Da última vez [
Baixando dados do site de dados abertos data.gov.ru ], eu aprendi como baixar dados do portal de dados abertos da Rússia com alguns problemas. O portal de dados abertos deve fornecer as informações mais relevantes sobre os dados abertos das autoridades federais, autoridades regionais e outras organizações (citação em data.gov.ru). Vamos ver quais dados no portal, quão relevantes eles são e de que forma eles são colocados.
O gráfico abaixo mostra a distribuição dos conjuntos de dados por categoria.
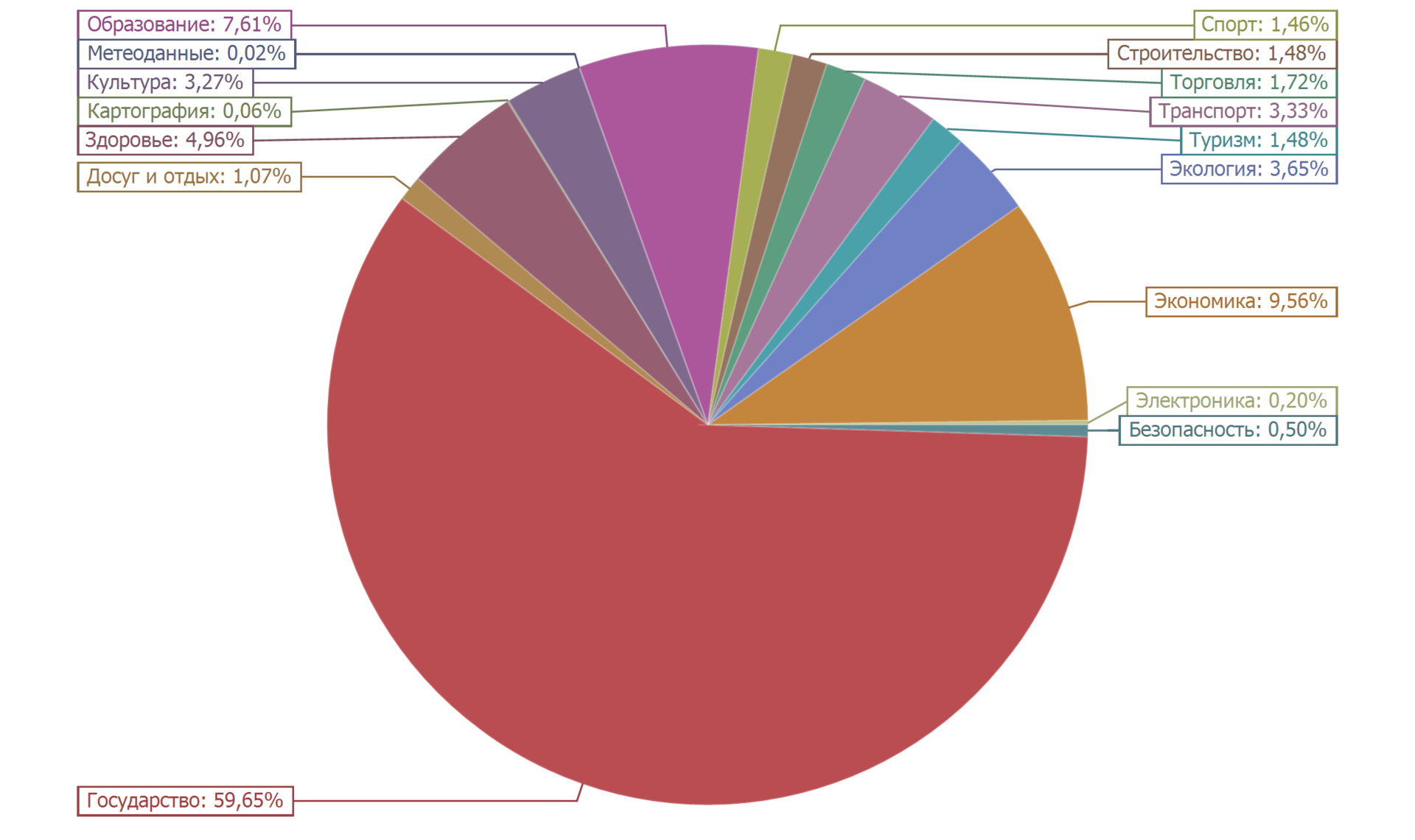
Mais da metade dos conjuntos de dados (59,65%) pertence à categoria "Estado". Cerca de dez por cento (9,56%) pertencem à categoria "Economia". Perto de dez por cento (7,61%) é o número de conjuntos de dados na categoria Educação. O resto é inferior a cinco por cento. A distribuição é bastante natural.
