
No início do século XX, Wilhelm von Austin, um treinador de cavalos e matemático alemão, anunciou ao mundo que havia ensinado um cavalo a contar. Durante anos, von Austin viajou pela Alemanha com uma demonstração desse fenômeno. Ele pediu ao cavalo, apelidado de
Clever Hans (raça
Orlov trotter ), para calcular os resultados de equações simples. Hans respondeu, batendo no casco. Dois mais dois? Quatro hits.
Mas os cientistas não acreditavam que Hans fosse tão inteligente quanto von Austin afirmava. O psicólogo
Karl Stumpf conduziu uma investigação completa, apelidada de "Comitê Hans". Ele descobriu que o Smart Hans não resolve equações, mas responde a sinais visuais. Hans bateu no casco até obter a resposta correta, após o que seu treinador e uma multidão entusiasmada começaram a gritar. E então ele simplesmente parou. Quando ele não viu essas reações, ele continuou a bater.
A ciência da computação pode aprender muito com Hans. O ritmo acelerado de desenvolvimento nessa área sugere que a maior parte da IA que criamos foi treinada o suficiente para dar as respostas corretas, mas realmente não entende as informações. E é fácil de enganar.
Os algoritmos de aprendizado de máquina rapidamente se transformaram em pastores que tudo vêem do rebanho humano. O software nos conecta à Internet, monitora spam e conteúdo malicioso em nossos e-mails e, em breve, dirigirá nossos carros. O engano deles muda a base tectônica da Internet e ameaça nossa segurança no futuro.
Pequenos grupos de pesquisa - da Pennsylvania State University, do Google e das forças armadas dos EUA - estão desenvolvendo planos para se proteger contra possíveis ataques à IA. As teorias apresentadas no estudo dizem que um invasor pode mudar o que um robomóvel "vê". Ou ative o reconhecimento de voz no telefone e force-o a entrar em um site malicioso usando sons que serão apenas ruído para uma pessoa. Ou deixe o vírus vazar pelo firewall da rede.
 À esquerda, a imagem do edifício, à direita, a imagem modificada, que a rede neural profunda relaciona aos avestruzes. No meio, todas as alterações aplicadas à imagem principal são mostradas.
À esquerda, a imagem do edifício, à direita, a imagem modificada, que a rede neural profunda relaciona aos avestruzes. No meio, todas as alterações aplicadas à imagem principal são mostradas.Em vez de assumir o controle de um robomóvel, esse método mostra a ele algo como uma alucinação - uma imagem que realmente não existe.
Esses ataques usam imagens com um truque [exemplos contraditórios - não existe um termo russo estabelecido; literalmente, algo como “exemplos com contraste” ou “exemplos rivais” - aprox. transl.]: imagens, sons, texto que parecem normais para as pessoas, mas são percebidos por uma máquina completamente diferente. As pequenas mudanças feitas pelos atacantes podem fazer com que a profunda rede neural tire conclusões erradas sobre o que mostra.
"Qualquer sistema que use o aprendizado de máquina para tomar decisões críticas de segurança é potencialmente vulnerável a esse tipo de ataque", disse Alex Kanchelyan, pesquisador da Universidade de Berkeley que estuda ataques de aprendizado de máquina usando imagens falsificadas.
Conhecer essas nuances nos estágios iniciais do desenvolvimento da IA fornece aos pesquisadores uma ferramenta para entender como corrigir essas deficiências. Alguns já aceitaram isso e dizem que seus algoritmos se tornaram cada vez mais eficientes por causa disso.
A maior parte do fluxo principal de pesquisa em IA é baseada em redes neurais profundas, que por sua vez se baseiam em um campo mais amplo de aprendizado de máquina. As tecnologias MoD usam cálculos e estatísticas diferenciais e integrais para criar software usado pela maioria de nós, como filtros de spam no correio ou pesquisar na Internet. Nos últimos 20 anos, os pesquisadores começaram a aplicar essas técnicas a uma nova idéia, redes neurais - estruturas de software que imitam a função cerebral. A idéia é descentralizar os cálculos em milhares de pequenas equações ("neurônios") que recebem dados, processam e os transmitem ainda mais, para a próxima camada de milhares de pequenas equações.
