A tradução automática com a ajuda de redes neurais
percorreu um longo caminho desde o momento da primeira pesquisa científica sobre esse assunto até o momento em que o Google anunciou a
transferência completa do serviço Google Translate para o aprendizado profundo .
Como você sabe, a base do tradutor neural é o mecanismo de Redes Neurais Recorrentes Bidirecionais, construído com base em cálculos matriciais, o que permite criar modelos probabilísticos significativamente mais complexos que os tradutores de máquina estatísticos. No entanto, sempre se acreditou que a tradução neural, como a tradução estatística, requer textos bilíngues paralelos para treinamento. Uma rede neural está sendo treinada nesses prédios, tendo uma tradução humana como referência.
Como se viu agora, as redes neurais são capazes de dominar um novo idioma para tradução, mesmo sem corpus paralelo de textos!
Dois trabalhos sobre esse assunto foram publicados no site de pré-impressão arXiv.org.
“Imagine que você está dando a uma pessoa muitos livros chineses e muitos livros árabes - não há livros idênticos entre eles - e essa pessoa está aprendendo a traduzir do chinês para o árabe. Parece impossível, certo? Mas mostramos que um computador é capaz disso ”,
diz Mikel Artetxe, cientista da computação da Universidade do País Basco, em San Sebastian (Espanha).
A maioria das redes neurais de tradução automática é ensinada “com um professor”, cujo papel é precisamente o corpus paralelo de textos traduzidos pelo homem. No processo de aprendizagem, grosso modo, a rede neural faz uma suposição, verifica o padrão e faz as configurações necessárias em seus sistemas, e depois aprende mais. O problema é que, para alguns idiomas do mundo, não há um grande número de textos paralelos; portanto, eles não estão disponíveis para redes neurais de tradução automática tradicional.