Expandiremos nosso conhecimento com os dados publicados no portal. Vejamos as estatísticas do posicionamento no portal de dados até a data da primeira publicação do conjunto de dados.
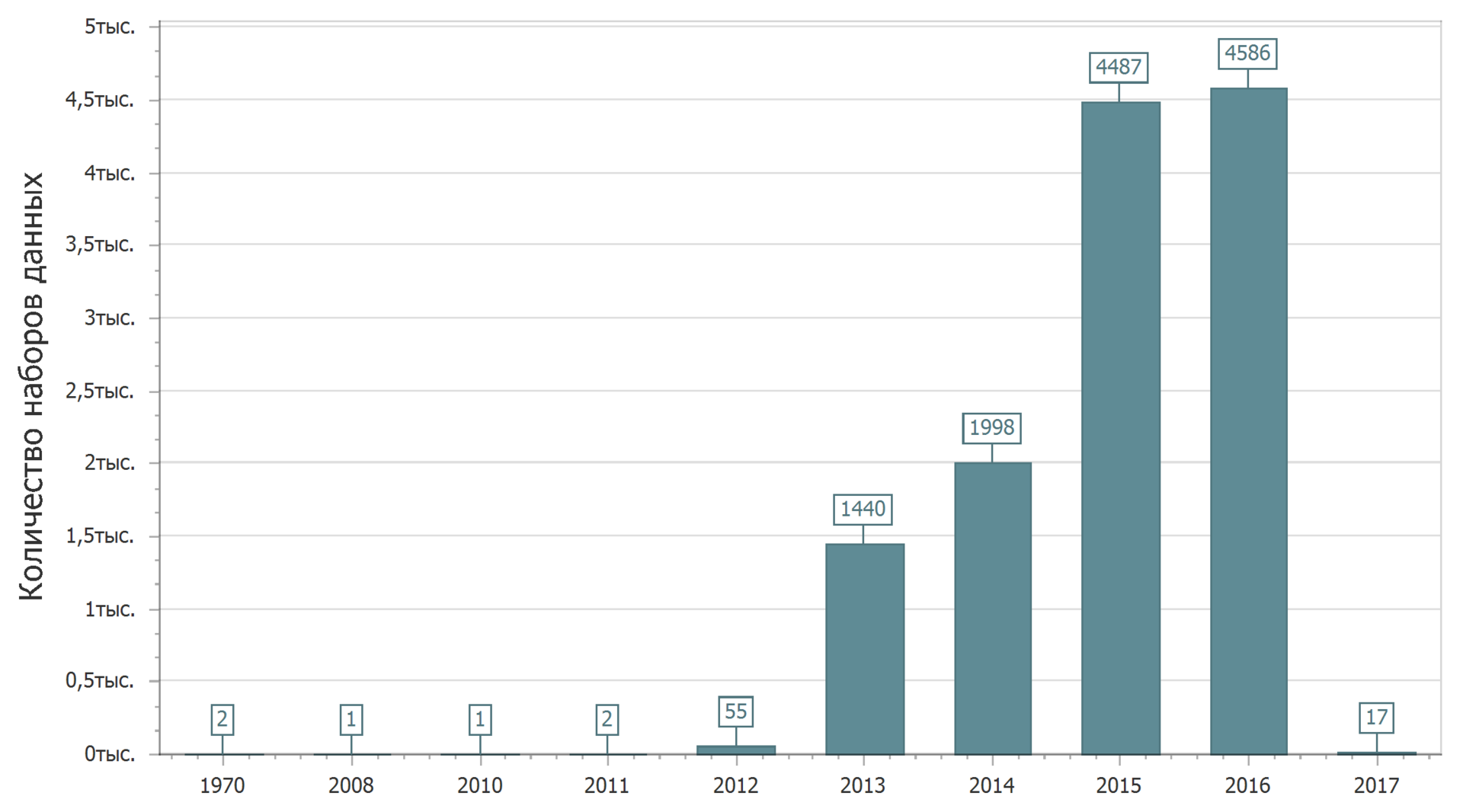
2017 está apenas começando e é natural que a quantidade de dados publicados em 2017 aumente. Sim, enquanto escrevo o texto, novos conjuntos de dados são carregados no portal.
Aparentemente, alguém conseguiu voltar no passado, tendo conseguido colocar dados na distante década de 1970.
