
Hoje, o gráfico é uma das maneiras mais aceitáveis de descrever os modelos criados no sistema de aprendizado de máquina. Esses gráficos computacionais são compostos de vértices de neurônios conectados por arestas de sinapse que descrevem as conexões entre vértices.
Ao contrário de um processador escalar central ou de gráficos vetoriais, o IPU - um novo tipo de processador projetado para aprendizado de máquina, permite criar esses gráficos. Um computador projetado para gerenciamento de gráficos é uma máquina ideal para modelos de gráficos computacionais criados como parte do aprendizado de máquina.
Uma das maneiras mais fáceis de descrever como a inteligência da máquina funciona é visualizá-la. A equipe de desenvolvimento do Graphcore criou uma coleção dessas imagens exibidas na IPU. A base foi o software Poplar, que visualiza o trabalho da inteligência artificial. Pesquisadores dessa empresa também descobriram por que redes profundas exigem tanta memória e quais soluções existem.
O álamo inclui um compilador gráfico que foi criado do zero para converter as operações padrão usadas como parte do aprendizado de máquina em código de aplicativo altamente otimizado para IPUs. Ele permite que você colete esses gráficos juntos no mesmo princípio em que os POPNNs são montados. A biblioteca contém um conjunto de diferentes tipos de vértices para primitivas generalizadas.
Os gráficos são o paradigma no qual todo software é baseado. No Álamo, os gráficos permitem definir o processo de cálculo, onde os vértices realizam operações e arestas descrevem o relacionamento entre eles. Por exemplo, se você quiser adicionar dois números, poderá definir um vértice com duas entradas (os números que deseja adicionar), alguns cálculos (a função de adicionar dois números) e a saída (resultado).
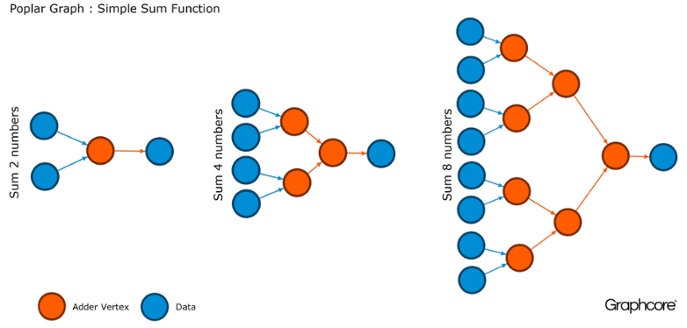
Normalmente, as operações de vértice são muito mais complicadas do que no exemplo descrito acima. Muitas vezes, eles são definidos por pequenos programas chamados codelets (nomes de código). A abstração gráfica é atraente porque não faz suposições sobre a estrutura dos cálculos e divide o cálculo em componentes que o processador IPU pode usar para trabalhar.
O álamo usa essa abstração simples para criar gráficos muito grandes que são representados como imagens. A geração programática do gráfico significa que podemos adaptá-lo aos cálculos específicos necessários para garantir o uso mais eficiente dos recursos da IPU.
O compilador converte operações padrão usadas em sistemas de aprendizado de máquina em código de aplicativo altamente otimizado para IPUs. Um compilador de gráficos cria uma imagem intermediária de um gráfico computacional implantado em um ou mais dispositivos IPU. O compilador pode exibir esse gráfico computacional; portanto, um aplicativo gravado no nível da estrutura da rede neural exibe uma imagem do gráfico computacional executado na IPU.
 Gráfico de aprendizado de ciclo completo AlexNet para frente e para trás
Gráfico de aprendizado de ciclo completo AlexNet para frente e para trásO compilador gráfico Poplar transformou
a descrição
da AlexNet em um gráfico computacional de 18,7 milhões de vértices e 115,8 milhões de arestas. O cluster claramente visível é o resultado de uma forte conexão entre os processos em cada camada da rede, com uma conexão mais fácil entre os níveis.
Outro exemplo é uma rede simples com conectividade completa, treinada no
MNIST - um conjunto de dados simples para visão computacional, uma espécie de “Olá, mundo” em aprendizado de máquina. Uma rede simples para explorar esse conjunto de dados ajuda a entender os gráficos que são controlados pelos aplicativos Poplar. Ao integrar bibliotecas de gráficos a ambientes como o TensorFlow, a empresa fornece uma das maneiras mais fáceis de usar IPUs em aplicativos de aprendizado de máquina.
