1. Introdução
Era uma vez, quando tudo era grande e eu era pequeno, li o livro Radio-electronic Toys de Wojciechowski, ansioso por dar vida aos dispositivos descritos nele. Assim, no já distante ano de 2008, dentre várias dezenas de relés eletromagnéticos, foi montada uma ALU de 4 bits ( RCVM1 - Máquina de computação digital com relés - versão 1 ), capaz de adicionar e subtrair. E então pensei - e se eu montar um número significativamente maior de relés e construir um computador de relé de pleno direito? Foram necessários apenas 8 anos para montar lentamente o relé aqui e ali até o número necessário, e comecei a criar.
Deixe-me apresentar seu projeto para criar uma segunda versão de um computador de retransmissão digital, com o codinome “BrainfuckPC” - um computador de 16 bits com arquitetura Von Neumann e um conjunto de instruções para a linguagem Brainfuck. O trabalho de design está concluído e estou no processo de criar esse monstro.

1 Especificações
- Largura do barramento de endereço: 16 bits
- Endereçamento: palavra por palavra, 16 bits / palavra
- Capacidade de memória: 64 Kiloslov (128KB)
- Largura do barramento de dados: 16 bits
- Espaço de endereço unificado para código e dados (arquitetura Von Neumann)
- Frequência do relógio (design): 100 Hz, 1 instrução / ciclo
- Conjunto de instruções: Brainfuck ++
- Número de relés (design): 792
- Relés usados: reed switches, RES55 (1p), RES64 (1z)
Detalhes rolados
Princípio geral do trabalho
Considere a estrutura generalizada de um computador:
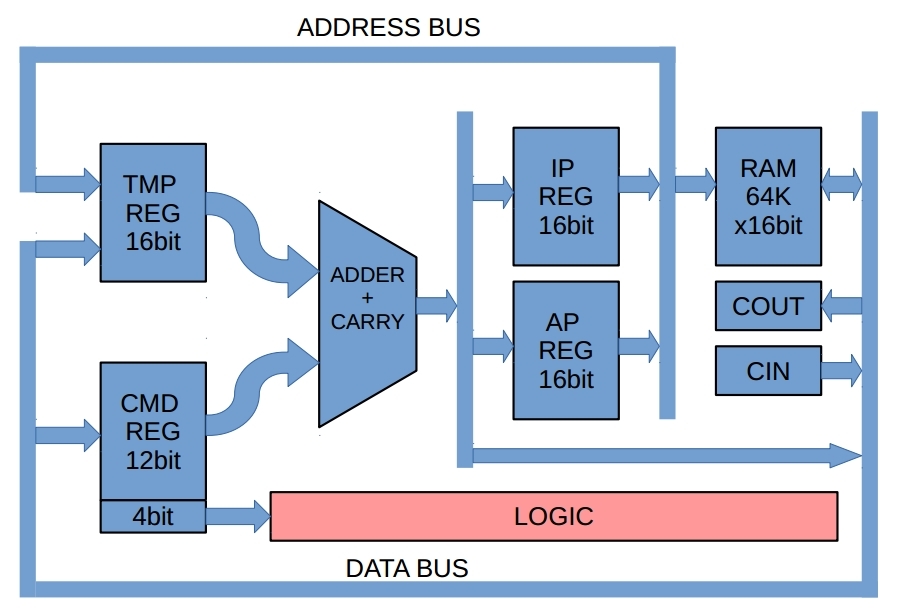
Figura 1: Estrutura geral do computador
O elemento central é o somador, e não é simples, mas com transferência paralela. Por que isso é necessário - vou contar um pouco abaixo.
O programa e os dados são armazenados em um bloco de memória. O acesso a eles é realizado no endereço registrado no registro de instruções IP ou no registro de endereços AP, com base no que agora queremos ler - dados no endereço especificado no AP ou na instrução registrada no endereço IP.
Para operar essa fita de Turing (e a linguagem de programação Brainfuck a identifica com precisão), precisamos ser capazes de executar uma das três ações:
- Altere o valor na célula de dados atual, ou seja, faça as operações Adicionar / Sub. No Brainfuck, o valor na célula só pode ser alterado por um, ou seja, +1 ou -1. Mas ter um somador completo, é um pecado não colapsar cadeias longas +++++++++++++ (------------) em uma operação AP + = N ( AP- = N) acelerando significativamente o processo cálculos. (também não esqueça de transformar [-] (ou [+]) em * AP = 0);
- Altere o número da célula de dados atualmente selecionada. Ou seja, percorrendo a memória de dados (AP ++, AP--);
- Mude o número da instrução atual. Primeiro, após cada instrução, precisamos aumentar o valor no registro IP em um. Em segundo lugar, altere esse valor se houver ramificações no código (por padrão, para organizar loops). Há apenas um sinalizador de controle - Z. Consequentemente, existem os comandos JumpIfZero e JumpIfNotZero.
