No início de novembro de 2017, a Qualcomm Datacenter Technologies (QDT) concluiu o trabalho em sua nova criação - um processador baseado na tecnologia de 10 nm - Centriq 2400. Que futuro aguarda o setor, de acordo com os criadores dessa inovação? Quais são os benefícios de obter servidores e por que o Centriq 2400 é tão exclusivo? Leia mais sobre isso e muito mais.
Em 8 de novembro, foi realizada uma conferência de imprensa da QDT em San Jose (Califórnia), na qual o início das entregas do novo processador foi anunciado oficialmente. Anand Chandrasekher, vice-presidente sênior e diretor executivo, disse:
A apresentação de hoje é uma conquista importante e o culminar de mais de 4 anos de design, desenvolvimento e suporte diligentes do sistema ... Criamos o processador de servidor mais avançado do mundo, que oferece alto desempenho combinado com um alto nível de eficiência energética, permitindo que nossos clientes reduzam significativamente seus custos.
Além do orgulho indiscutível em seus produtos, os representantes da empresa não têm vergonha de declarar que o processador Centriq 2400 é significativamente superior aos produtos concorrentes, por exemplo, Intel Xeon Platinum 8180. De acordo com seus cálculos, para cada dólar gasto (e o custo do processador é de US $ 1995), o usuário obterá desempenho em 4 vezes. E quando recalculado para o desempenho em 1 watt - 45% a mais. Declarações ousadas, no entanto, muitos dos representantes de várias empresas interessadas no novo produto estão mais do que felizes em ouvi-los.
Especificações técnicas do Qualcomm Centriq 2400
Arquitetura da CPU:- até 48 núcleos de 64 bits com um pico de frequência de 2,6 GHz;
- Compatibilidade com Armv8
- Somente AArch64;
- Armv8 FP / SIMD;
- Extensão de CRC e Armv8 Crypto;
Cache da CPU:- Cache de instruções de 64 Kb (instruções) L1 e 24 Kb de cache L0 de ciclo único;
- Cache de dados L1 de 32 Kb;
- 512 KB de cache L2 total para cada 2 núcleos;
- Cache L3 compartilhado de 60 MB;
