 Como traduzir um documento no Word e não vaporizá-lo com formatação ? Como não traduzir a mesma coisa? Como manter a uniformidade? Como não comprar software caro? Como trabalhar com eficiência e rapidez?
Como traduzir um documento no Word e não vaporizá-lo com formatação ? Como não traduzir a mesma coisa? Como manter a uniformidade? Como não comprar software caro? Como trabalhar com eficiência e rapidez?Se você estiver familiarizado com o Trados, MemoQ ou CrowdIn, vá direto para as instruções de instalação. Se estas são novas palavras para você, seja bem-vindo ao maravilhoso mundo da
Tradução Assistida por Computador.Sobre tradução por computador
Google Translate - tradução automática, o computador traduz para você. O CAT é um princípio de trabalho quando um computador apenas ajuda no trabalho, automatizando processos de rotina.
Os programas CAT dividem o código-fonte em
segmentos - linhas, sentenças, parágrafos ou parágrafos. Uma pessoa traduz um segmento um por um e a tradução é armazenada em um banco de dados especial - memória de tradução (
TM ). Se o tradutor encontrar um
segmento semelhante , o programa mostrará uma dica ou uma possível tradução. E o programa
pode traduzir segmentos idênticos por
si só .
O CAT é especialmente bom na tradução de
instruções ,
documentos legais ,
interfaces de programa - onde
palavras semelhantes são muito comuns . Na tradução literária, a ajuda não será tão óbvia, mas mais adiante.
Quanto mais textos sobre tópicos semelhantes você traduzir, mais traduções se acumulam
no banco de dados , mais frequentemente aparecem dicas. Ao longo dos anos, essa base pode acumular que, no novo documento, metade da tradução estará pronta "sozinha".
Quando a tradução é concluída, o programa cria um documento
idêntico ao original - preservando a estrutura e a formatação, mas substituindo o texto original pela tradução.
Os programas CAT não modificam o documento original, portanto, é impossível corromper permanentemente o documento. A saída será um arquivo totalmente traduzido.
O que são programas CAT?
Diferente.
Trados ,
MemoQ - sistemas corporativos caros que são instalados em um computador.
CrowdIn ,
Tolmach e outros - trabalham diretamente no navegador. Como regra, tudo custa dinheiro ou há restrições no volume de projetos.
Mas nem tudo é tão ruim: eu uso o
OmegaT há
oito anos , um programa de código aberto gratuito que roda em sistemas Windows, Mac e Linux e é constantemente aprimorado pela comunidade. Eu trabalho nele com
chinês , inglês e russo.
O que o OmegaT pode fazer?
 OmegaTwww.omegat.org
OmegaTwww.omegat.orgFreeware (GPLv3), código aberto
Windows, macOS, Linux
Ele sabe tudo o que é descrito no primeiro capítulo - para ajudar o tradutor em seu trabalho e vários outros insignificantes.
Formatos de arquivo- Microsoft Word, Excel, PowerPoint (somente novos .xlsx, .docx e * .pptx, os antigos devem ser convertidos primeiro)
- OpenOffice .ods, .odt e outros
- Arquivos de texto .txt, .rtf
- Chave = arquivos de texto de valor (* .ini e similares)
- HTML
- Arquivos com uma estrutura XML (você mesmo pode configurá-lo)
- E muitos outros.
LínguasQualquer. Quase tudo o que existe no Unicode. Para idiomas raros, pode ser necessário ajustar as regras de segmentação, mas tudo está resolvido.
Não vou recontar as instruções . É completo e informativo, e familiarizar-se com isso é muito importante. Depois, haverá apenas operações básicas com o programa que ajudarão você a começar.
Instalação
Faça o download da distribuição em
omegat.org .
Usarei a versão em inglês
4.1.1 da ramificação
mais recente para Windows. Este conteúdo requer que o Java seja executado. Se você não tiver certeza se possui um, faça o download da versão marcada JRE. Não se assuste com a inscrição Beta, o programa funciona mais do que de forma estável.
Verificação ortográfica
Após a instalação, o programa está pronto para funcionar, mas, por padrão, não há verificação ortográfica suficiente.
- Inicie o OmegaT
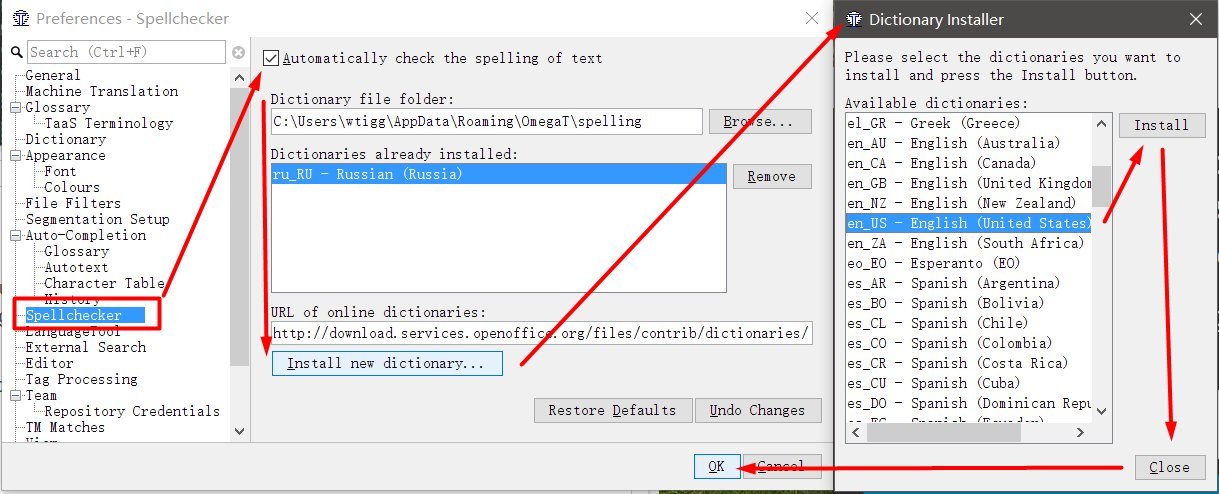
- Vá para Opções → Preferências → Verificador ortográfico
- Marque a caixa Verificar automaticamente a ortografia do texto
- Clique em Instalar novo dicionário
- Escolha um idioma (por exemplo, ru_RU para russo), clique em Instalar
- Clique em Fechar . Na lista, vemos o idioma russo.
- Saímos das configurações.
Como criar um projeto
O OmegaT não funciona com arquivos individuais, mas com "projetos". Um projeto é um conjunto de pastas com uma estrutura específica. Para converter um arquivo, você precisa criar um projeto e adicionar o arquivo lá.
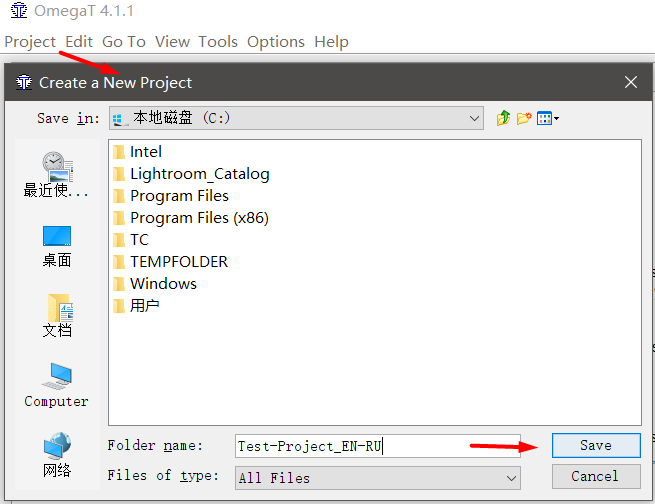
- Inicie o OmegaT
- Projeto → Novo , selecione o local para salvar e o nome do projeto. Eu recomendo dar nomes significativos aos projetos e indicar um par de idiomas neles. Por exemplo, Test-Project_EN-RU .
- Na janela exibida, especifique o par de idiomas
Idioma dos arquivos de origem - o idioma do qual você está traduzindo; Target Files Language é o idioma para o qual você está traduzindo. É necessário indicar no código de duas ou quatro letras. Por exemplo, RU é russo e RU-RU e RU-BY esclarecem que é russo da Federação Russa e russo da Bielorrússia. Para que a verificação ortográfica funcione, o código deve corresponder ao código especificado nas configurações ortográficas (se RU-RU estiver definida em ortografia e RU estiver no projeto, a verificação não funcionará).
- Marque a caixa ao lado de Ativar segmentação em nível de sentença (dividindo segmentos por sentenças em vez de parágrafos) e Propagação automática de traduções (traduzir automaticamente traduções). É melhor desmarcar a caixa de seleção Remover tags , explicarei seu trabalho mais tarde.
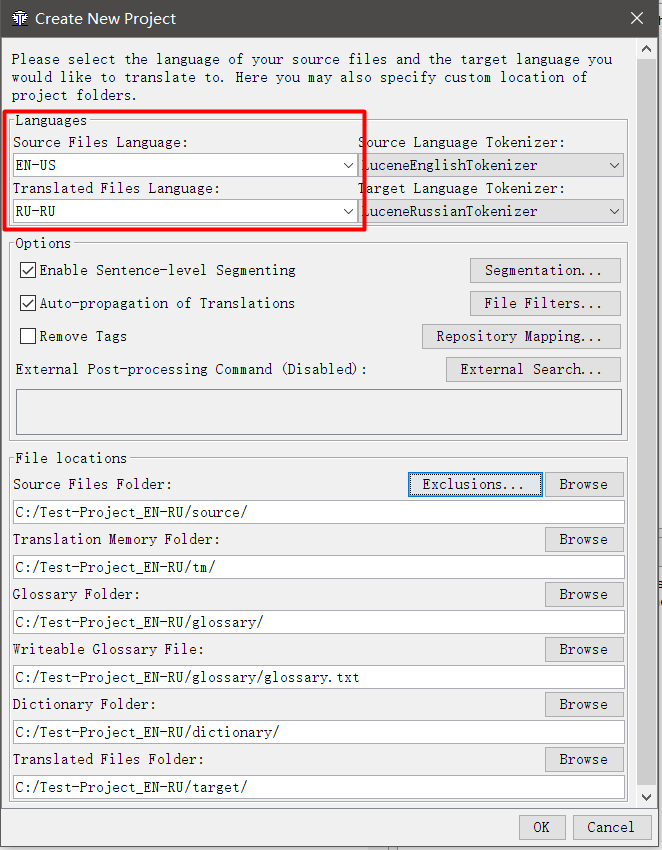
- Clique em OK
O que são essas pastas?
Existem vários subdiretórios dentro da pasta do projeto:
- dicionário - você pode adicionar dicionários no formato StarDict; a função é bastante inútil.
- glossário - um banco de dados de termos para o projeto, mais sobre isso posteriormente;
- omegat - memória de tradução e backups de projetos;
- fonte - pasta com arquivos de origem;
- target - a pasta na qual as traduções aparecerão;
- tm - pasta para memórias de tradução adicionais, mais sobre isso mais tarde.
E também o arquivo
omegat.project com a configuração do projeto atual.
Como adicionar arquivos
Depois de criar o projeto, você verá a seguinte janela:
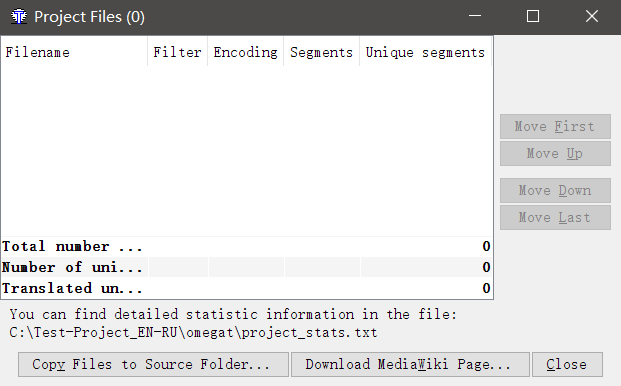
Clique em
Copiar arquivos para a pasta de origem e selecione os arquivos que deseja converter. Os arquivos serão copiados para a pasta
\ source \ do projeto recém-criado. Você pode adicionar arquivos lá manualmente. Basta copiar os arquivos para
\ source \ via explorer.
Por exemplo, criei dois arquivos - Excel e Word, nos quais mostrarei o trabalho do OmegaT.
Interface
OmegaT está sendo executado, os arquivos foram adicionados. Vamos ver como eles se parecem no programa.
