 Nós, da equipe de serviços de pagamento em blockchain da Wirex , estamos familiarizados com a experiência da necessidade de refinar e melhorar constantemente a solução tecnológica existente. O autor do material abaixo fala sobre a história da evolução da implantação de código da famosa plataforma de notícias sociais Reddit.
Nós, da equipe de serviços de pagamento em blockchain da Wirex , estamos familiarizados com a experiência da necessidade de refinar e melhorar constantemente a solução tecnológica existente. O autor do material abaixo fala sobre a história da evolução da implantação de código da famosa plataforma de notícias sociais Reddit."É importante seguir a direção do seu desenvolvimento para poder enviá-lo em uma boa direção a tempo."
A equipe do Reddit está constantemente implantando código. Todos os membros da equipe de desenvolvimento escrevem regularmente códigos que são verificados novamente pelo próprio autor e testados externamente, para que ele possa ir para a "produção". Toda semana fazemos pelo menos 200 "implantações", cada uma das quais geralmente leva menos de 10 minutos.
O sistema que fornece tudo isso evoluiu ao longo dos anos. Vamos ver o que mudou nisso todo esse tempo e o que permaneceu inalterado.
Início da história: implantações estáveis e recorrentes (2007-2010)
Todo o sistema que temos hoje cresceu a partir de uma semente - um script Perl chamado push. Foi escrito há muito tempo, em tempos muito diferentes para o Reddit. Toda a nossa equipe técnica era tão pequena naquele momento que se
encaixava silenciosamente
em uma pequena “sala de reuniões” . Não usamos a AWS na época. O site funcionou em um número finito de servidores e qualquer capacidade adicional teve que ser adicionada manualmente. Tudo funcionou em um aplicativo Python monolítico grande chamado r2.
Uma coisa ao longo dos anos permaneceu inalterada. As solicitações foram classificadas no balanceador de carga e distribuídas entre os "conjuntos" que contêm servidores de aplicativos mais ou menos idênticos. Por exemplo, as páginas da
lista de tópicos e
comentários são processadas por diferentes conjuntos de servidores. De fato, qualquer processo r2 pode lidar com qualquer tipo de solicitação; no entanto, a divisão em conjuntos permite proteger cada um deles de saltos repentinos no tráfego em conjuntos vizinhos. Assim, no caso de crescimento do tráfego, a falha não ameaça todo o sistema, mas seus pools individuais.
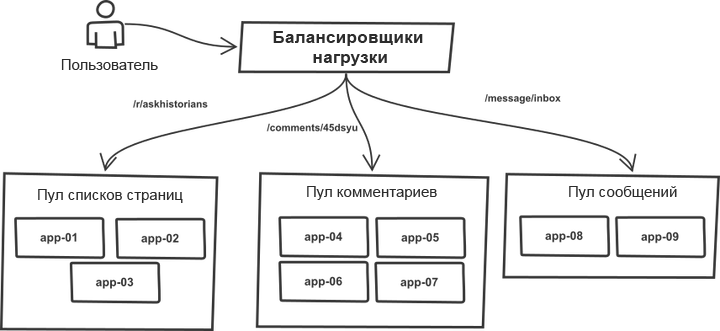
A lista de servidores de destino foi escrita manualmente no código da ferramenta de envio e o processo de implantação funcionou com um sistema monolítico. A ferramenta percorreu a lista de servidores, conectados via SSH, executou uma das seqüências predefinidas de comandos que atualizavam a cópia atual do código usando o git e reiniciam todos os processos de aplicativos. A essência do processo (o código é bastante simplificado para uma compreensão geral):
# `make -C /home/reddit/reddit static` `rsync /home/reddit/reddit/static public:/var/www/` # app- # , foreach $h (@hostlist) { `git push $h:/home/reddit/reddit master` `ssh $h make -C /home/reddit/reddit` `ssh $h /bin/restart-reddit.sh` }
A implantação ocorreu sequencialmente, um servidor após o outro. Por toda a sua simplicidade, o esquema teve uma vantagem importante: é muito semelhante à "
implantação de canários ". Ao implantar o código em vários servidores e perceber erros, você percebeu imediatamente que havia erros, pode interromper (Ctrl-C) o processo e reverter antes que surjam problemas com todas as solicitações de uma só vez. A facilidade de implantação tornou fácil e sem sérias consequências verificar as coisas na produção e reverter se elas não funcionaram. Além disso, era conveniente determinar qual implantação específica causou erros, onde especificamente e o que precisa ser revertido.