- filtrar solicitações de interprocessador L2;
- QoS;
onde L (L1, L2, L3, L0) é o nível, ou seja, L0 é o nível zero.Tecnologia:- Tecnologia FinFET de 10nm da Samsung;
Largura de banda da memória:- 6 canais para conectar módulos de memória DDR4;
- até 2667 MT / s por conexão;
- 128 GB / s - largura de banda total máxima;
- Compactação de largura de banda incorporada
Capacidade de memória:- 768 GB = 128 GB x 6 conexões;
Tipo de memória:- Conexões DDR4 de 64 bits com ECC de 8 bits;
- RDIMM e LRDIMM;
Interface suportada:- GPIO
- I²C;
- SPI
- SATA Gen 3 de 8 bandas;
- 32 PCIe Gen3 com capacidade de conectar até 6 controladores PCIe;
Além das características acima, vale ressaltar que este processador possui 18 bilhões de transistores em cada chip. E todos os seus núcleos são conectados por um barramento em anel bidirecional. Em carga máxima, o Centriq 2400 consome apenas 120 watts.
O foco principal do novo processador ainda são as soluções em nuvem. Segundo os representantes da empresa, o Centriq 2400 permitirá criar sistemas de servidor que serão caracterizados por alto desempenho, eficiência e escalabilidade.
Isso não poderia deixar de atrair muitas empresas, tecnologias em nuvem para as quais são quase a base de suas atividades. A apresentação contou com a presença de: Alibaba, LinkedIn, Cloudflare, American Megatrends Inc., Arm, Cadence Design Systems, Canonical, Chelsio Communications, Excelero, Hewlett Packard Enterprise, Illumina, MariaDB, Mellanox, Microsoft Azure, MongoDB, Netronome, Packet, Red Hat, ScyllaDB, 6WIND, Samsung, Solarflare, Smartcore, SUSE, Sinopse, Uber, Xilinx. A lista é bastante impressionante, o que indica maior atenção a este produto.
No momento, o processador Qualcomm Centriq 2400 está apenas ganhando força, tanto em prevalência quanto em popularidade. O que, naturalmente, levará ao surgimento de algo novo, semelhante ou até mais produtivo, dos concorrentes da QDT.
