Os chips nos computadores de mesa mais modernos têm quatro núcleos, mas os fabricantes de chips já anunciaram planos de atualizar para seis núcleos, e os processadores de 16 núcleos estão longe de ser incomuns para servidores de alto desempenho.
Quanto mais núcleos, maior o problema de alocação de memória entre todos os núcleos enquanto trabalham juntos. Com o aumento do número de núcleos, é cada vez mais lucrativo minimizar a perda de tempo no gerenciamento dos núcleos durante o processamento de dados - porque a taxa de troca de dados fica atrás da velocidade do processador e do processamento de dados na memória. Você pode ativar fisicamente o cache rápido de outra pessoa ou pode usar seu próprio lento, mas economizar tempo de transferência de dados. A tarefa é complicada pelo fato de a quantidade de memória solicitada pelos programas não corresponder claramente aos tamanhos de cache de cada tipo.
Somente uma quantidade muito limitada de memória pode ser localizada fisicamente o mais próximo possível do processador - um cache do processador de nível L1, cuja quantidade é extremamente pequena. Daniel Sanchez, Po-An Tsai, e Nathan Beckmann, pesquisadores do Laboratório de Ciência da Computação e Inteligência Artificial do Instituto de Tecnologia de Massachusetts,
ensinaram ao computador
como configurar diferentes tipos de memória para ajustar uma hierarquia flexível de programas. tempo real O novo sistema, chamado Jenga, analisa as necessidades volumétricas e a frequência do acesso do programa à memória e redistribui a potência de cada um dos três tipos de cache do processador em combinações que proporcionam maior eficiência e economia de energia.

Para começar, os pesquisadores testaram o aumento de desempenho com uma combinação de memória estática e dinâmica ao trabalhar em programas para um processador de núcleo único e obtiveram a hierarquia principal - quando é melhor usar essa combinação. De 2 tipos de memória ou de um. Dois parâmetros foram avaliados - atraso do sinal (latência) e consumo de energia durante a operação de cada programa. Cerca de 40% dos programas começaram a funcionar pior com uma combinação de tipos de memória, o resto - melhor. Tendo corrigido quais programas “gostam” de desempenho misto e quais - o tamanho da memória, os pesquisadores construíram seu sistema Jenga.
Eles praticamente testaram 4 tipos de programas em um computador virtual com 36 núcleos. Testou o programa:
- omnet - Testbed de rede modular objetivo, biblioteca de modelagem C e plataforma de ferramentas de modelagem de rede (azul na figura)
- mcf - Meta Content Framework (vermelho)
- astar - software para exibição de realidade virtual (verde)
- bzip2 - arquivador (cor roxa)
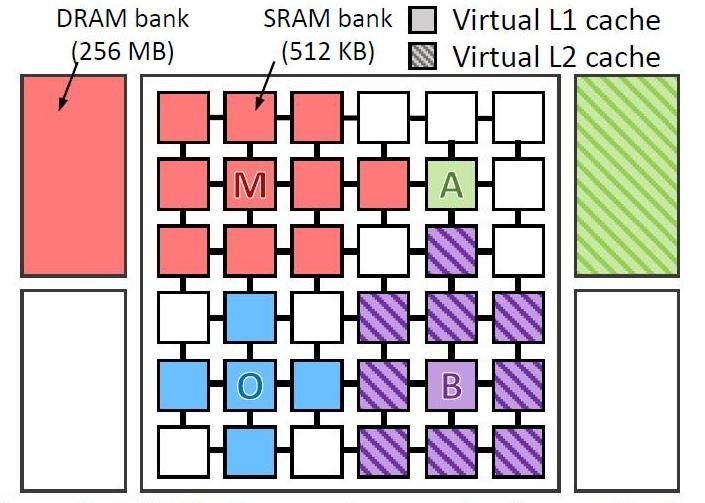
A imagem mostra onde e como os dados de cada programa foram processados. As letras indicam onde cada aplicativo está sendo executado (um por quadrante), as cores indicam onde seus dados estão localizados e a hachura indica o segundo nível da hierarquia virtual quando está presente.
Níveis de cacheO cache da CPU é dividido em vários níveis. Para processadores universais - até 3. A memória mais rápida é o cache de primeiro nível - cache L1, porque está localizado no mesmo chip que o processador. Consiste em um cache de comando e um cache de dados. Alguns processadores sem cache L1 não podem funcionar. O cache L1 é executado na frequência do processador e pode ser acessado a cada ciclo de clock. Geralmente, é possível executar várias operações de leitura / gravação ao mesmo tempo. O volume geralmente é pequeno - não mais que 128 KB.
O cache L1 interage com um cache de segundo nível - L2. É o segundo mais rápido. Geralmente, ele está localizado no chip, como L1, ou nas imediações do núcleo, por exemplo, em um cartucho do processador. Nos processadores mais antigos, um chipset na placa-mãe. O tamanho do cache L2 é de 128 KB a 12 MB. Nos modernos processadores com vários núcleos, o cache de segundo nível, localizado no mesmo chip, é uma memória compartilhada - com um tamanho total de cache de 8 MB, 2 MB por núcleo. Normalmente, a latência do cache L2 localizado no chip principal está entre 8 e 20 ciclos de clock. Em tarefas relacionadas a vários acessos a uma área limitada da memória, por exemplo, um DBMS, seu uso completo aumenta a produtividade em dez vezes.
