 Uma captura de tela da tarefa e a emissão da rede neural pix2code em seu próprio idioma, que o compilador converte em código para a plataforma desejada (Android, iOS)
Uma captura de tela da tarefa e a emissão da rede neural pix2code em seu próprio idioma, que o compilador converte em código para a plataforma desejada (Android, iOS)O novo programa
pix2code (um
artigo científico ) foi projetado para facilitar o trabalho de programadores que estão envolvidos no negócio tedioso de codificar a GUI do cliente.
O designer geralmente cria layouts de interface e o programador deve escrever código para implementar esse design. Esse trabalho ocupa um tempo valioso que o desenvolvedor pode gastar em tarefas mais interessantes e criativas, ou seja, na implementação das funções e lógica reais do programa, não na GUI. Em breve, a geração de código poderá ser transferida para os ombros do programa. Uma demonstração de brinquedo das possibilidades futuras de aprendizado de máquina é o projeto
pix2code , que já alcançou o primeiro lugar na
lista dos repositórios mais populares do GitHub , embora o autor nem tenha publicado o código fonte e os conjuntos de dados para o treinamento da rede neural! Um interesse tão grande neste tópico.
Codificar uma GUI é chato. Para piorar, essas são linguagens de programação diferentes em plataformas diferentes. Ou seja, você precisa escrever um código separado para Android, separado para iOS, se o programa funcionar nativamente. Isso leva ainda mais tempo e faz com que você execute as mesmas tarefas chatas. Mais precisamente, era antes. O programa pix2code gera código GUI para as três plataformas principais - Andriod, iOS e HTML / CSS de plataforma cruzada - com uma precisão de 77% (a precisão é determinada na linguagem interna do programa - comparando o código gerado com o código de destino / esperado para cada plataforma).
O autor do programa Tony Beltramelli, da startup dinamarquesa
UIzard Technologies, chama isso de demonstração do conceito. Ele acredita que, ao escalar, o modelo melhorará a precisão da codificação e é potencialmente capaz de salvar as pessoas de codificarem manualmente a GUI.
O programa pix2code é construído em redes neurais convolucionais e recorrentes. O treinamento na GPU Nvidia Tesla K80 levou um pouco menos de cinco horas - período durante o qual o sistema otimizou
parâmetros para um conjunto de dados. Então, se você quiser treiná-la para três plataformas, levará cerca de 15 horas.
O modelo é capaz de gerar código aceitando apenas valores de pixel de uma captura de tela na entrada. Em outras palavras, um pipeline especial não é necessário para uma rede neural extrair recursos e pré-processar dados de entrada.
A geração de código de computador a partir da captura de tela pode ser comparada com a geração de uma descrição de texto a partir de uma fotografia. Assim, a arquitetura do modelo pix2code consiste em três partes: 1) um módulo de visão computacional para reconhecer imagens, objetos apresentados, localização, forma e cor (botões, legendas, contêineres de elementos); 2) um módulo de linguagem para entender o texto (neste caso, uma linguagem de programação) e gerar exemplos de sintaxe e semanticamente corretos; 3) usando os dois modelos anteriores para gerar descrições de texto (código) para objetos reconhecidos (elementos da GUI).
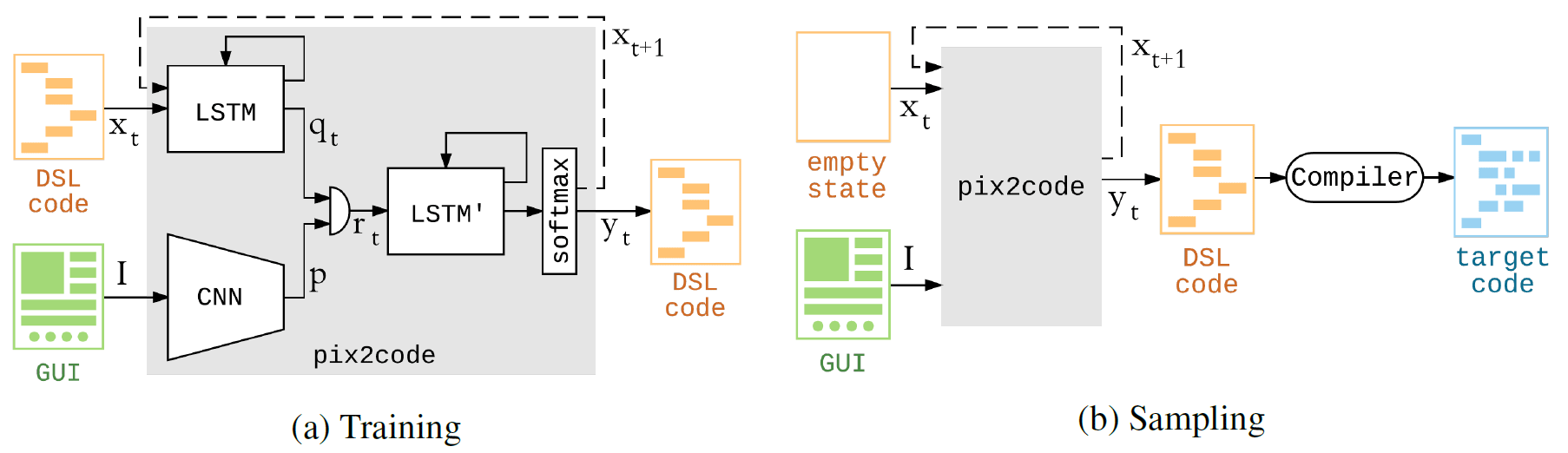
O autor chama a atenção para o fato de que a rede neural pode ser treinada em um conjunto de dados diferente - e então começará a gerar código em outros idiomas para outras plataformas. O próprio autor não planeja fazer isso, porque considera o pix2code como um tipo de brinquedo que demonstra algumas das tecnologias nas quais sua startup está trabalhando. No entanto, qualquer pessoa pode bifurcar o projeto e criar uma implementação para outros idiomas / plataformas.
Em um artigo científico, Tony Beltramelli escreveu que publicaria conjuntos de dados para treinar a rede neural em domínio público no repositório no GitHub. O repositório já foi criado. Lá, na seção Perguntas frequentes, o autor esclarece que ele publicará conjuntos de dados após a publicação (ou recusa em publicar) de seu artigo na
conferência do NIPS 2017 . Uma notificação dos organizadores da conferência deve chegar no início de setembro, para que os conjuntos de dados apareçam no repositório ao mesmo tempo. Haverá capturas de tela da GUI, o código correspondente na linguagem do programa e a saída do compilador para as três plataformas principais.
Em relação ao código-fonte do programa, seu autor não prometeu publicar, mas, devido ao grande interesse em seu desenvolvimento, ele decidiu abri-lo também. Isso será feito simultaneamente com a publicação dos conjuntos de dados.
O artigo científico foi
publicado em 22 de maio de 2017 no site de pré-impressão arXiv.org (arXiv: 1705.07962).