Mas nem todo mundo acredita cegamente na frescura de novos itens. Se aqueles que acreditam que a realização de testes e análise comparativa de vários processadores permitirão que você veja resultados muito mais indicativos do que as palavras dos promotores do Centriq 2400.
O Cloudflare conduziu uma análise comparativa de três plataformas: Grantley (Intel), Purley (Intel) e Centriq (Qualcomm).
Abaixo serão apresentados gráficos dessa análise e as conclusões de seu autor -
Vlad Krasnov . (
Original desta análise no blog do Cloudflare )
Criptografia de Chave Pública
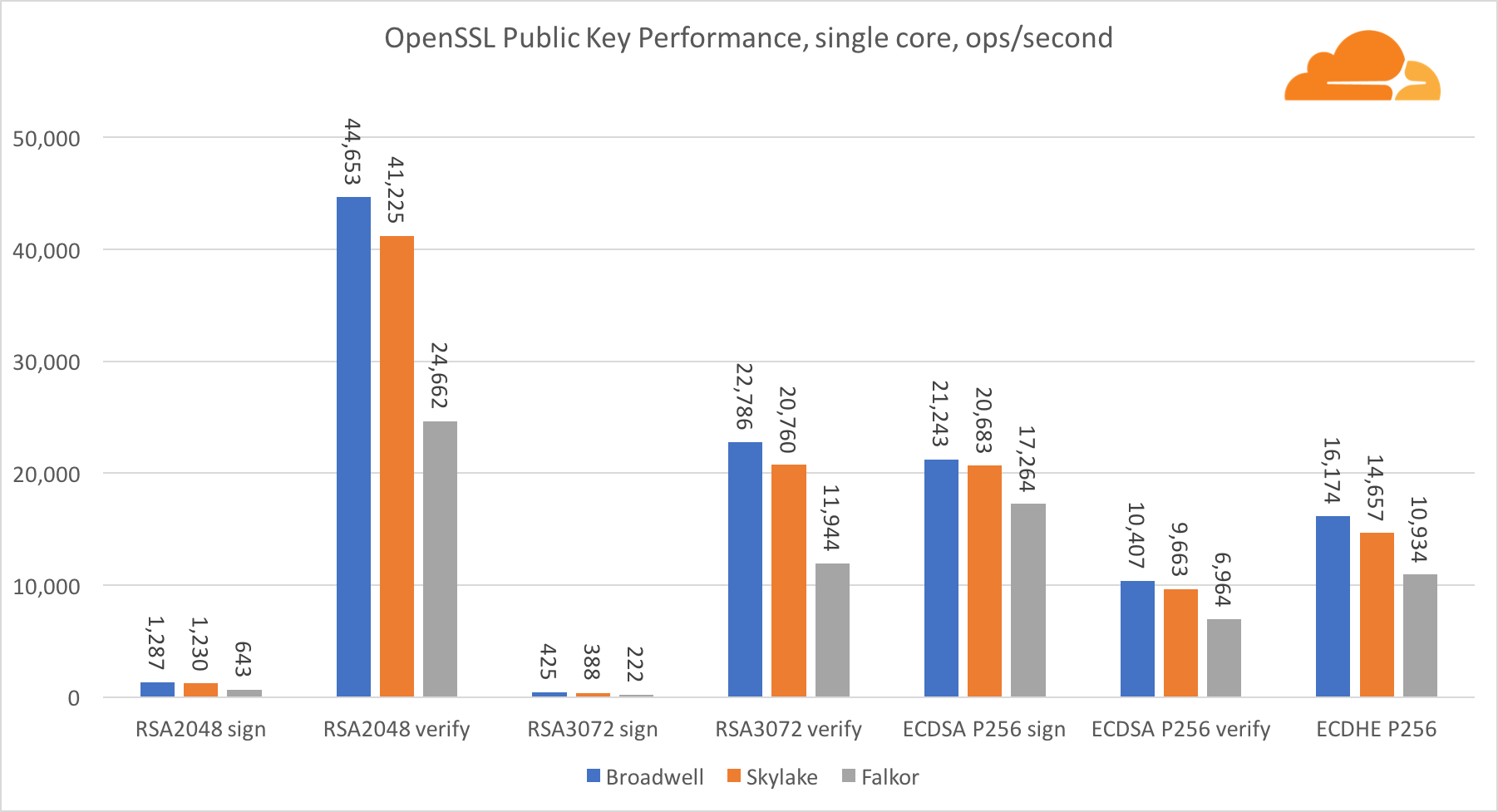
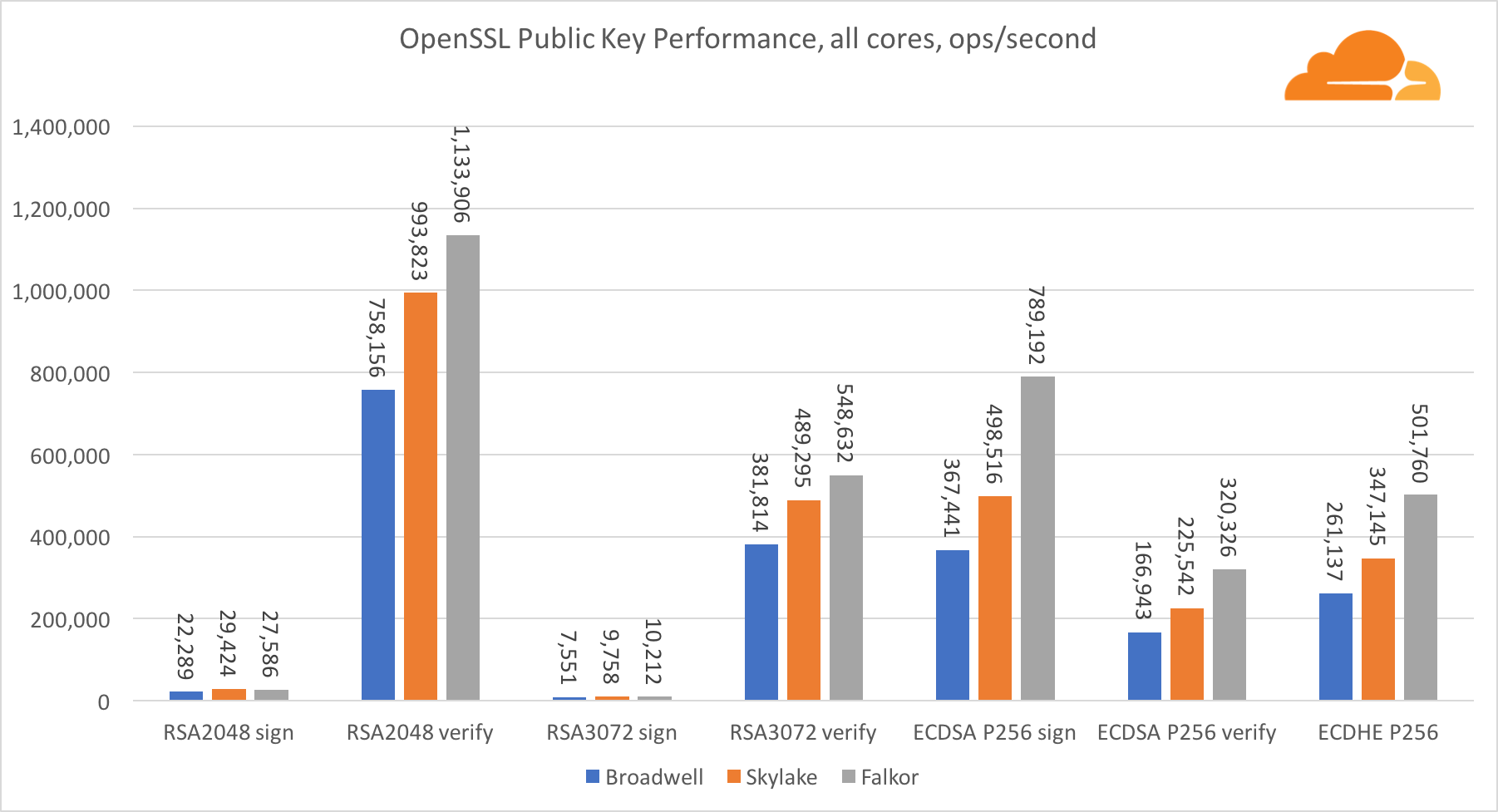
A criptografia de chave pública é o desempenho mais puro da ALU (dispositivo lógico aritmético). É interessante, mas não surpreendente, que em uma referência básica, o núcleo de Broadwell seja mais rápido que o Skylake, e ambos sejam mais rápidos que o Falkor. Isso ocorre porque Broadwell opera com uma frequência mais alta, embora em termos de arquitetura não seja muito inferior ao Skylake.
Falkor é inferior aos outros neste teste. Primeiro, o modo turbo foi ativado em um dos benchmarks básicos, o que significa que os processadores Intel operam com uma frequência mais alta. Além disso, a Intel introduziu duas instruções especiais na Broadwell para acelerar o processamento de grandes números: ADCX e ADOX. Eles executam duas operações independentes de adição / transporte por ciclo, enquanto o ARM pode fazer apenas uma. Da mesma forma, o conjunto de instruções do ARMv8 não possui um único comando para executar a multiplicação de 64 bits; em vez disso, um par de instruções MUL e UMULH é usado.
No entanto, no nível do SoC, a Falkor vence. É um pouco mais lento que o Skylake em termos de RSA2048 e somente porque o RSA2048 não possui uma implementação otimizada para ARM. O desempenho da ECDSA é ridiculamente alto. Um único chip Centriq pode satisfazer as necessidades de quase qualquer empresa do mundo com a ECDSA.
