 Um exemplo de rede neural após o treinamento baseado em rostos de celebridades. À esquerda, está o conjunto inicial de imagens de 8 × 8 pixels na entrada da rede neural, no centro é o resultado da interpolação de até 32 × 32 pixels, de acordo com a previsão do modelo. À direita, estão fotografias reais de rostos de celebridades, reduzidas para 32 × 32, das quais foram obtidas amostras para a coluna da esquerda
Um exemplo de rede neural após o treinamento baseado em rostos de celebridades. À esquerda, está o conjunto inicial de imagens de 8 × 8 pixels na entrada da rede neural, no centro é o resultado da interpolação de até 32 × 32 pixels, de acordo com a previsão do modelo. À direita, estão fotografias reais de rostos de celebridades, reduzidas para 32 × 32, das quais foram obtidas amostras para a coluna da esquerdaÉ possível aumentar a resolução das fotos para o infinito? É possível gerar imagens confiáveis com base em 64 pixels? A lógica sugere que isso é impossível.
A nova rede neural do Google Brain pensa de maneira diferente. Realmente aumenta a resolução das fotos para um nível incrível.
Essa "super-resolução" não é uma restauração da imagem original de uma cópia de baixa resolução. Esta é uma síntese de uma fotografia crível que
provavelmente poderia ser a imagem original. Este é um processo probabilístico.
Quando a tarefa é "aumentar a resolução" de uma fotografia, mas não há detalhes a serem aprimorados, a tarefa do modelo é gerar a imagem mais plausível do ponto de vista humano. Por sua vez, é impossível gerar uma imagem realista até que o modelo tenha criado os contornos e tomado uma decisão "decidida" sobre quais texturas, formas e padrões estarão presentes em diferentes partes da imagem.
Por exemplo, basta olhar para o KDPV, onde na coluna da esquerda há imagens reais de teste para a rede neural. Eles não têm detalhes de pele e cabelo. Eles não podem de forma alguma ser restaurados pelos métodos tradicionais de interpolação, como linear ou bicúbico. No entanto, se você tiver um conhecimento profundo sobre toda a diversidade de rostos e seus contornos típicos (e sabendo que é necessário aumentar a resolução da face aqui), a rede neural poderá realizar uma coisa fantástica - e "desenhar" os detalhes ausentes que provavelmente estão lá.
Especialistas do Google Brain publicaram o artigo científico
Recursive Pixel Super Resolution, que descreve um modelo totalmente probabilístico treinado em um conjunto de fotografias de alta resolução e suas cópias reduzidas de 8 × 8 para gerar imagens de 32 × 32 a partir de pequenas amostras de 8 × 8.
O modelo consiste em dois componentes treinados simultaneamente: uma rede neural condicionante e uma rede anterior. O primeiro deles sobrepõe efetivamente uma imagem de baixa resolução na distribuição das imagens de alta resolução correspondentes e o segundo modela detalhes de alta resolução para tornar a versão final mais realista. Uma rede neural com ar condicionado consiste em unidades
ResNet , e a anterior é uma arquitetura
PixelCNN .
Esquematicamente, o modelo é representado na ilustração.
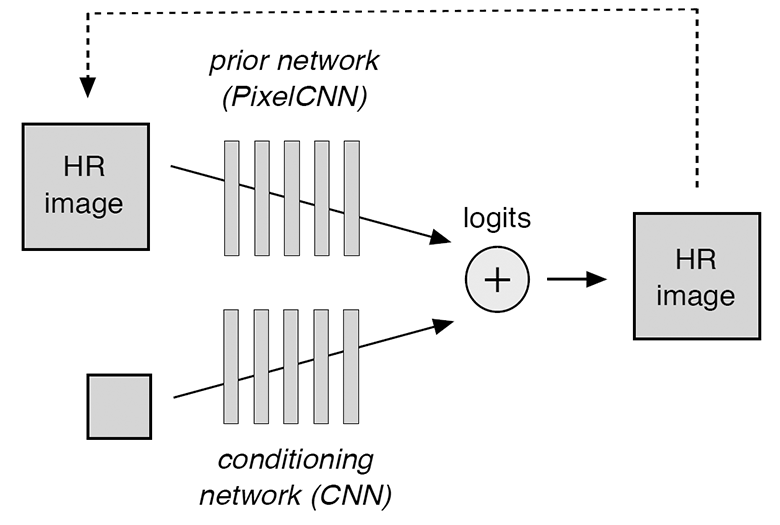
Uma rede neural convolucional condicionada recebe imagens de baixa resolução na entrada e produz logits - valores que prevêem a probabilidade condicional de logit para cada pixel em uma imagem de alta resolução. Por sua vez, a rede neural convolucional anteriormente faz previsões baseadas em previsões aleatórias anteriores (indicadas por uma linha tracejada no diagrama). A distribuição de probabilidade para todo o modelo é calculada como um operador de softmax em cima da soma de dois conjuntos de logits de uma rede neural condicionada e anterior.