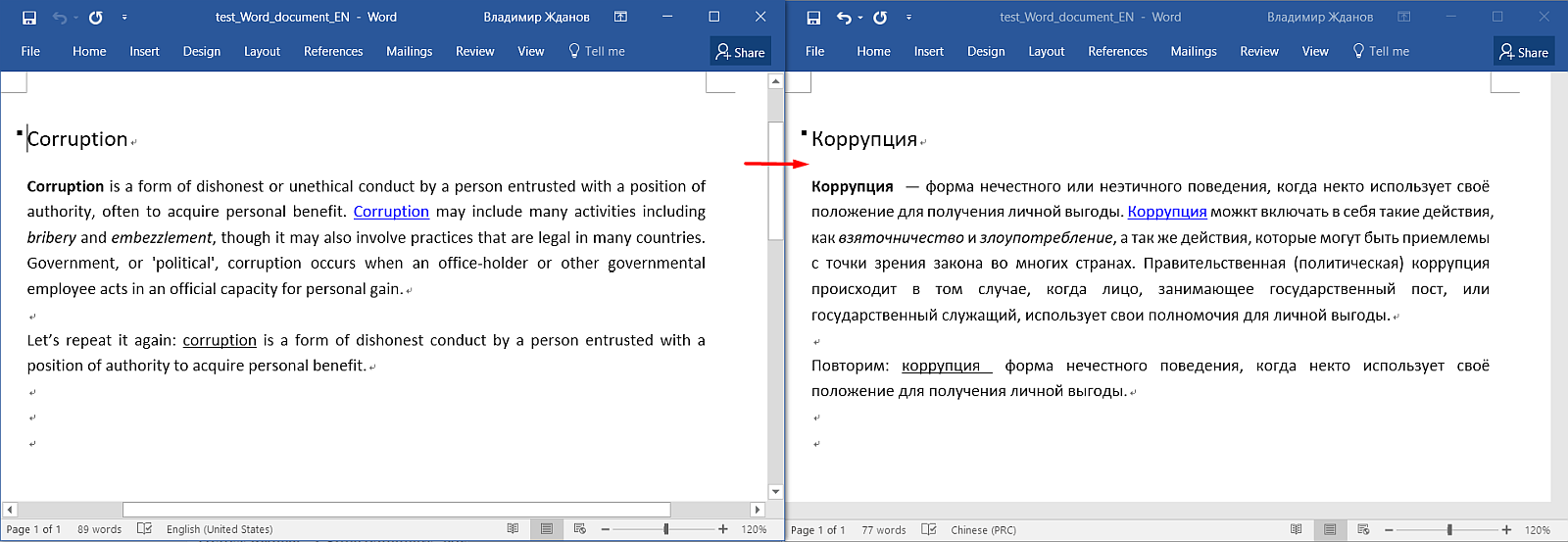
Aqui está o documento de origem no Word. Aqui você pode ver o cabeçalho, parágrafos, formatação (negrito, links, sublinhados).

E aqui está o que parece no OmegaT:
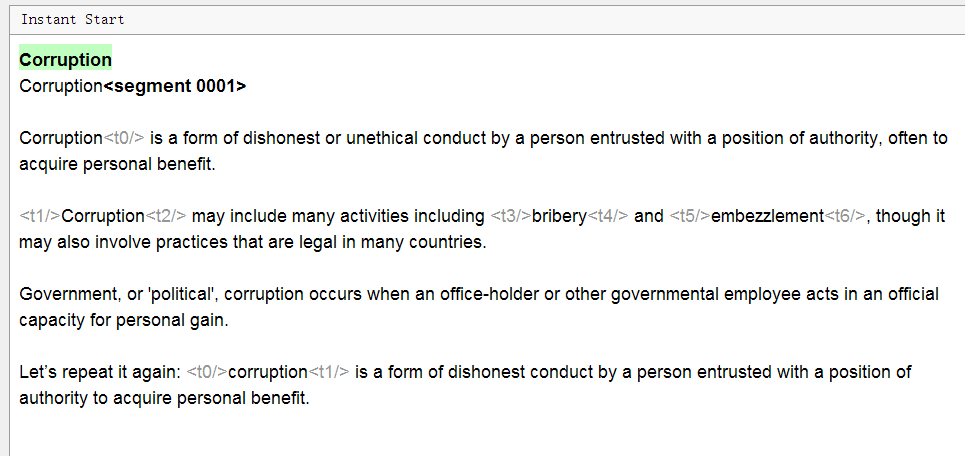
Observação: todo o texto é dividido em frases, a formatação não é visível, algumas
tags cinza apareceram e o cabeçalho é duplicado. Qual é o problema?
- Texto segmentado
Cada oferta foi alocada em um segmento separado. As regras de segmentação podem ser configuradas independentemente, se necessário. - A formatação no OmegaT não é visível, as tags o substituem
São abreviações de tags do Word que podem parecer com <t>. Para preservar a formatação original, você precisa deixar essas tags como estão, inserindo a tradução entre as tags na mesma lógica que no original.
A opção Remover tags nas configurações do projeto remove as tags junto com a formatação. Não é recomendável usar se for importante manter a formatação original. - O título não é duplicado.
De fato, o texto no idioma de origem é sempre exibido na parte superior (em verde), você não pode alterá-lo. Abaixo, há uma caixa de texto onde o mesmo texto é copiado por padrão. Você precisa excluí-lo e inserir a tradução.
Além disso, no lado direito do programa, existem mais dois setores:
Fuzzy Matches e
Glossary (dicionário do projeto).
Correspondências difusas (correspondências difusas) - resultados da pesquisa no banco de dados do projeto. As dicas de tradução baseadas nas traduções anteriores serão exibidas lá.
Glossário (dicionário do projeto) - o resultado de uma pesquisa de glossário criada por você. Ao contrário da memória de tradução, este não é um texto pronto, mas apenas sugestões para certos termos. Esta é uma ferramenta poderosa que ajuda a manter a consistência na terminologia.
Como traduzir
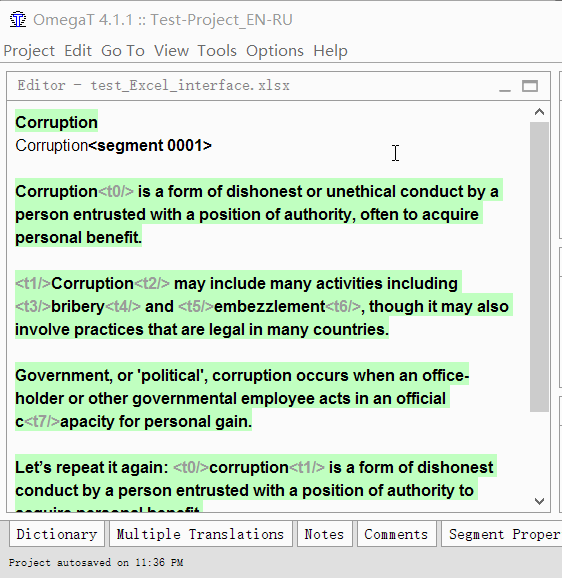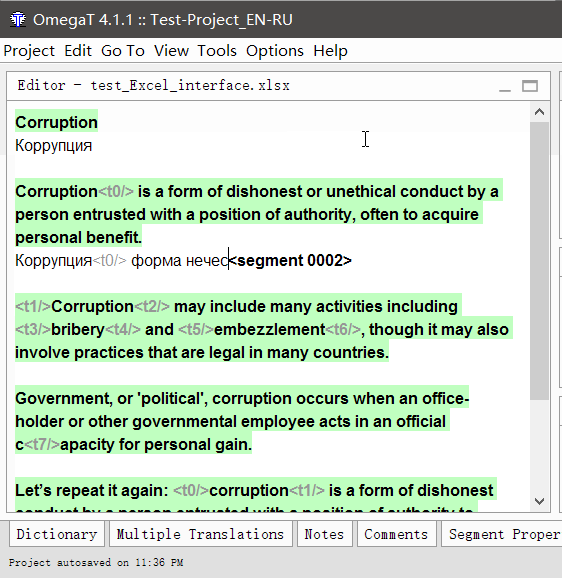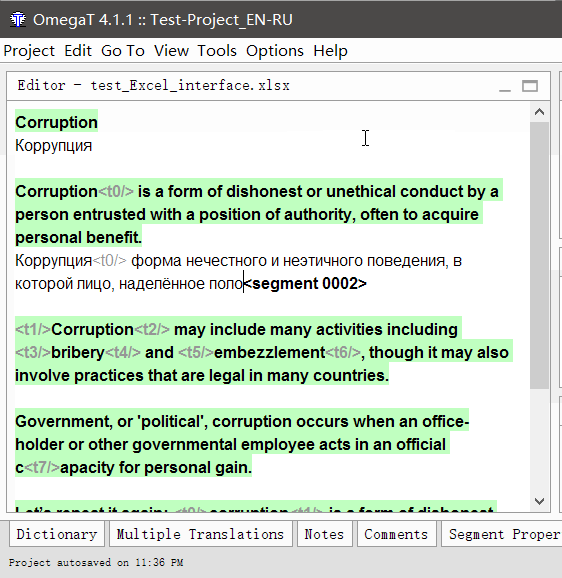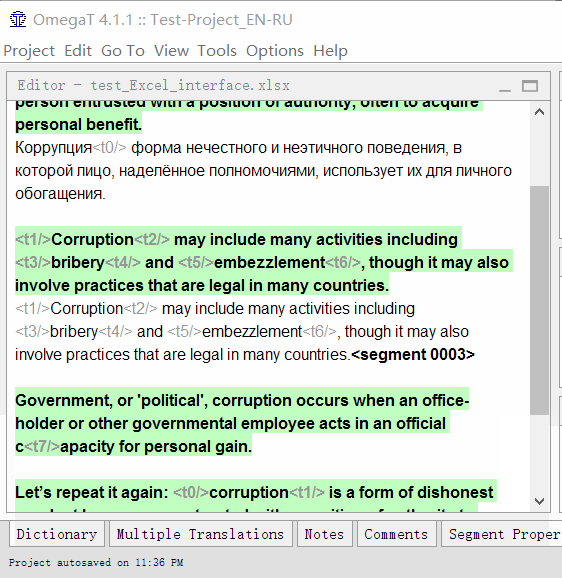
- Clique duas vezes em um segmento para traduzir
Uma linha de texto editável aparecerá sob o texto original, o cursor estará no início e o texto original será duplicado na linha. - Digite sua tradução
- Pressione Enter
Quando pressionado, a tradução será salva e o cursor se moverá para o próximo segmento.
Repita até terminar o documento. A qualquer momento, você pode retornar ao segmento anterior clicando duas vezes nele.
No canto inferior direito, há um
conveniente indicador de progresso . Clique nele para mudar o modo de visualização.

Arquivo atual:% de segmentos traduzidos (segmentos restantes) / Projeto:% de segmentos traduzidos (segmentos restantes), número total de segmentos. [/ Legenda]
Essa linha indica que no arquivo atual foram traduzidos 5,8% dos segmentos únicos, 1382 ainda não foram traduzidos.No total, 63% dos segmentos foram traduzidos no projeto, 1756 permaneceu e seu número total no projeto foi 5979.

Arquivo: segmentos únicos traduzidos / número total de segmentos únicos (projeto: segmentos únicos traduzidos / total de segmentos únicos, total de segmentos no projeto) [/ caption]
No
segundo modo, a ilustração diz que no arquivo de 1592 segmentos únicos, 146 foram traduzidos e no projeto de 4748 segmentos únicos, 2992 foram traduzidos. No total, 5979 segmentos (incluindo repetições) foram traduzidos.
Os números 14/14 no final não se referem ao contador do projeto. Este é um indicador do comprimento do segmento com o qual você está trabalhando. Ele diz que o original tinha 14 caracteres e a tradução também tinha 14. Essa função é útil nos casos em que você precisa observar rigorosamente o comprimento da string, por exemplo, ao traduzir a interface do programa.
Jogos Difusos Jogos Difusos
A ferramenta mais importante de qualquer aplicativo CAT, para isso eles existem.