Também é muito interessante ver que a Skylake ultrapassa Broadwell em 30%, apesar de ter perdido no teste para um núcleo e ter apenas 20% mais núcleos que Broadwell. Isso pode ser explicado por um modo turbo mais eficiente e por um hyperthreading aprimorado.
Criptografia simétrica
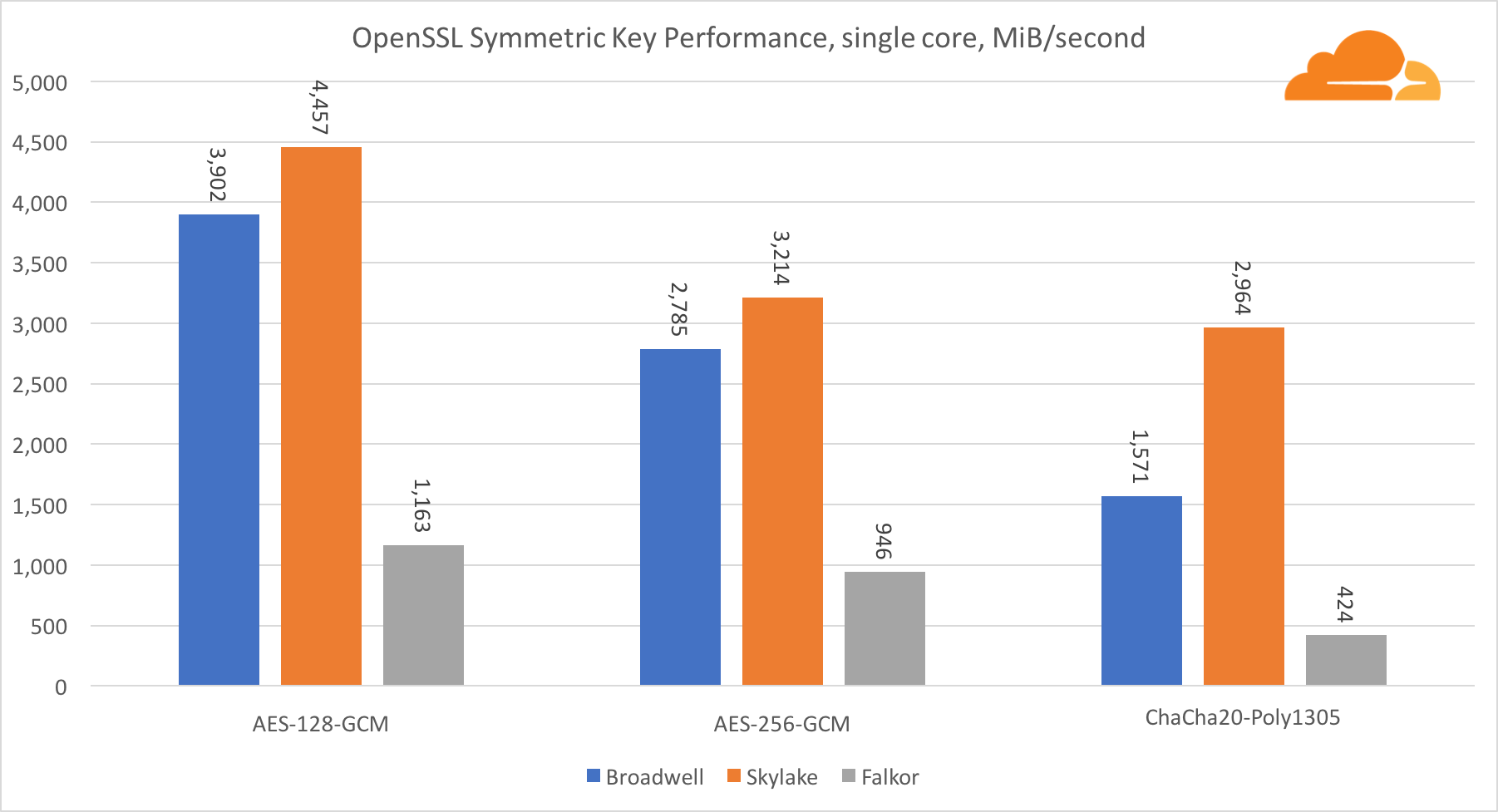
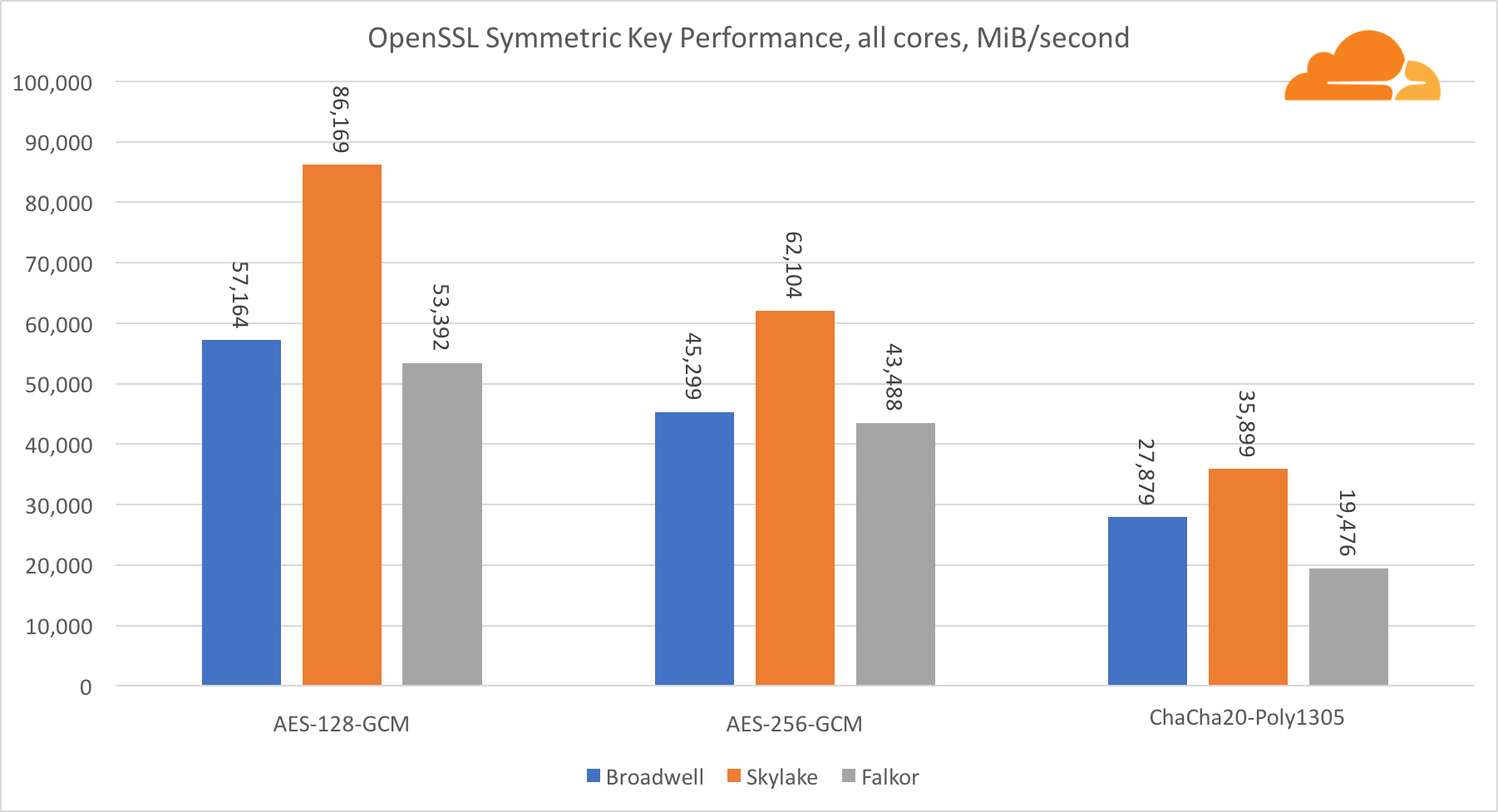
O desempenho dos núcleos da Intel na criptografia simétrica é simplesmente excelente.
O AES-GCM usa uma combinação de instruções especiais de hardware para acelerar o AES e o CLMUL. A Intel apresentou essas instruções pela primeira vez em 2010, com seu processador Westmere e, a cada geração, eles aprimoravam seu desempenho. O ARM introduziu recentemente um conjunto de instruções semelhantes com seu conjunto de instruções de 64 bits como uma adição opcional. Felizmente, todos os fornecedores de equipamentos que conheço os implementaram. É altamente provável que a Qualcomm melhore o desempenho das instruções criptográficas nas gerações futuras.
O ChaCha20-Poly1305 é um algoritmo mais geral projetado de forma a fazer melhor uso de amplos módulos SIMD. A Qualcomm possui apenas NEON SIMD de 128 bits, a Broadwell possui o AVX2 de 256 bits e a Skylake possui o AVX-512 de 512 bits. Isso explica por que a Skylake com essa margem deixou a liderança na avaliação do trabalho com um único núcleo. No teste de todos os núcleos, ao mesmo tempo, o espaço da Skylake em relação aos demais foi reduzido, pois deveria reduzir a frequência do relógio ao executar cargas de trabalho AVX-512. Ao executar o AVX-512 em todos os núcleos, a frequência base diminui para 1,4 GHz. Lembre-se disso se você misturar o AVX-512 e outro código.
A conclusão sobre a criptografia simétrica é que, apesar de a Skylake liderar, Broadwell e Falkor apresentaram resultados muito bons, com desempenho bastante alto para casos reais, dado que, do nosso lado, a RSA consome mais tempo do processador do que todos os outros algoritmos criptográficos combinados. .