Esse mecanismo fez um bom trabalho ao garantir estabilidade e controle durante a implantação. A ferramenta funcionou muito rápido. As coisas deram certo.
Nosso regimento chegou (2011)
Então contratamos mais pessoas, agora havia seis desenvolvedores e nossa nova
“sala de reuniões” ficou mais espaçosa . Começamos a perceber que o processo de implantação de código agora precisava de mais coordenação, principalmente quando os colegas trabalhavam em casa. O utilitário push foi atualizado: agora anunciava o início e o fim das implantações usando o chatbot do IRC, que simplesmente ficava no IRC e anunciava os eventos. Os processos realizados durante as implantações não sofreram quase nenhuma alteração, mas agora o sistema fez tudo pelo desenvolvedor e contou a todos sobre as modificações feitas.
A partir desse momento, o uso do bate-papo começou no fluxo de trabalho de implantação. A conversa sobre o gerenciamento da implantação a partir de bate-papos era bastante popular na época, no entanto, como usamos servidores IRC de terceiros, não podíamos confiar cem vezes no bate-papo no gerenciamento do ambiente de produção e, portanto, o processo permaneceu no nível de um fluxo unidirecional de informações.
À medida que o tráfego para o site crescia, também aumentava a infraestrutura que o apoiava. De tempos em tempos, tínhamos que iniciar um novo grupo de servidores de aplicativos e colocá-los em operação. O processo ainda não foi automatizado. Em particular, a lista de hosts em push ainda precisava ser atualizada manualmente.
O poder dos pools geralmente aumentava com a adição de vários servidores por vez. Como resultado, a execução sucessiva da lista conseguiu rolar as alterações para um grupo inteiro de servidores no mesmo pool, sem afetar os outros, ou seja, não houve diversificação pelos pools.

O UWSGI foi usado para controlar os processos de trabalho; portanto, quando atribuímos ao aplicativo um comando de reinicialização, ele eliminou todos os processos existentes de uma só vez, substituindo-os por novos. Novos processos levaram algum tempo para se preparar para processar solicitações. No caso de uma reinicialização não intencional de um grupo de servidores localizados no mesmo pool, a combinação dessas duas circunstâncias afetou seriamente a capacidade desse pool de atender solicitações. Então, chegamos a um limite na velocidade de implantação segura de código em todos os servidores. À medida que o número de servidores aumentou, também aumentou a duração de todo o procedimento.
Implantação de instrumento de reciclagem (2012)
Redesenhamos completamente a ferramenta de implantação. E embora seu nome, apesar de uma alteração completa, permanecesse o mesmo (push), desta vez foi escrito em Python. A nova versão teve algumas melhorias importantes.
Primeiro, ele pegou a lista de hosts do DNS, e não da sequência codificada no código. Isso permitiu que apenas a lista fosse atualizada, sem a necessidade de atualizar o código push. Surgiram os primórdios de um sistema de descoberta de serviços.
Para resolver o problema de reinicializações sucessivas, embaralhámos a lista de hosts antes das implantações. O embaralhamento reduziu os riscos e permitiu acelerar o processo.

A versão original embaralhava a lista aleatoriamente a cada vez, no entanto, isso dificultava a reversão rápida, porque cada vez que a lista do primeiro grupo de servidores era diferente. Portanto, corrigimos a mistura: agora ela gerava uma certa ordem que poderia ser usada durante a implantação repetida após a reversão.
Outra mudança pequena, mas importante, foi a implantação constante de alguma versão fixa do código. A versão anterior da ferramenta sempre atualizava a ramificação mestre no host de destino, mas o que acontece se o mestre muda corretamente durante a implantação devido ao fato de alguém ter iniciado o código por engano? A implantação de uma determinada revisão do git em vez de chamar pelo nome da filial tornou possível garantir que a mesma versão do código fosse usada em cada servidor de produção.
E, finalmente, a nova ferramenta distinguiu seu código (trabalhou principalmente com uma lista de hosts e os acessou via SSH) e os comandos executados nos servidores. Ainda dependia muito das necessidades do R2, mas tinha algo como um protótipo de API. Isso permitiu ao r2 seguir suas próprias etapas de implantação, o que facilitou as mudanças contínuas e liberou o fluxo. A seguir, é apresentado um exemplo de comandos executados em um servidor separado. O código, novamente, não é o código exato, mas no geral essa sequência descreve bem o fluxo de trabalho r2:
sudo /opt/reddit/deploy.py fetch reddit sudo /opt/reddit/deploy.py deploy reddit f3bbbd66a6 sudo /opt/reddit/deploy.py fetch-names sudo /opt/reddit/deploy.py restart all
Especialmente digno de nota são os nomes de busca: esta instrução é exclusiva para r2.