Em geral, a imagem é clara: primeiro, crescimento acentuado, depois estabilidade. Embora seja provavelmente muito cedo para falar sobre estabilidade.
Uma imagem interessante pode ser vista se considerarmos a distribuição dos conjuntos de dados por data de relevância (a data após a qual a versão atual do conjunto de dados deve ser atualizada).
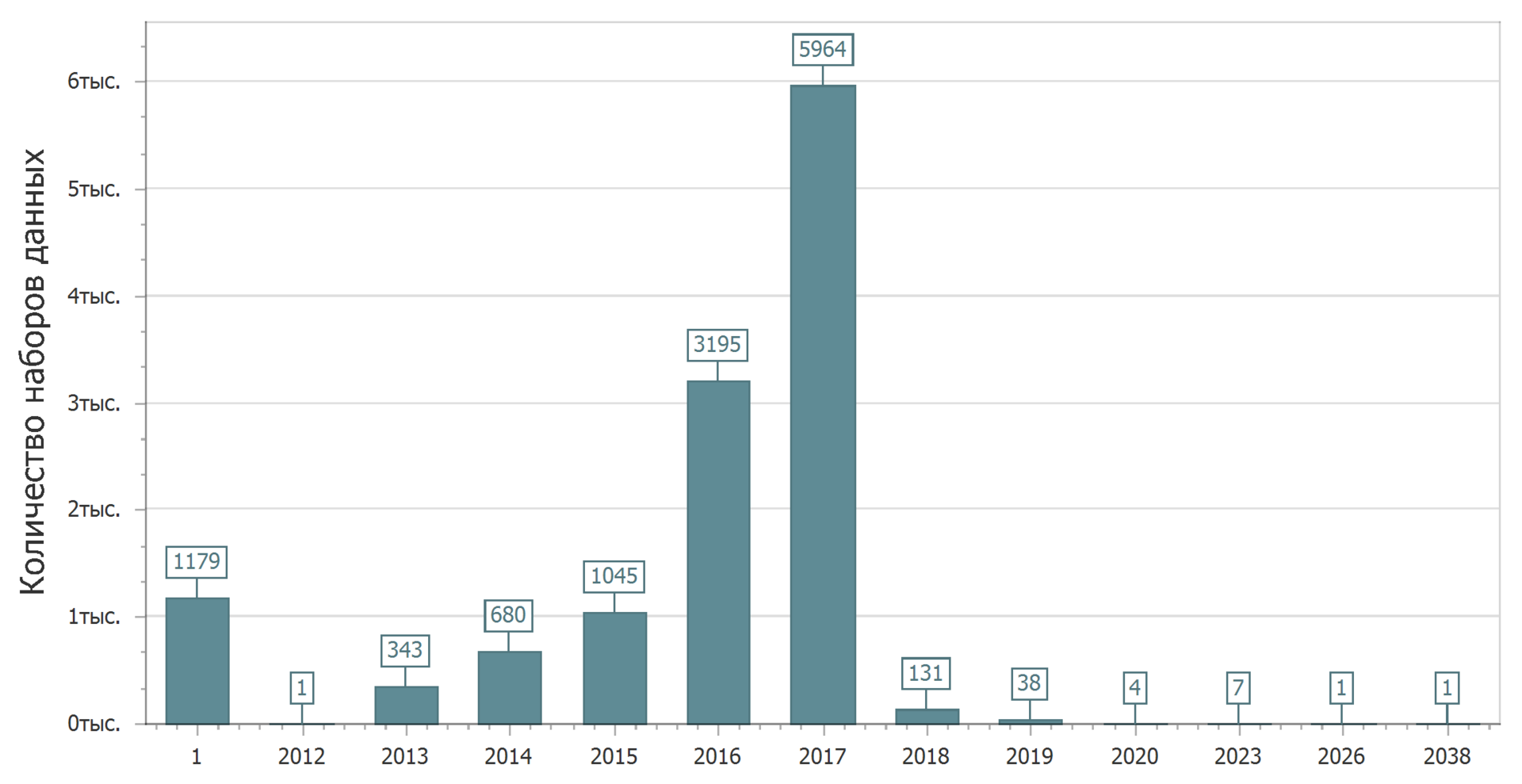
Imediatamente corre 1 ano. Assim, designei conjuntos de dados que não têm uma data atualizada. Com base na determinação da data da relevância, podemos concluir que esses são conjuntos de dados que não precisam ser atualizados. Naturalmente, esses conjuntos de dados têm o direito de existir. Sempre há dados arquivísticos (históricos) que dificilmente serão alterados (bem, se não houver erros), e há dados atuais - atuais que estão constantemente mudando. Ambos e outros podem ser de interesse. Afinal, acontece que você precisa descobrir: como foi no passado (sob o czar ou sob o regime soviético)? Mas, é claro, os dados reais (atualizados) que são atualizados constantemente são mais interessantes.
