O Network Security Services (
NSS ) é um conjunto de bibliotecas usadas no desenvolvimento de plataforma cruzada de aplicativos seguros para clientes e servidores.
O pacote NSS, como o OpenSSL, oferece a capacidade de usar utilitários de linha de comando para implementar várias funções de PKI (geração de chaves, emissão de certificados x509v3, trabalho com assinaturas eletrônicas, suporte a TLS etc.). Um desses utilitários, o Pretty-print (PP), permite visualizar convenientemente o conteúdo do certificado x509 v3 e da assinatura eletrônica (pkcs # 7), etc. Além disso, o certificado pode estar nas codificações DER e PEM:
bash-4.3$ pp -h Usage: pp [-t type] [-a] [-i input] [-o output] [-w] [-u] Pretty prints a file containing ASN.1 data in DER or ascii format. -t type Specify input and display type: public-key (pk), certificate (c), certificate-request (cr), certificate-identity (ci), pkcs7 (p7), crl or name (n). (Use either the long type name or the shortcut.) -a Input is in ascii encoded form (RFC1113) -i input Define an input file to use (default is stdin) -o output Define an output file to use (default is stdout) -w Don't wrap long output lines -u Use UTF-8 (default is to show non-ascii as .) bash-4.3$
Além disso, a presença do parâmetro –u (codificação UTF-8) permite visualizar o certificado na codificação russa. Mas,
observando cuidadosamente as capturas de tela da GUI para os utilitários de linha de comando do pacote NSS, você percebe que alguns dos dados do certificado simplesmente desapareceram:
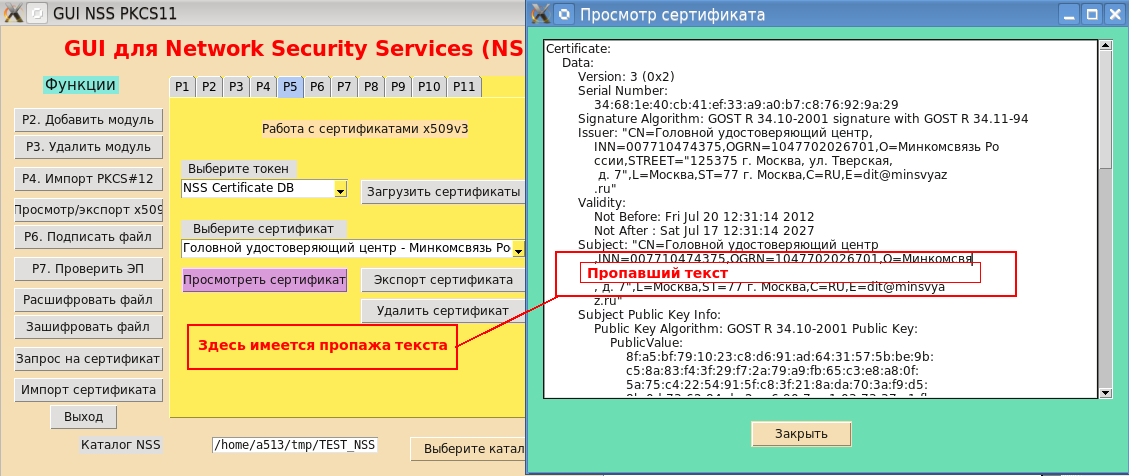
A busca pelas informações ausentes começou. O utilitário "cute print" (que é como o Pretty-print é traduzido) para exibir o certificado raiz da CA principal do Ministério das Comunicações foi lançado na linha de comando:
$pp – certificate –u –i _.cer … Subject: "CN= ,INN=007710474375,OGRN=1047702026701,O= ,STREET="125375 . , . , . 7",L=,ST=77 . ,C=RU,E=dit@minsvya z.ru" …. $
O resultado confirmou a perda de dados. Além disso, dois símbolos não mostráveis apareceram na tela (um losango de cor preta com um ponto de interrogação? No interior). A análise mostrou que esses caracteres não exibidos têm os códigos 0xD0 e 0xBE, respectivamente:
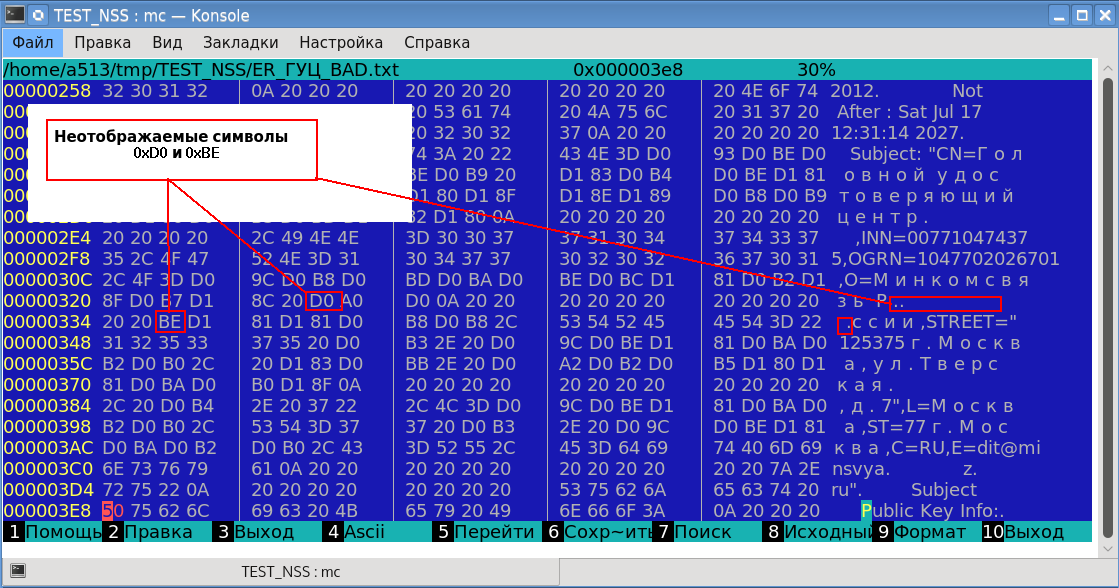
A letra russa “o” desapareceu com uma representação hexadecimal na codificação UTF-8 como 0xD00xBE. E os códigos 0xD0 e 0xBE são nossos caracteres não exibidos. E que tipo de caracteres apareceu entre esses bytes? E esta é uma impressão “bonita” - símbolos de alinhamento do texto impresso.