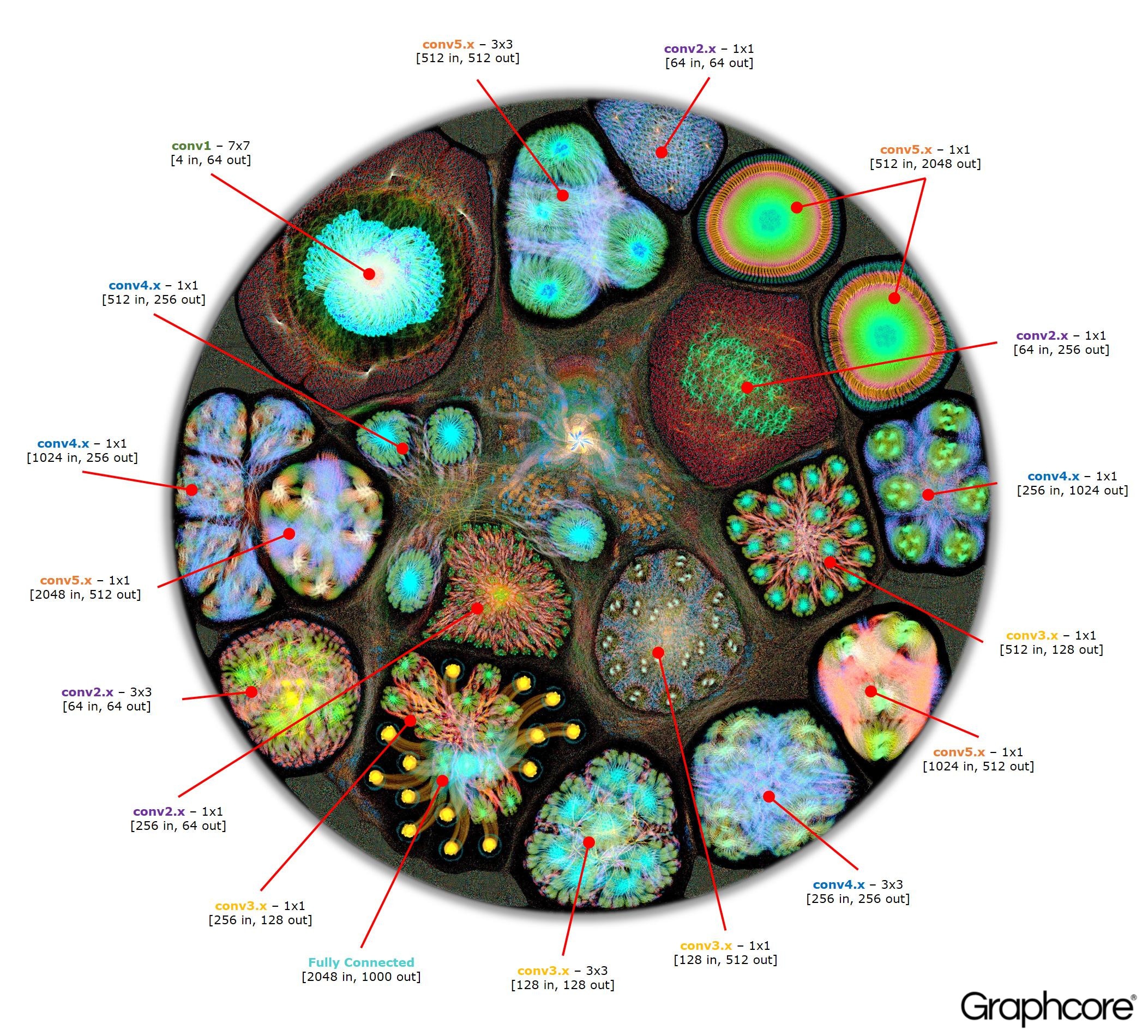
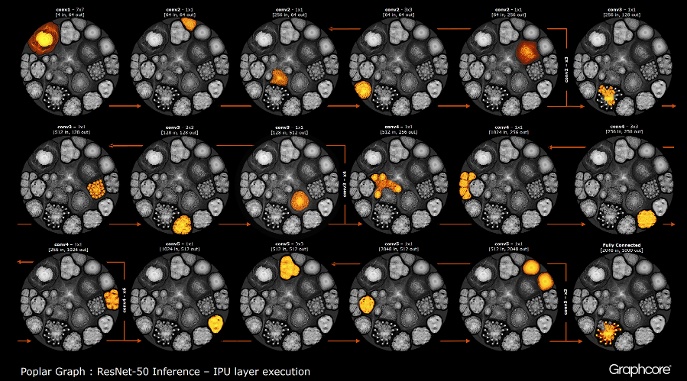
Depois que o gráfico é construído usando o compilador, ele precisa ser executado. Isso é possível usando o mecanismo de gráfico. Usando o ResNet-50 como exemplo, sua operação é demonstrada.