Esses algoritmos de IA são treinados da mesma maneira que no caso do MO, que, por sua vez, copia o processo de aprendizado de uma pessoa. São mostrados exemplos de coisas diferentes e suas tags associadas. Mostre ao computador (ou criança) a imagem de um gato, diga que ele se parece com isso e o algoritmo aprenderá a reconhecer gatos. Mas para isso, o computador terá que visualizar milhares e milhões de imagens de gatos e gatos.
Os pesquisadores descobriram que esses sistemas podem ser atacados com dados enganosos especialmente selecionados, que eles chamam de "exemplos contraditórios".
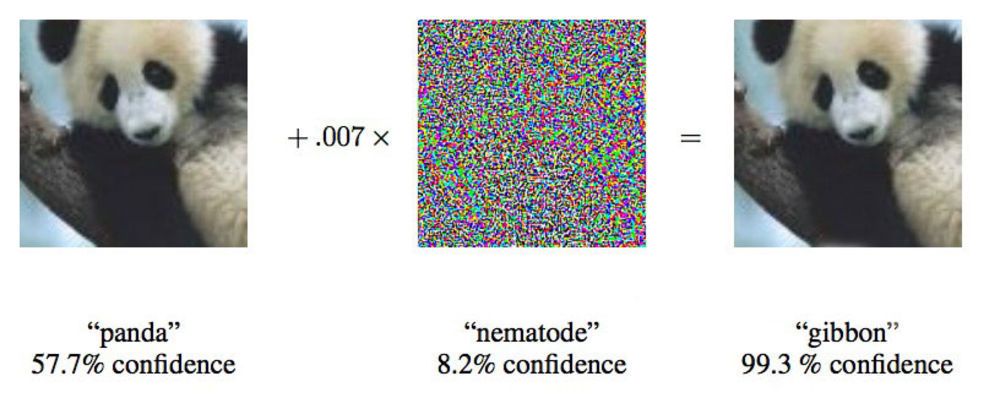 Em um artigo de 2015, pesquisadores do Google mostraram que redes neurais profundas podem ser forçadas a atribuir essa imagem de um panda aos gibões.
Em um artigo de 2015, pesquisadores do Google mostraram que redes neurais profundas podem ser forçadas a atribuir essa imagem de um panda aos gibões."Mostramos uma foto que mostra claramente o ônibus escolar e faz com que você pense que é um avestruz", disse Ian Goodfellow, pesquisador do Google que está trabalhando ativamente nesses ataques em redes neurais.
Alterando as imagens fornecidas às redes neurais em apenas 4%, os pesquisadores foram capazes de induzi-las a cometer erros com a classificação em 97% dos casos. Mesmo que não soubessem exatamente como a rede neural processa imagens, eles poderiam enganá-la em 85% dos casos.
A última variante de fraude sem dados na arquitetura de rede é chamada de "ataque de caixa preta". Este é o primeiro caso documentado de um ataque funcional desse tipo em uma rede neural profunda, e sua importância é que aproximadamente nesse cenário possam ocorrer ataques no mundo real.
No estudo, pesquisadores da Pennsylvania State University, Google e US Navy Research Laboratory atacaram uma rede neural que classifica imagens suportadas pelo projeto MetaMind e serve como uma ferramenta online para desenvolvedores. A equipe construiu e treinou a rede atacada, mas seu algoritmo de ataque funcionou independentemente da arquitetura. Com esse algoritmo, eles conseguiram enganar a rede neural da caixa preta com uma precisão de 84,24%.
 A linha superior de fotos e caracteres - correto reconhecimento de caracteres.
A linha superior de fotos e caracteres - correto reconhecimento de caracteres.