Vou explicar com um exemplo:
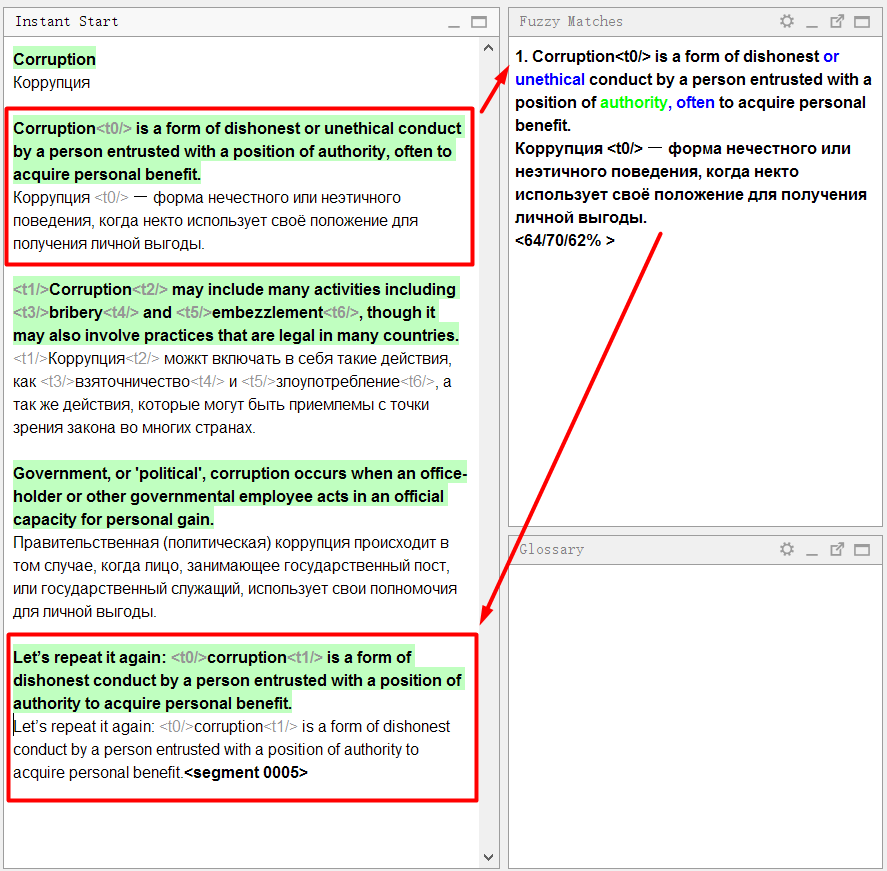
No documento de exemplo, a
primeira frase é muito semelhante à
quarta . Eu andei em ordem e traduzi a primeira frase. Quando cheguei ao quarto, o programa imediatamente mostrou uma
coincidência imprecisa :
Observe atentamente o painel de correspondências:
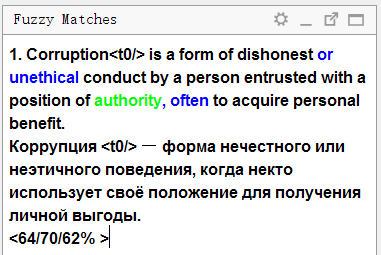
A parte superior exibe o texto no
idioma de origem , que foi
salvo na memória de tradução . As palavras presentes na memória de tradução, mas ausentes na frase atual (com a qual a correspondência é comparada) são destacadas em azul, as palavras localizadas próximas às partes ausentes são destacadas em verde.
Abaixo está uma tradução armazenada na memória. Se você pressionar
Ctrl + R , ele será copiado para o campo para tradução.
Três números são mostrados abaixo como uma porcentagem. Eles significam o grau de coincidência entre a frase e a memória de tradução. Você pode ler mais sobre o mecanismo de cálculo
na ajuda do OmegaT .
Tradução automática de segmentos idênticos
Obviamente, se o mecanismo de
correspondência difusa encontrar uma
correspondência de 100% , ele poderá ser
inserido por si mesmo . Por exemplo, pegue outro arquivo, desta vez no Excel. Aproximadamente neste formulário, muitas vezes chega um pedido para traduzir a interface de um site ou programa.
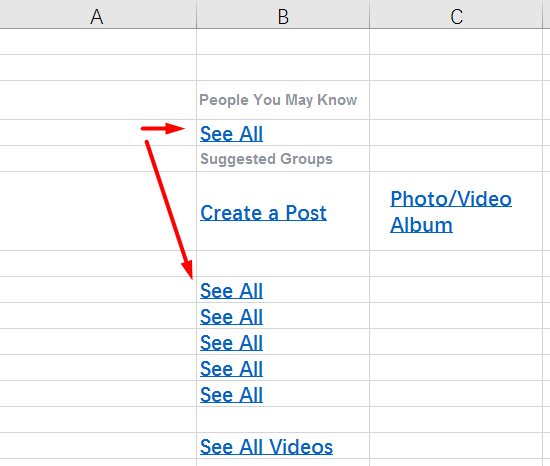
E aqui está a aparência do arquivo no OmegaT:
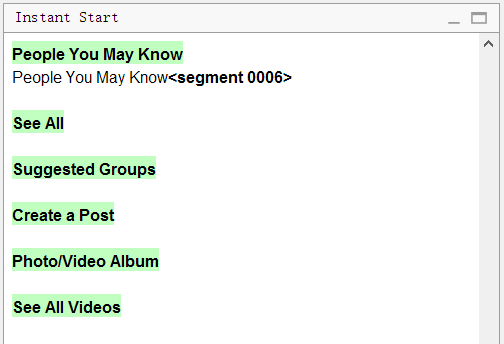
Observe que no original havia
seis linhas de
Ver tudo . O programa removeu todas as duplicatas, deixando apenas
uma linha. Basta traduzi-lo sozinho e os demais segmentos também serão traduzidos.
Glossário
O glossário funciona de maneira muito simples. Primeiro
você adiciona palavras (original e tradução). Agora, quando a palavra aparecer no texto, um prompt aparecerá imediatamente na janela
Glossário .
Assim, quando um termo aparecer em uma nova frase, você saberá imediatamente como traduzi-lo. Por exemplo, se você sempre precisar escrever “Bom” em vez de “OK” ao traduzir a interface do programa, basta adicionar a palavra “OK” com a tradução “Bom” ao dicionário. Ao adicionar algumas centenas de palavras ao projeto, você simplificará bastante sua vida.
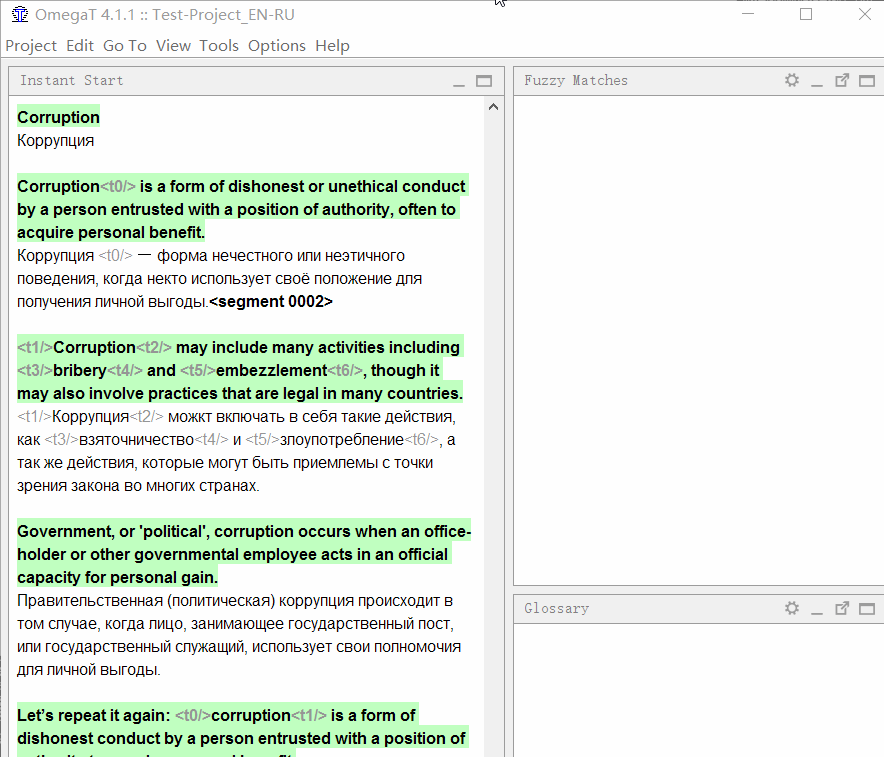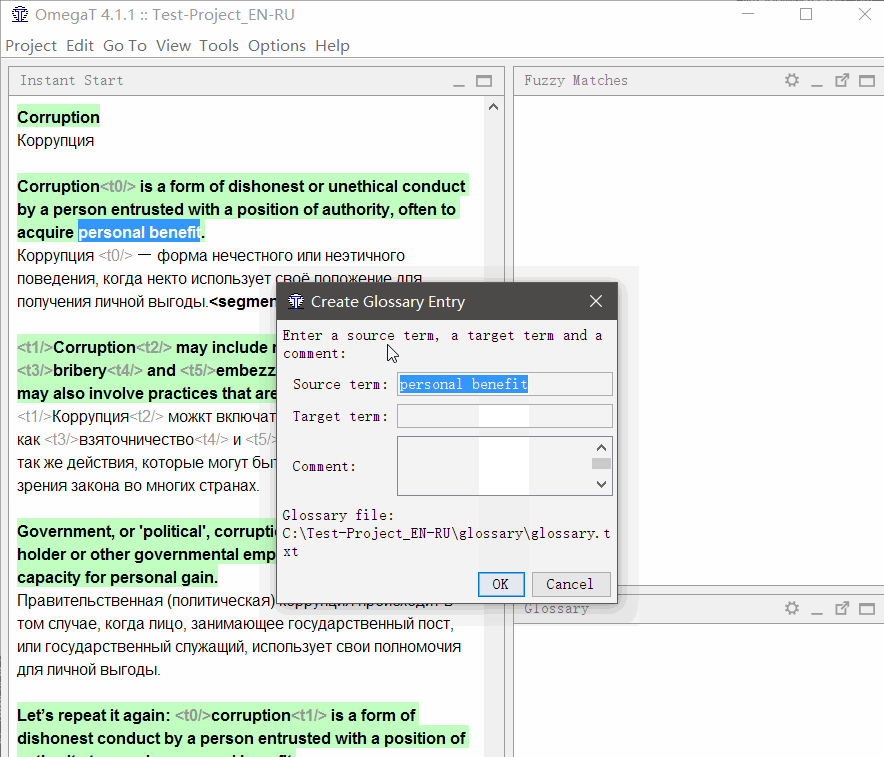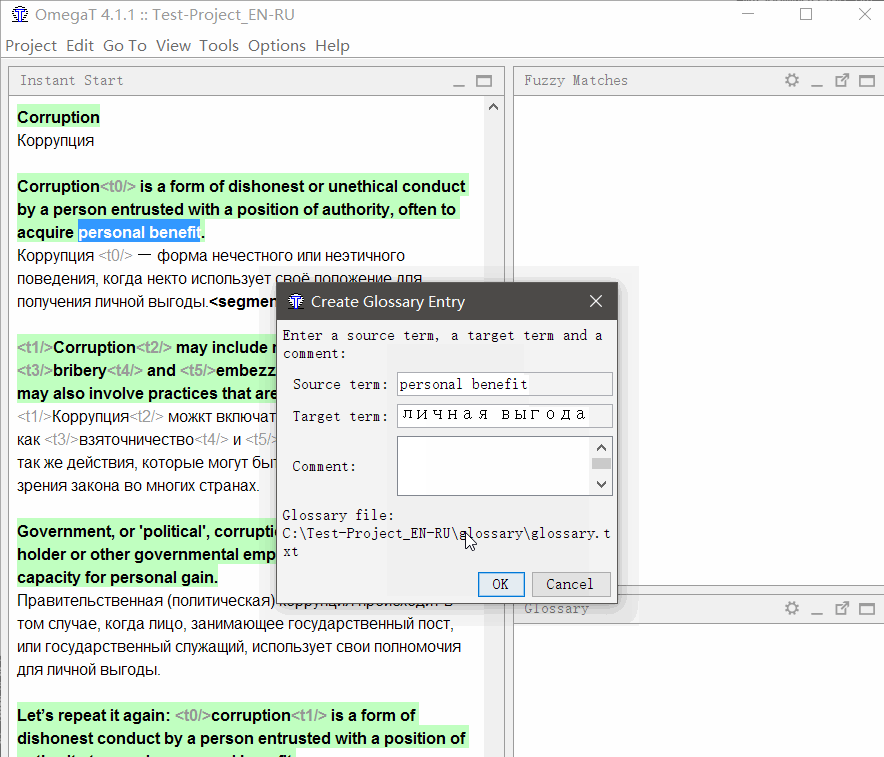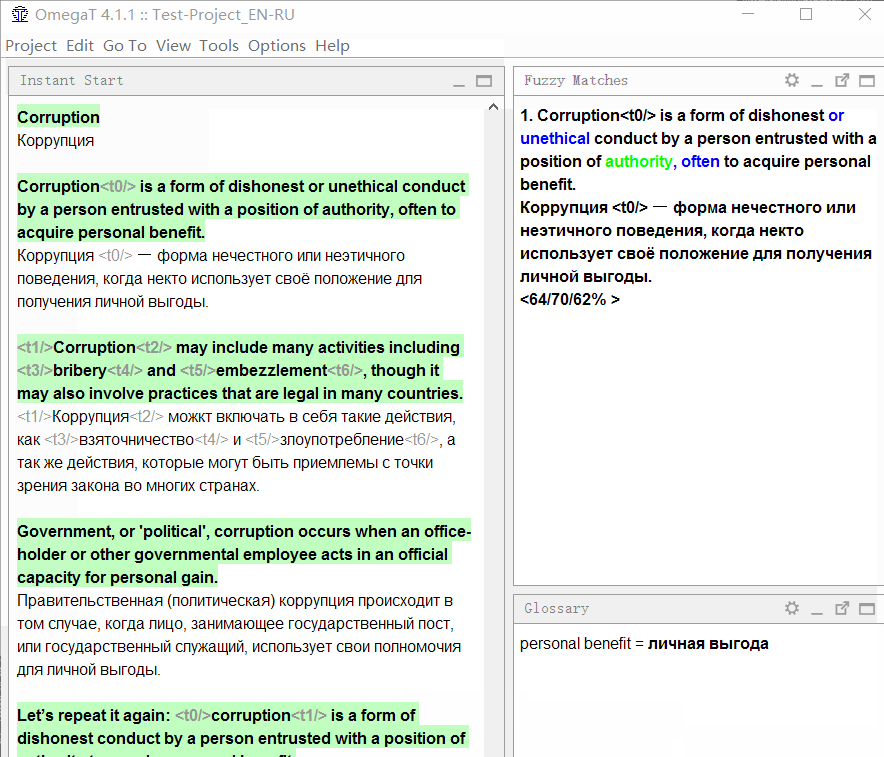
Para
adicionar uma palavra ao glossário , selecione-a, clique com o botão direito do mouse e selecione
Adicionar entrada do glossário .