No total, precisamos fornecer a uma entrada do somador o valor de qualquer um dos três blocos a seguir - registro AP, registro IP, barramento DATA. Faremos isso através de um registro temporário, no qual salvaremos um dos valores necessários, conectando o desejado usando chaves de 16 bits.
Na segunda entrada do somador, enviaremos um número pelo qual um desses valores deve mudar para mais ou menos. Devido à largura limitada da instrução, você só pode alterá-lo por um número de + -12 bits. No entanto, para Brainfuck, isso é mais do que suficiente ("o suficiente para todos", sim).
Tiraremos esses 12 bits do registro de comandos, na presença de tais comandos é natural, porque parte dos comandos não usa o somador. Não se esqueça que números negativos serão exibidos no código aumentado, com apresentação de extra. entrada de transferência de unidade (ou seja, será A + invB + 1)
O resultado do cálculo é carregado imediatamente para onde o obtivemos. Devido ao registro temporário, podemos fazer isso sem problemas.
Mais detalhes (eu diria mesmo chatos) sobre arquitetura podem ser encontrados neste vídeo:
Conjunto de instruções
Tendo desenhado um diagrama esquemático geral capaz de implementar 8 instruções básicas do Brainfuck, percebi que ele tem um potencial muito maior. Portanto, desenvolvi um conjunto mais amplo de instruções compatíveis com o Brainfuck, mas requer a compilação de cada instrução Brainfuck de origem em uma instrução de computador de 16 bits.
Descrição Geral das Instruções
Todas as instruções são de 16 bits. Formado de várias partes.
- Bits 15, 14, 13 - determine a classe de instrução
- Bit 12 - Bit de sinal para obter instruções de sinal
- Bits 11-0 - contêm os 12 bits inferiores do int-a assinado. Os 4 bits mais significativos são formados de acordo com o valor do 12º bit.
Tabela de instruções
| Manual de instruções | Opcode | Operação | Equivalente a Brainfuck | Descrição do produto |
|---|
| add m16 | 0X XX | AP ← AP + m16 | '+' (Repetir m16 vezes) | Adiciona a base ao valor atual da célula selecionada |
| sub m16 | 1X XX | ← AP - m16 | '-' (Repetir m16 vezes) | Consequentemente, subtrai a base de |
| ada m16 | 2X XX | AP ← AP + m16 | '>' (Repetir m16 vezes) | Aumenta o valor do endereço |
| ads m16 | 3X XX | ← AP - m16 | '<' (Repetir m16 vezes) | Diminui o valor do endereço. |
| jz m16 | 4X XX | (* AP == 0)? IP ← IP + m16: IP ← IP | '[' | Vá para IP + m16 se o valor da célula atual for zero |
| jz m16 | 5X XX | (* AP == 0)? IP ← IP - m16: IP ← IP | Não | Vá para IP - m16 se o valor da célula atual for zero |
| jnz m16 | 6X XX | (* AP! = 0)? IP ← IP + m16: IP ← IP | Não | Vá para IP + m16 se o valor da célula atual não for zero |
| jnz m16 | 7X XX | (* AP! = 0)? IP ← IP - m16: IP ← IP | ']' | Vá para IP - m16 se o valor da célula atual não for zero |
| e m16 | 8X XX | AP ← AP E m16 | Não | E lógico com um número positivo |