Linha inferior - a rede foi forçada a reconhecer sinais completamente errados.Fornecer dados imprecisos às máquinas não é uma idéia nova, mas Doug Tygar, professor da Universidade de Berkeley, que estuda aprendizado de máquina há 10 anos, diz que essa tecnologia de ataque evoluiu de um MO simples para redes neurais profundas complexas. Os hackers maliciosos usam essa técnica em filtros de spam há anos.
A pesquisa de Tiger vem de
seu trabalho de 2006 sobre ataques desse tipo em uma rede com o Ministério da Defesa, que ele
expandiu em 2011 com a ajuda de pesquisadores da Universidade da Califórnia em Berkeley e da Microsoft Research. A equipe do Google, a primeira a usar redes neurais profundas, publicou seu
primeiro trabalho em 2014, dois anos depois de descobrir a possibilidade de tais ataques. Eles queriam ter certeza de que isso não era algum tipo de anomalia, mas uma possibilidade real. Em 2015, eles publicaram outro
trabalho no qual descreveram uma maneira de proteger redes e aumentar sua eficiência, e Ian Goodfellow desde então deu conselhos sobre outros trabalhos científicos nessa área, incluindo
o ataque da caixa preta .
Os pesquisadores chamam a idéia mais geral de informação não confiável de "dados bizantinos" e, graças ao progresso da pesquisa, chegaram ao aprendizado profundo. O termo vem da bem conhecida "
tarefa dos generais bizantinos "
, um experimento mental no campo da ciência da computação, no qual um grupo de generais deve coordenar suas ações com a ajuda de mensageiros, sem ter a confiança de que um deles é um traidor. Eles não podem confiar nas informações recebidas de seus colegas.
"Esses algoritmos são projetados para lidar com ruídos aleatórios, mas não com dados bizantinos", diz Taigar. Para entender como esses ataques funcionam, Goodfello sugere imaginar uma rede neural na forma de um diagrama de dispersão.
Cada ponto do diagrama representa um pixel da imagem processada pela rede neural. Normalmente, a rede tenta traçar uma linha através dos dados que melhor se ajustam ao conjunto de todos os pontos. Na prática, isso é um pouco mais complicado, porque pixels diferentes têm valores diferentes para a rede. Na realidade, este é um gráfico multidimensional complexo processado por um computador.
Mas, em nossa simples analogia de um gráfico de dispersão, o formato da linha traçada através dos dados determina o que a rede pensa que vê. Para um ataque bem-sucedido a esses sistemas, os pesquisadores precisam alterar apenas uma pequena parte desses pontos e fazer com que a rede tome uma decisão que realmente não existe. No exemplo de um ônibus que se parece com um avestruz, a foto do ônibus escolar é pontilhada com pixels organizados de acordo com o padrão associado às características exclusivas das fotos de avestruz familiares à rede. Esse é um contorno invisível para os olhos, mas quando o algoritmo
processa e simplifica os dados , os pontos extremos de dados para o avestruz lhe parecem uma opção de classificação adequada. Na versão da caixa preta, os pesquisadores testaram o trabalho com diferentes dados de entrada para determinar como o algoritmo vê certos objetos.
Ao fornecer ao classificador de objetos dados falsos e ao estudar as decisões tomadas pela máquina, os pesquisadores conseguiram restaurar o algoritmo para enganar o sistema de reconhecimento de imagens. Potencialmente, um sistema desse tipo em robomobiles, neste caso, pode ver o sinal de "ceder" em vez do sinal de parada. Quando eles entenderam como a rede funcionava, conseguiram fazer a máquina ver qualquer coisa.
