
Há quatro anos, o Google percebeu o real potencial do uso de redes neurais em suas aplicações. Então ela começou a apresentá-los em todos os lugares - tradução de texto, pesquisa por voz com reconhecimento de fala, etc. Grosso modo, se todos realizassem uma pesquisa por voz no Android (ou ditassem texto com reconhecimento de fala) por apenas três minutos por dia, o Google teria que dobrar o número de datacenters (!) Para que as redes neurais processassem uma quantidade tão grande de tráfego de voz.
Algo precisava ser feito - e o Google encontrou uma solução. Em 2015, ela desenvolveu sua própria arquitetura de hardware para aprendizado de máquina (TPU), que é até 70 vezes mais rápida que as GPUs e CPUs tradicionais em termos de desempenho e até 196 vezes mais em termos de número de cálculos por watt. GPUs / CPUs tradicionais referem-se aos processadores de uso geral Xeon E5 v3 (Haswell) e GPUs Nvidia Tesla K80.
A arquitetura do TPU foi descrita pela primeira vez nesta semana em um
artigo científico (pdf) que será apresentado no 44º Simpósio Internacional de Arquitetura de Computadores (ISCA), 26 de junho de 2017 em Toronto. Um dos principais autores de mais de 70 autores deste trabalho científico,
um destacado engenheiro Norman Jouppi, conhecido como um dos criadores do processador MIPS, em
entrevista à
The Next Platform, explicou em suas próprias palavras os recursos da arquitetura TPU exclusiva, que na verdade é um ASIC especializado. circuito integrado para fins especiais.
Ao contrário dos FPGAs convencionais ou ASICs altamente especializados, os módulos TPU são programados da mesma maneira que uma GPU ou CPU; não é um equipamento de alcance estreito para uma única rede neural. Norman Yuppy diz que o TPU suporta instruções CISC para diferentes tipos de redes neurais: redes neurais convolucionais, modelos LSTM e modelos grandes e totalmente conectados. Para que ele permaneça programável, use apenas a matriz como primitiva, e não como vetor ou escalar.
O Google enfatiza que, enquanto outros desenvolvedores estão otimizando seus microchips para redes neurais convolucionais, essas redes neurais fornecem apenas 5% da carga nos data centers do Google. A maioria dos aplicativos do Google usa os
perceptrons Rumelhart multicamadas , por isso era tão importante criar uma arquitetura mais universal que não fosse "aprimorada" apenas para redes neurais convolucionais.
 Um dos elementos da arquitetura é o mecanismo de fluxo de dados sistólico, uma matriz de 256 × 256, que recebe ativação (pesos) dos neurônios à esquerda e depois tudo muda passo a passo, multiplicado pelos pesos na célula. Acontece que a matriz sistólica realiza 65 536 cálculos por ciclo. Essa arquitetura é ideal para redes neurais.
Um dos elementos da arquitetura é o mecanismo de fluxo de dados sistólico, uma matriz de 256 × 256, que recebe ativação (pesos) dos neurônios à esquerda e depois tudo muda passo a passo, multiplicado pelos pesos na célula. Acontece que a matriz sistólica realiza 65 536 cálculos por ciclo. Essa arquitetura é ideal para redes neurais.De acordo com Yuppy, a arquitetura das TPUs é mais um coprocessador FPU do que uma GPU comum, embora numerosas matrizes para multiplicação não armazenem nenhum programa em si, elas simplesmente executam instruções recebidas do host.