Mesmo se você não considerar o gráfico com muito cuidado, é claro que alguns dados devem ser atualizados em um futuro bastante distante. Podemos dizer que aqueles que os publicaram têm uma tremenda confiança no futuro. Nos próximos cinco, dez, vinte (?) Anos eles não mudarão nada. Ou talvez seja apenas um erro? E é possível.
Mas, em geral, a imagem é bastante feliz - quase metade dos dados planeja ser atualizado este ano.
E agora vamos confirmar esta imagem alegre. Considere a distribuição dos conjuntos de dados até a data da última alteração.
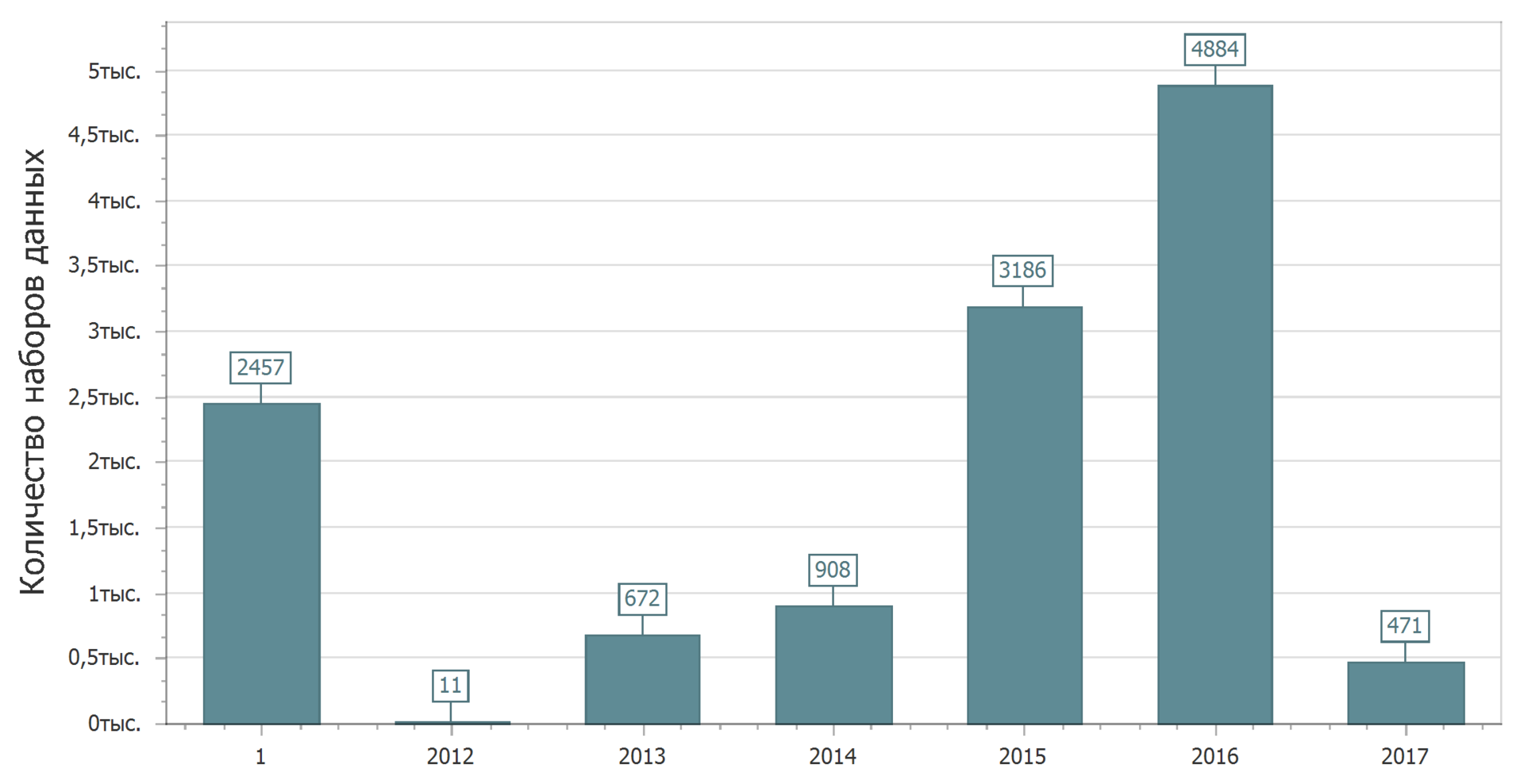
Sim Novamente 1 ano. Esses conjuntos de dados não foram modificados. Eu só quero pegar alguém. Como, eles prometeram atualizar, mas não fizeram alterações. Ou eles não prometeram atualizar e atualizar. Mas da próxima vez, procuraremos padrões (ou a falta deles).