O que aconteceu? A entrada de uma impressão "boa" (arquivo /nss/cmd/lib/secutil.c, função secu_PrintRawStringQuotesOptional) recebe dados na forma de SECITEM, ou seja, endereços por matriz de bytes e seu comprimento:
for (i = 0; i < si->len; i++) { unsigned char val = si->data[i]; unsigned char c; if (SECU_GetWrapEnabled() && column > 76) { SECU_Newline(out); SECU_Indent(out, level); column = level * INDENT_MULT; } if (utf8DisplayEnabled) { if (val < 32) c = '.'; else c = val; } else { c = printable[val]; } fprintf(out, "%c", c); column++; }
E se (SECU_GetWrapEnabled () == True) for fornecido para uma boa impressão (o utilitário PP não possui parâmetro -w) e o número de bytes em uma linha exceder 76 (coluna> 76), depois do próximo caractere uma nova linha (SECU_Newline) e os recuos necessários (SECU_Indent ) Ao mesmo tempo, nenhum dos desenvolvedores pensou que, se a codificação UTF-8 for usada (utf8DisplayEnabled), a beleza poderá ser induzida somente após o próximo caractere, e não o byte, pois o conceito de byte e caractere na codificação UTF-8 pode não coincidir . Se falamos de letras russas, cada uma delas
é codificada em dois bytes. Apenas essa lacuna ocorreu com a letra russa “o” (0xD00xBE).
Qual é a saída? Tudo é bastante simples na função secu_PrintRawStringQuotesOptional para substituir a linha:
if (SECU_GetWrapEnabled() && column > 76) {
em uma linha do seguinte formulário:
if (SECU_GetWrapEnabled() && column > 76 && (val <= 0x7F || val == 0xD0 || val == 0xD1)) {
Se você agora reconstruir o utilitário PP e instalá-lo no sistema, a impressão "legal" justificará seu nome para o "idioma russo excelente, poderoso, verdadeiro e gratuito!" (I.S. Turgenev):
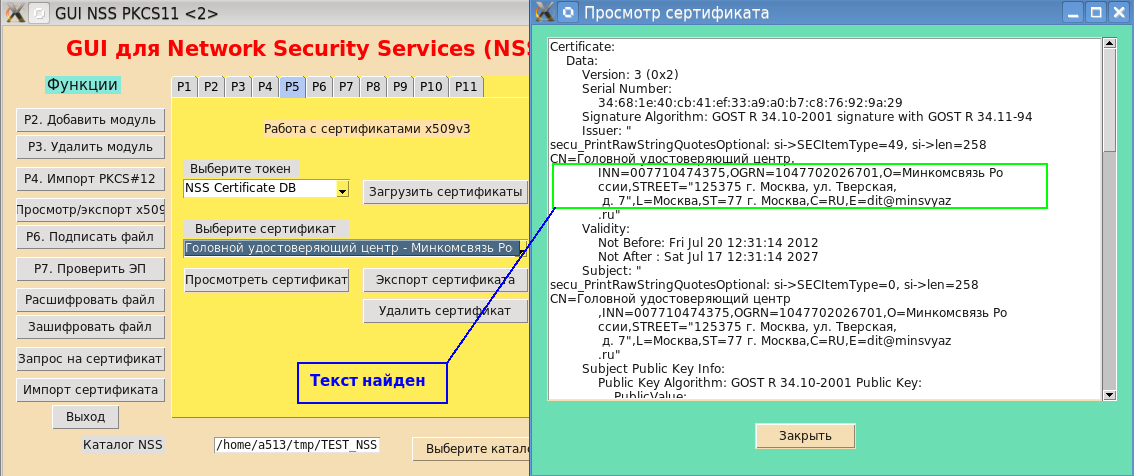
Se falarmos sobre a beleza da impressão, seria possível adicionar hifenização não apenas pelo número de caracteres na linha, mas mais correto, por exemplo, pelo espaço, vírgula, dois pontos e outros caracteres. Não estou falando da análise semântica da transferência. Mas essa já é uma área de inteligência artificial.
E, finalmente, esta é a segunda imprecisão descoberta nos utilitários do NSS. O primeiro foi descoberto no utilitário
oidcalc .