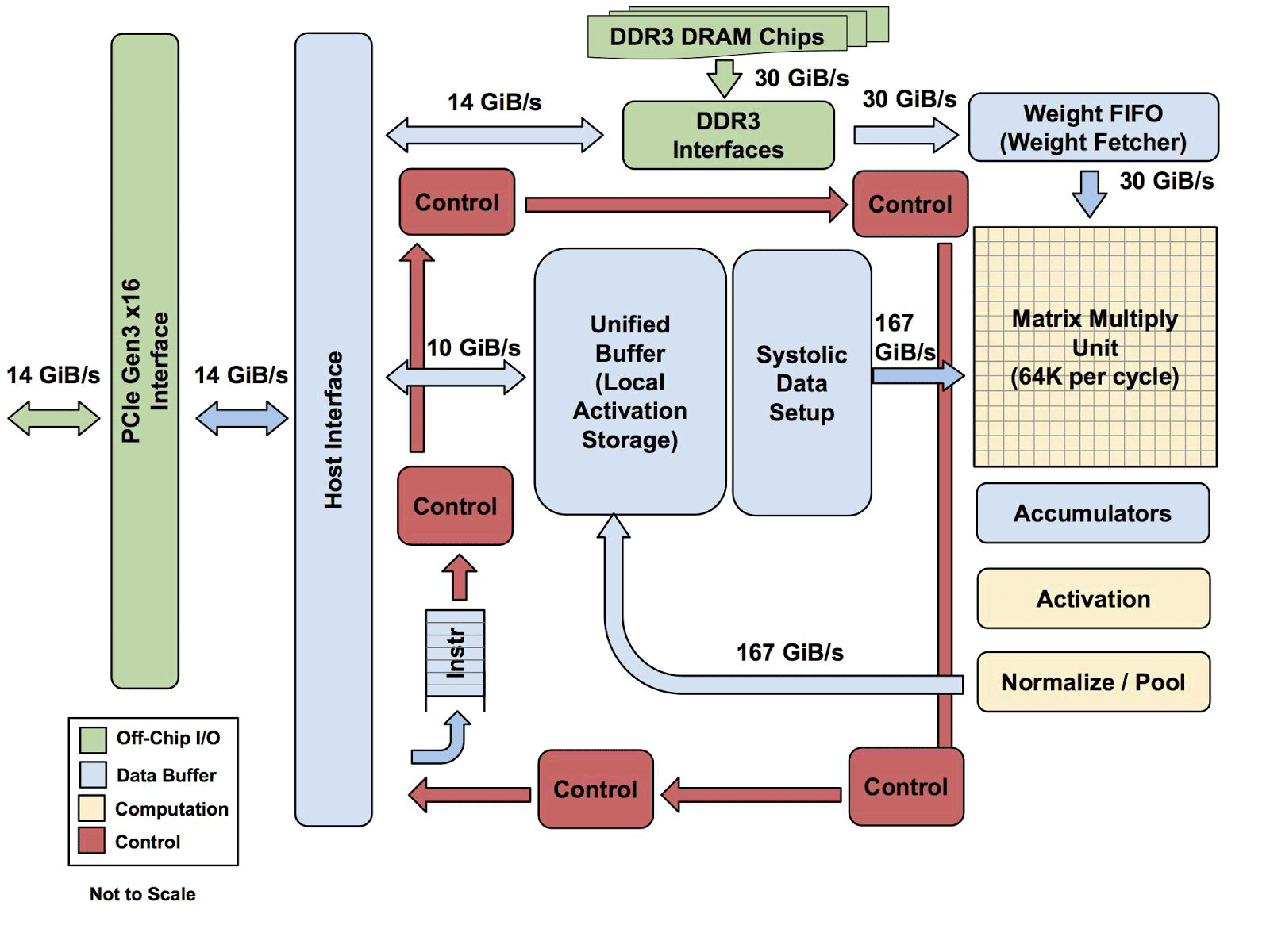 Toda a arquitetura TPU, com exceção da memória DDR3. As instruções são enviadas do host (esquerda) para a fila. Então, a lógica de controle, dependendo da instrução, pode executar cada um deles repetidamente
Toda a arquitetura TPU, com exceção da memória DDR3. As instruções são enviadas do host (esquerda) para a fila. Então, a lógica de controle, dependendo da instrução, pode executar cada um deles repetidamenteAinda não se sabe o quão escalável é essa arquitetura. Yuppy diz que em um sistema com esse tipo de host sempre haverá algum tipo de gargalo.