Além disso, as palavras podem ser adicionadas maciçamente ao arquivo
\ glossary \ glossary.txt no formato “guia de tradução original” (uma tabela do Excel salva no formato * .csv delimitado por tabulações)
Como salvar
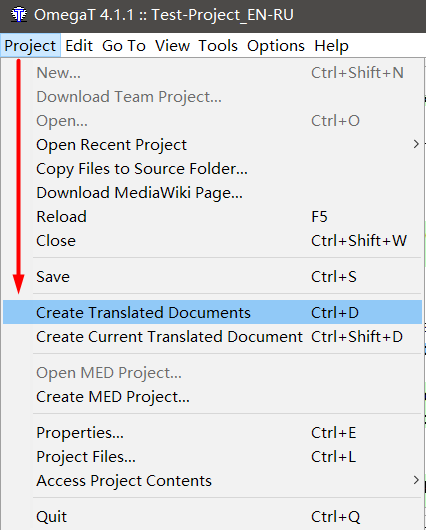
O item
Projeto → Salvar significa "salvar o projeto", ou seja, escrevendo todas as transferências para o arquivo de banco de dados. E para
obter o arquivo finalizado , você precisa selecionar
Projeto → Criar documentos traduzidos .
Com esse comando, o OmegaT criará um novo arquivo na pasta
\ target \ com o mesmo nome que o original e
alterará todo o texto para tradução . Se você não traduziu nenhum segmento, no arquivo em seu lugar estará o texto original.
Como adicionar tradução automática
Em algumas situações, a tradução automática (como o
Google Translate ) pode ajudar a traduzir mais rapidamente. O OmegaT pode ser configurado para que diretamente em sua interface exiba uma tradução automática do segmento, que você pode usar diretamente ou editar muito rapidamente.
No OmegaT, você pode conectar sistemas como o
Google Translate ,
Microsoft Translator e
Yandex.Translator . Você terá que pagar pelos dois primeiros e o
Yandex.Translator fornece seus serviços gratuitamente (dentro dos limites de uso razoáveis). Agora vou lhe dizer como fazê-lo.
- Registre uma conta no Yandex.
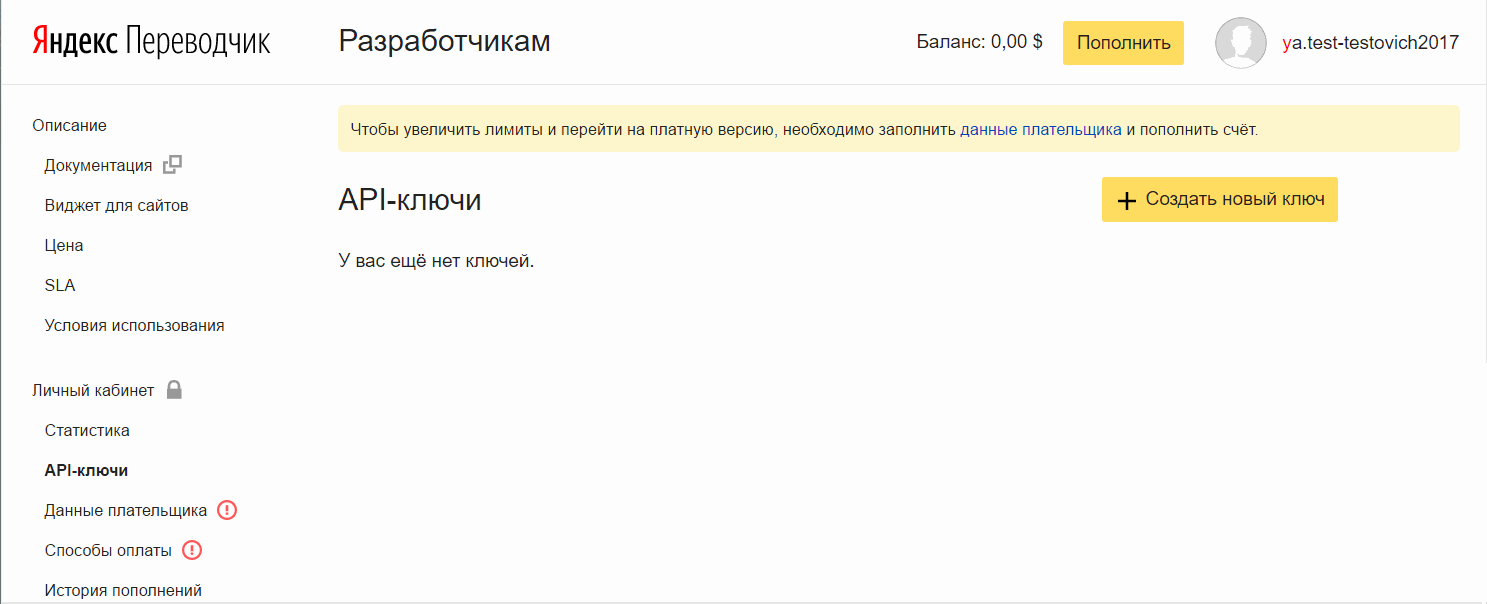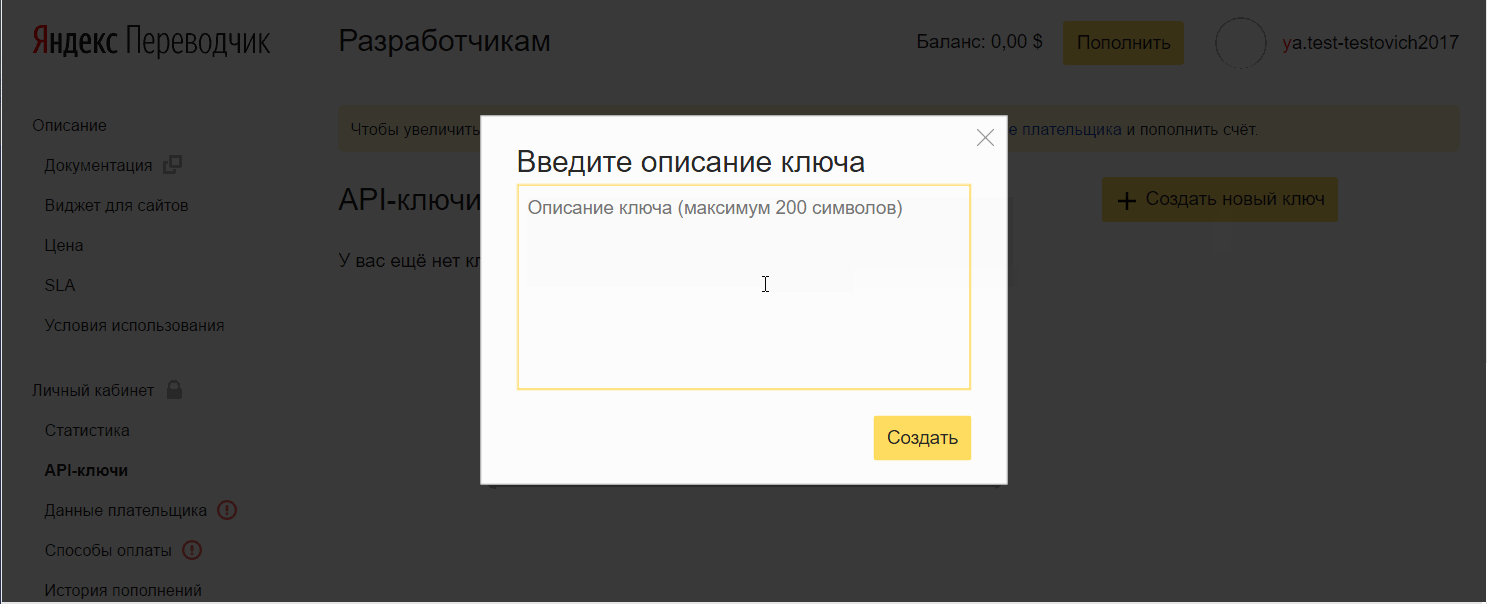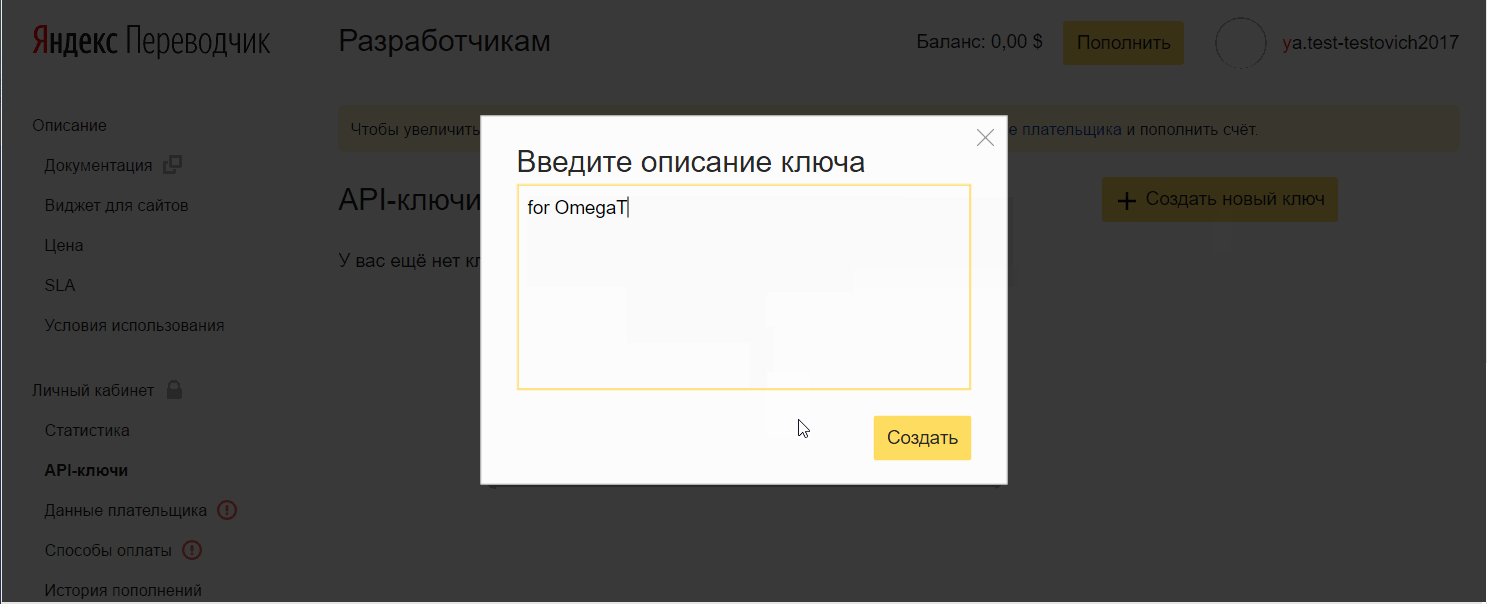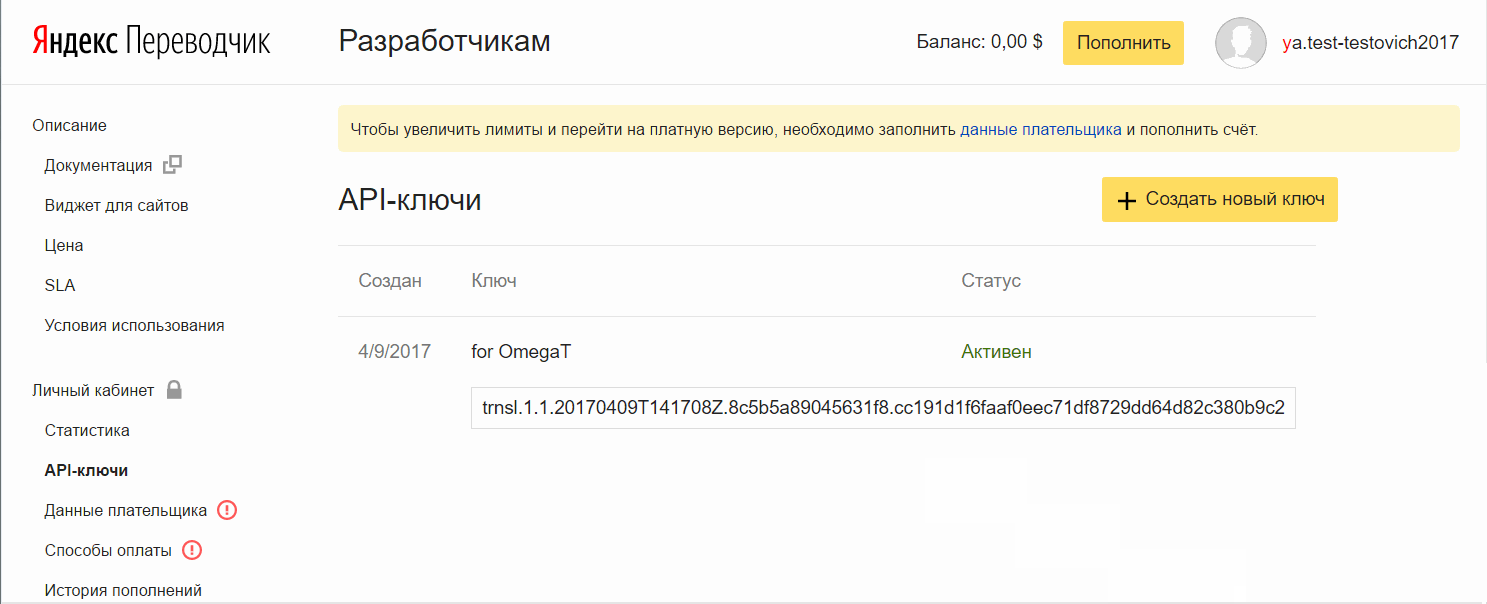
Por exemplo, obtenha correio. - Vá para a página do desenvolvedor na seção "Tradutor" neste link .