Compressão (compressão)
O próximo teste que eu queria fazer era a compactação. Por duas razões. Primeiramente, essa é uma carga de trabalho importante, porque quanto melhor a compactação, menos lacunas na capacidade e isso permitem uma entrega mais rápida de conteúdo ao cliente. Em segundo lugar, essa é uma carga de trabalho de previsão incorreta de ramificação de alta frequência muito exigente.
Obviamente, o primeiro teste será a popular biblioteca zlib. No Cloudflare, usamos uma versão aprimorada da biblioteca otimizada para processadores Intel de 64 bits e, embora seja escrita principalmente em C, ela usa alguns recursos internos específicos da Intel. Seria injusto comparar esta versão otimizada com o zlib original. Mas não se preocupe, um pouco de esforço e eu adaptei a biblioteca para que ela funcione na arquitetura ARMv8, usando as propriedades NEON e CRC32. Além disso, sua velocidade é 2 vezes maior que a original, para alguns arquivos.
O segundo teste é a nova biblioteca brotli, escrita em C e permitindo o uso de condições iguais para todas as plataformas.
Todos os testes foram realizados no HTML blog.cloudflare.com, na memória, semelhante à forma como o NGINX realiza a compactação de streaming. A menos que a versão específica do arquivo HTML tenha 29329 bytes, o que é um bom indicador, pois corresponde ao tamanho da maioria dos arquivos que compactamos. O teste de compactação paralela é a compactação paralela de vários arquivos ao mesmo tempo; a compactação única é a compactação de um arquivo em vários fluxos, semelhante à maneira como o NGINX funciona.
gzip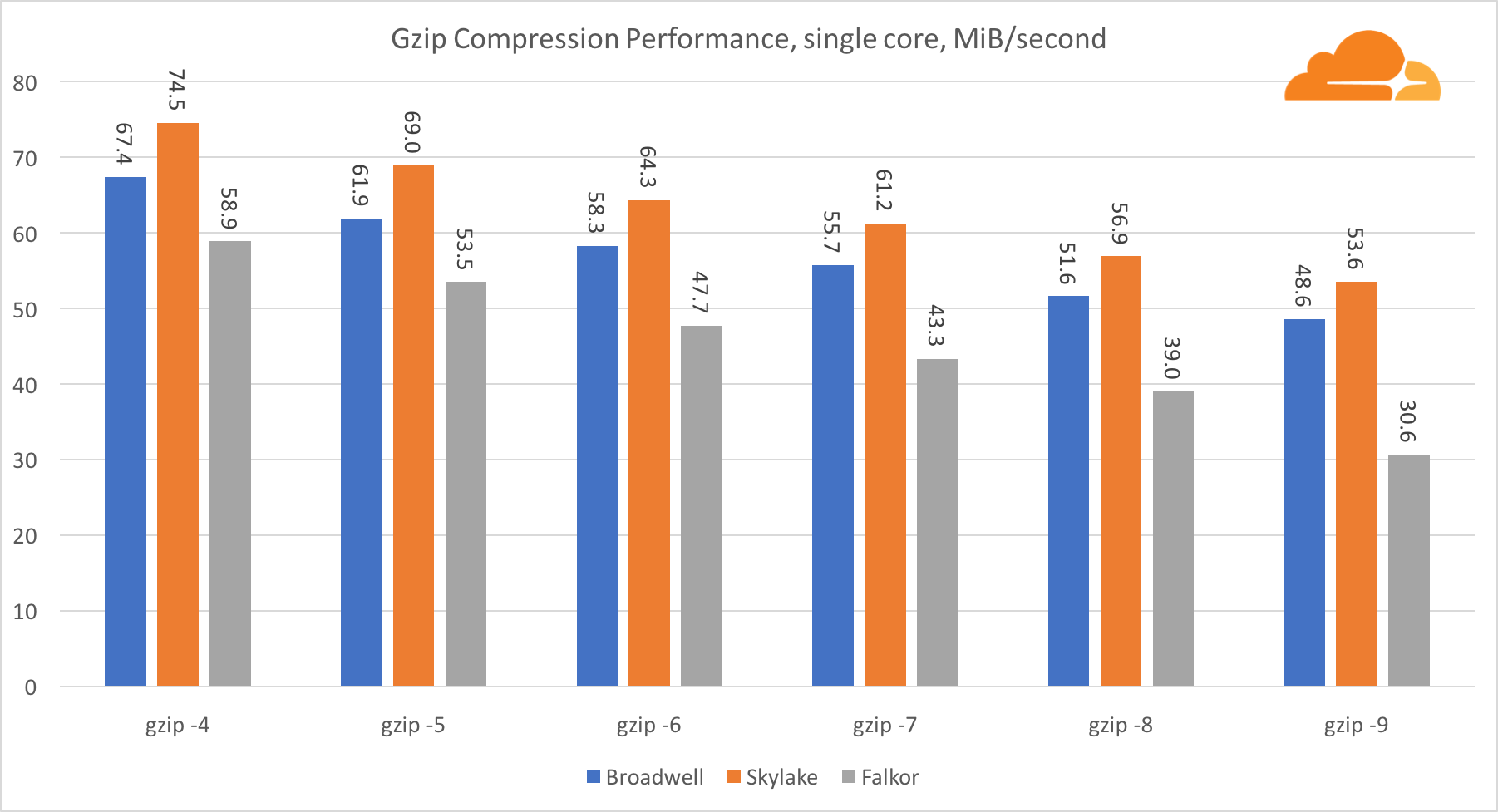
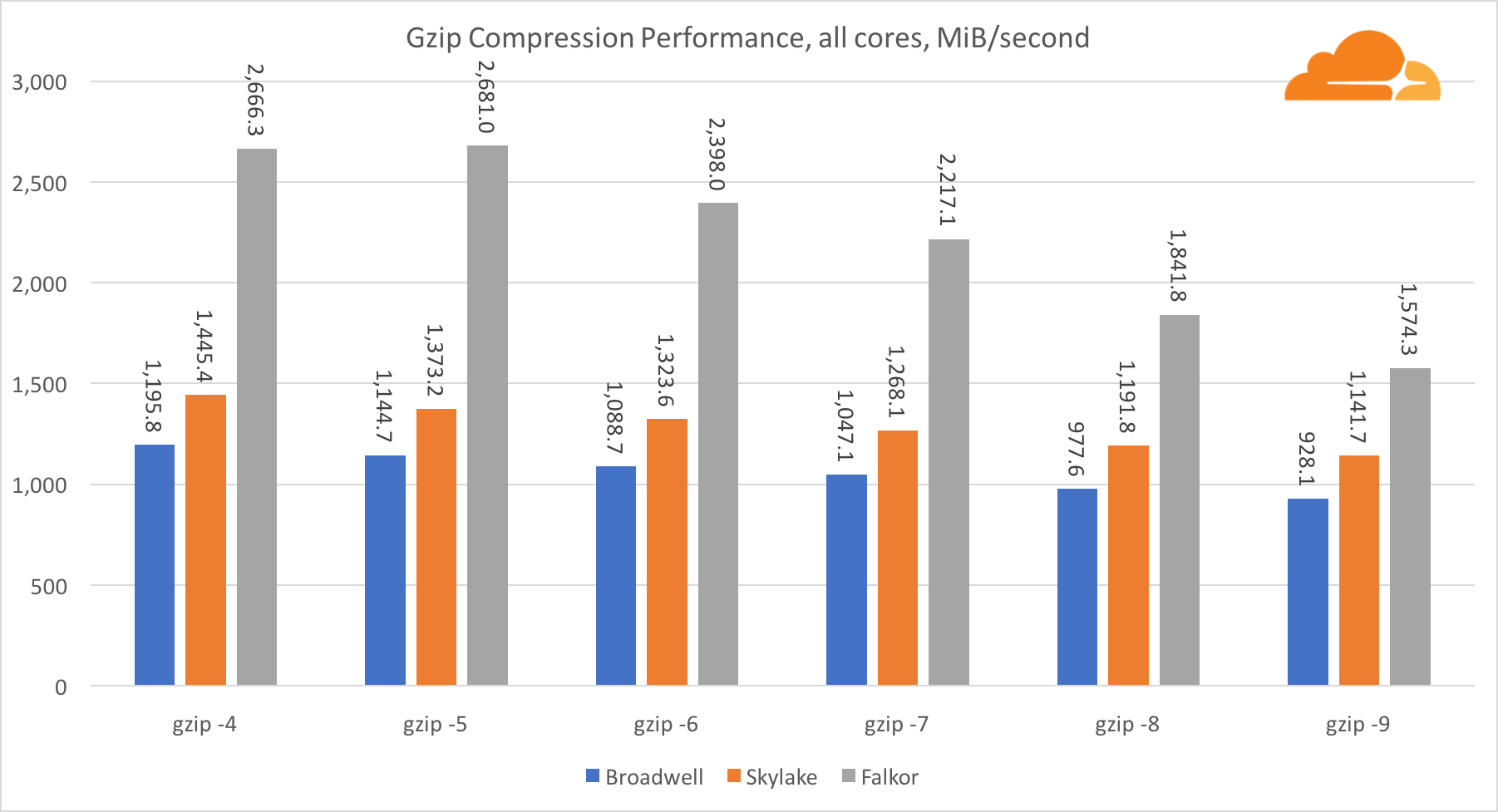
Usando o gzip no nível de núcleo único, a Skylake, sem dúvida, vence. Com uma frequência mais baixa que a Broadwell, a Skylake se beneficia de uma menor exposição a erros de previsão das agências. O núcleo Falkor não está muito atrás. No nível do sistema, o Falkor tem um desempenho muito melhor com mais núcleos. Observe como o gzip se adapta bem a vários núcleos.