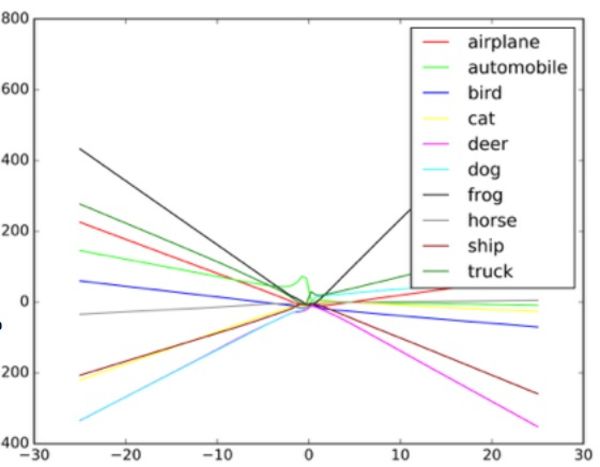 Um exemplo de como o classificador de imagem desenha linhas diferentes, dependendo dos diferentes objetos na imagem. Exemplos falsos podem ser considerados valores extremos no gráfico.
Um exemplo de como o classificador de imagem desenha linhas diferentes, dependendo dos diferentes objetos na imagem. Exemplos falsos podem ser considerados valores extremos no gráfico.Os pesquisadores dizem que esse ataque pode ser inserido diretamente no sistema de processamento de imagem, contornando a câmera, ou essas manipulações podem ser realizadas com um sinal real.
Mas a especialista em segurança da Universidade Columbia, Alison Bishop, disse que essa previsão não é realista e depende do sistema usado no robomóvel. Se os invasores já tiverem acesso ao fluxo de dados da câmera, eles já poderão fornecer qualquer entrada.
"Se eles conseguem chegar à entrada da câmera, essas dificuldades não são necessárias", diz ela. "Você pode apenas mostrar a ela o sinal de parada."
Outros métodos de ataque, além de contornar a câmera - por exemplo, desenhando marcas visuais em um sinal real, parecem improváveis a Bishop. Ela duvida que as câmeras de baixa resolução usadas nos robomobiles geralmente consigam distinguir entre pequenas mudanças no sinal.
 A imagem primitiva à esquerda é classificada como um ônibus escolar. Corrigido à direita - como um avestruz. No meio - a imagem muda.
A imagem primitiva à esquerda é classificada como um ônibus escolar. Corrigido à direita - como um avestruz. No meio - a imagem muda.Dois grupos, um na Universidade de Berkeley e outro na Universidade de Georgetown, desenvolveram algoritmos que podem emitir comandos de fala para assistentes digitais como Siri e Google Now, que soam como um ruído inaudível. Para uma pessoa, esses comandos parecerão ruído aleatório, mas, ao mesmo tempo, podem dar comandos para dispositivos como Alexa, não previstos pelo proprietário.
Nicholas Carlini, um dos pesquisadores em ataques de áudio bizantinos, diz que em seus testes eles foram capazes de ativar programas de reconhecimento de áudio de código aberto, Siri e Google Now, com uma precisão de mais de 90%.
O barulho é como algum tipo de negociação alienígena de ficção científica. Isso é uma mistura de ruído branco e voz humana, mas não é como um comando de voz.
De acordo com Carlini, em um ataque como esse, qualquer pessoa que ouvir um ruído do telefone (embora seja necessário planejar ataques no iOS e Android separadamente) pode ser forçada a ir para uma página da web que também reproduz ruído, que infectará os telefones localizados nas proximidades. Ou esta página pode fazer o download silencioso de um programa de malware. Também é possível que esses ruídos percam no rádio e ocultem ruídos brancos ou em paralelo com outras informações de áudio.
Esses ataques podem ocorrer porque a máquina é treinada para garantir que quase todos os dados contenham dados importantes, e que uma coisa seja mais comum que a outra, conforme explicado por Goodfello.
Enganar a rede, forçando-a a acreditar que vê um objeto comum, é mais fácil, porque acredita que deveria ver esses objetos com mais frequência. Portanto, Goodfellow e outro grupo da Universidade de Wyoming conseguiram que a rede classificasse imagens que não existiam - identificou objetos com ruído branco, criou pixels preto e branco aleatoriamente.