- Clique em Criar uma nova chave , insira uma descrição (para você), clique em Criar.
 Adicione a chave
Adicione a chave ao OmegaT:
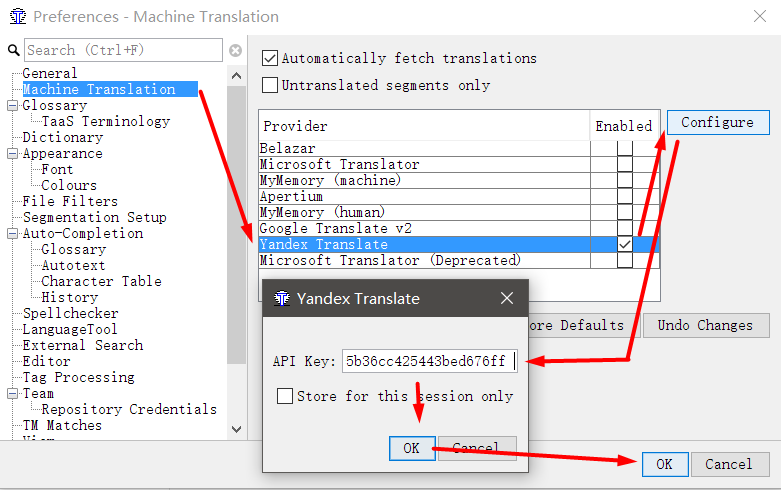
- No OmegaT, vá para Opções → Preferências → Tradução automática
- Selecione Yandex Translate , marque-o e clique em Configurar
- Copie a chave da API no campo exibido, clique em OK
- Na janela que aparece, você pode definir uma senha ou pular esta ação.
É necessária uma senha para proteger sua chave de API. Real para sistemas de tradução paga.
Feche as configurações. Agora, na janela principal do programa, você pode
clicar na guia Traduções Automáticas na parte inferior da janela. Para manter a janela de tradução automática sempre à vista, clique no ícone pequeno com duas janelas.
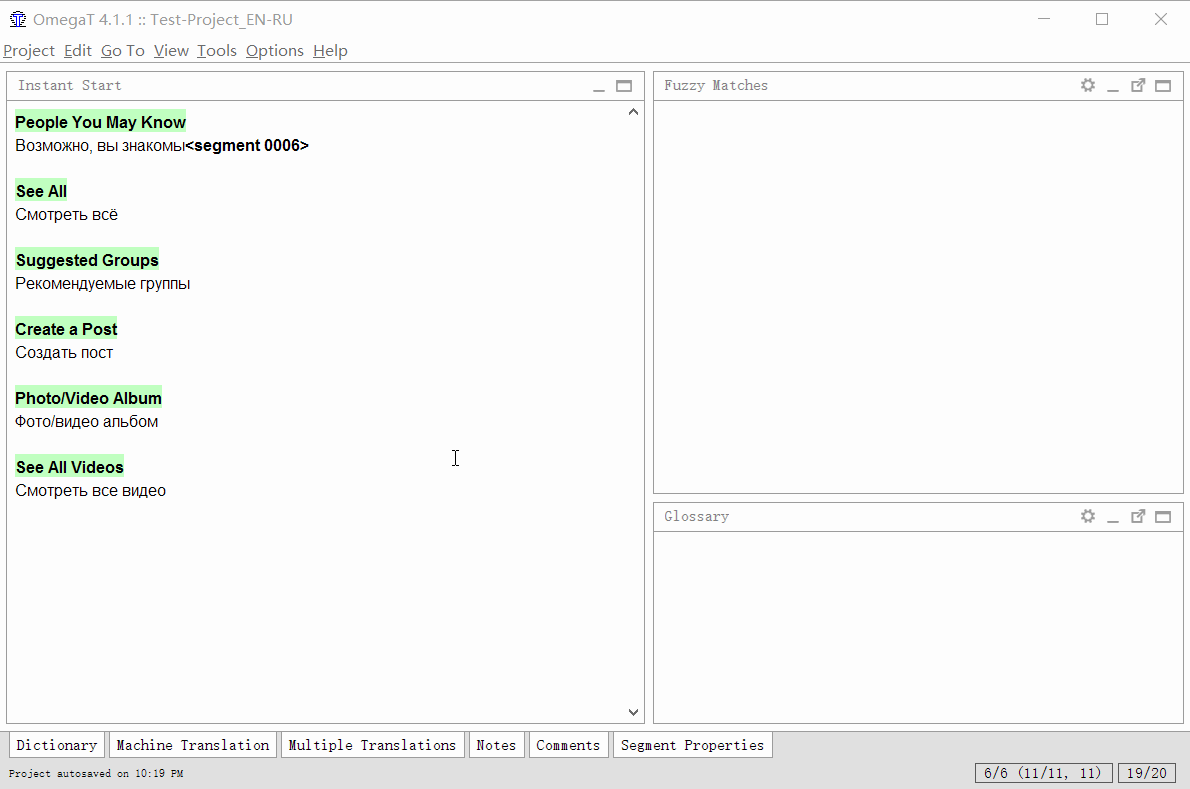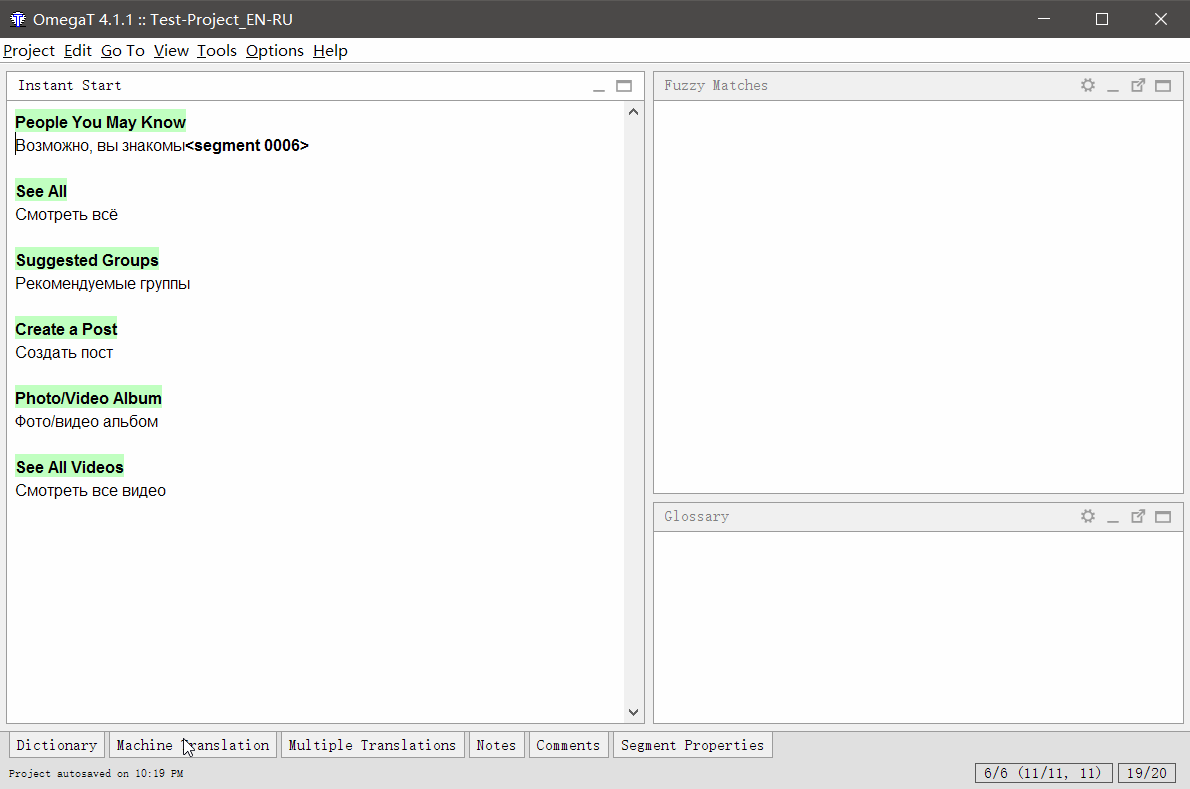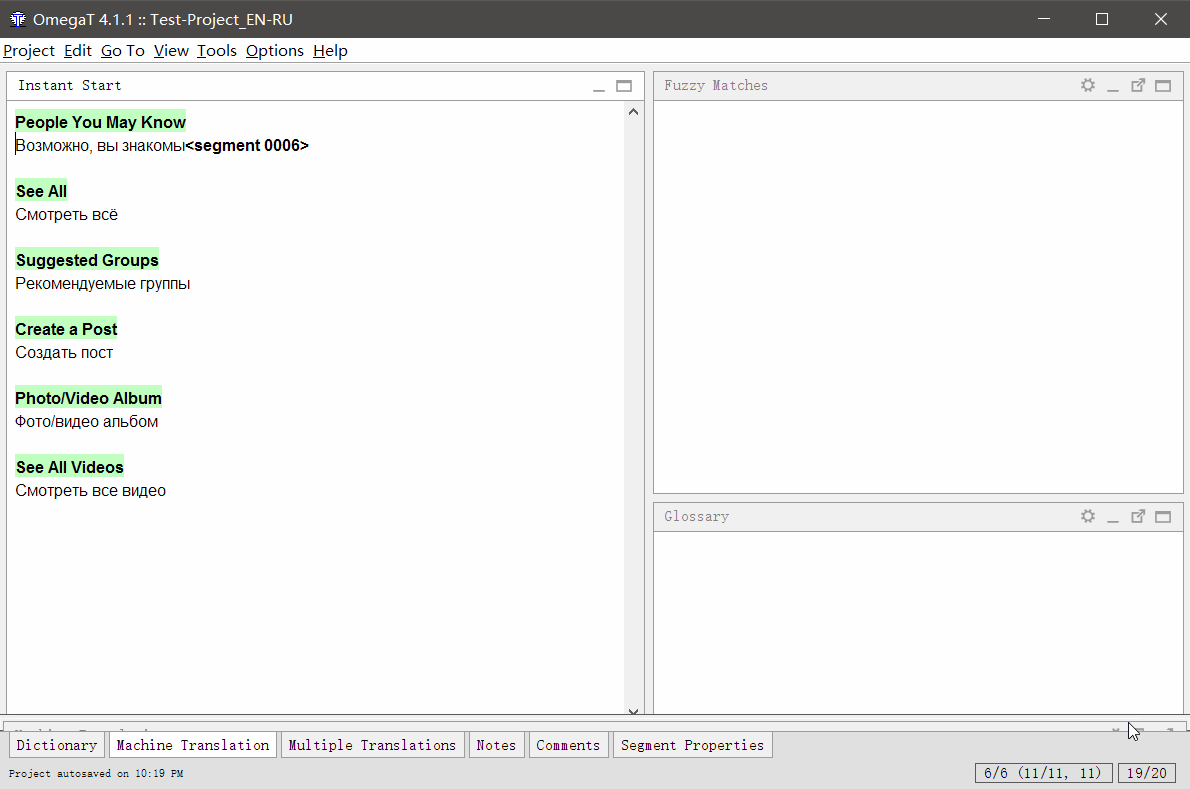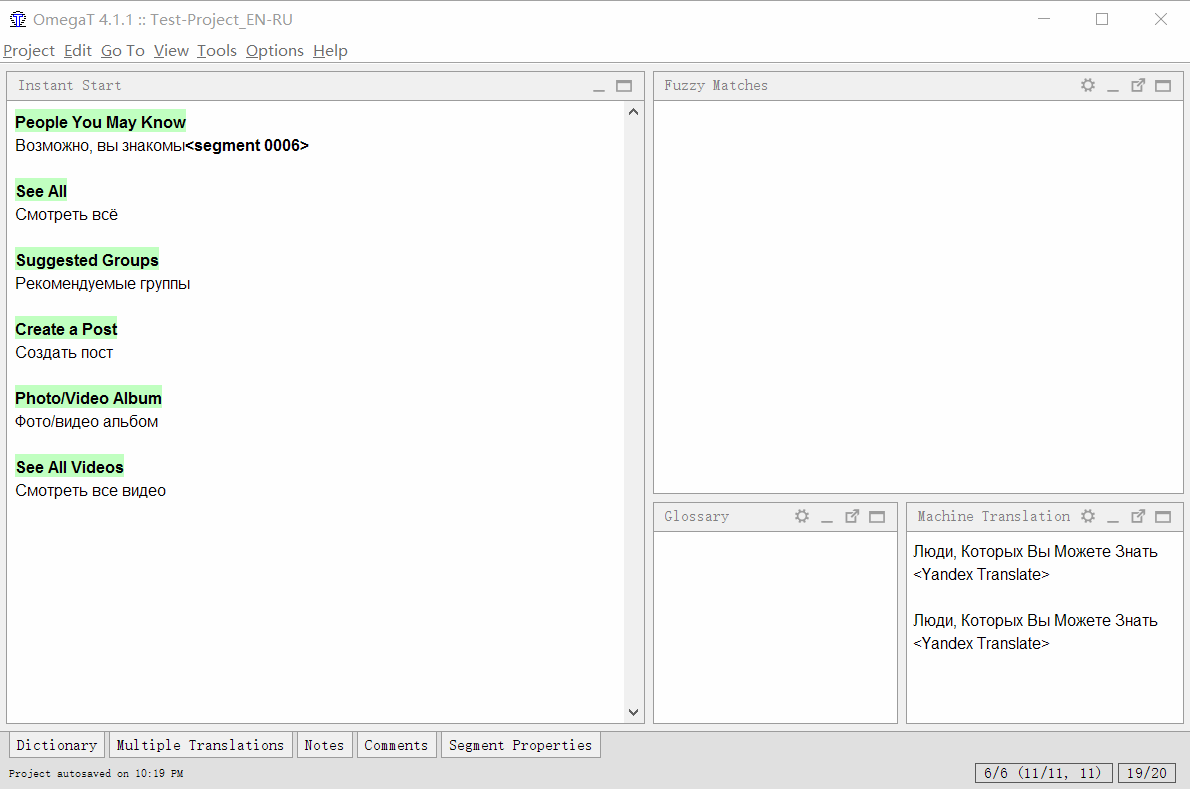
Agora, ao mudar para um novo segmento, o programa fará uma solicitação ao Yandex.Translator, receberá uma resposta e a mostrará em uma janela. A tecla de atalho Ctrl + M pode colar o resultado no campo de conversão.
Como verificar se há erros no texto?
Além da verificação ortográfica simples que configuramos anteriormente, é possível verificar erros mais complexos, desde o estilo até as tags ausentes. Para fazer isso, o OmegaT usa a
ferramenta de idioma aberta. Ele vem completo com o OmegaT, pode ser instalado separadamente ou conectado a um servidor remoto.
- Ferramentas → Verificar problemas (ou Ctrl + Shift + V )
- Clique duas vezes no erro da lista para ir para o segmento para edição.
Ao clicar com o botão direito do mouse, você pode adicionar uma palavra ao dicionário ou desativar a verificação desse tipo de erro.
À esquerda na janela
Verificar problemas , você pode selecionar o filtro
Tags . É útil na tradução de documentos com um grande número de tags, que são muito importantes para salvar - por exemplo, ao localizar software.
Dica: Se você deseja salvar as tags a todo custo, o OmegaT pode ser impedido de criar documentos finais, se houver erros nas tags. Isso é feito em
Ferramentas → Preferências → Processamento de tags → Não permite criar documentos traduzidos com problemas de tags .
O ajuste fino da Ferramenta de Idiomas está disponível em
Ferramentas → Preferências → LanguageTool. Aqui você pode escolher se deseja usar a Ferramenta de Idioma interna ou se conectar a um servidor local / remoto. Abaixo, você pode selecionar o tipo de erro ao qual o programa responderá, por exemplo, "
Pontuação " → "
Vírgula ausente antes da preposição" AND "em uma frase complexa ou"
Estilo "→"
Palavras faladas ".
Como abrir memória de tradução TMX?
Acontece que você precisa ver o que está no arquivo * .tmx ou até editá-lo. A estrutura do arquivo é bastante simples, e você pode conviver com o bloco de notas, mas isso não é muito conveniente. O OmegaT não pode abrir o