Dois novos modelos oferecem uma nova abordagem: ensinar uma rede neural de tradução automática
sem professor . O próprio sistema está tentando criar uma espécie de corpus paralelo de textos, agrupando palavras entre si. O fato é que na maioria das línguas do mundo existem os mesmos significados, que simplesmente correspondem a palavras diferentes. Portanto, todos esses significados são agrupados em grupos idênticos, ou seja, os mesmos significados de palavras são agrupados em torno dos mesmos significados de palavras, quase independentemente do idioma (consulte o artigo “
Rede Neural do Google Tradutor compilou uma base unificada dos significados das palavras humanas ”) .
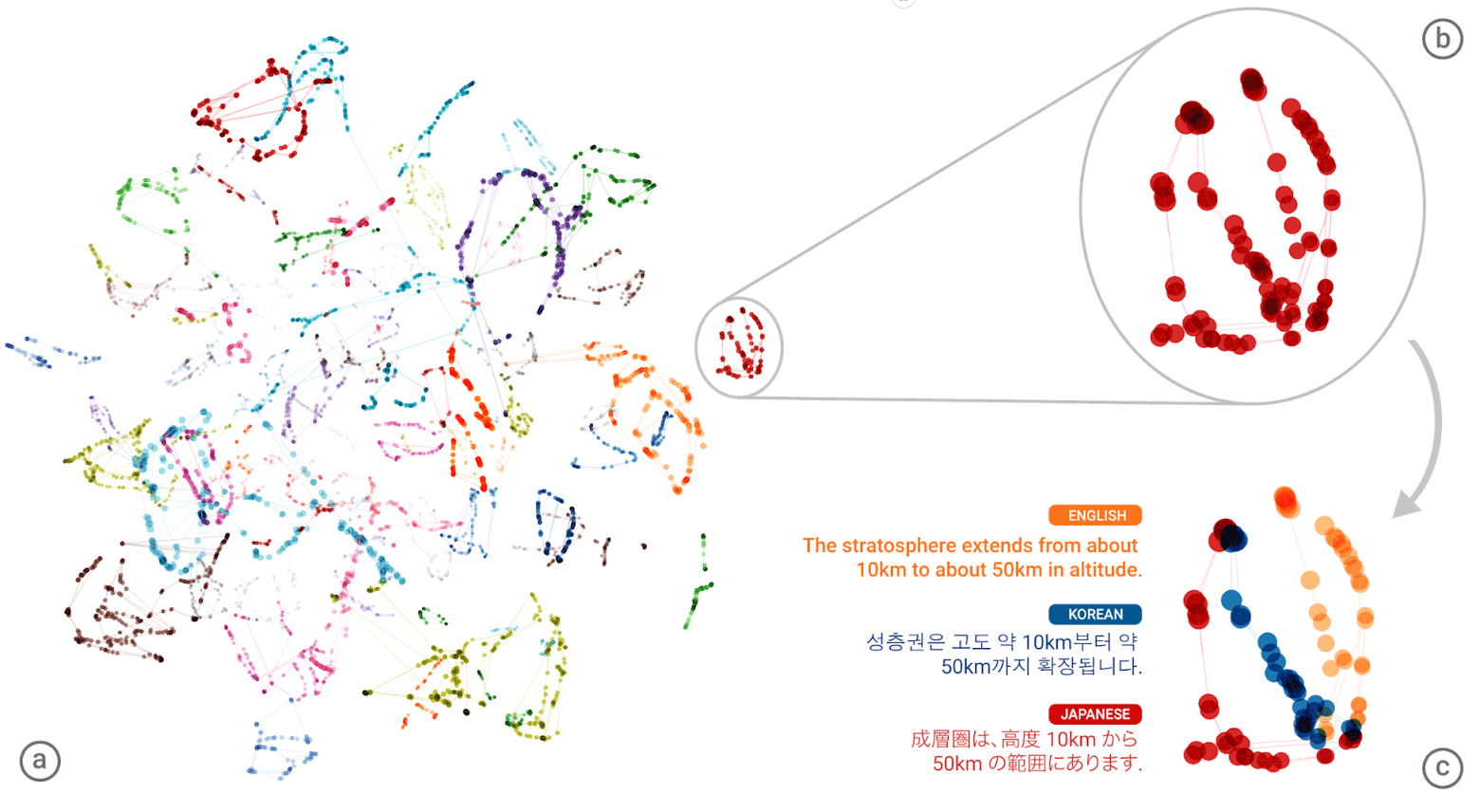 A "linguagem universal" da rede neural da Tradução Automática Neural do Google (GNMT). Os agrupamentos de significados de cada palavra são mostrados em cores diferentes na ilustração à esquerda; os significados mais baixos são os significados de palavras obtidos para ele em diferentes idiomas humanos: inglês, coreano e japonês.
A "linguagem universal" da rede neural da Tradução Automática Neural do Google (GNMT). Os agrupamentos de significados de cada palavra são mostrados em cores diferentes na ilustração à esquerda; os significados mais baixos são os significados de palavras obtidos para ele em diferentes idiomas humanos: inglês, coreano e japonês.Depois de compilar um atlas gigante para cada idioma, o sistema tenta sobrepor um desses atlas em outro - e aqui está você, você está pronto para ter algum tipo de corpus de texto paralelo!
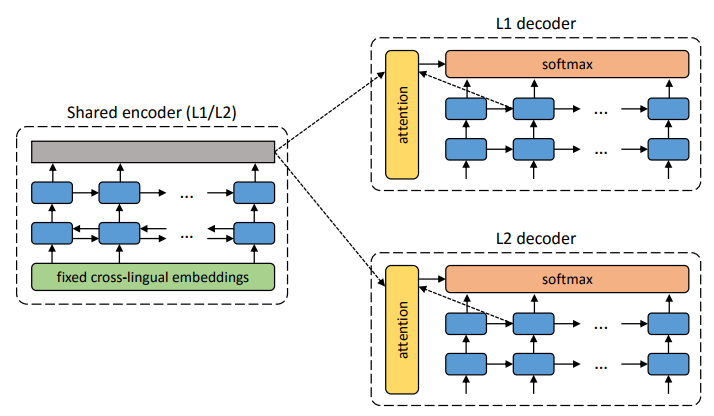
Você pode comparar os padrões das duas arquiteturas de aprendizagem sem professor propostas.