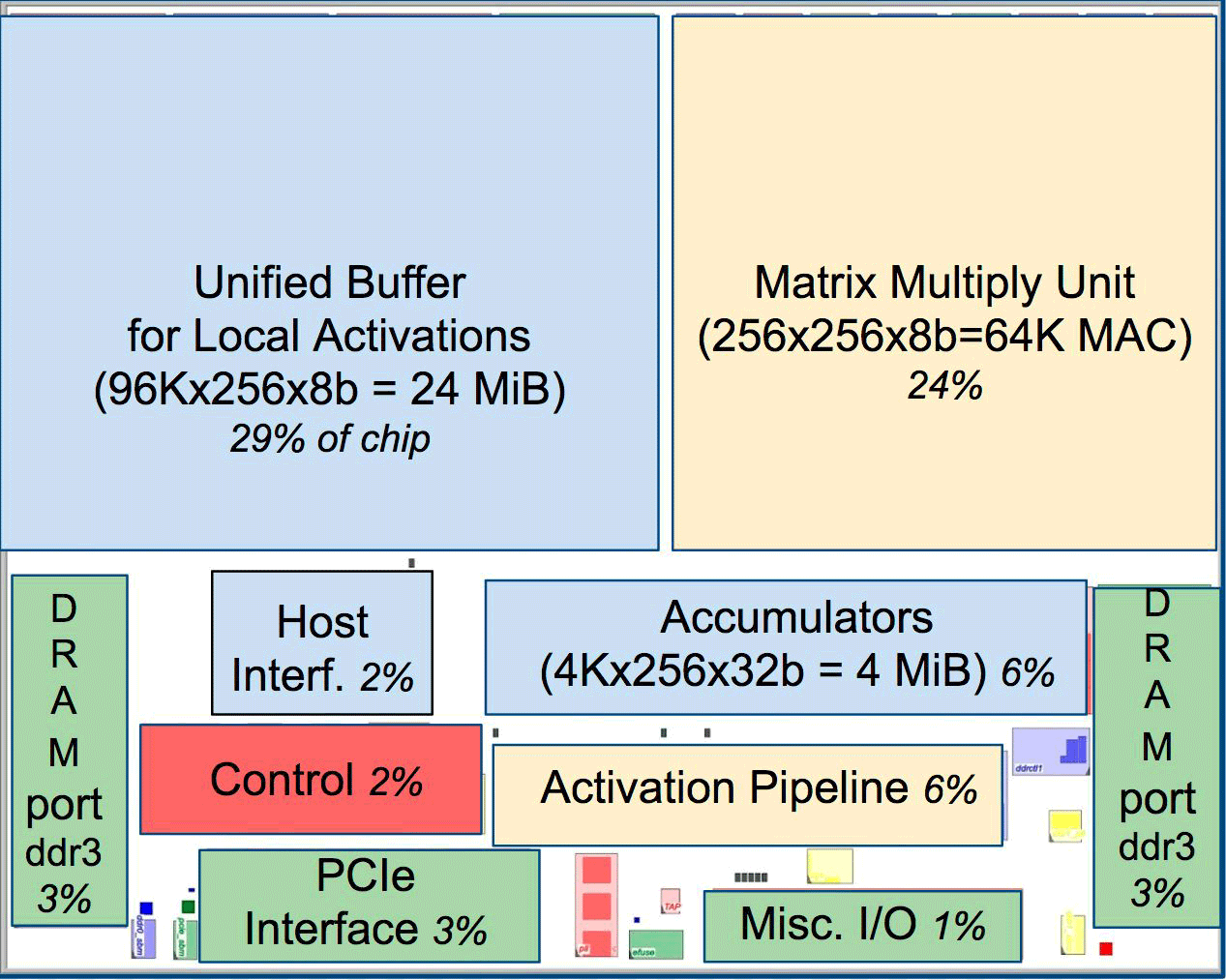
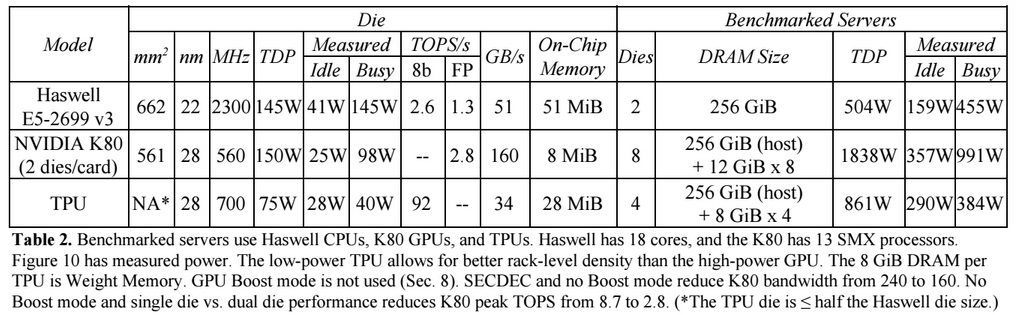
Comparado às CPUs e GPUs convencionais, a arquitetura de máquinas do Google as supera em dez vezes. Por exemplo, um processador Haswell Xeon E5-2699 v3 com 18 núcleos a uma freqüência de 2,3 GHz com um ponto flutuante de 64 bits executa 1,3 tera-operações por segundo (TOPS) e mostra uma taxa de transferência de dados de 51 GB / s. Nesse caso, o próprio chip consome 145 watts e todo o sistema possui 256 GB de memória - 455 watts.
Para comparação, o TPU em operações de 8 bits com 256 GB de memória externa e 32 GB de memória interna demonstra a velocidade de troca com memória de 34 GB / s, mas ao mesmo tempo o cartão executa 92 TOPS, ou seja, aproximadamente 71 vezes mais que o processador Haswell. O consumo de energia do servidor na TPU é de 384 watts.
O gráfico a seguir compara o desempenho relativo por watt de um servidor com uma GPU (coluna azul), um servidor em TPU (vermelho) em relação a um servidor na CPU. Ele também compara o desempenho relativo por watt do servidor com o TPU em relação ao servidor na GPU (laranja) e a versão aprimorada do TPU em relação ao servidor na CPU (verde) e o servidor na GPU (roxo).