Combine informações sobre a primeira publicação e a última atualização. Ou seja, se houve uma atualização - pegue a data da atualização, se não houver atualização - pegue a data da primeira publicação. O resultado é a data da última alteração de dados.

Beleza A tendência é claramente visível - mais da metade dos dados foram alterados pela última vez ou foram criados em 2016-2017. Talvez você possa considerá-los relevantes.
É necessário observar uma ressalva. Alguns conjuntos de dados são repetidos: o mesmo nome e proprietário do conjunto de dados são encontrados várias vezes no registro.
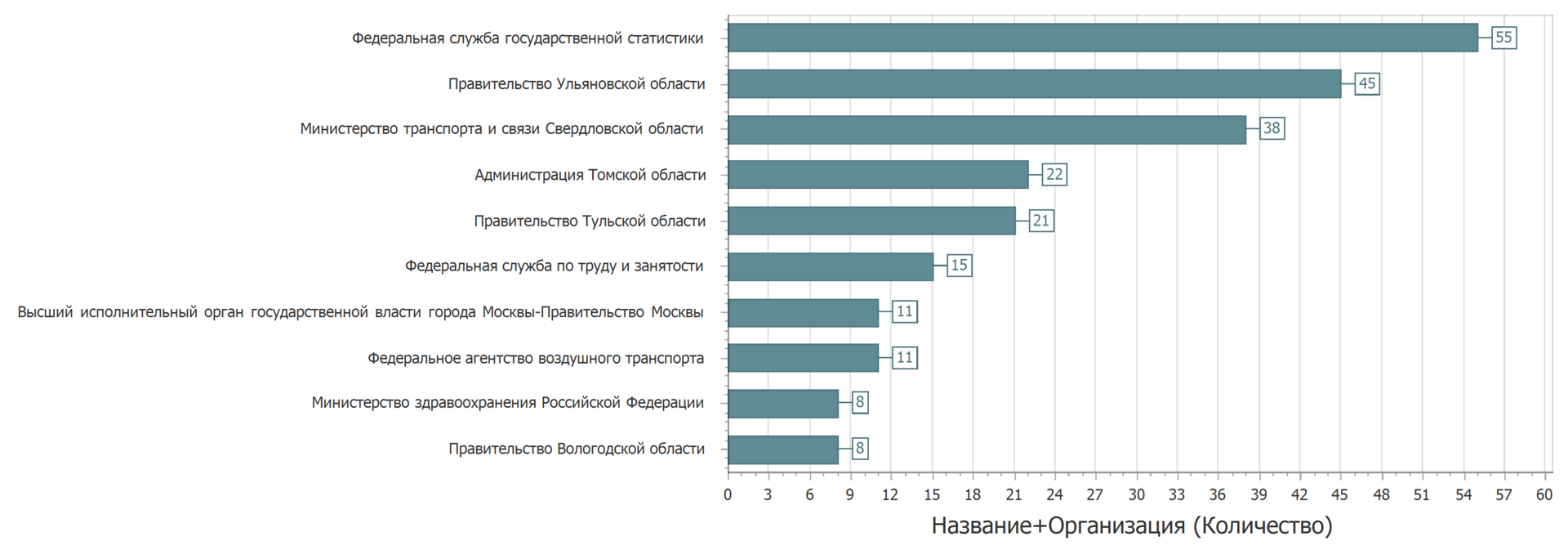
Em vez de atualizar, o conjunto de dados foi organizado novamente. Às vezes, os sets eram dispostos em uma categoria diferente. Mas se você olhar para conjuntos de dados com o mesmo nome, proprietário e categoria, a imagem será a seguinte.