| e m16 | 9X XX | AP ← AP E m16 | Não | AND lógico com um número negativo (outra pessoa deve formar os 4 bits mais altos) |
| ou m16 | aX XX | AP ← AP OU m16 | Não | OR lógico com constante positiva |
| ou m16 | bX XX | AP ← AP OU m16 | Não | OR lógico com constante negativa |
| em | c0 00 | * AP ← CIN | ',' | Leia um caractere m8 no console. Se o buffer de entrada estiver vazio, aguarde. |
| fora | c0 01 | COUT ← * AP | '.' | Imprimir caracteres m8 no console |
| clr.ap | d0 01 | AP ← 0 | Não | Limpe o registro AP. O comando permite combinação |
| clr.ip | d0 02 | IP ← 0 | Não | Limpe o registro IP. O comando permite combinação |
| clr.dp | d0 04 | * AP ← 0 | '[+]' ou '[-]' | Limpar célula de memória. O comando permite combinação |
| set.ap | d0 10 | AP ← * AP | Não | Escreva o valor atual no registro AP |
| set.ip | d0 20 | IP ← * AP | Não | Grava o valor atual no registro IP |
| get.ap | d1 00 | * AP ← AP | Não | Ler o valor atual do registro AP |
| get.ip | d2 00 | * AP ← IP | Não | Ler o valor atual do registro IP |
| mode.b8 | e1 00 | | Não | Ativação de 8 bits (1) |
| mode.b16 | e2 00 | | Não | Ativação de 16 bits |
| parar | f0 00 | | Não | Pare a máquina |
- AP - Registro de Endereço
- IP - Registro de Instruções
- * AP - localização atual da memória
- CIN - Entrada do console
- COUT - Saída do console
- Quando o modo de 8 bits é ativado, o somador continua a operar no modo de 16 bits. No entanto, instruções condicionais (ou seja, testar o valor da célula de memória atual quanto à igualdade de zero) tornam-se 8 bits. ( AP & 0x00FF == 0)? e ( AP & 0x00FF! = 0)? Até agora, a entrada e saída do console decidiram sair sempre de 8 bits. Não está em Unicode para imprimir no final?
Neste vídeo, falei em detalhes (mas pouco entendido) sobre o que cada instrução faz e a que instruções sobre o cérebro corresponde:
Adicionador paralelo
Os computadores de retransmissão devem ser não apenas retransmitidos, mas também rápidos. Como qualquer outro computador, o meu também será uma máquina síncrona, equipada com um gerador de relógio. Naturalmente, gostaria de não desperdiçar ciclos de relógio e tentar ajustar cada operação em um ciclo - ou seja, para as bordas ascendentes e descendentes do gerador síncrono, tenho tempo para carregar um novo comando e executá-lo. Ao mesmo tempo, é desejável que todos os comandos sejam executados pelo mesmo período de tempo.
Cada relé possui um certo atraso na operação e liberação, o que levaremos por 1 unidade de tempo convencional (cu) Se usarmos o relé RES22, 1u.e. será igual a 12-15ms (informativo), RES64 - 1,3ms (informativo). A operação mais cara (e mais frequente) no meu carro é o somador.
Por si só, é bastante simples e rápido, mas "há uma ressalva" que reside no método de calcular e transmitir o sinal de transferência.
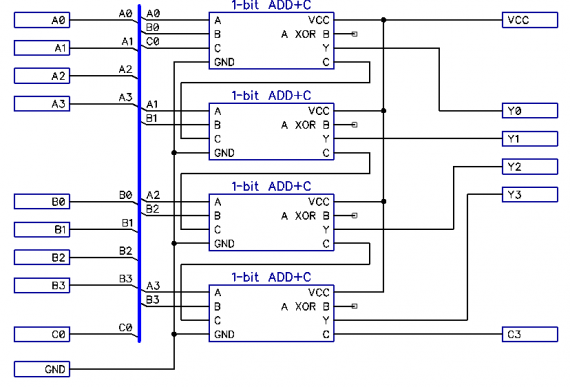
Figura 2: Adicionador de transferência serial.