Em um estudo da Goodfellow, o ruído branco aleatório que passava por uma rede foi classificado por ela como um cavalo. Coincidentemente, isso nos leva de volta à história de Clever Hans, um cavalo não muito matematicamente dotado.
Goodfellow diz que redes neurais, como Smart Hans, na verdade não aprendem nenhuma idéia, mas apenas aprendem a descobrir quando encontram a idéia certa. A diferença é pequena, mas importante. A falta de conhecimento fundamental facilita as tentativas maliciosas de recriar a aparência de encontrar os resultados "certos" do algoritmo, que de fato se mostram falsos. Para entender o que é algo, uma máquina também deve entender o que não é.
Goodfello, tendo treinado a rede classificando imagens tanto em imagens naturais quanto em imagens (falsas) processadas, descobriu que ele não apenas podia reduzir a eficácia de tais ataques em 90%, mas também fazia a rede lidar melhor com a tarefa inicial.
"Ao tornar possível explicar imagens falsas realmente incomuns, você pode obter uma explicação ainda mais confiável dos conceitos subjacentes", diz Goodfellow.
Dois grupos de pesquisadores de áudio usaram uma abordagem semelhante à da equipe do Google, protegendo suas redes neurais de seus próprios ataques por overtraining. Eles também alcançaram sucessos semelhantes, reduzindo sua eficiência de ataque em mais de 90%.
Não é de surpreender que esta área de pesquisa tenha interessado as forças armadas dos EUA. O Laboratório de Pesquisa do Exército até patrocinou dois dos mais recentes trabalhos sobre esse assunto, incluindo o ataque da caixa preta. E embora a agência esteja financiando pesquisas, isso não significa que a tecnologia será usada na guerra. Segundo o representante do departamento, até 10 anos podem passar da pesquisa para tecnologias adequadas ao uso de um soldado.
Ananthram Swami, pesquisador do Laboratório do Exército dos EUA, esteve envolvido em vários trabalhos recentes que tratam do engano da IA. O exército está interessado na questão de detectar e interromper dados fraudulentos em nosso mundo, onde nem todas as fontes de informação podem ser cuidadosamente verificadas. Swami aponta para um conjunto de dados obtidos de sensores públicos localizados em universidades e trabalhando em projetos de código aberto.
“Nem sempre controlamos todos os dados. É muito fácil para o nosso adversário nos enganar ”, diz Swami. "Em alguns casos, as consequências de tal fraude podem ser frívolas, em alguns casos, o oposto."
Ele também diz que o exército está interessado em robôs, tanques e outros veículos autônomos, de modo que o objetivo dessa pesquisa é óbvio. Ao estudar essas questões, o exército poderá ganhar uma vantagem no desenvolvimento de sistemas que não são suscetíveis a ataques desse tipo.
Mas qualquer grupo que use uma rede neural deve se preocupar com o potencial de ataques com falsificação de IA. O aprendizado de máquina e a IA estão em sua infância, e as falhas de segurança podem ter conseqüências terríveis no momento. Muitas empresas confiam informações altamente confidenciais a sistemas de IA que não passaram no teste do tempo. Nossas redes neurais ainda são jovens demais para sabermos tudo o que precisamos sobre elas.
Uma supervisão semelhante levou
o bot da Microsoft no Twitter, Tay , a se tornar rapidamente um racista com uma propensão ao genocídio. O fluxo de dados maliciosos e a função "repetir depois de mim" levaram ao fato de que Tay se desviou bastante do caminho pretendido. O bot foi enganado por informações precárias, e isso serve como um exemplo conveniente de uma má implementação do aprendizado de máquina.
Kanchelyan diz que não acredita que as possibilidades de tais ataques tenham se esgotado após uma pesquisa bem-sucedida da equipe do Google.
"Na área de segurança de computadores, os atacantes estão sempre à nossa frente", diz Kanchelyan. "Será bastante perigoso afirmar que resolvemos todos os problemas com o engano das redes neurais por meio de seu treinamento repetido".