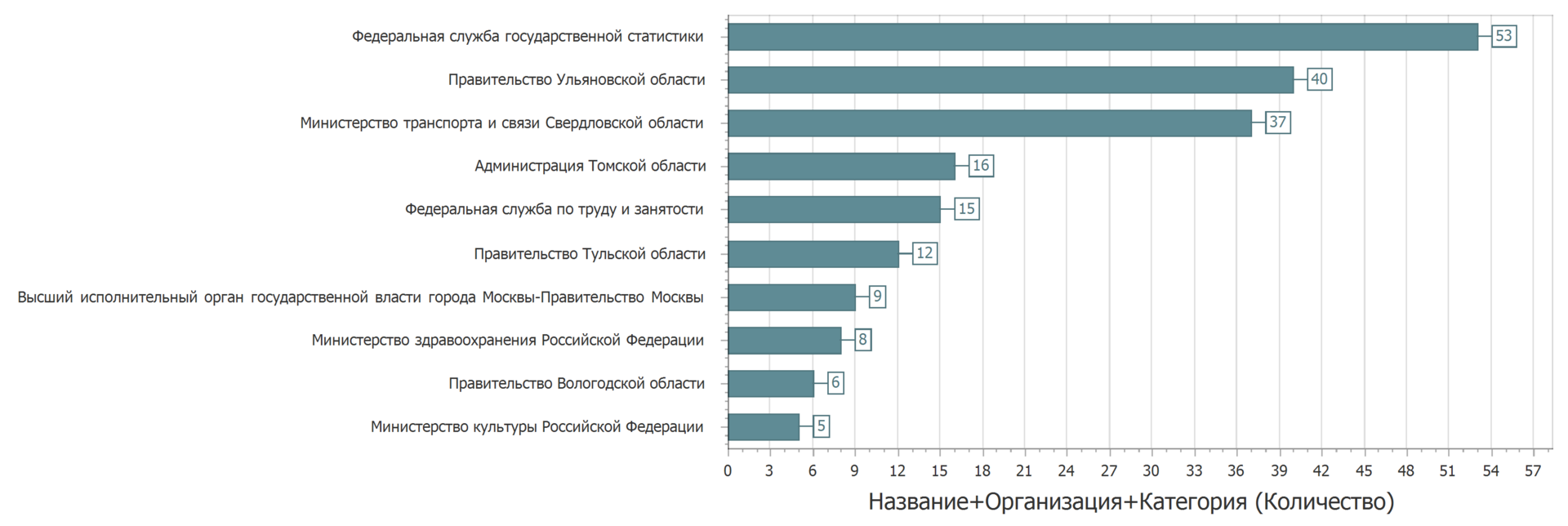
Pelo menos muito parecido. Mas dificilmente crítico. Alguns proprietários de dados, aparentemente, precisam espalhar cuidadosamente os dados.
Uma pequena verificação sobre o preenchimento dos campos de texto nos conjuntos de dados dos passaportes.
| O campo | Definido por | Não definido |
|---|
| Título | 100% | 0% |
| Descrição do produto | 80,84% | 19,16% |
| Categorias | 100% | 0% |
| O dono | 99,7% | 0,03% |
| Palavras-chave | 99,48% | 0,52% |
| Pessoa responsável | 96,43% | 3,57% |
| Número de telefone da pessoa responsável | 96% | 4% |
| E-mail da pessoa responsável | 92,68% | 7,32% |
| Formato de dados | 97,79% | 2,21% |
| Link de discagem | 96,86% | 3,14% |
O nome e a categoria são definidos em todos os lugares. Quase um quinto dos conjuntos de dados não contém uma descrição. Em quase todos os lugares o proprietário é conhecido e algumas palavras-chave são definidas. A pessoa responsável também está presente em quase toda parte. Não está claro por que precisamos de conjuntos de dados que não podem ser baixados (cerca de 3%).
Como resultado, dividimos todos os conjuntos de dados em duas categorias: todos os campos são especificados, pelo menos um campo não é especificado.

Trinta por cento (30,3%) tem pelo menos um campo indefinido. Em que formato os dados são enviados?