Inicialmente, planejei usar um somador de transporte sequencial. Nesse adicionador, cada descarga subsequente depende do estado do sinal de transferência de descarga do atual. Como resultado, a duração da operação de cálculo variará entre 2 - N * 2 cu, onde N é o número de dígitos. Como resultado, um somador de transporte sequencial de 16 bits terá um atraso máximo de 32
Os carregadores de transporte paralelo oferecem desempenho máximo. Faltam os processos de propagação de transferências de descarga em descarga. Em cada categoria, os valores de saída são gerados simultaneamente:

Figura 3: Adicionador de transporte paralelo
A capacidade de construir um somador com as propriedades indicadas baseia-se na reprodução das funções de soma e transferência, que dependem apenas dos valores dos termos, independentemente da localização da descarga na grade de descarga. O problema é que o próprio esquema de transferência paralela se torna mais complicado a cada descarga subsequente. Aqui, veja o que acontece:
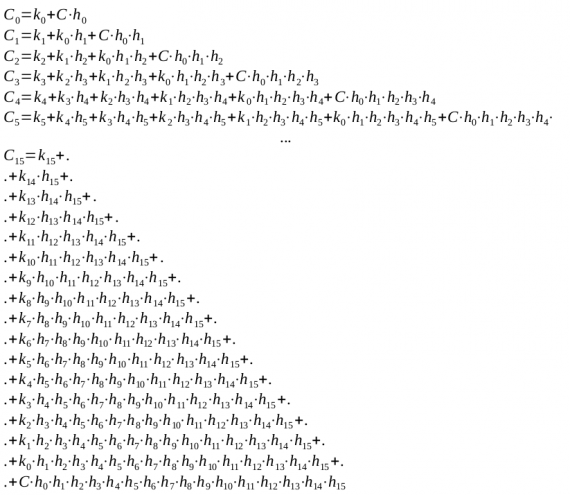
Figura 4: (que deveria estar na forma de fórmulas LaTeX, mas não) A equação para calcular o sinal de transferência para os bits. Onde - bit a bit E, - OR bit a bit
Como resultado, implementar a migração paralela é bastante caro. No entanto, pode-se notar que a descarga subsequente contém a equação para o cálculo da anterior (deve haver um meme “ok? Com Meme com Nicolas Cage); portanto, em princípio, será suficiente fazer um esquema de cálculo de transferência apenas para a descarga sênior e coletar o restante, fornecendo conclusão de resultados intermediários.

Figura 5: Diagrama completo de um somador paralelo de 16 bits
Na Figura 5, as duas primeiras colunas são os próprios adicionadores. Em seguida, vêm os blocos 2AND e 2OR, que formam os valores intermediários de hek, mostrados na Figura 4. A presença deles me levou a expandir a lista de comandos com as operações lógicas de adição e multiplicação, para as quais eu só preciso adicionar algumas travas e o microcódigo correspondente.
Tudo o resto são blocos 5AND baseados em 4 relés RES64, que podem ser soldados para que um módulo possa ser usado como, por exemplo, 2AND + 3AND. Para esses blocos, cada passo AND lógico é emitido através de um diodo, que permite coletar sinais de transferência intermediários.
Tempo estimado de propagação do sinal: os somadores lidam com 1 cu, neste momento os sinais são gerados nas saídas dos blocos 2AND / 2OR e, em seguida, 1 cu - por multiplicação em blocos 5AND, adição lógica em diodos, não introduz atraso. Bem, o último gasto em recalcular o somador.
Total 3 cu versus 32 ou, no máximo, 4,5 ms para o somador.
Registros
Existem quatro registros especializados de 16 bits na máquina. Sem RONs. Apenas ligação apertada, apenas hardcore! Consiste em D-flip-flops, cada D-flip-flop é um módulo separado em 4 relés RES55 com o seguinte circuito:

Figura 6: Diagrama esquemático do módulo D-flip-flop. Em algum lugar ainda existe um conector, mas aqui não é importante, porque tudo está assinado.
Os dados chegam à entrada de dados, cujo relé determina para onde o sinal de sincronização irá - redefinir o gatilho ou instalá-lo (pelo qual mais dois relés são responsáveis, um com travamento automático). O quarto relé obtém a saída de comutação Q. Um recurso muito útil.
Placa de memória

Figura 7: Placa de memória. Dimensões da placa 315x200mm
Um elemento muito complexo e importante, embora o próprio circuito de memória seja uma pequena parte do preenchimento total do bloco. A tarefa deste fórum é, em primeiro lugar, transportar 64 quiloslovos da memória total de programas e dados. Ele é montado com base em dois chips de cache de 64 Kbyte. A entrada de endereço através dos circuitos de proteção e do comutador é conectada ao barramento de endereços do computador e, no lado do barramento de dados, um sistema complexo de buffer de entrada e driver de saída, também com o comutador. Para ler e gravar na memória, duas linhas W / R e Sync são responsáveis. O primeiro escolhe o que faremos, o segundo - realmente fará.
E embora esse Sync em si não esteja lá, o cartão de memória naturalmente vive sua própria vida. Na renderização, você pode ver duas matrizes de LED 16x16. Este visor mostra alguma área de memória. Uma espécie de VideoRAM, determinada programaticamente, a propósito. Interroga o chip de memória e controla a saída do microcontrolador Atmega1280.