Note-se que o Google fez comparações em testes de aplicativos no TensorFlow com a versão antiga relativa do Haswell Xeon, enquanto na versão mais recente do Broadwell Xeon E5 v4, o número de instruções por ciclo aumentou em 5% devido a melhorias arquiteturais e na versão do Skylake Xeon E5 v5 , que é esperado no verão, o número de instruções por ciclo pode aumentar em mais 9 a 10%. E com o aumento do número de núcleos de 18 para 28 no Skylake, o desempenho geral dos processadores Intel nos testes do Google pode melhorar em 80%. Mas, mesmo assim, haverá uma enorme diferença de desempenho com o TPU. Na versão do teste com ponto flutuante de 32 bits, a diferença entre TPUs e CPUs é reduzida para aproximadamente 3,5 vezes. Mas a maioria dos modelos quantiza perfeitamente para 8 bits.
O Google pensou em como usar GPU, FPGA e ASIC em seus data centers desde 2006, mas não os encontrou até a última vez em que introduziu o aprendizado de máquina para várias tarefas práticas, e a carga nessas redes neurais começou a crescer com bilhões de solicitações de usuários. Agora a empresa não tem escolha a não ser afastar-se das CPUs tradicionais.
A empresa não planeja vender seus processadores para ninguém, mas espera que o trabalho científico com o ASIC 2015 permita que outras pessoas melhorem a arquitetura e criem versões aprimoradas do ASIC que "elevem ainda mais a fasquia". O próprio Google provavelmente já está trabalhando em uma nova versão do ASIC.