Mas como avaliar a qualidade dessa rede? Os autores do trabalho científico chegaram à conclusão de que métricas padrão, como razão de pico de sinal para ruído (pSNR) e similaridade estrutural (SSIM), não são capazes de avaliar corretamente a qualidade da previsão para esses problemas de aumento super-forte na resolução. De acordo com essas métricas, o melhor resultado são imagens borradas, não imagens fotorrealistas nas quais detalhes claros e confiáveis não coincidem no local da colocação com os detalhes claros da imagem real. Ou seja, essas métricas pSNR e SSIM são extremamente conservadoras. Estudos mostraram que as pessoas podem distinguir facilmente fotos reais de opções borradas criadas por métodos de regressão, mas não é tão fácil para elas distinguir entre as amostras geradas pela rede neural e fotos reais.
Vamos ver quais resultados o modelo desenvolvido pelo Google Brain e treinado em um conjunto de 200.000 rostos de celebridades (conjunto de fotos CelebA) e 2.000.000 quartos de dormir (conjunto de fotos LSUN Bedrooms) mostra. Em todos os casos, as fotos antes do treinamento do sistema foram reduzidas para um tamanho de 32 × 32 pixels e novamente para 8 × 8 usando o método de interpolação bicúbica. Redes neurais TensorFlow treinadas em 8 GPUs.
Os resultados foram comparados em duas bases principais: 1) regressão pixel a pixel independente (regressão) com uma arquitetura semelhante à rede neural
SRResNet , que mostra excelentes resultados em métricas padrão para avaliar a qualidade da interpolação; 2) procure o elemento vizinho mais próximo (NN), que pesquisa no banco de dados de amostras educacionais de baixa resolução a imagem mais semelhante pela proximidade de pixels no espaço euclidiano e, em seguida, retorna a imagem de alta resolução correspondente a partir da qual essa amostra educacional foi gerada.
Deve-se notar que o modelo probabilístico produz resultados de qualidade diferente, dependendo da temperatura do softmax. Foi estabelecido manualmente que os valores ótimos
situam-se entre 1.1 e 1.3. Mas mesmo se você instalar
de qualquer maneira, os resultados serão diferentes a cada vez.
 Resultados diferentes ao iniciar um modelo com temperatura softmax
Resultados diferentes ao iniciar um modelo com temperatura softmax Você pode avaliar a qualidade do trabalho do modelo probabilístico pelas amostras sob o spoiler.
Comparação de resultados de quartos Comparação de resultados de rostos de celebridades Para verificar o realismo dos resultados, os cientistas realizaram uma pesquisa sobre crowdsourcing. Aos participantes foram mostradas duas fotografias: uma real e a segunda gerada por vários métodos a partir de uma cópia reduzida de 8 × 8 e solicitadas a indicar qual fotografia foi tirada pela câmera.
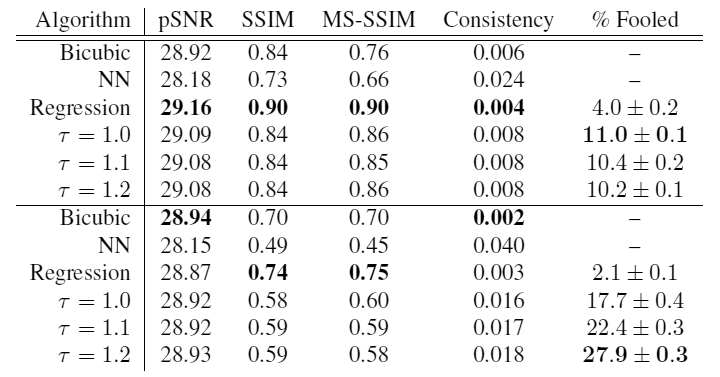
No topo da tabela estão os resultados para a base de celebridades e abaixo para os quartos. Como você pode ver, a temperatura
nas fotografias dos quartos, o modelo apresentou o resultado máximo: em 27,9% dos casos, sua entrega mostrou-se mais realista do que a imagem real! Este é um sucesso claro.
A ilustração abaixo mostra o trabalho mais bem-sucedido da rede neural, na qual ela "supera" os originais em termos de realismo. Por objetividade - e algumas das piores.

No campo da geração de imagens fotorrealistas usando redes neurais, agora é observado um desenvolvimento muito rápido. Em 2017, certamente ouviremos muitas notícias sobre esse tópico.