Para o sim, as tarefas do microcontrolador não param por aí. A entrada e saída do console dependem dele. Onde será exibido - ainda não decidi, portanto, o conversor USB-Serial para um console comum e o ESp8266 para Wi-Fi estão divorciados na placa. Segundo o último, nos planos mais urgentes de ter uma página da web com a capacidade de baixar programas para o computador na memória e no próprio console. Sim, as tarefas do MK também incluem o carregamento inicial do programa na RAM, para o qual ele tem acesso total à RAM, bem como uma pequena entrada EEPROM de 1 Mbit para armazenar programas.
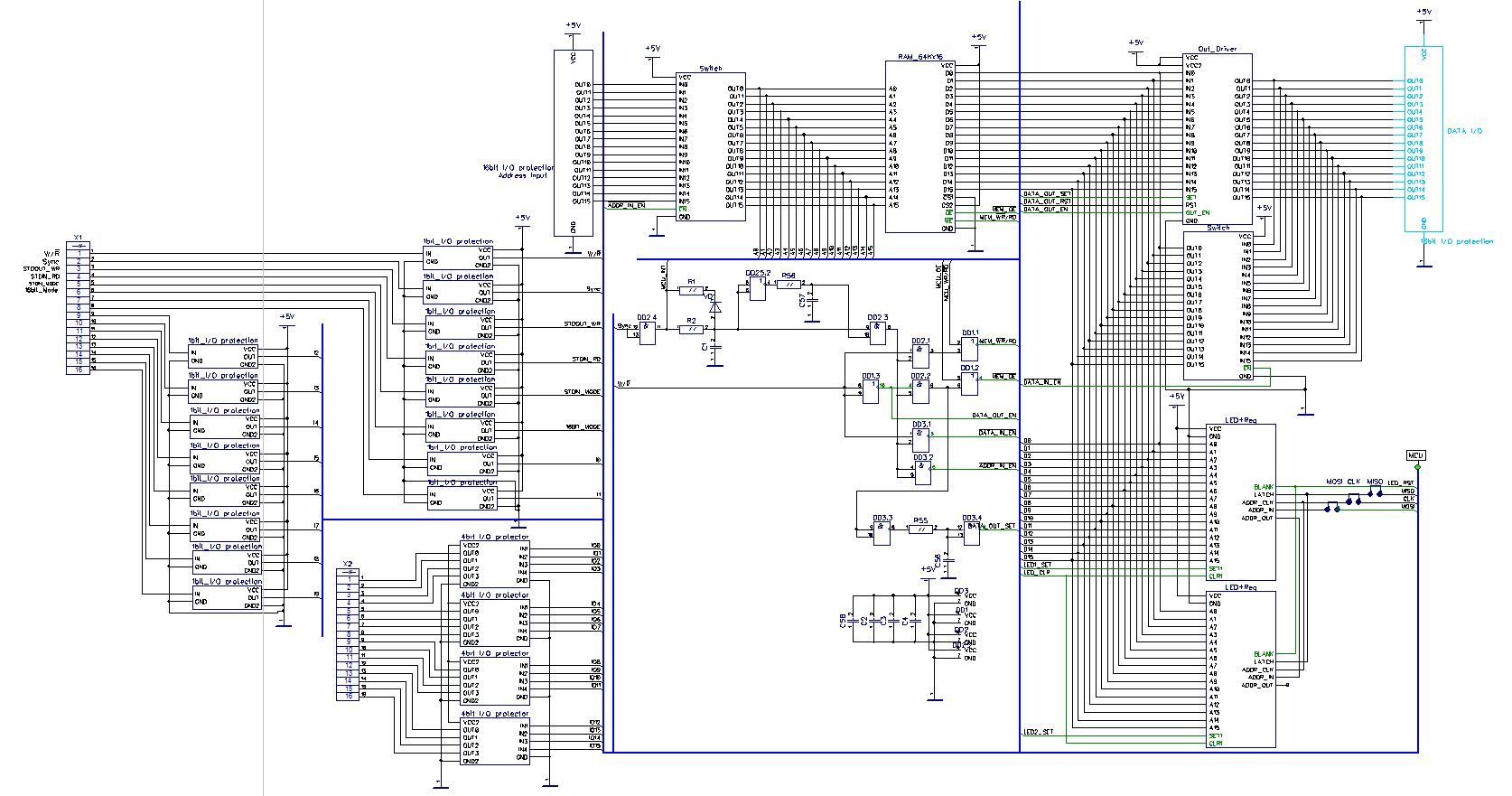
Figura 8: Diagrama esquemático de um cartão de memória. Diagramas de microcontrolador e bloco não mostrados
Bloco lógico
Não tenho ideia de como ele vai acabar procurando. A versão mais recente está presente no circuito geral do computador, mas eu não gosto. Provavelmente eu farei um sequenciador de 12 estágios e, com a ajuda das teclas, enviarei sinais para blocos individuais.