 Count ResNet-50
Count ResNet-50A arquitetura ResNet-50 permite criar redes profundas a partir de partições repetidas. O processador precisa apenas determinar essas partições uma vez e chamá-las novamente. Por exemplo, um cluster no nível conv4 é executado seis vezes, mas apenas uma vez aplicado ao gráfico. A imagem também demonstra a variedade de formas de camadas convolucionais, uma vez que cada uma delas possui um gráfico construído de acordo com a forma natural de cálculo.
O mecanismo cria e controla a execução de um modelo de aprendizado de máquina usando um gráfico criado pelo compilador. Uma vez implantado, o Graph Engine monitora e responde a IPUs ou dispositivos usados pelos aplicativos.
Image ResNet-50 mostra o modelo inteiro. Nesse nível, é difícil distinguir entre vértices individuais, portanto, você deve observar imagens ampliadas. A seguir estão alguns exemplos de seções dentro de camadas de uma rede neural.


Por que redes profundas precisam de tanta memória?
Grandes quantidades de memória ocupada são um dos maiores problemas das redes neurais profundas. Os pesquisadores estão tentando lidar com a largura de banda limitada dos dispositivos DRAM, que devem ser usados pelos sistemas modernos para armazenar um grande número de pesos e ativações em uma rede neural profunda.
As arquiteturas foram desenvolvidas usando chips de processador projetados para processamento sequencial e otimização de DRAM para memória de alta densidade. A interface entre os dois dispositivos é um gargalo que introduz limitações de largura de banda e adiciona uma sobrecarga significativa ao consumo de energia.
Embora ainda não tenhamos uma imagem completa do cérebro humano e como ele funciona, é geralmente claro que não há grandes instalações de armazenamento separadas para a memória. Acredita-se que a função da memória de longo e curto prazo no cérebro humano esteja incorporada na estrutura dos neurônios + sinapses. Mesmo organismos simples como
vermes com uma estrutura neural do cérebro, composta por pouco mais de 300 neurônios,
têm algum grau de função de memória.
Construir memória em processadores convencionais é uma maneira de contornar os gargalos de memória, abrindo grande largura de banda com muito menos consumo de energia. No entanto, a memória em um chip é uma coisa cara, que não é projetada para grandes quantidades de memória, conectadas aos processadores centrais e gráficos atualmente usados para a preparação e implantação de redes neurais profundas.
Portanto, é útil observar como a memória é usada hoje em unidades de processamento central e sistemas de aprendizado profundo em aceleradores gráficos e se perguntar: por que eles precisam de dispositivos de armazenamento de memória tão grandes quando o cérebro humano funciona bem sem eles?
As redes neurais precisam de memória para armazenar dados de entrada, parâmetros de peso e funções de ativação, pois a entrada é distribuída pela rede. No treinamento, a ativação na entrada deve ser preservada até que possa ser usada para calcular os erros dos gradientes na saída.
Por exemplo, uma rede ResNet de 50 camadas possui cerca de 26 milhões de parâmetros de ponderação e calcula 16 milhões de ativações avançadas. Se você usar um número de ponto flutuante de 32 bits para armazenar cada peso e ativação, isso exigirá cerca de 168 MB de espaço. Usando um valor de precisão menor para armazenar essas escalas e ativações, poderíamos reduzir pela metade ou até quadruplicar esse requisito de armazenamento.
Um sério problema de memória surge do fato de que as GPUs dependem de dados representados como vetores densos. Portanto, eles podem usar um único fluxo de instruções (SIMD) para obter computação de alta densidade. O processador central usa blocos vetoriais semelhantes para computação de alto desempenho.