BrotliCom brotli em um núcleo, a situação é semelhante à anterior. Skylake é o mais rápido, mas Falkor não está muito atrás. E no padrão 9, o Falkor é ainda mais rápido. O Brotli padrão 4 é muito semelhante ao nível 5 do gzip, enquanto a compactação real ainda é melhor (8010B versus 8187B).
Ao compactar em vários núcleos, a situação se torna um pouco confusa. Para os níveis 4, 5 e 6, o brotli escala muito bem. Nos níveis 7 e 8, ele começa a cair produtivamente no núcleo, afundando no nível 9 no nível 9, onde obtemos 3 vezes menos produtividade de todos os núcleos em comparação com um.
Na minha opinião, isso se deve ao fato de que, a cada nível, o brotli começa a consumir mais memória e trava o cache. Os indicadores estão começando a se recuperar já nos níveis 10 e 11.
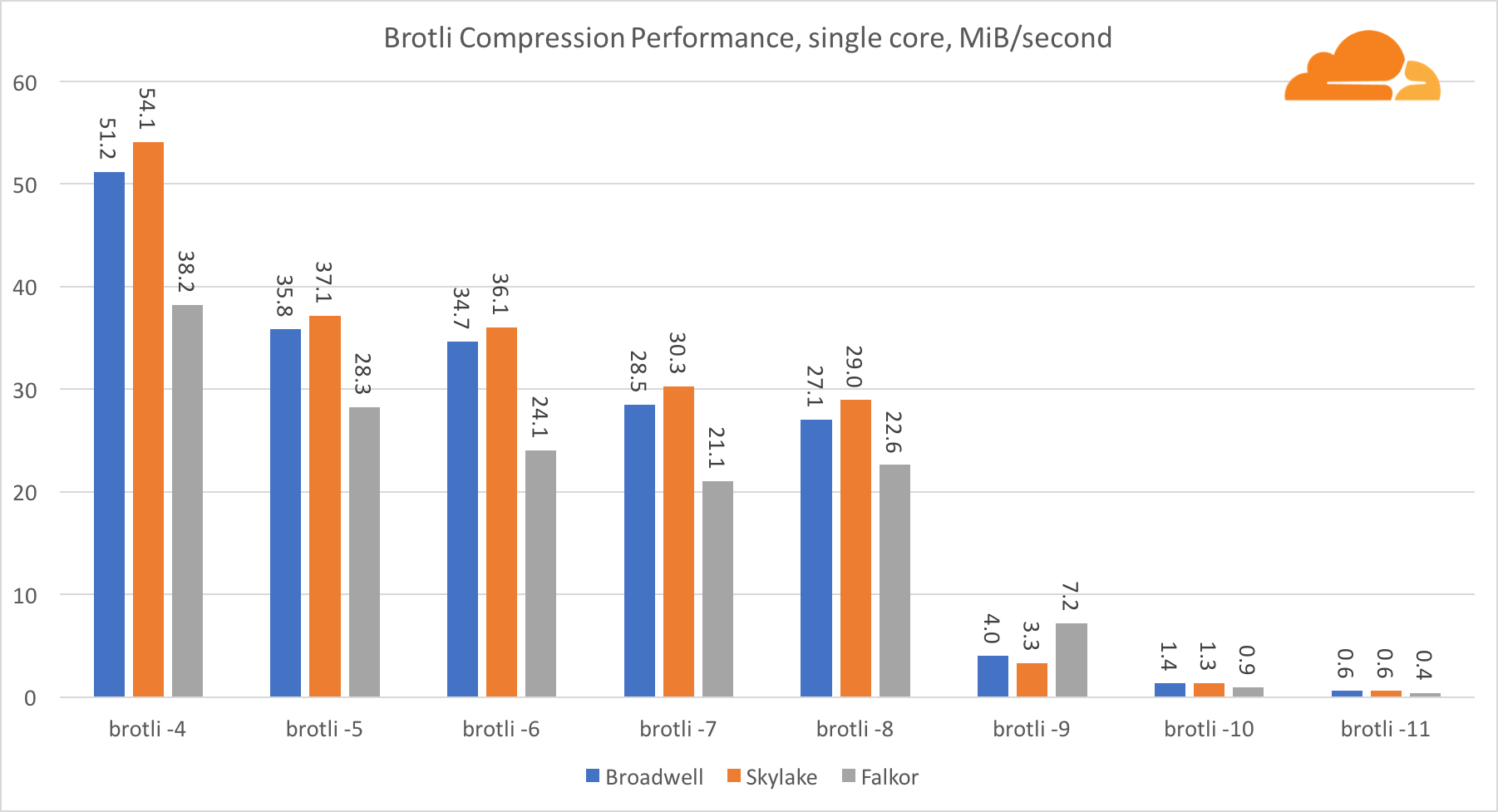
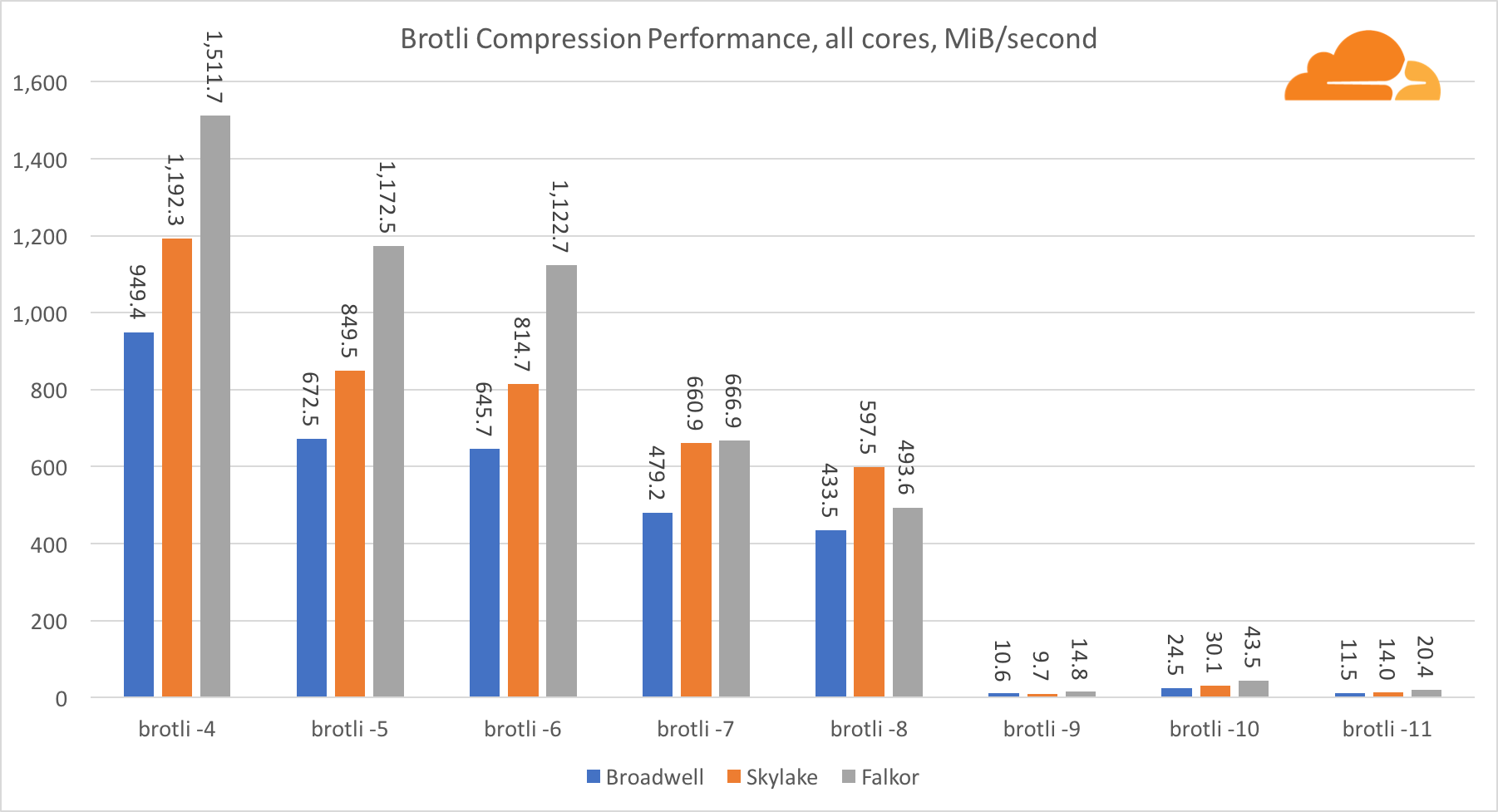
Como conclusão, Falkor venceu, já que a compactação dinâmica não ultrapassará o nível 7.
Golang
Golang é outra linguagem muito importante para o Cloudflare. Também é um dos primeiros idiomas para suportar o ARMv8, para que você possa esperar um bom desempenho. Eu usei alguns testes internos, mas os modifiquei para várias goroutines.
Ir criptografiaEu gostaria de começar com testes de desempenho de criptografia. Graças ao OpenSSL, temos excelentes dados de origem e será muito interessante ver o quão boa é a biblioteca Go.
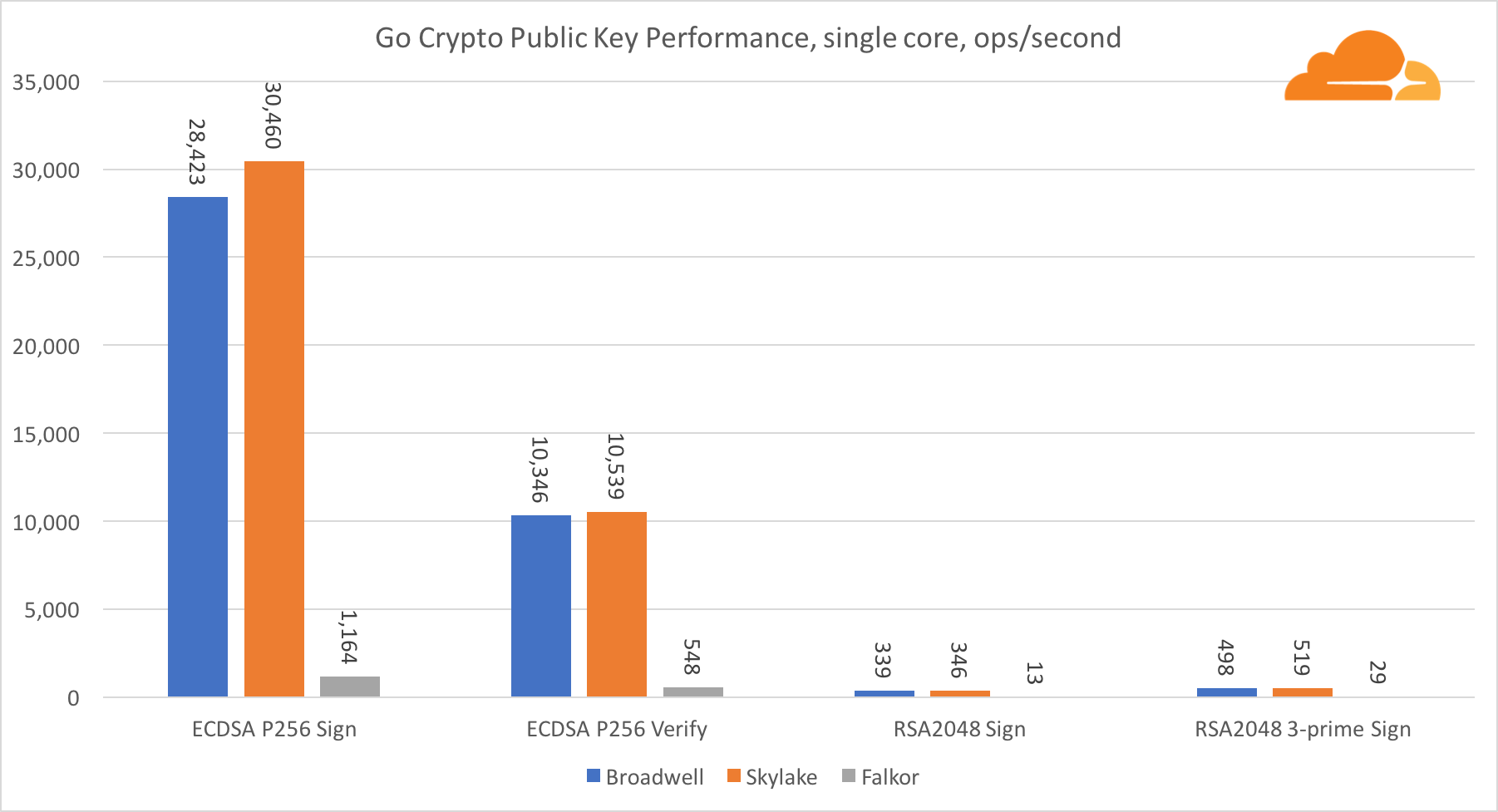
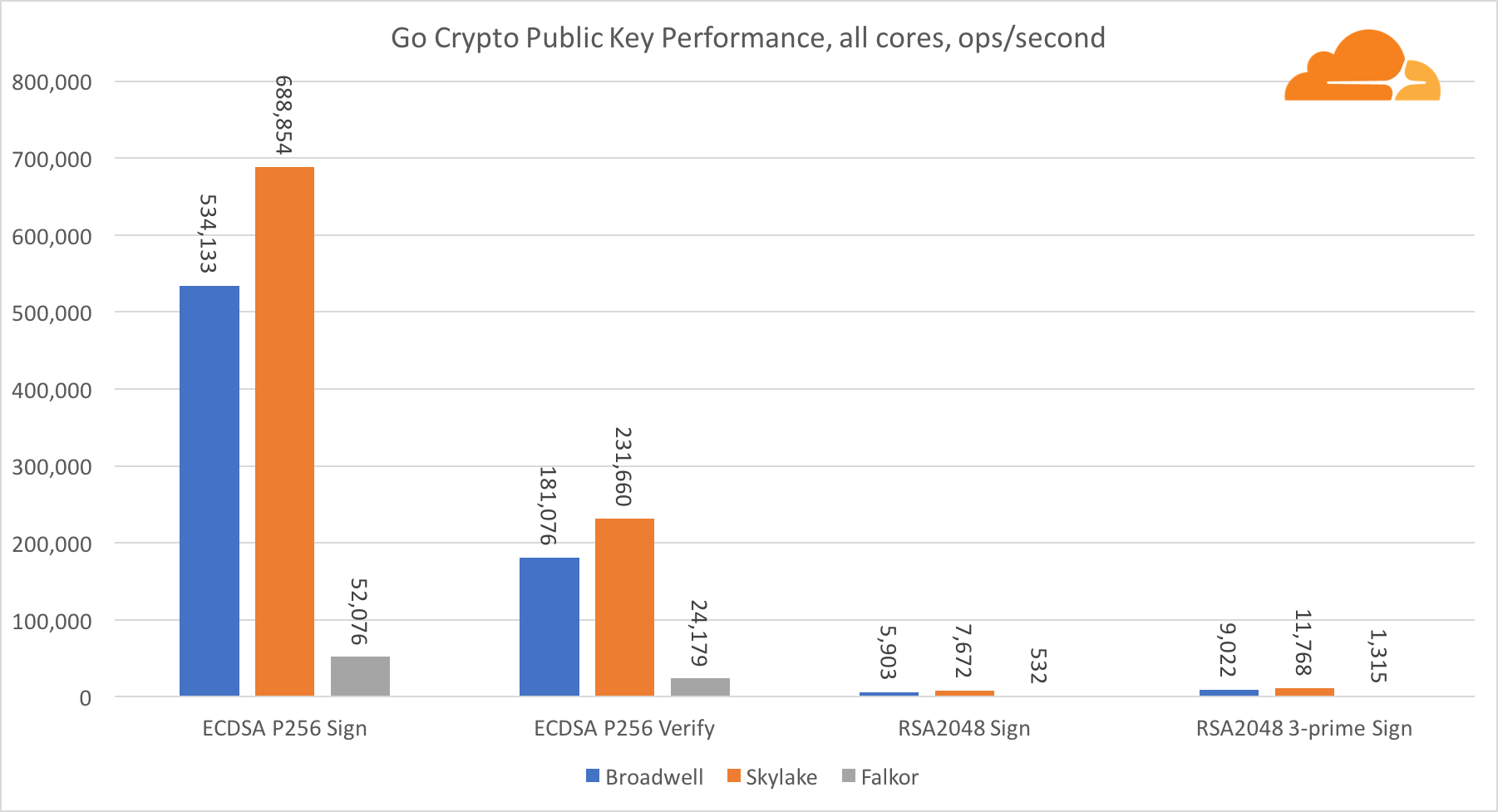
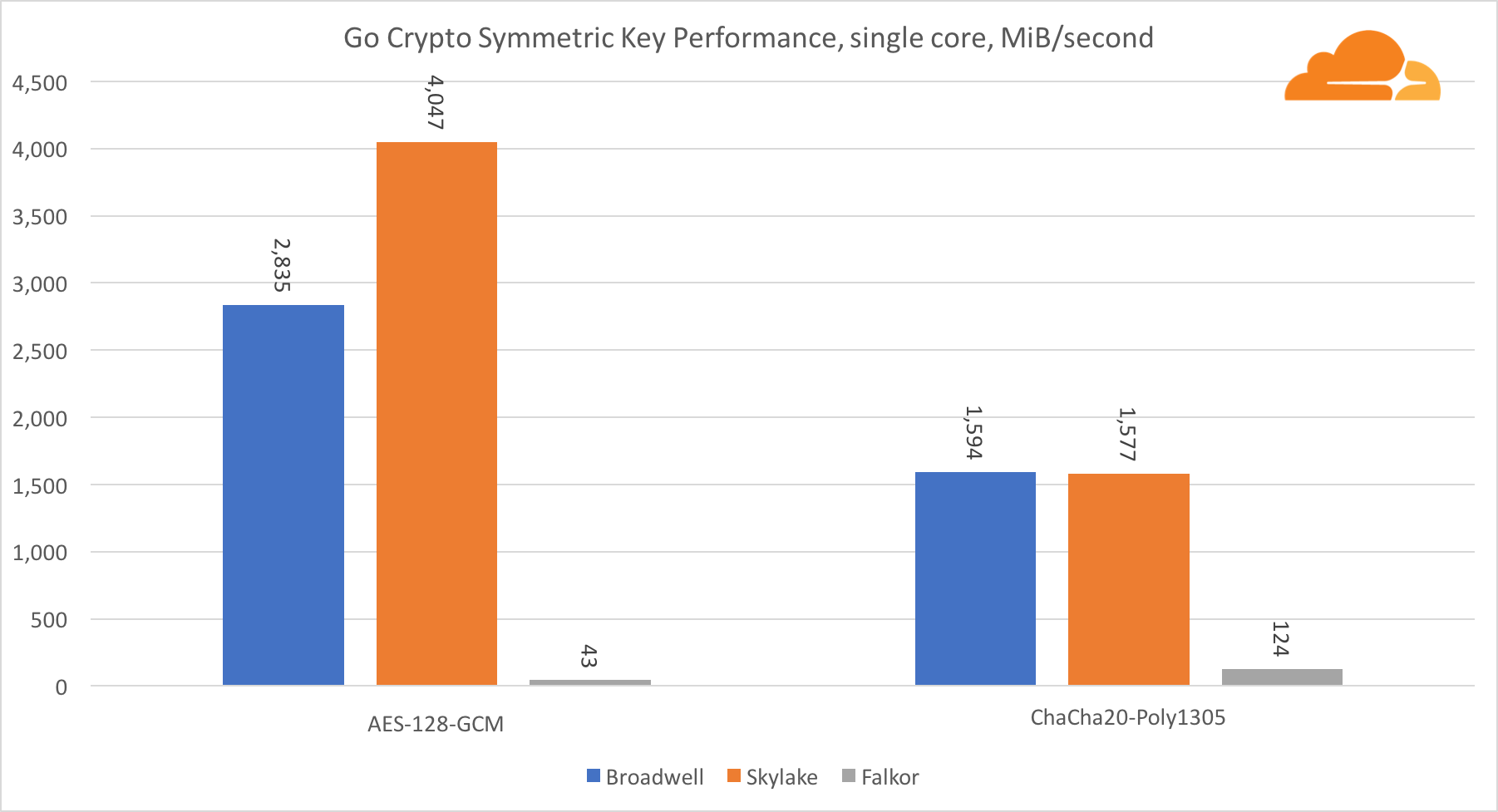
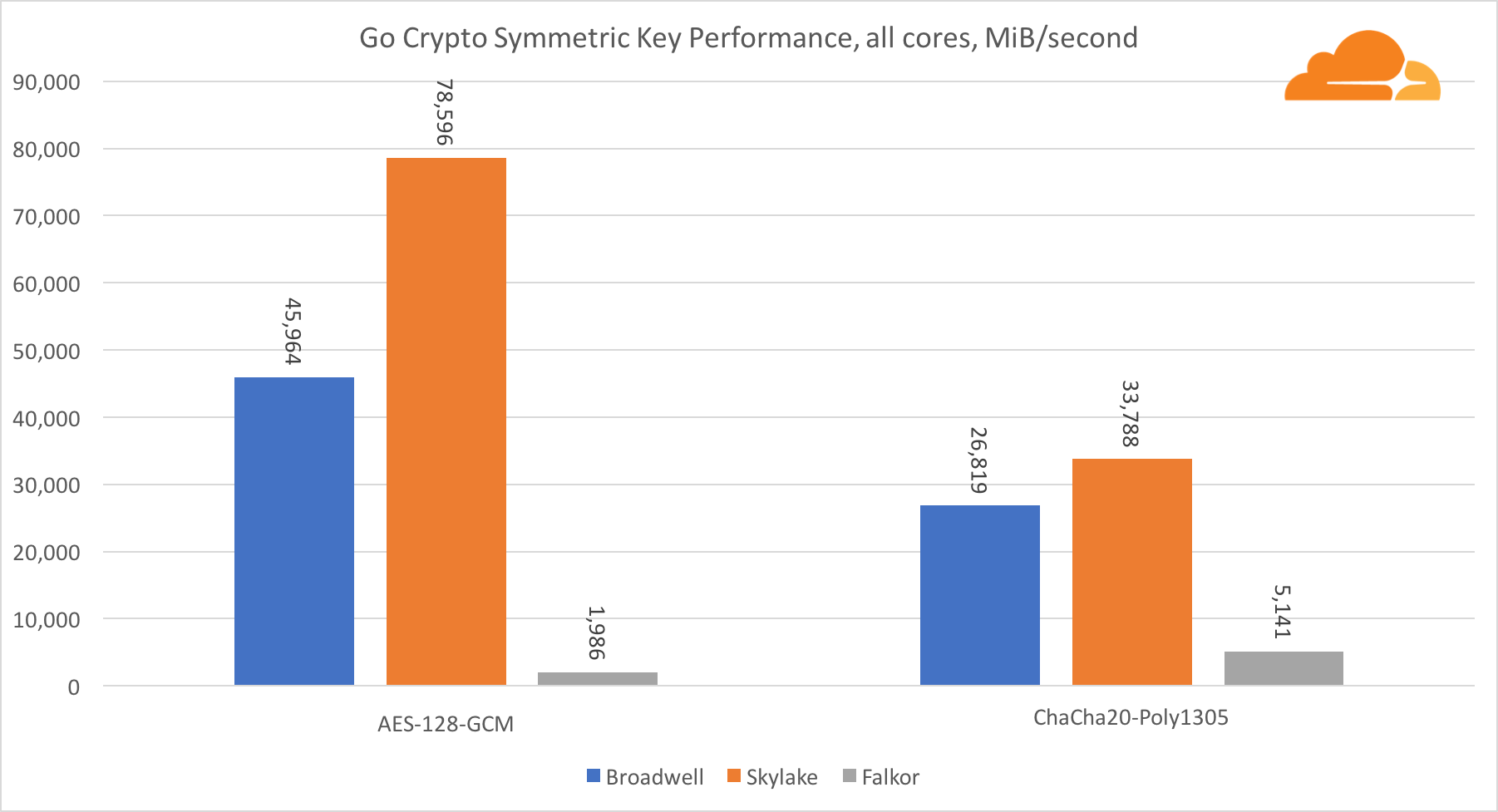
Em relação à criptografia Go, o ARM e a Intel não estão na mesma categoria de peso. O Go possui um código assembler altamente otimizado para ECDSA, AES-GCM e Chacha20-Poly1305 na Intel. Também existem funções matemáticas otimizadas usadas nos cálculos de RSA. O ARMv8 não tem tudo isso, o que o coloca em uma posição muito desvantajosa.