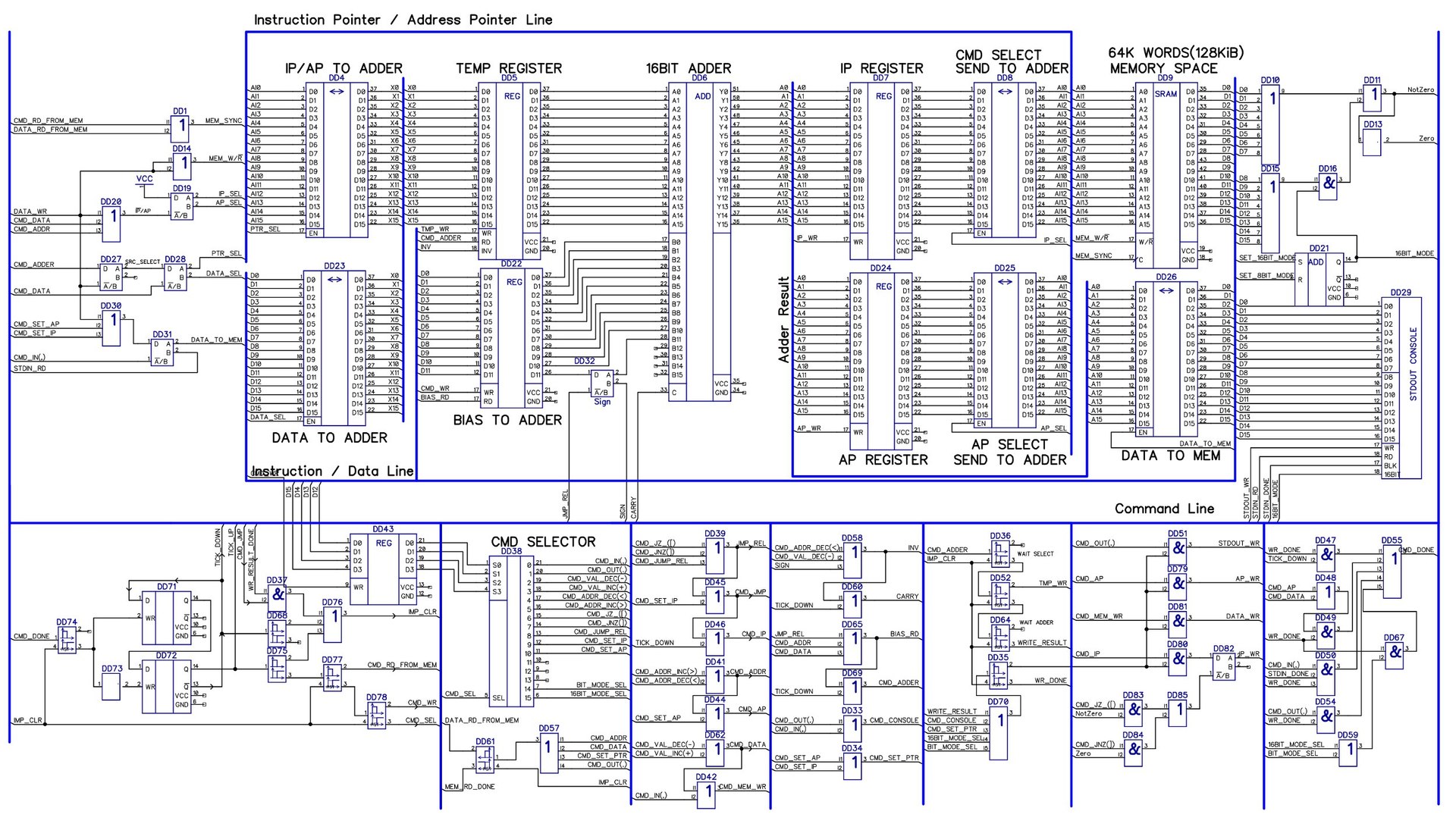
Figura 9: Tudo em torno dos blocos de 16 bits é um bloco lógico
Construção civil
O design da máquina é modular, estrutura em bloco. O KDPV mostra claramente como o enchimento da máquina será localizado. Mas as primeiras coisas primeiro:
Módulo
O elemento básico do computador é um módulo de 60x44mm, com um conector de 16 pinos, transportando 4 relés, seus chicotes e 4 LEDs para indicar:

Figura 10: Modelo 3D do módulo
Módulos de vários tipos:
- Somador de 1 bit com transferência - 16 peças;
- Módulo 5AND para circuito de transferência paralelo - 32 peças;
- Módulo D-flip-flop - 64 pcs por registro, além de um pouco de lógica;
- Módulo 4x2AND_SW, para organização de travas. Existem apenas 4 relés de fechamento;
- Módulo 4x2AND, para organizar travas. Existem 3 de 4 relés com um contato de comutação. Em 4 relés não havia pino de saída suficiente;
- O módulo é um diodo, 8 diodos D226D. Para organizar um OR com várias entradas
- O módulo universal 2AND / 2OR permite criar 2AND-NOT, 2OR-NOT, 4AND, 4AND-NOT, 4OR, 4OR-NOT e qualquer combinação. Baseado em 4 relés com comutação de contatos e pontos comuns;
Como eu, apesar de ter encontrado um bloco de lógica de controle, já rejeitado, não sei o número exato de módulos de cada tipo. Eu vou descobrir isso na estrada. O número estimado de módulos é de 192 peças.
Bloquear
Pegamos uma placa de 150x200mm, soldamos 32 conectores com 16 pinos, mas não é simples, mas para finalizar e instalar nossos módulos em uma matriz 8x4, obtendo um bloco:

Figura 11: Bloco
No meu carro, haverá 6 desses blocos - dois blocos por somador, dois blocos por registrador e dois blocos por lógica. Eu arranho nabos em mais alguns blocos de trincos, mas se estiverem, são planos e soldados
A instalação envolvente foi escolhida porque: em primeiro lugar, os circuitos de cada placa base, embora sejam conhecidos antecipadamente, podem mudar e estão sujeitos a erros. Em segundo lugar, em princípio, é impossível separar corretamente o bloco lógico pela primeira vez, e se tudo estiver claro para o bloco de registro e você pode cometer um erro com, digamos, uma linha de sincronização, será necessário refazer a lógica mil e uma vezes. Será muito melhor se você coletar cada componente do bloco lógico gradualmente. Terceiro, um fator puramente mecânico - é fisicamente impossível separar esses blocos em uma placa de duas camadas :) Os pneus de 16 bits divergem em várias direções, que se cruzam repetidamente.
No total, cada unidade contém 32 módulos, com um número total de relés de 128 peças. A potência de cada unidade é 5V 2A.
Computador
Em um quadro grande, dimensões 640x480 mm (na verdade um pouco mais, mas o número é bonito), existem seis blocos de relés e uma placa de memória:
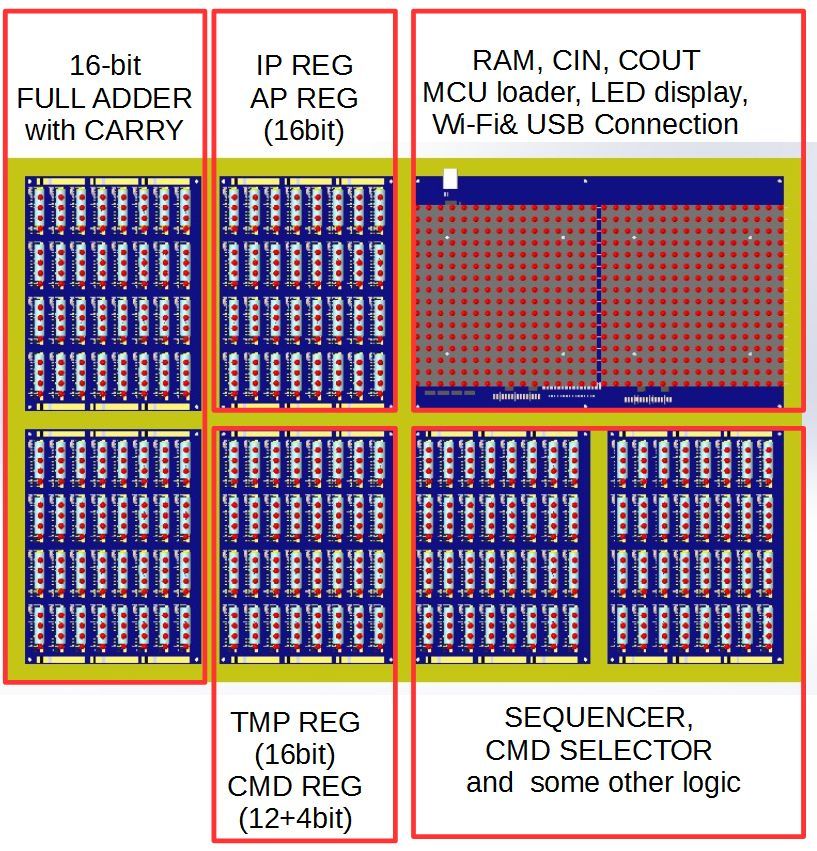
Figura 12: Localização do bloco da máquina
Todo o computador é inserido em uma moldura de madeira feita de madeira preciosa, com frente e traseira de vidro.