O cache L3 é geralmente ainda maior, embora um pouco mais lento que L2 (devido ao fato de o barramento entre L2 e L3 ser mais estreito que o barramento entre L1 e L2). L3 geralmente está localizado separadamente do núcleo da CPU, mas pode ser grande - mais de 32 MB. O cache L3 é mais lento que os caches anteriores, mas ainda mais rápido que a RAM. Nos sistemas multiprocessadores é de uso comum. O uso do cache de terceiro nível é justificado em uma gama muito estreita de tarefas e pode não apenas aumentar a produtividade, mas vice-versa e levar a uma diminuição geral no desempenho do sistema.
Desabilitar o cache do segundo e terceiro níveis é mais útil em problemas matemáticos quando a quantidade de dados é menor que o tamanho do cache. Nesse caso, você pode carregar todos os dados imediatamente no cache L1 e processá-los.
Periodicamente, o Jenga no nível do sistema operacional reconfigura hierarquias virtuais para minimizar a troca de dados, dadas as restrições de recursos e o comportamento do aplicativo. Cada reconfiguração consiste em quatro etapas.
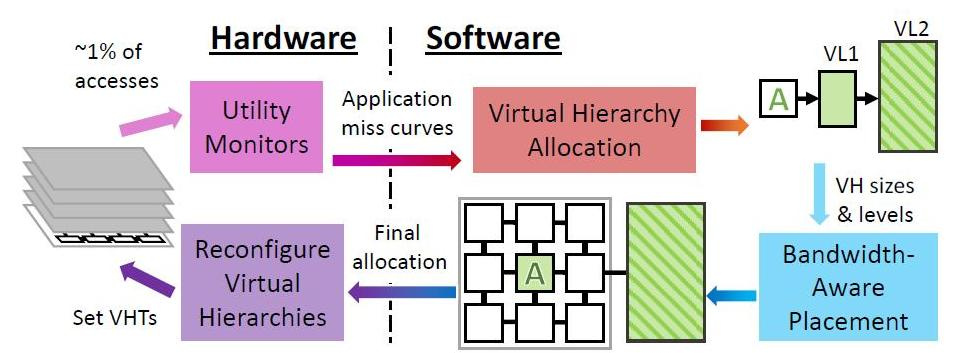
O Jenga distribui dados não apenas dependendo de quais programas são despachados - adorando uma grande memória de velocidade única ou amando o desempenho de caches mistos, mas também dependendo da proximidade física das células da memória com os dados que estão sendo processados. Independentemente do tipo de cache que o programa exija por padrão ou hierarquia. O principal é minimizar o atraso do sinal e o consumo de energia. Dependendo de quantos tipos de memória o programa "gosta", o Jenga modela a latência de cada hierarquia virtual com um ou dois níveis. Hierarquias de dois níveis formam uma superfície, hierarquias de nível único formam uma curva. A Jenga projeta o atraso mínimo nos tamanhos VL1, o que fornece duas curvas. Por fim, o Jenga usa essas curvas para selecionar a melhor hierarquia (ou seja, tamanho do VL1).
O uso de Jenga deu um efeito tangível. O chip virtual de 36 núcleos era 30% mais rápido e usava 85% menos energia. É claro que, embora o Jenga seja apenas uma simulação de um computador em funcionamento, levará algum tempo até que você veja exemplos reais desse cache e até que os fabricantes de chips o aceitem se gostarem da tecnologia.
Configuração condicional de 36 máquinas nucleares
- Processadores . 36 núcleos, x86-64 ISA, 2,4 GHz, semelhante a Silvermont OOO: 8B de largura
ifetch; Bpred de dois níveis com BHSRs de 512 × 10 bits + PHT de 1024 × 2 bits, decodificação / emissão / renomeação / confirmação de duas vias, QI e ROB de 32 entradas, QI e ROB de 32 entradas, LQ de 10 entradas e SQ de 16 entradas; 371 pJ / instrução, 163 mW / potência estática do núcleo - Caches de nível L1 . Caches associativos a conjuntos de 8 KB, dados divididos e instruções de 32
Latência de 3 ciclos; 15/33 pJ por acerto / erro - Serviço de pré-busca de pré-buscadores . Pré-buscadores de fluxo de 16 entradas modelados e validados contra
Nehalem - Caches de nível L2 . 128 KB privados por núcleo, associativos a conjuntos de 8 vias, inclusive, latência de 6 ciclos; 46/93 pJ por golpe / falta
- Modo coerente (coerência) . Bancos de diretório de latência de 16 vias e 6 ciclos para Jenga; diretórios L3 em cache para outros
- NoC global . Malha 6 × 6, flits e links de 128 bits, roteamento XY, roteadores em pipeline de 2 ciclos, links de 1 ciclo; 63/71 pJ por roteador / link flit transversal, 12 / 4mW roteador / link de energia estática
- Blocos de memória estática SRAM . 18 MB, um banco de 512 KB por bloco, zcache de 52 candidatos e 4 vias, latência de banco de 9 ciclos, particionamento Vantage; 240/500 pJ por acerto / erro, 28 mW / potência estática do banco
- Memória dinâmica multicamada DRAM empilhada . 1152MB, um cofre de 128MB por 4 blocos, liga com MAP-I DDR3-3200 (1600 MHz), barramento de 128 bits, 16 fileiras, 8 bancos / classificação, buffer de linha de 2 KB; 4,4 / 6,2 nJ por acerto / erro, 88 mW / potência estática do cofre
- Memória principal . 4 canais DDR3-1600, barramento de 64 bits, 2 fileiras / canal, 8 bancos / classificação, buffer de linha de 8 KB; 20 nJ / acesso, potência estática de 4W
- DRAM . tCAS = 8, tRCD = 8, tRTP = 4, tRAS = 24, tRP = 8, tRRD = 4, tWTR = 4, tWR = 8, tFAW = 18 (todos os tempos em tCK; DRAM empilhada tem metade do tCK como memória principal )