TMX para edição: a memória de tradução pode ser adicionada apenas ao projeto, mas não pode ser aberta por si só.
Para usuários do Windows, o utilitário
Olifant gratuito do pacote
Okapi é adequado,
você pode baixá-lo aqui .
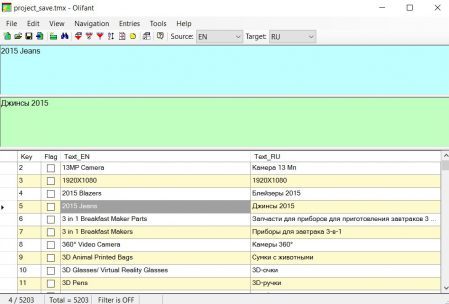
Não vejo razão para escrever instruções passo a passo para este programa, tudo é intuitivo:
Arquivo → Abrir , selecione a memória de tradução. No topo do programa, o original e a tradução, na parte inferior - uma lista de todos os segmentos.
Através de
Arquivo → Propriedades da TM, você pode alterar as propriedades da memória de tradução, como pares de idiomas, codificação e assim por diante.
Como criar sua própria TM?
Suponha que você já tenha um arquivo bilíngue de alta qualidade e deseje usá-lo no projeto como material de referência. Se o arquivo estiver no formato
Excel , onde o texto original está em uma coluna e a tradução correspondente nas células opostas, é muito fácil fazer a TM.
Existem três maneiras que eu uso:
- Utilitário Okapi Olifant gratuito
- Alinhador OmegaT incorporado
- Serviço online Translatum.gr
Olifante
O programa sobre o qual falamos no capítulo anterior pode não apenas abrir
TMXs prontos , mas também criar novos, além de combinar vários
* .tmx em uma memória.
Instale e execute o
Olifant , clique em
Arquivo → Novo e selecione o idioma de origem e o idioma de tradução. Agora adicione os segmentos bilíngües à nova memória:
Arquivo → Importar . Você pode adicionar arquivos do
Wordfast, outros arquivos
* .tmx ou
delimitados por tabulações - em outras palavras, um arquivo de texto em que o fragmento de origem e sua tradução são separados por tabulações.
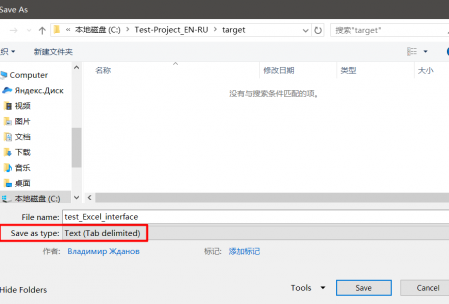
O arquivo
delimitado por tabulação pode ser criado no
MS Excel ou no
Libre Office Calc . Para fazer isso, crie uma tabela com duas colunas. Na primeira, cole o texto de origem, nas células opostas na segunda coluna - a tradução.
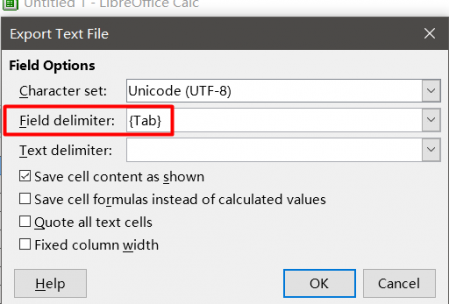
Salve o arquivo no formato de
texto delimitado por tabulação (no
Microsoft Office ) ou no
CSV de texto com os parâmetros
Delimitador de campo = Tab, Conjunto de caracteres = UTF-8 e
Delimitador de texto = * vazio * se você estiver usando o
Libre Office .
Ao importar todos os fragmentos necessários, basta salvar em
Arquivo → Salvar como no
formato TMX .
OmegaT Aligner
Ao contrário do Olifant, a fonte não é uma tabela com duas colunas, mas dois arquivos independentes com a mesma estrutura, mas em idiomas diferentes. Quanto mais complexa for a formatação e mais diferenças, pior será o resultado da correspondência automática, mas ela poderá ser corrigida manualmente no
Aligner .
Inicie o
OmegaT , abra
Ferramentas → Alinhar arquivos . Indique os idiomas do original e da tradução, anexe os arquivos.
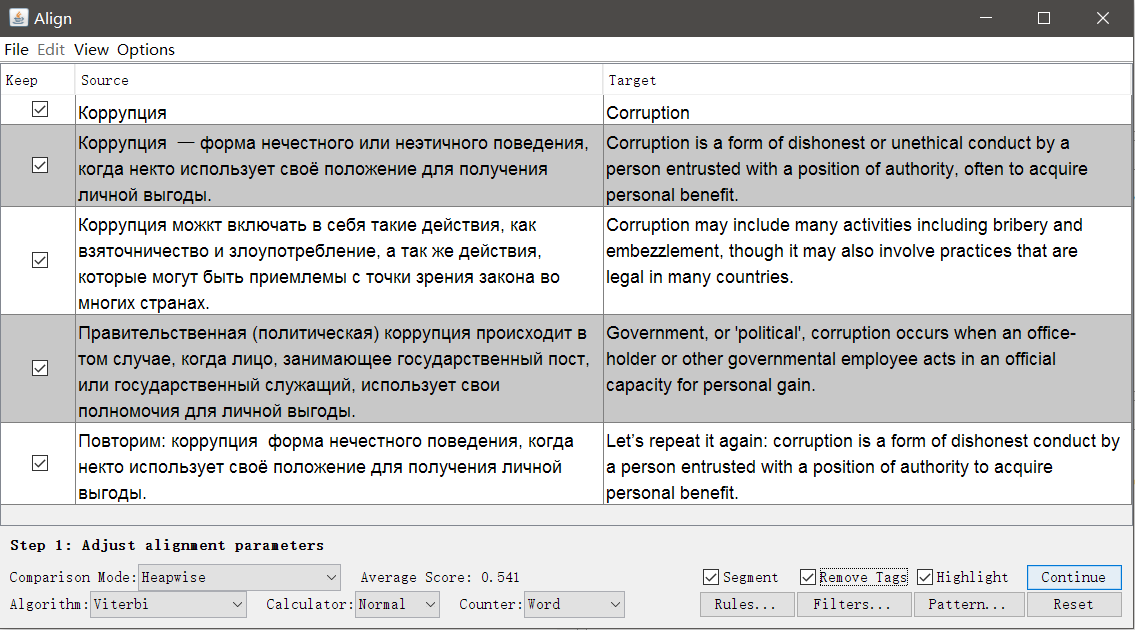
Se necessário, você pode remover as tags e alterar as configurações de segmentação.