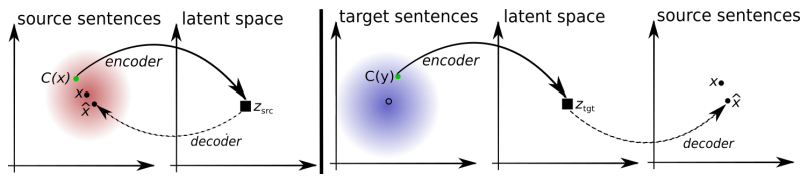
 A arquitetura do sistema proposto. Para cada sentença no idioma L1, o sistema aprende a alternância de duas etapas: 1) denoising , que otimiza a probabilidade de codificar uma versão barulhenta da sentença com um codificador comum e sua reconstrução pelo decodificador L1; 2) retrotradução, quando uma frase é traduzida no modo de saída (ou seja, codificada por um codificador comum e decodificado pelo decodificador L2) e, em seguida, a probabilidade de codificar essa frase traduzida com um codificador comum e a restauração da frase original pelo decodificador L1 é otimizada. Ilustração: artigo científico de Mikel Artetks et al.
A arquitetura do sistema proposto. Para cada sentença no idioma L1, o sistema aprende a alternância de duas etapas: 1) denoising , que otimiza a probabilidade de codificar uma versão barulhenta da sentença com um codificador comum e sua reconstrução pelo decodificador L1; 2) retrotradução, quando uma frase é traduzida no modo de saída (ou seja, codificada por um codificador comum e decodificado pelo decodificador L2) e, em seguida, a probabilidade de codificar essa frase traduzida com um codificador comum e a restauração da frase original pelo decodificador L1 é otimizada. Ilustração: artigo científico de Mikel Artetks et al.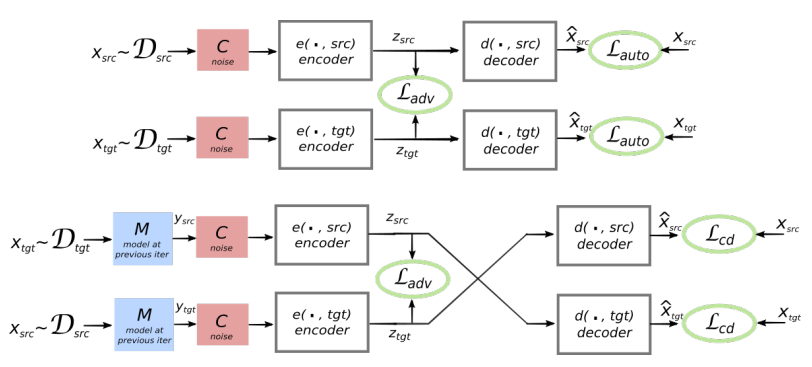 A arquitetura proposta e os objetivos de aprendizagem do sistema (a partir do segundo trabalho científico). A arquitetura é um modelo de tradução de frases, em que o codificador e o decodificador trabalham em dois idiomas, dependendo do identificador do idioma de entrada, que troca as tabelas de pesquisa. Acima (codificação automática): o modelo está aprendendo a executar a redução de ruído em cada domínio. Abaixo (tradução): como antes, mais codificamos a partir de outro idioma, usando como entrada a tradução produzida pelo modelo na iteração anterior (retângulo azul). Elipses verdes indicam termos na função de perda. Ilustração: artigo científico de Guillaume Lampl et al.
A arquitetura proposta e os objetivos de aprendizagem do sistema (a partir do segundo trabalho científico). A arquitetura é um modelo de tradução de frases, em que o codificador e o decodificador trabalham em dois idiomas, dependendo do identificador do idioma de entrada, que troca as tabelas de pesquisa. Acima (codificação automática): o modelo está aprendendo a executar a redução de ruído em cada domínio. Abaixo (tradução): como antes, mais codificamos a partir de outro idioma, usando como entrada a tradução produzida pelo modelo na iteração anterior (retângulo azul). Elipses verdes indicam termos na função de perda. Ilustração: artigo científico de Guillaume Lampl et al.Ambos os trabalhos científicos usam uma técnica visivelmente semelhante, com pequenas diferenças. Mas em ambos os casos, a tradução é realizada através de uma “linguagem” intermediária ou, melhor, de uma dimensão ou espaço intermediário. Até agora, as redes neurais sem professor mostram uma qualidade de tradução não muito alta, mas os autores dizem que é fácil melhorar se você usar uma pequena ajuda de um professor, agora apenas por uma questão de pureza do experimento que eles não fizeram.
Observe que o segundo trabalho científico foi publicado por pesquisadores da divisão de IA do Facebook.
Os trabalhos são apresentados para a Conferência Internacional sobre Representações de Aprendizagem 2018. Nenhum dos artigos foi publicado ainda na imprensa científica.