Fabricação
Apesar da data atual, o projeto realmente existe :-) E não está no estágio mais ativo, mas ainda está em fabricação.
Relé
Eu os tenho. Em grande número, mas o problema é que existem trezentas ou mais que mil ações - um relé de 27 Volts e 5 volts RES55 pode não ser suficiente para mim. Não posso finalmente estimar a escala do desastre, mas acho que na próxima vez que coletar essa máquina infernal, o problema desaparecerá devido ao reabastecimento externo.

Figura 13: Reservas de retransmissão. 800 peças de revezamento - novas, apreendidas com sucesso no mercado de rádio Mitsa por um centavo
Uma das fontes de reabastecimento são as placas de relé DAC das fontes de alimentação do laboratório. Aqui estão estes:

Figura 14: Placas de fontes de alimentação do tipo PSU adquiridas no mercado de rádio (não, eu não
Placas de circuito impresso
Decidi fazer todas as placas de circuito impresso. Prendi 300 dólares aos chineses e, há 4 meses, faço o trabalho de cobrir os espaços em branco com fotorresiste, translúcido, gravura, cobrindo com uma máscara de solda, desenvolvendo, perfurando e fresando.

Figura 15: Painéis gravados de vários tipos
Faço placas em placas, 9 módulos em uma placa de 200x150mm. Gravado 30 placas e preso na aplicação de uma máscara de solda. Eu não vou começar. A máscara de solda do meu FSR-8000 é azul, de dois componentes, e eu já lidei com isso antes.
As placas de 200x150 mm não foram escolhidas por acaso - nós as temos no mercado de rádio, em um local secreto, elas estão vendendo estavelmente por muitos anos, e todo o meu dispositivo é adaptado para este formato.
Em uma palavra, comecei a aplicar o fotorresiste (MPF-VSC da Diazonium) usando um laminador e esses são apenas milagres. A qualidade da colagem aumentou significativamente.
Então será necessário cortar e perfurar essas placas, para as quais eu tenho até uma fresa 3D.

Figura 16: Fresadora 3D 2020CNC chinesa DIY
Levei por modestos 175 dólares exclusivamente para eletrônicos. É o suficiente para perfurar e fresar placas, e já estou vendo conjuntos de parafusos de esferas + trilhos para máquinas 3D. Pronto para comprar um pouco caro, mas para montar você mesmo quando começar a ser necessário - é isso.
:
, . ( ) Elf. , ( ). //TODO — , .
: . , . . Segmentation Fault!
, . — . leBrainfuck , .
, , Brainfuck . +-<>, [-] . , . , .
. 8 . :

— 10 . LLVM 0,9 . Intel Vtune Amplifier 120 10 .
. , 3 brainfuck-. 100 50 347 — .. , ! , , . .
, , ,
.
-6 , , . — , . — . - — 30-40 - 6 .
????777

Referências
openSource. :
- https://github.com/radiolok/RelayComputer2 - um repositório com diagramas esquemáticos e layouts de PCB. Um link para o repositório de firmware da placa de memória acrescentarei mais tarde
- https://github.com/radiolok/RelayComputer2/blob/master/roadmap.md Marcarei esta página separadamente com o roteiro do projeto no qual as principais alterações são registradas.
- https://hackaday.io/project/18599-brainfuck-relay-computer nesta página Publico relatórios detalhados sobre o que foi feito. De acordo com o conjunto de massa crítica, eles se transformarão em um artigo sobre GT.
- https://github.com/radiolok/bfutils compilador e emulador.