Clique em Continuar e você será levado a uma janela com ajuste manual de segmentos: você pode dividir, mesclar ou mover segmentos para cima ou para baixo.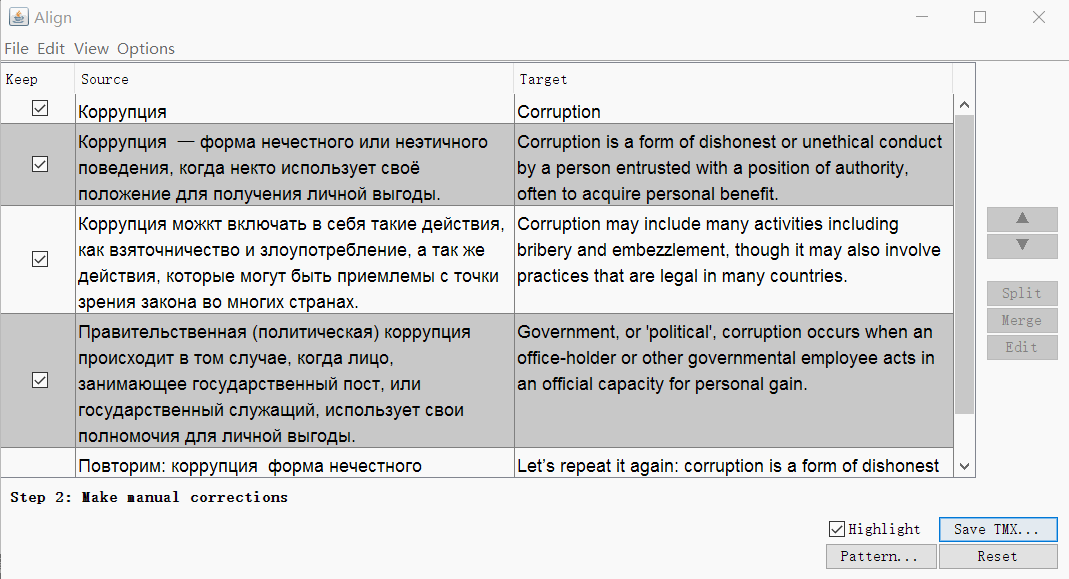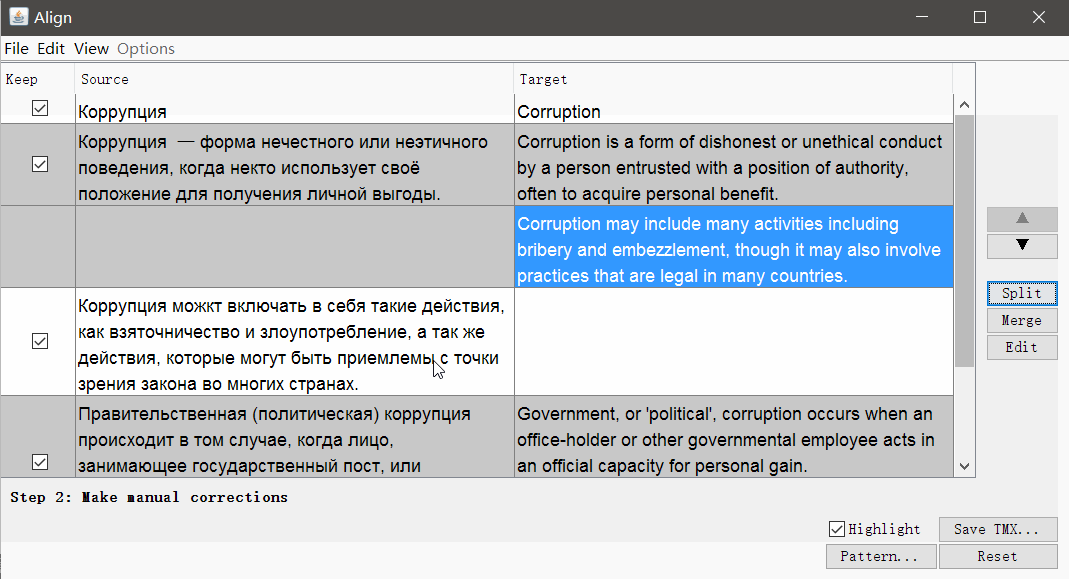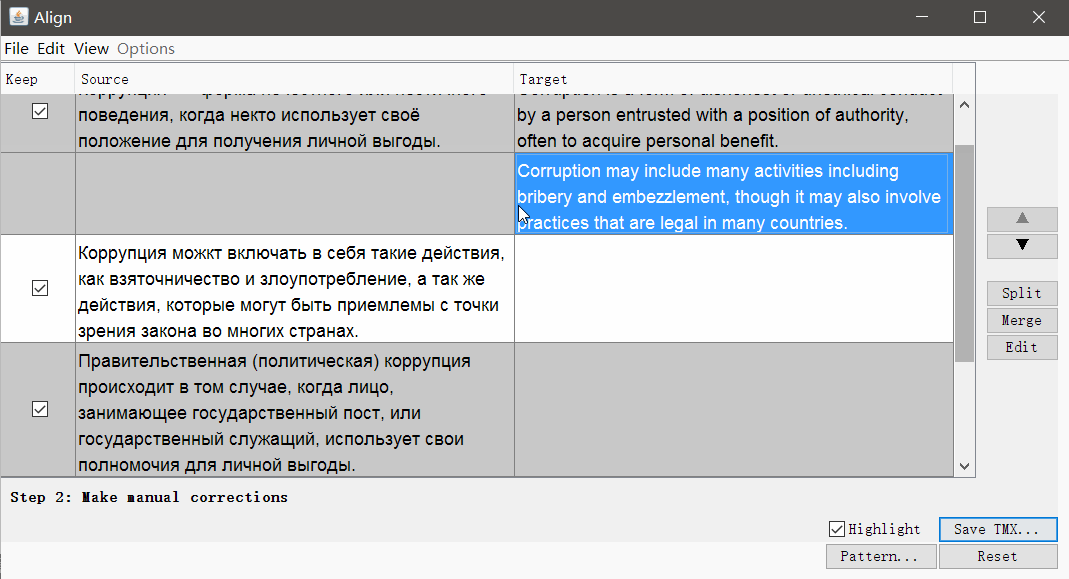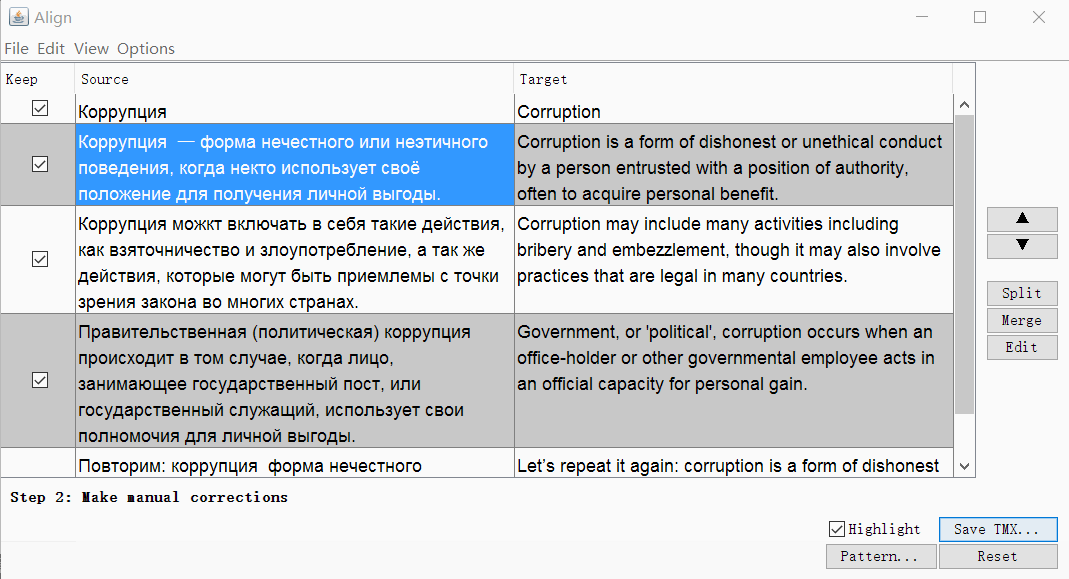 Quando tudo parecer bom, salve o resultado com o botão Salvar TMX .
Quando tudo parecer bom, salve o resultado com o botão Salvar TMX .Translatum.gr
Funciona da mesma forma que o Olifant , na entrada é necessário enviar um arquivo do Excel com duas colunas de texto.- Crie um novo arquivo do Excel (obrigatório * .xlsx)
- Na primeira coluna, insira o texto original , na segunda - tradução
Não use formatação, ele não será salvo - Siga o link do conversor
- Selecionar arquivo criado
- Indique os códigos dos idiomas de origem e de destino.Por
exemplo, se você tiver um texto em inglês-russo, será EN-US e RU-RU - Clique em Enviar
- Uma página será aberta, onde você poderá baixar o arquivo com memória de tradução.
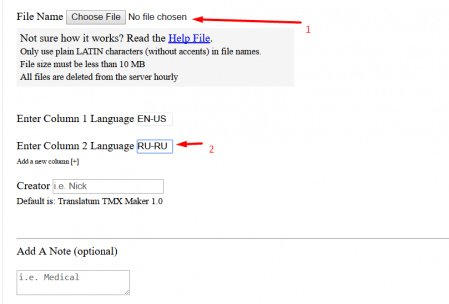 Para usar a memória de tradução no projeto, descompacte o arquivo e coloque-o na pasta do projeto, subdiretório \ tm \ (para exibir correspondências difusas) ou \ tm \ auto \ (para forçar 100% das correspondências).Atenção!Há um bug bastante desagradável ao criar memória de tradução, que usa caracteres especiais como ">", "<" e até apóstrofos. Como o TMX é uma estrutura XML , os caracteres especiais usados na estrutura do documento são convertidos em pedaços de texto "seguros". Por exemplo, o apóstrofo 'se transformará em & pos; (e comercial, pos e ponto e vírgula).Em algumas situações, isso pode prejudicar bastante a memória de tradução. Na verdade, ainda não encontrei uma solução para esse problema.
Para usar a memória de tradução no projeto, descompacte o arquivo e coloque-o na pasta do projeto, subdiretório \ tm \ (para exibir correspondências difusas) ou \ tm \ auto \ (para forçar 100% das correspondências).Atenção!Há um bug bastante desagradável ao criar memória de tradução, que usa caracteres especiais como ">", "<" e até apóstrofos. Como o TMX é uma estrutura XML , os caracteres especiais usados na estrutura do documento são convertidos em pedaços de texto "seguros". Por exemplo, o apóstrofo 'se transformará em & pos; (e comercial, pos e ponto e vírgula).Em algumas situações, isso pode prejudicar bastante a memória de tradução. Na verdade, ainda não encontrei uma solução para esse problema.Como calcular o volume do projeto
Devemos dizer aos clientes quanto você levará para a transferência!De fato, não há nada mais fácil. Abra o projeto no OmegaT , vá em Ferramentas → Estatísticas .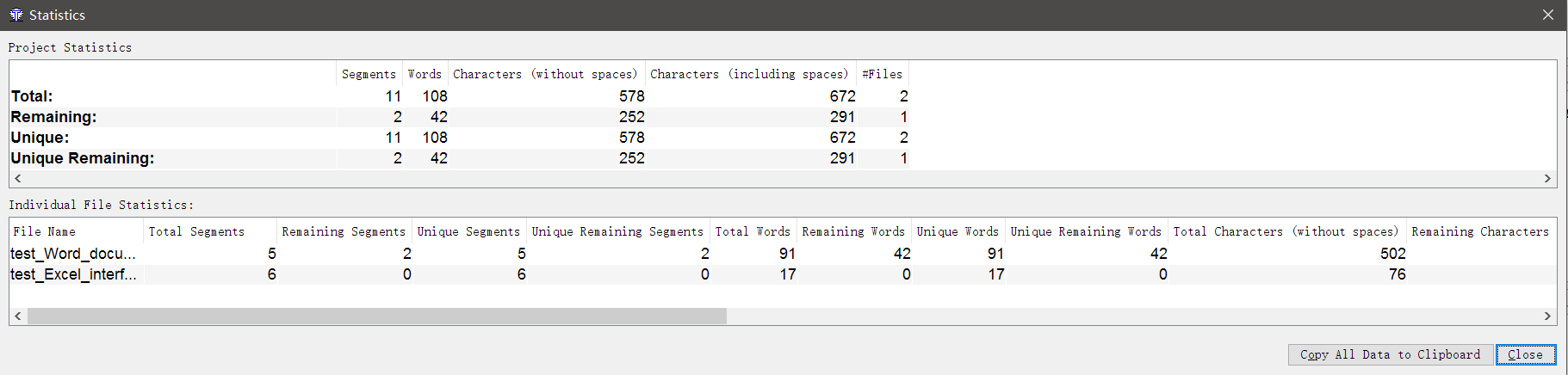 Aqui você encontrará informações abrangentes sobre quantas palavras e caracteres nos arquivos, quantas repetições estão aqui, quantas já foram traduzidas e quanto resta a ser traduzido, e assim por diante.Infelizmente, não existe uma calculadora do custo da tradução no OmegaT, você terá que calcular tudo sozinho.