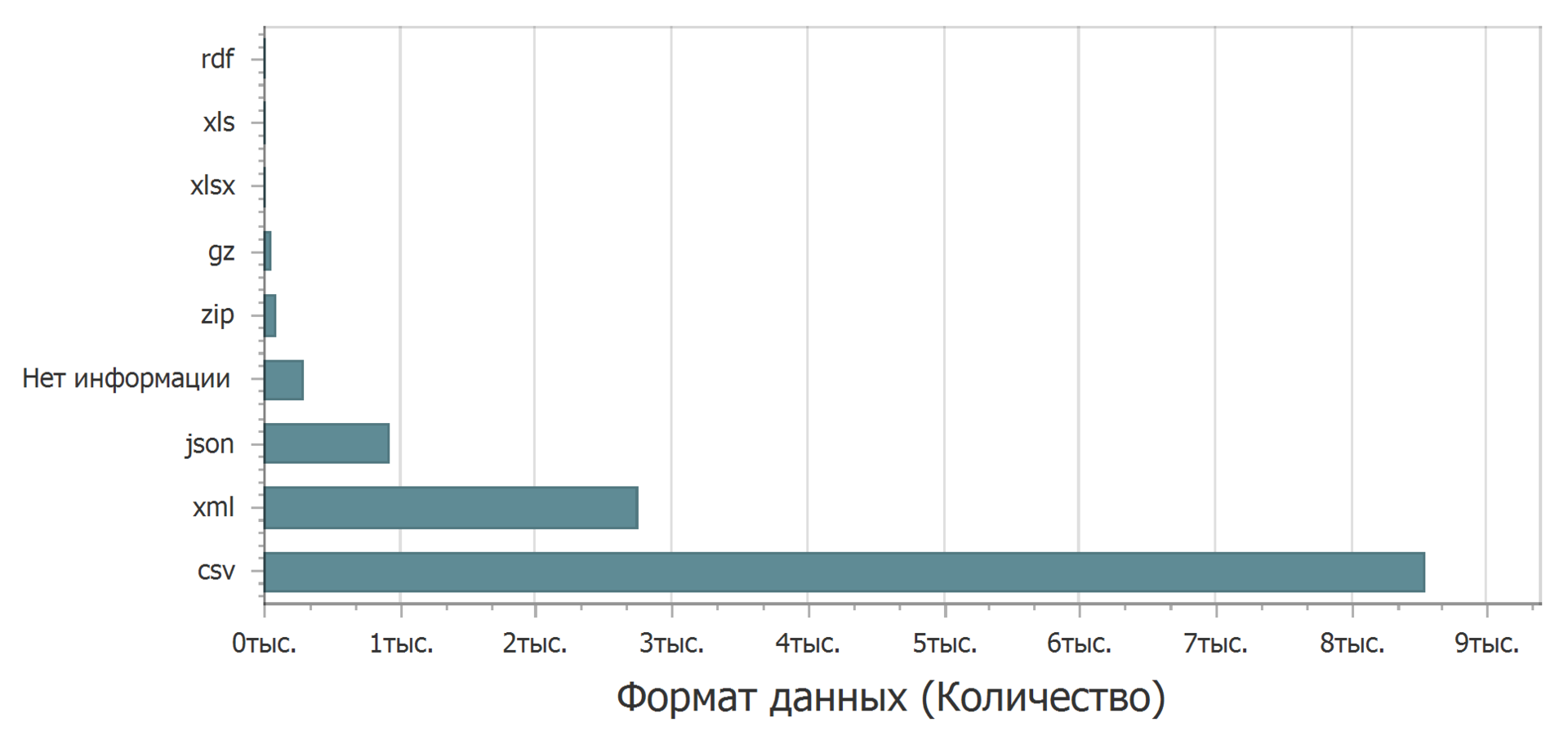
Principalmente em formato de texto delimitado simples (csv). Em segundo lugar, é xml. No terceiro json. O líder claro é o formato csv - você pode abri-lo em qualquer editor de texto, importá-lo para praticamente qualquer lugar para processamento e, com um pouco de esforço, inseri-lo como uma tabela em um editor de texto. O formato xml também é bastante fácil de ver. Mas com o formato json, pode haver problemas. Se você se concentrar no Excel, como o editor de planilhas mais usado, o json já é um problema. Você pode pesquisar no Google sobre este tópico e encontrar uma maneira de fazer o download, mas não direto. O Excel não possui ferramentas internas para carregar o json.
Obviamente, o problema é destemido, não fatal, mas desagradável. Certamente, este formato irá parar ou deixar perplexo alguém.
