não mudarem. Do ponto de vista de um jogo de pôquer antagônico, a principal tarefa do DeepStack é encontrar o equilíbrio de Nash, ou seja, minimizar a possibilidade de explorar sua estratégia por outro jogador para obter lucro. Absolutamente todos os programas de pôquer desenvolvidos até agora foram facilmente explorados após testar sua estratégia usando a técnica LBR (melhor resposta local) - veja recenteUma visão geral dos mais recentes bots de poker .Portanto, o DeepStack não é completamente explorado usando LBR. Juntamente com os resultados reais que o bot mostrou no jogo com profissionais, há apenas uma pergunta: por que os desenvolvedores publicaram informações sobre essa arquitetura em domínio público?O trabalho científico foi publicado em 6 de janeiro de 2017 no site arXiv.org, onde os artigos são dispostos antes de serem publicados no jornal oficial.A equipe de desenvolvimento é liderada pelo professor de ciência da computação Michael Bowling da Universidade de Alberta (EUA). Equipe de Desenvolvimento do DeepStackO Departamento de Bots de Poker da Universidade de Alberta (Grupo de Pesquisa em Poker de Computador) foi criado nos anos 90, o primeiro bot criado aqui foiLoki em 1997. Depois, Poki (1999), PsOpti / Sparbot (2002), Vexbot (2003), Hyperborean (2006), Polaris (2007), Hyperborean No-Limit (2007), Hyperborean Ring (2009), Cepheus (2015) e finalmente , coroa da criação - DeepStack.Em um futuro próximo, o programa DeepStack será testado em jogos com profissionais mais experientes, que são de nível muito mais alto do que os da tabela no começo do artigo. A partir deste fim de semana, o programa jogará em um torneio no Pittsburgh Casinoonde vários profissionais de classe mundial devem chegar. Em 20 dias, o DeepStack deve jogar cerca de 120.000 mãos. Isso é suficiente para avaliar com precisão a qualidade do programa.Até o momento, o DeepStack jogou 44.852 mãos contra voluntários profissionais selecionados pela Federação Internacional de Poker. Os jogadores receberam prêmios em dinheiro por um bom jogo (primeiro prêmio de $ 5.000 CAD), para que as pessoas jogassem com força total. No entanto, o programa está em uma boa vantagem.
Equipe de Desenvolvimento do DeepStackO Departamento de Bots de Poker da Universidade de Alberta (Grupo de Pesquisa em Poker de Computador) foi criado nos anos 90, o primeiro bot criado aqui foiLoki em 1997. Depois, Poki (1999), PsOpti / Sparbot (2002), Vexbot (2003), Hyperborean (2006), Polaris (2007), Hyperborean No-Limit (2007), Hyperborean Ring (2009), Cepheus (2015) e finalmente , coroa da criação - DeepStack.Em um futuro próximo, o programa DeepStack será testado em jogos com profissionais mais experientes, que são de nível muito mais alto do que os da tabela no começo do artigo. A partir deste fim de semana, o programa jogará em um torneio no Pittsburgh Casinoonde vários profissionais de classe mundial devem chegar. Em 20 dias, o DeepStack deve jogar cerca de 120.000 mãos. Isso é suficiente para avaliar com precisão a qualidade do programa.Até o momento, o DeepStack jogou 44.852 mãos contra voluntários profissionais selecionados pela Federação Internacional de Poker. Os jogadores receberam prêmios em dinheiro por um bom jogo (primeiro prêmio de $ 5.000 CAD), para que as pessoas jogassem com força total. No entanto, o programa está em uma boa vantagem.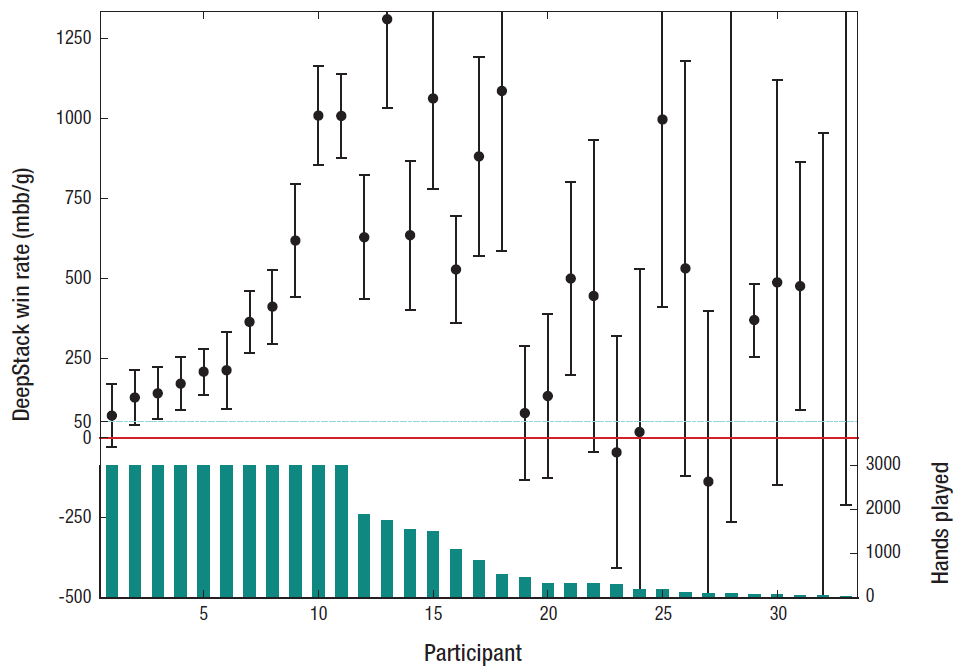
Source: https://habr.com/ru/post/pt400709/
All Articles