Aqui você encontrará informações abrangentes sobre quantas palavras e caracteres nos arquivos, quantas repetições estão aqui, quantas já foram traduzidas e quanto resta a ser traduzido, e assim por diante.Infelizmente, não existe uma calculadora do custo da tradução no OmegaT, você terá que calcular tudo sozinho.Como mesclar e dividir segmentos?
Acontece que você deseja combinar dois segmentos em um ou vice-versa, força um segmento específico a se dividir em duas partes. Se o problema for encontrado com um grande número de segmentos no projeto, vale a pena reconfigurar as regras de segmentação. Se você precisar mesclar ou dividir segmentos no sentido do ponto, use o script especial Mesclar ou dividir segmentos:- Instale o script
Baixe aqui , descompacte-o na pasta \ scripts (no Windows pode ser C: \ Arquivos de Programas (x86) \ OmegaT \ scripts \) - Tornar as regras de segmentação Projeto Específico do
Projeto → Propriedades → Segmentação → marque a caixa Tornar as regras de segmentação específicas do projeto - Dê um botão ao script
Ferramentas → Script, na parte esquerda da janela, localize Mesclar ou dividir segmentos, selecione-o com um clique do mouse e clique com o botão direito do mouse em um dos números na parte inferior da janela. Por exemplo, por unidade. E clique em Adicionar script.
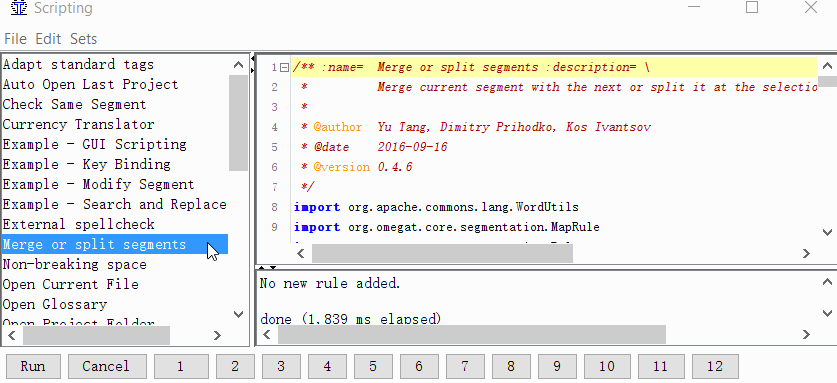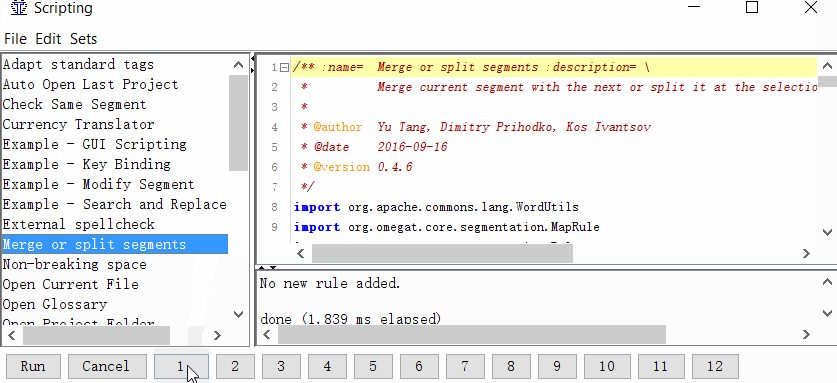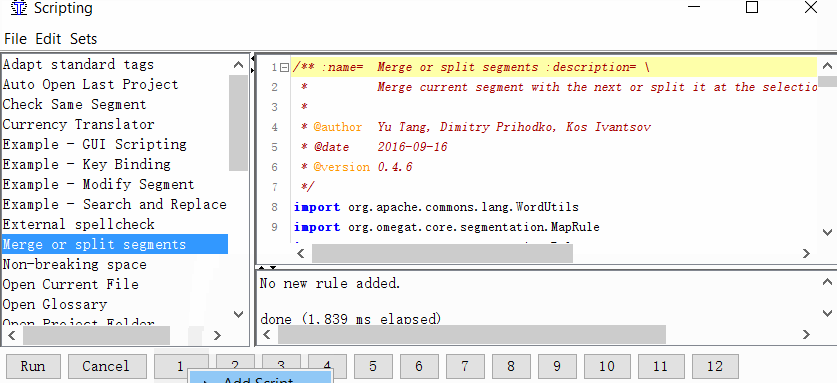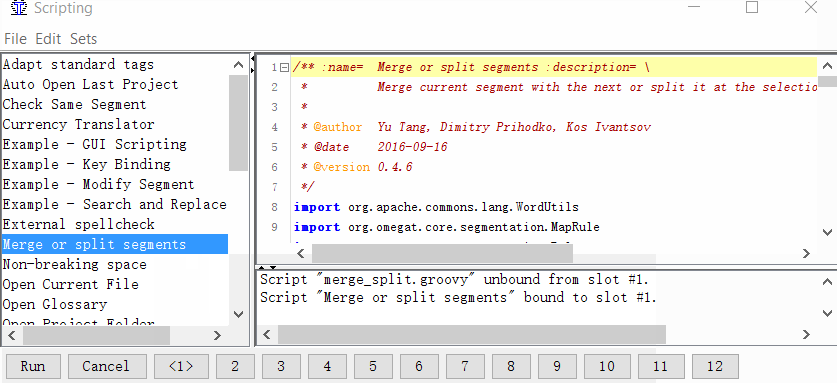 Agora você pode mesclar ou dividir segmentos.
Agora você pode mesclar ou dividir segmentos.Unificação
- Encontre os dois segmentos um após o outro que você deseja combinar;
- Vá para o primeiro segmento;
- Clique em Ferramentas → 1. Mesclar ou dividir segmentos
O programa exibirá um aviso com o resultado da mesclagem. Você pode clicar em OK para mesclar ou cancelar a ação.Separação
- Encontre o segmento que você deseja dividir;
- No texto de origem do segmento (acima da tradução), selecione a segunda metade do texto (do meio até o final) que você deseja criar segmentos separados;
- Clique em Ferramentas → 1. Mesclar ou dividir segmentos
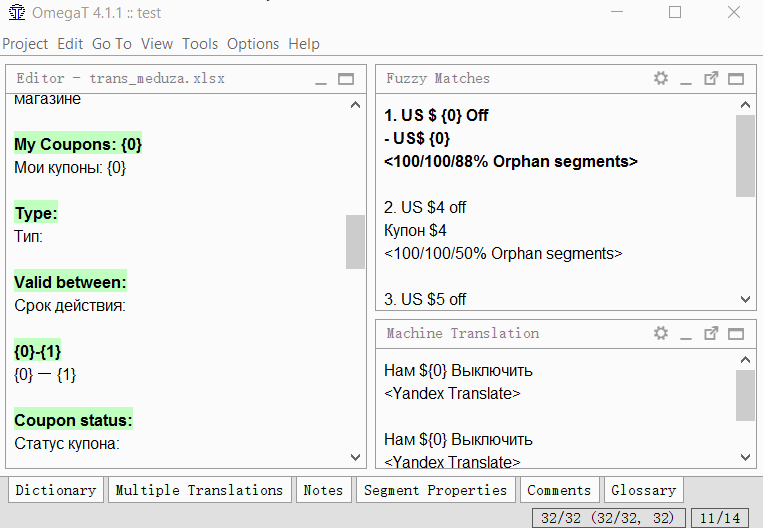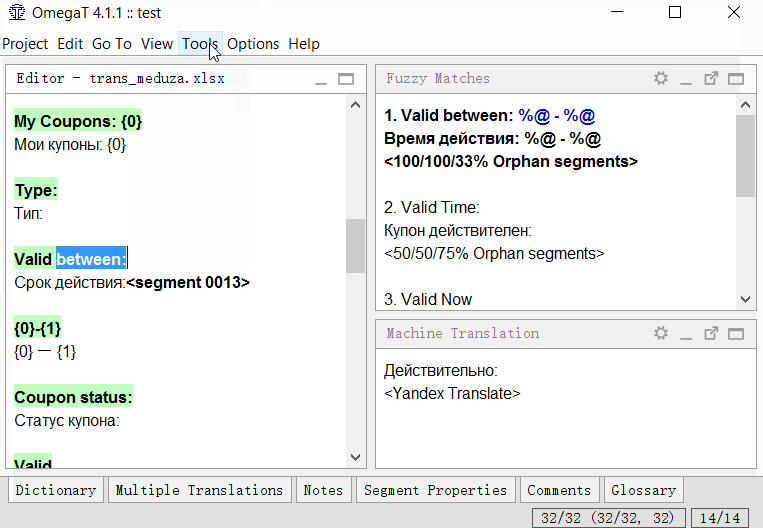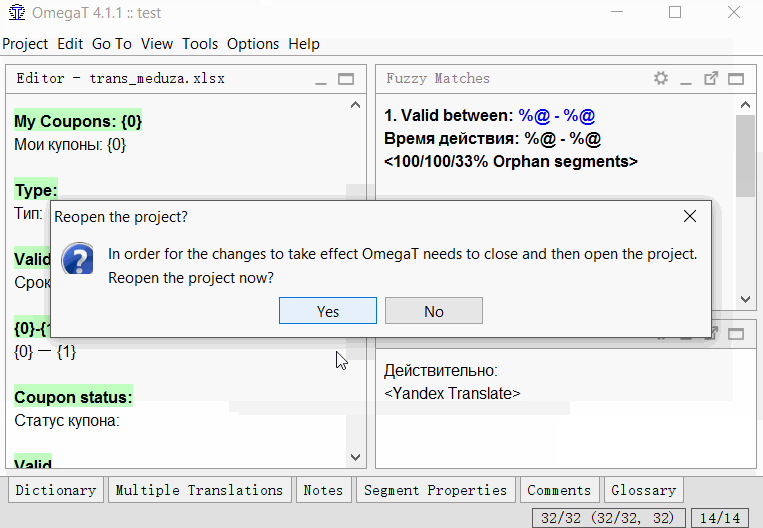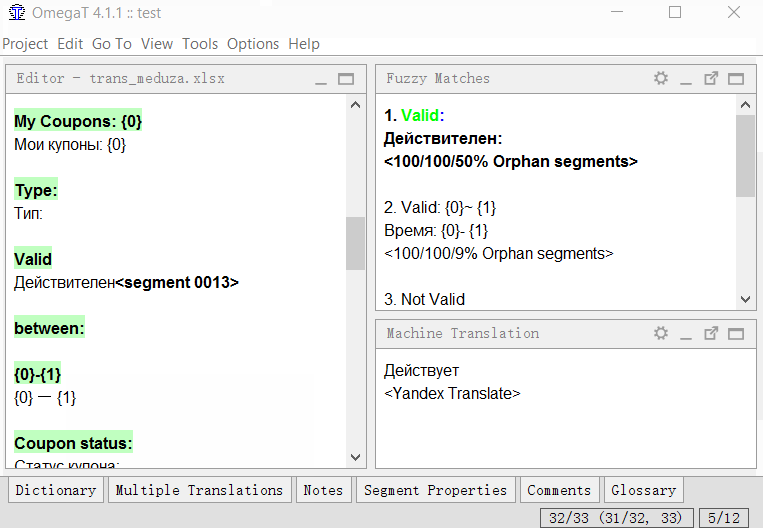 O programa exibirá um aviso com o resultado da divisão. Você pode clicar em OK para dividir ou cancelar a ação.O script cria uma nova regra de segmentação e a aplica ao projeto. O script está muito longe do ideal e nem sempre funciona, mas até agora no OmegaT é a única maneira de segmentar / mesclar segmentos no sentido do ponto.
O programa exibirá um aviso com o resultado da divisão. Você pode clicar em OK para dividir ou cancelar a ação.O script cria uma nova regra de segmentação e a aplica ao projeto. O script está muito longe do ideal e nem sempre funciona, mas até agora no OmegaT é a única maneira de segmentar / mesclar segmentos no sentido do ponto.Em vez de uma conclusão
Combinei as duas notas do meu livreto aconchegante em uma enorme folha sobre o OmegaT. Tentei revelar todas as suas principais características, que uso regularmente. Certifique-se de escrever nos comentários por que o artigo é burro e em qual hub ele realmente pertence.Tradutores profissionais devem criticar minha tradução para inglês-russo e participar de uma pesquisa sobre programas normais de CAT.PS: alguém sabe por que o mecanismo GT não entende os links html dentro da página?