No entanto, a diferença pode ser reduzida com relativamente pouco esforço e sabemos que, com a otimização adequada, o desempenho pode estar no mesmo nível do OpenSSL. Mesmo mudanças muito pequenas, como a implementação da função addMulVVW na montagem, levam a um aumento de dez vezes no desempenho da RSA, colocando Falkor (com uma pontuação de 8009) acima de Broadwell e Skylake.
Vale a pena notar outra coisa interessante - no Skylake, o código Go Chacha20-Poly1305 que usa o AVX2 funciona da mesma maneira que o código OpenSSL AVX512. Novamente, isso se deve ao fato de o AVX2 operar em frequências de clock mais altas.
Go gzipAgora, vamos dar uma olhada no desempenho Go do gzip. Também há um ótimo guia para código bastante otimizado, e podemos compará-lo com o Go. No caso da biblioteca gzip, não há otimizações específicas para a Intel.
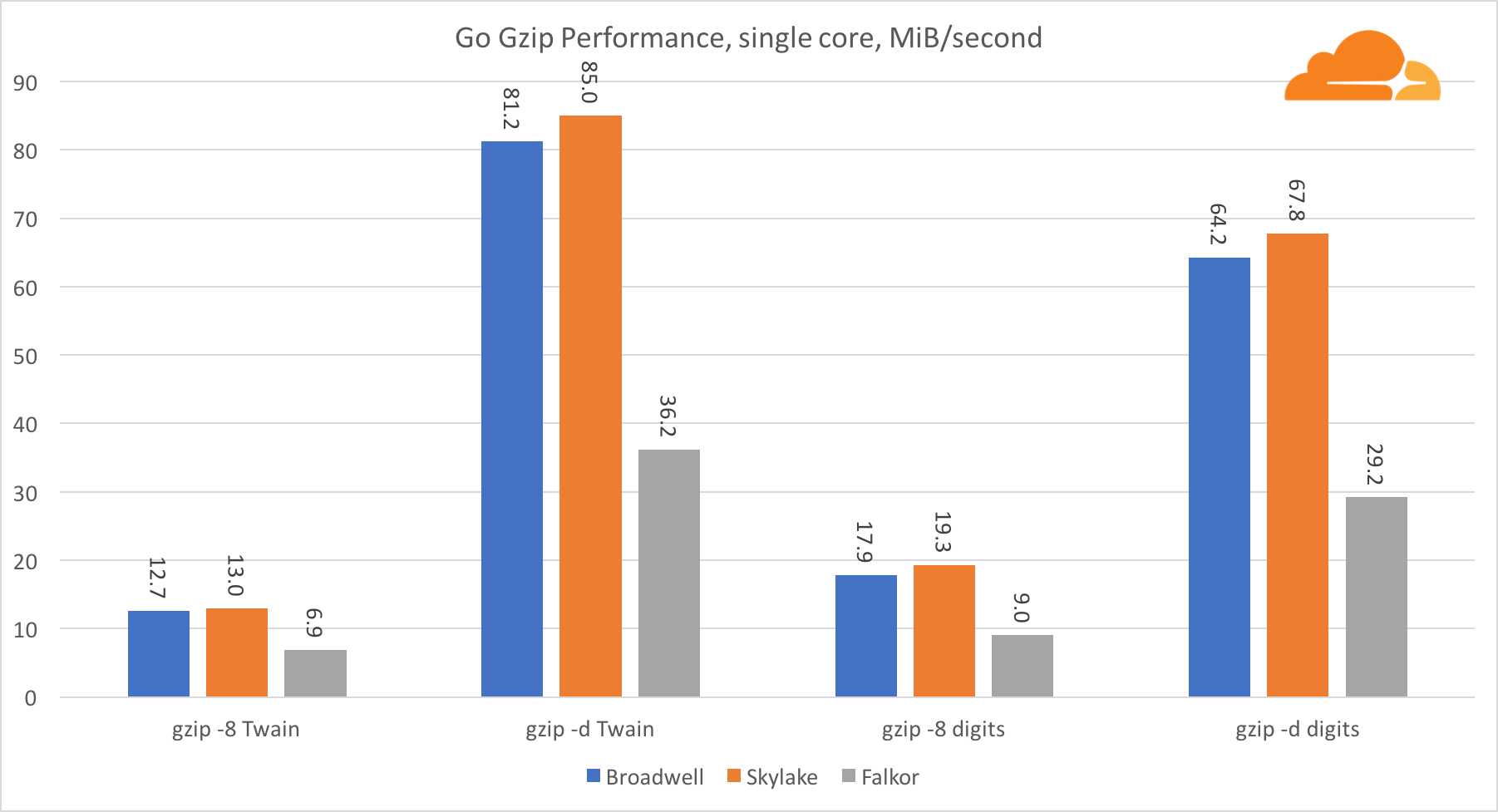

O desempenho do Gzip é muito bom. O desempenho em um único núcleo Falkor fica significativamente atrás dos dois processadores Intel, mas no nível do sistema, ele conseguiu derrotar Broadwell e localizado abaixo de Skylake. Como já sabemos que o Falkor é superior aos outros dois processadores quando o C. está em execução, isso só pode significar uma coisa - o back-end do Go para o ARMv8 ainda não foi finalizado em comparação com o gcc.
Ir regexpO Regexp é amplamente usado em uma variedade de tarefas, porque seu desempenho também é extremamente importante. Fiz testes internos em fluxos de 32 kb.