Escalonamento automático (2013)
Finalmente, decidimos mudar para uma nuvem com dimensionamento automático (um tópico para uma postagem separada). Isso nos permitiu economizar muito dinheiro nos momentos em que o site não estava carregado com tráfego e aumentar automaticamente a capacidade de lidar com qualquer aumento acentuado de solicitações.
Aprimoramentos anteriores, carregando automaticamente a lista de hosts do DNS, tornaram essa transição uma questão natural. A lista de hosts mudou com mais frequência do que antes, mas, do ponto de vista da ferramenta de implantação, isso não teve nenhum papel. A mudança, que foi originalmente introduzida como uma melhoria de qualidade, tornou-se um dos principais componentes necessários para executar o dimensionamento automático.
No entanto, o dimensionamento automático levou a alguns casos fronteiriços interessantes. Havia uma necessidade de controlar lançamentos. O que acontece se o servidor iniciar corretamente durante a implantação? Precisávamos garantir que cada novo servidor em execução verificasse a disponibilidade do novo código e o aceitasse, se houvesse um. Não poderíamos esquecer os servidores que ficaram offline no momento da implantação. A ferramenta precisava se tornar mais inteligente e aprender a determinar que o servidor ficou offline como parte do procedimento, e não como resultado de um erro que ocorreu durante a implantação. No último caso, ele teve que avisar em voz alta todos os colegas envolvidos no problema.
Ao mesmo tempo, nós, a propósito, e por várias razões, mudamos de uWSGI para
Gunicorn . No entanto, do ponto de vista do tópico deste post, essa transição não levou a alterações significativas.
Então funcionou por um tempo.
Muitos servidores (2014)
Com o tempo, o número de servidores necessários para atender ao pico de tráfego aumentou. Isso levou ao fato de que as implantações exigiam cada vez mais tempo. No pior cenário, uma implantação normal levou cerca de uma hora - um resultado ruim.
Reescrevemos a ferramenta para que ela possa oferecer suporte ao trabalho paralelo com hosts. A nova versão é chamada
rollingpin . A versão antiga exigia muito tempo para inicializar as conexões ssh e aguardar a conclusão de todos os comandos; portanto, a paralelização dentro de limites razoáveis nos permitiu acelerar a implantação. O tempo de implantação diminuiu novamente para cinco minutos.

Para reduzir o impacto da reinicialização simultânea de vários servidores, o componente de mistura da ferramenta se tornou mais inteligente. Em vez de embaralhar cegamente a lista, ele classificou os pools de servidores para que os hosts de um pool estivessem
o mais afastados
possível .
A mudança mais importante na nova ferramenta foi que a
API entre a ferramenta de implantação e as ferramentas em cada servidor foi definida muito mais claramente e separada das necessidades de r2. Inicialmente, isso foi feito com o desejo de tornar o código mais orientado ao código-fonte, mas logo essa abordagem foi muito útil de outra maneira. A seguir, é apresentado um exemplo de implantação com a seleção de comandos da API iniciados remotamente:

Muitas pessoas (2015)
De repente, chegou um momento em que muitas pessoas já estavam trabalhando no R2. Foi legal e, ao mesmo tempo, significava que haveria ainda mais implantações. Cumprir a regra de uma implantação por vez tornou-se cada vez mais difícil. Os desenvolvedores tiveram que concordar um com o outro sobre o procedimento para emitir o código. Para otimizar a situação, adicionamos outro elemento ao chatbot que coordena a fila de implantação. Os engenheiros solicitaram uma reserva de implantação e a receberam ou seu código "em fila". Isso ajudou a simplificar as implantações, e quem quisesse concluí-las poderia esperar com calma pela sua vez.
Outra adição importante à medida que a equipe cresceu foi acompanhar as implantações em
um só lugar . Alteramos a ferramenta de implantação para enviar métricas para o Graphite. Isso facilitou o rastreamento da correlação entre implantações e alterações de métricas.