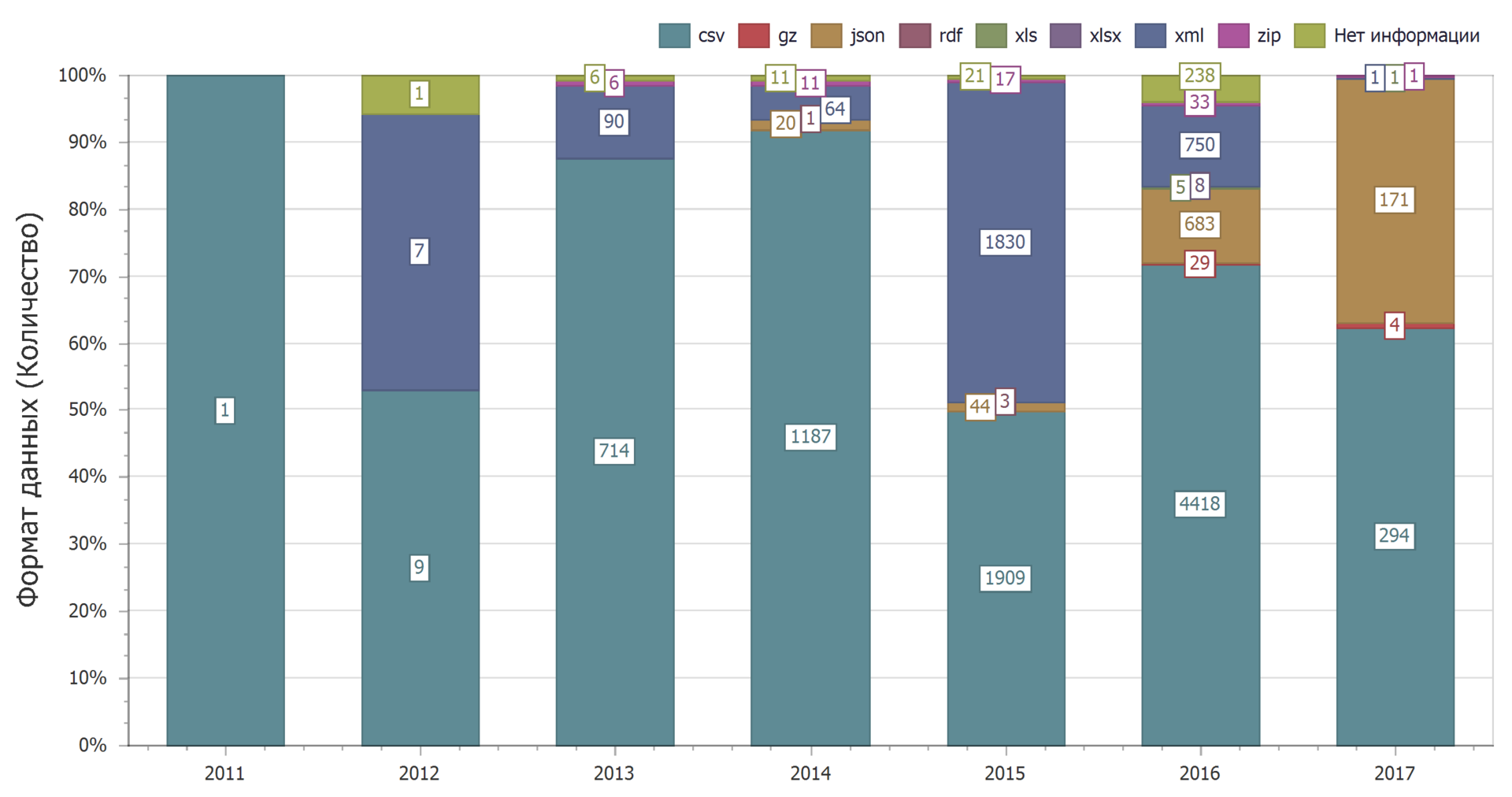
A distribuição por anos mostra que, com o tempo, a predominância do formato csv persiste.

O uso do formato json aumentará dramaticamente. Isso reduz o uso do formato xml.
E isso pode ser explicado. O formato csv é o mais simples, por isso é usado com frequência. Ao mesmo tempo, os serviços web agora estão cada vez mais usando o formato json e cada vez menos xml.
Conclusões
Mais da metade dos dados publicados no portal de dados abertos da Rússia pertence à categoria "Estado".
Mais da metade dos dados foi modificada ou criada pela última vez em 2016-2017.
Trinta por cento dos passaportes do conjunto de dados têm pelo menos um campo não atribuído.
Os formatos mais comuns para armazenar dados abertos: csv, xml, json. Ao mesmo tempo, há um aumento no número de conjuntos de dados no formato json e uma diminuição no número de conjuntos de dados no formato xml.
O que vem a seguir?
Depois de analisar os conjuntos de dados, vamos ver com que frequência eles são usados - visualizados, baixados. Quais classificações os usuários definem para conjuntos de dados? Quais conjuntos de dados são de interesse? Com que frequência os conjuntos de dados são atualizados? Qual o tamanho dos conjuntos de dados? E existe alguma relação entre tudo isso?