 Os duplos digitais de políticos e atores famosos estão sob o controle total do "marionetista". Ilustração: Universidade de Washington, 2015
Os duplos digitais de políticos e atores famosos estão sob o controle total do "marionetista". Ilustração: Universidade de Washington, 2015Os programas gráficos 3D, juntamente com as redes neurais, atingiram uma qualidade tal que o vídeo falso é quase indistinguível do real. Em breve, não será possível afirmar com certeza que a pessoa na tela da TV é um verdadeiro político, não uma simulação de computador.
Em dezembro de 2015, cientistas da Universidade de Washington introduziram a
tecnologia dos "duplos digitais" : a criação de modelos 3D "ao vivo" a partir de centenas de fotografias de um personagem. Um enorme arquivo de fotos foi compilado para celebridades e políticos na Internet. O programa cria um modelo, e esse é como uma boneca em uma corda - pode ser controlado como você quiser, dar expressões faciais diferentes, fazer qualquer discurso com os lábios.
Agora, às vésperas da conferência de computação gráfica
SIGGRAPH 2017 , o mesmo grupo de pesquisadores publicou um novo
trabalho científico com uma versão avançada de "contrapartes digitais".
Agora, ao ensinar o programa, não apenas as fotografias são usadas, mas também os vídeos, para que o treinamento se torne muito mais eficaz. Para demonstrar a tecnologia, os cientistas escolheram um personagem famoso - o ex-presidente dos EUA Barack Obama. Essa é uma boa escolha, porque a Internet possui uma enorme quantidade de material de vídeo em HD. Milhões de quadros de vídeo estão disponíveis para o treinamento de uma rede neural.
A rede neural estudou em todos os detalhes as características das expressões faciais de Obama: movimentos dos lábios a cada som, aparência de rugas perto dos olhos, mudanças no formato das sobrancelhas e inclinação da cabeça. A expressão facial do personagem experimental estava associada aos sons que ele pronuncia: a rede neural processava não apenas os quadros dos vídeos, mas também as faixas de áudio para eles.
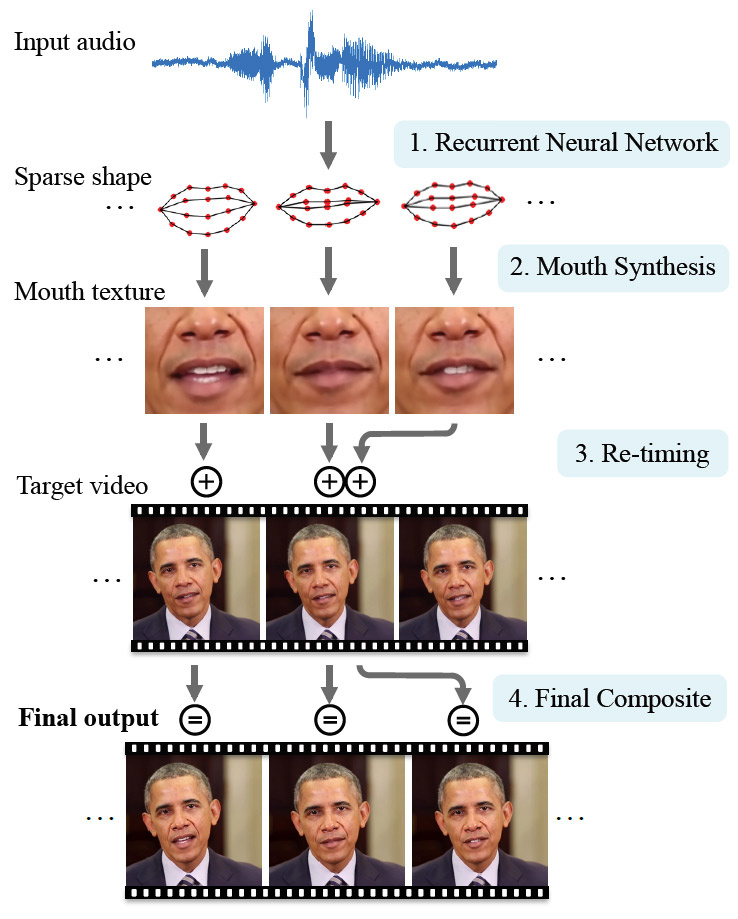
Assim, uma IA fraca aprendeu a sincronizar expressões faciais e movimentos labiais com qualquer discurso arbitrário que os pesquisadores alimentem com a entrada de uma rede neural.
Em um teaser para trabalhos científicos, são comparadas as gravações em vídeo da vida real dos discursos de Obama e o resultado sintetizado por uma rede neural.
Note-se que o resultado sintetizado difere acentuadamente do original, mas ainda parece muito realista.
Pesquisadores enfatizam que anteriormente, para obter "duplos digitais", as pessoas eram forçadas a repetir repetidamente as mesmas frases na frente das câmeras para gravar todas as combinações de morfemas e expressões faciais. Agora você pode fazer isso em vídeos publicamente disponíveis. É verdade que nem todas as pessoas na Internet têm material de vídeo suficiente para falsificar sua personalidade, mas com o tempo, os próprios usuários resolvem esse problema carregando gigabytes de suas fotos e vídeos nas redes sociais.
Do ponto de vista prático, essa tecnologia também pode ser usada. Por exemplo, Ira Kemelmacher-Shlizerman, uma das coautoras do trabalho científico,
diz que ela melhorará a qualidade da videoconferência sintetizando os quadros ausentes se eles caírem do fluxo de vídeo. Se o som ficar sem interferência e o vídeo ficar lento, essa síntese complementará a imagem ou aumentará sua resolução. Obviamente, a tecnologia pode encontrar aplicação em jogos de computador e realidade virtual se o jogador se comunicar com um personagem virtual. Agora, o discurso do personagem virtual se tornará mais realista e pode ser uma cópia digital de uma pessoa real. Por exemplo, você pode "reviver" uma figura histórica do passado recente apenas por suas gravações de áudio. Obviamente, a criação de falsificações para fins políticos será facilitada. Se agora eles
são moldados no “Photoshop” e lançados nas redes sociais , no futuro vídeos falsos serão mostrados na TV.
Os autores reconhecem que a tecnologia até agora não é perfeita. Por exemplo, se Obama desviar um pouco o rosto da câmera, partes da boca poderão se separar do rosto e se sobrepor ao fundo. Mas esses são pequenos erros que podem ser corrigidos com o treinamento adicional da rede neural.
Outra desvantagem do modelo criado é que ele não modela emoções. As expressões faciais são absolutamente neutras e quase sempre iguais. Assim, em alguns casos, o duplo digital perde seu realismo: sua expressão facial parece muito séria para as palavras frívolas que pronuncia. Ou vice-versa - muito frívolo para discursos muito sérios. No entanto, esses incidentes acontecem com políticos reais na vida real.

A tecnologia criada é semelhante, em princípio, ao trabalho em um
programa para a criação de duplas digitais do Face2Face , onde as expressões faciais e a fala de uma pessoa são transferidas para a face de outra. Em seu trabalho científico, autores de Washington comparam os resultados de sua rede neural com o Face2Face. Eles explicam que, no caso do Face2Face, sempre é necessário um fluxo de vídeo para simular, e seu modelo funciona apenas com gravação de som.