
Em maio de 2017, os pesquisadores do Google Brain introduziram o projeto
AutoML , que automatiza o design de modelos de aprendizado de máquina. As experiências do AutoML mostraram que esse sistema pode gerar pequenas redes neurais com desempenho muito bom - bastante comparável às redes neurais projetadas e treinadas por especialistas humanos. No entanto, no início, o AutoML estava limitado a pequenos conjuntos de dados científicos como o CIFAR-10 e o Penn Treebank.
Os engenheiros do Google se perguntaram - e se colocarmos tarefas mais sérias para o gerador de IA? Esse sistema de IA é capaz de gerar outra IA que será melhor que a IA fabricada pelo homem em alguma tarefa importante, como classificar objetos do
ImageNet - o mais famoso dos conjuntos de dados em larga escala na visão de máquina? Portanto, havia uma rede neural da
NASNet , criada quase sem intervenção humana.
Como se viu, a IA lida com o design e o treinamento de redes neurais não piores que os humanos. A tarefa de classificar objetos do conjunto de dados ImageNet e definir objetos do conjunto de dados
COCO fazia parte do projeto
Aprendendo Arquiteturas Transferíveis para Reconhecimento de Imagem Escalável .
Os desenvolvedores do projeto AutoML
dizem que a tarefa acabou não sendo trivial, porque os novos conjuntos de dados são várias ordens de magnitude maiores que as anteriores com as quais o sistema está acostumado. Eu tive que mudar alguns algoritmos de operação do AutoML, incluindo redesenhar o espaço de pesquisa para que o AutoML pudesse encontrar a melhor camada e duplicá-la várias vezes antes de criar a versão final da rede neural. Além disso, os desenvolvedores exploraram opções para a arquitetura de redes neurais para o CIFAR-10 - e transferiram manualmente a arquitetura de maior sucesso para as tarefas ImageNet e COCO.
Graças a essas manipulações, o sistema AutoML foi capaz de detectar as camadas mais eficientes da rede neural, que funcionaram bem no CIFAR-10 e, ao mesmo tempo, provaram ser boas nas tarefas ImageNet e COCO. Essas duas camadas descobertas foram combinadas para formar uma arquitetura inovadora chamada NASNet.
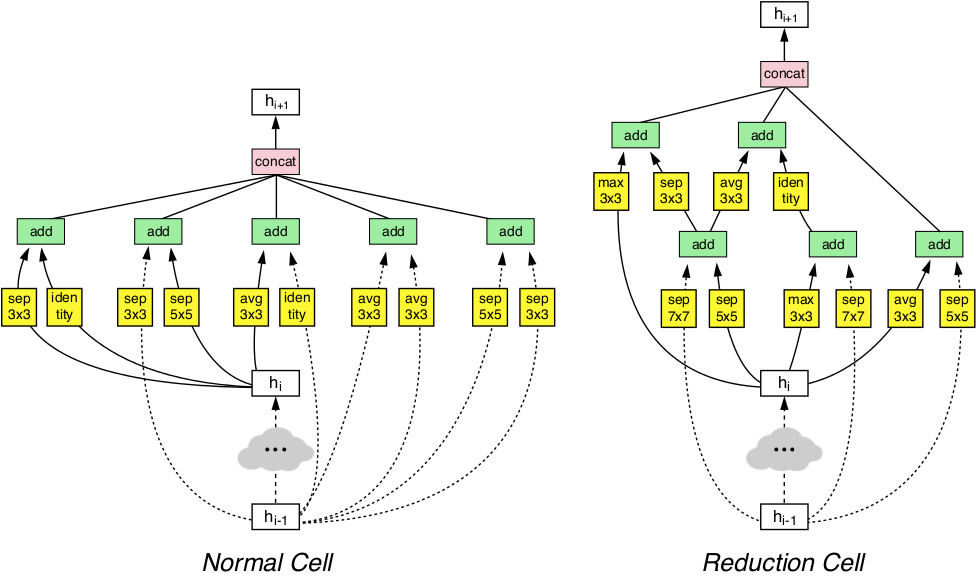 A arquitetura NASNet consiste em dois tipos de camadas: uma camada normal (esquerda) e uma camada de redução (direita). Essas duas camadas são projetadas por um gerador AutoML.
A arquitetura NASNet consiste em dois tipos de camadas: uma camada normal (esquerda) e uma camada de redução (direita). Essas duas camadas são projetadas por um gerador AutoML.Os benchmarks mostraram que a IA gerada automaticamente supera todos os outros sistemas de visão de máquina criados e treinados por especialistas humanos na classificação e definição de objetos.