Muitos (dois) serviços (também 2015)
De repente, chegou o momento do lançamento do segundo serviço on-line. Era uma versão móvel do site com sua própria pilha completamente diferente, seus próprios servidores e o processo de compilação. Este foi o primeiro teste real de uma API de ferramenta de implantação dividida. Além disso, a capacidade de executar todas as etapas de montagem em diferentes "locais" para cada projeto permitiu suportar a carga e lidar com a manutenção de dois serviços no mesmo sistema.
25 serviços (2016)
Durante o próximo ano, testemunhamos a rápida expansão da equipe. Em vez de dois serviços, duas dúzias apareceram, em vez de duas equipes de desenvolvimento, quinze. A maioria dos serviços foi criada no
Baseplate , em nossa estrutura de back-end ou em aplicativos clientes, semelhantes à Web móvel. A infraestrutura por trás das implantações é a mesma para todos. Em breve, muitos outros novos serviços serão lançados on-line, e tudo isso se deve em grande parte à versatilidade do rolo. Permite simplificar o lançamento de novos serviços usando ferramentas familiares às pessoas.
Airbag (2017)
À medida que o número de servidores no monólito aumentou, o tempo de implantação aumentou. Queríamos aumentar significativamente o número de implantações paralelas, mas isso causaria muitas reinicializações simultâneas dos servidores de aplicativos. Obviamente, essas coisas levam a uma queda na taxa de transferência e à perda da capacidade de atender às solicitações recebidas devido à sobrecarga dos servidores restantes.
O processo principal do Gunicorn usou o mesmo modelo do uWSGI, recarregando todos os trabalhadores ao mesmo tempo. Os novos processos de trabalho não conseguiram atender às solicitações até que estivessem totalmente carregados. O tempo de lançamento do nosso monólito variou de 10 a 30 segundos. Isso significava que, durante esse período, não poderíamos processar solicitações. Para encontrar uma saída para essa situação, substituímos o processo principal do gunicorn pelo gerente de trabalho
Einhorn do Stripe,
preservando a pilha HTTP do Gunicorn e o contêiner WSGI . Durante a reinicialização, o Einhorn cria um novo trabalhador, espera até que esteja pronto, se livra de um trabalhador antigo e repete o processo até que a atualização seja concluída. Isso cria um airbag e nos permite manter a largura de banda em um nível durante as implantações.
O novo modelo criou outro problema. Como mencionado anteriormente, a substituição de um trabalhador por um novo e totalmente concluído levou até 30 segundos. Isso significava que, se houvesse um erro no código, ele não aparecia imediatamente e conseguia implantar em muitos servidores antes de ser detectado. Para evitar isso, introduzimos um mecanismo para bloquear a transição do procedimento de implantação para o novo servidor, que estava em vigor até que todos os processos de trabalho fossem reiniciados. Foi implementado simplesmente - pesquisando o estado de einhorn e aguardando a prontidão de todos os novos trabalhadores. Para manter a velocidade no mesmo nível, expandimos o número de servidores sendo processados em paralelo, o que era completamente seguro sob as novas condições.
Esse mecanismo nos permite implantar simultaneamente em um número muito maior de máquinas, e o tempo de implantação, cobrindo aproximadamente 800 servidores, é reduzido para 7 minutos, levando em consideração pausas adicionais para verificação de bugs.
Olhando para trás
A infraestrutura de implantação descrita aqui é um produto nascido de muitos anos de melhorias consistentes, em vez de um esforço único e focado. Os ecos das decisões tomadas uma vez e alcançados nos estágios iniciais dos compromissos ainda se fazem sentir no sistema atual, e esse sempre foi o caso em todos os estágios. Essa abordagem evolutiva tem seus prós e contras: requer um mínimo de esforço em qualquer estágio; no entanto, há um risco, mais cedo ou mais tarde, de parar. É importante seguir a direção do seu desenvolvimento para poder enviá-lo em uma boa direção no prazo.
O futuro
A infraestrutura do Reddit deve estar pronta para suporte contínuo da equipe à medida que cresce e lança coisas novas. A taxa de crescimento da empresa está mais rápida do que nunca, e estamos trabalhando em projetos ainda mais interessantes e em larga escala do que tudo o que fizemos antes. Os problemas que enfrentamos hoje são de natureza dupla: por um lado, é necessário aumentar a autonomia dos desenvolvedores, por outro lado, para manter a segurança da infraestrutura de produção e melhorar o airbag, o que permite aos desenvolvedores executar implantações com rapidez e confiança.