Nas GPUs, a sinapse tem 1024 bits de largura e, portanto, eles usam dados de ponto flutuante de 32 bits; portanto, eles os dividem em minilotes paralelos de 32 amostras para criar vetores de dados de 1024 bits. Essa abordagem para organizar o paralelismo vetorial aumenta em 32 vezes o número de ativações e a necessidade de armazenamento local com capacidade superior a 2 GB.
As GPUs e outras máquinas projetadas para álgebra matricial também estão sujeitas à carga de memória dos pesos ou ativações da rede neural. As GPUs não podem executar com eficiência pequenas convoluções usadas em redes neurais profundas. Portanto, uma transformação chamada “downgrade” é usada para converter essas convoluções em multiplicações matriz-matriz (GEMMs), com as quais os aceleradores gráficos podem lidar com eficácia.
Também é necessária memória adicional para armazenar dados de entrada, valores de tempo e instruções do programa. A medição do uso de memória ao treinar o ResNet-50 em uma GPU de alto desempenho mostrou que ele requer mais de 7,5 GB de DRAM local.
Talvez alguém decida que uma menor precisão pode reduzir a quantidade de memória necessária, mas esse não é o caso. Quando você muda os valores dos dados para a metade da precisão para pesos e ativações, preenche apenas metade da largura do vetor do SIMD, gastando metade dos recursos de computação disponíveis. Para compensar isso, quando você muda de precisão total para meia precisão na GPU, precisará dobrar o tamanho do minilote para causar paralelismo de dados suficiente para usar todos os cálculos disponíveis. Assim, a transição para escalas e ativações de menor precisão na GPU ainda requer mais de 7,5 GB de memória dinâmica com acesso livre.
Com tantos dados a serem armazenados, é simplesmente impossível encaixar tudo isso na GPU. Em cada camada da rede neural convolucional, é necessário salvar o estado da DRAM externa, carregar a próxima camada de rede e depois carregar os dados no sistema. Como resultado, a interface de memória externa, já limitada pela largura de banda da memória, sofre com a carga adicional de recarregar constantemente a balança, além de salvar e recuperar funções de ativação. Isso diminui significativamente o tempo de treinamento e aumenta significativamente o consumo de energia.
Existem várias soluções para esse problema. Primeiramente, operações como funções de ativação podem ser executadas “no local”, permitindo que você substitua a entrada diretamente na saída. Assim, a memória existente pode ser reutilizada. Em segundo lugar, a oportunidade de reutilização da memória pode ser obtida analisando a dependência de dados entre operações na rede e a distribuição da mesma memória para operações que não estão sendo usadas no momento.
A segunda abordagem é especialmente eficaz quando toda a rede neural pode ser analisada no estágio de compilação para criar uma memória alocada fixa, uma vez que os custos de gerenciamento de memória são reduzidos a quase zero. Descobriu-se que uma combinação desses métodos reduz o uso de memória da rede neural em duas a três vezes.
Uma terceira abordagem significativa foi descoberta recentemente pela equipe do Baidu Deep Speech. Eles aplicaram vários métodos de economia de memória para obter uma redução de 16 vezes no consumo de memória pelas funções de ativação, o que lhes permitiu treinar redes com 100 camadas. Anteriormente, com a mesma quantidade de memória, eles podiam treinar redes com nove camadas.
A combinação de recursos de memória e processamento em um dispositivo tem um potencial significativo para aumentar a produtividade e a eficiência das redes neurais convolucionais, além de outras formas de aprendizado de máquina. Você pode fazer um compromisso entre os recursos de memória e computação para equilibrar os recursos e o desempenho do sistema.
Redes neurais e modelos de conhecimento em outros métodos de aprendizado de máquina podem ser considerados gráficos matemáticos. Nestes gráficos, uma enorme quantidade de paralelismo está concentrada. Um processador paralelo projetado para usar simultaneidade em gráficos não depende de minilote e pode reduzir significativamente a quantidade de armazenamento local necessário.
Resultados de pesquisas modernas mostraram que todos esses métodos podem melhorar significativamente o desempenho das redes neurais. Os gráficos modernos e as unidades de processamento central têm memória interna muito limitada, apenas alguns megabytes no total. As novas arquiteturas de processador projetadas especificamente para aprendizado de máquina fornecem um equilíbrio entre a memória e a computação no chip, proporcionando um aumento significativo no desempenho e na eficiência em comparação com as modernas unidades de processamento central e aceleradores gráficos.