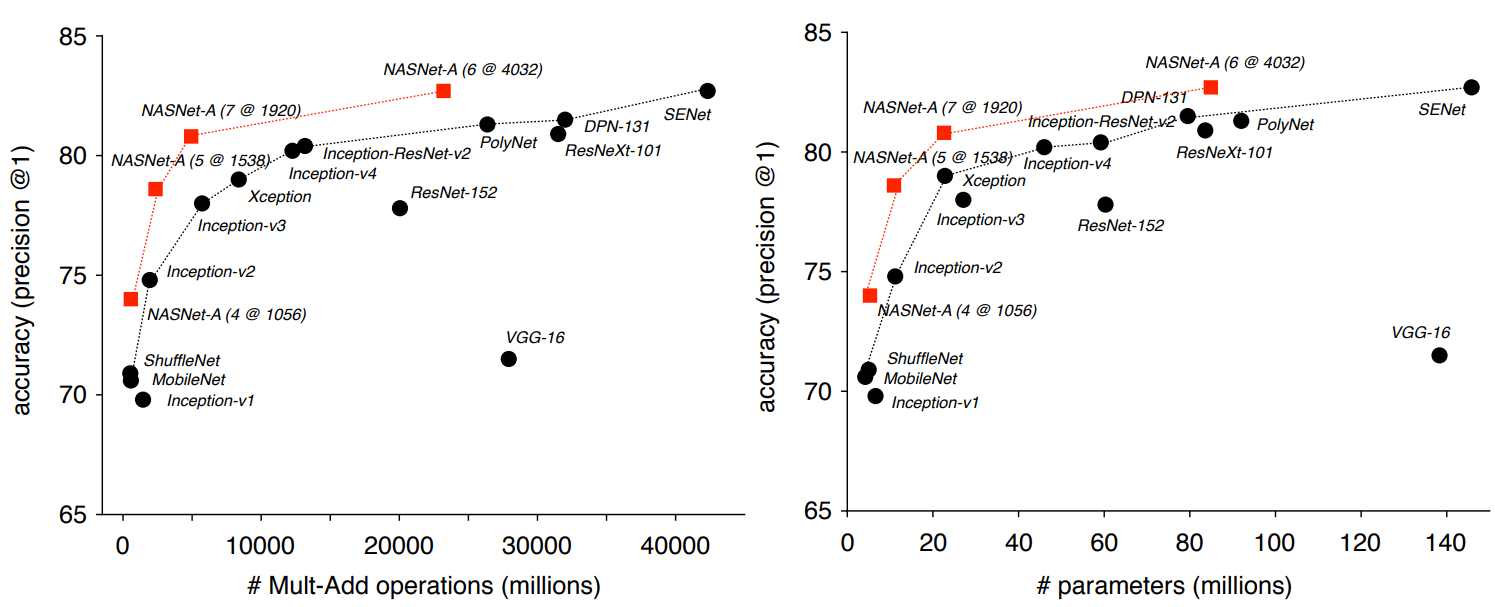
Portanto, na tarefa de classificação baseada no ImageNet, a rede neural da NASNet demonstrou uma precisão de previsão de 82,7% no conjunto de testes. Esse resultado é superior a todos os modelos de visão de máquina projetados anteriormente da família Inception. O sistema NASNet mostrou um resultado de pelo menos 1,2 pontos percentuais mais alto que todas as redes neurais de visão de máquina conhecidas, incluindo os últimos resultados de trabalhos ainda não publicados na imprensa científica, mas já publicados no site de pré-impressão arXiv.org.
Os pesquisadores enfatizam que o NASNet pode ser dimensionado e, portanto, adaptado para trabalhar em sistemas com recursos de computação fracos, sem muita perda de precisão. A rede neural é capaz de funcionar mesmo em um telefone móvel com uma CPU fraca e com um recurso de memória limitado. Os autores dizem que a versão em miniatura do NASNet mostra uma precisão de 74%, que é 3,1 pontos percentuais melhor do que as redes neurais conhecidas da mais alta qualidade para plataformas móveis.
Quando os atributos adquiridos do classificador ImageNet foram transferidos para o reconhecimento de objetos e combinados com a estrutura
Faster-RCNN , o sistema apresentou os melhores resultados no problema de reconhecimento de objetos COCO, tanto no modelo grande quanto na versão reduzida para plataformas móveis. O modelo grande mostrou um resultado de 43,1% mAP, que é 4 pontos percentuais melhor que o concorrente mais próximo.
Os autores abriram o código-fonte para NASNet nos repositórios
Slim e
Object Detection para TensorFlow, para que todos possam experimentar uma nova rede neural em seu próprio trabalho.
O artigo científico foi
publicado em 1 de dezembro de 2017 no site de pré-impressão arXiv.org (arXiv: 1707.07012v3, terceira versão).