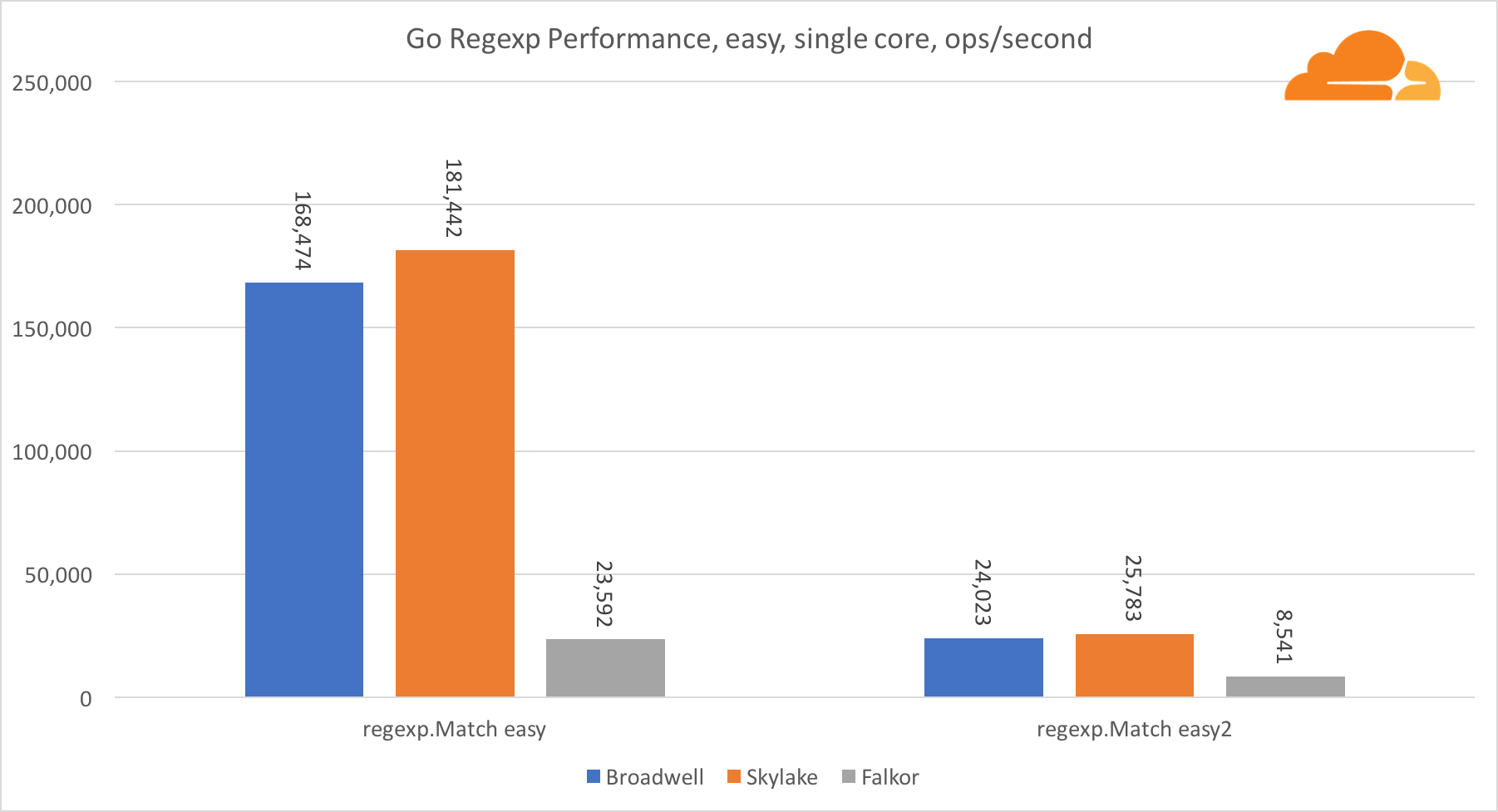
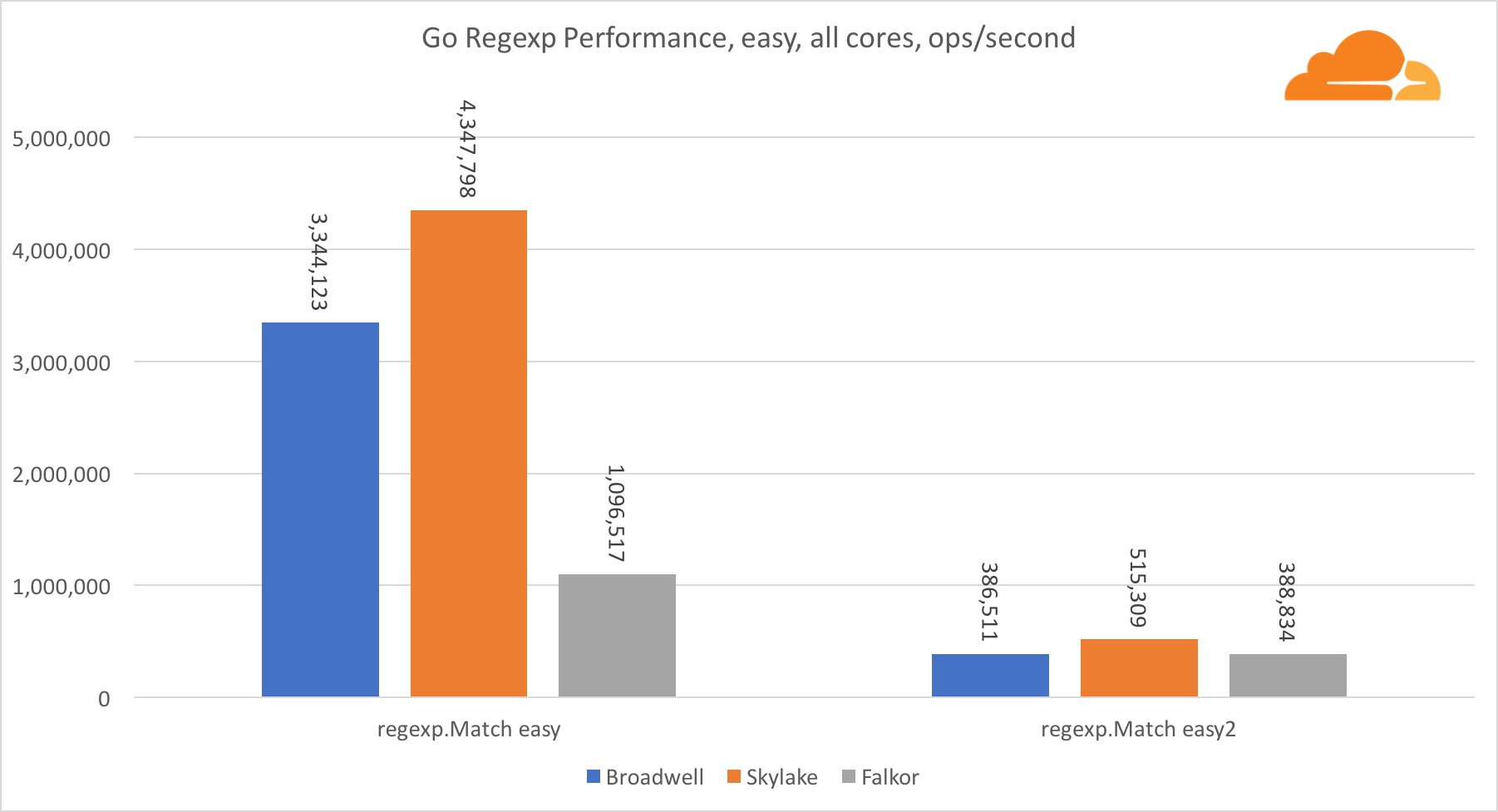
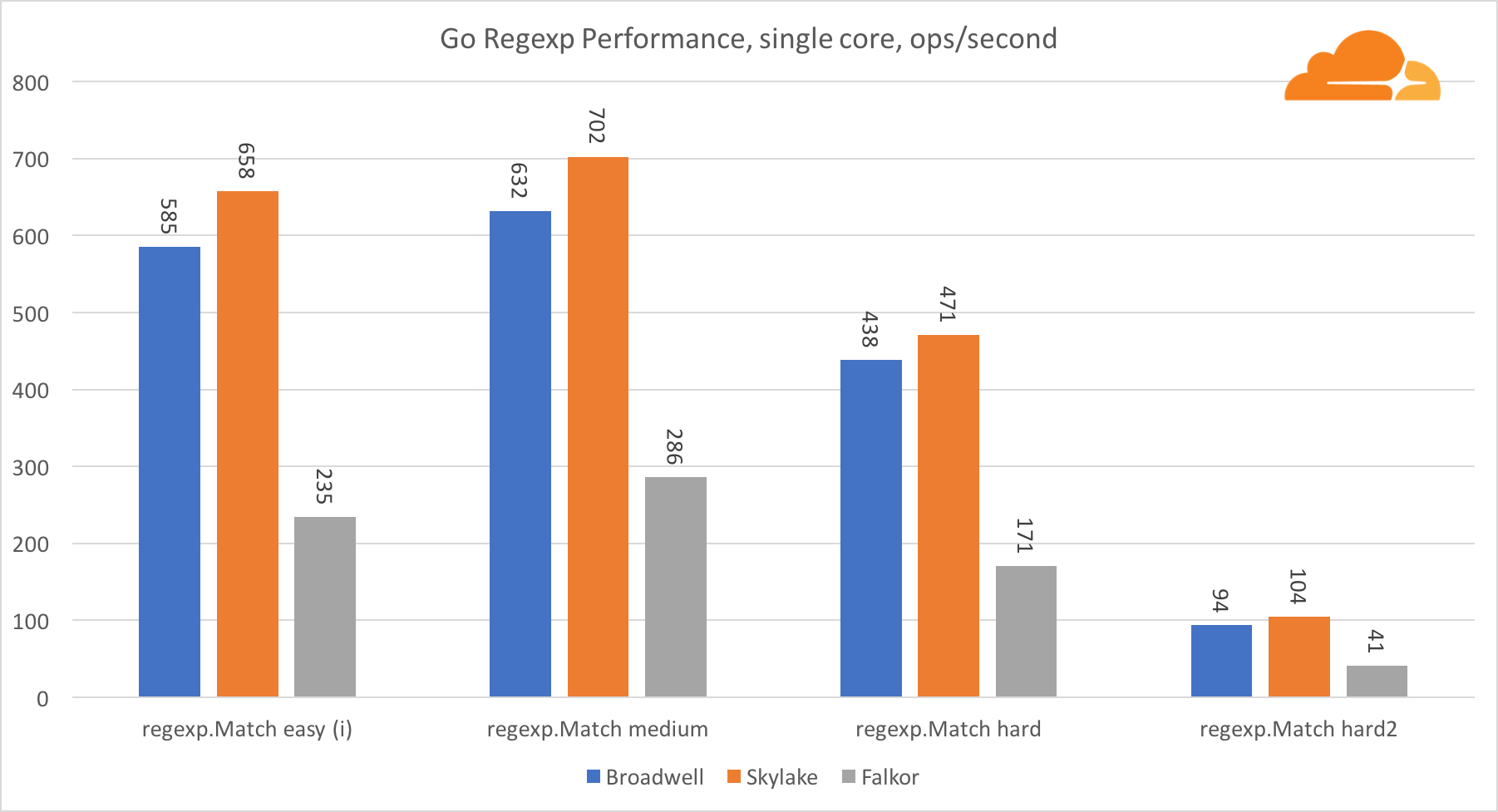
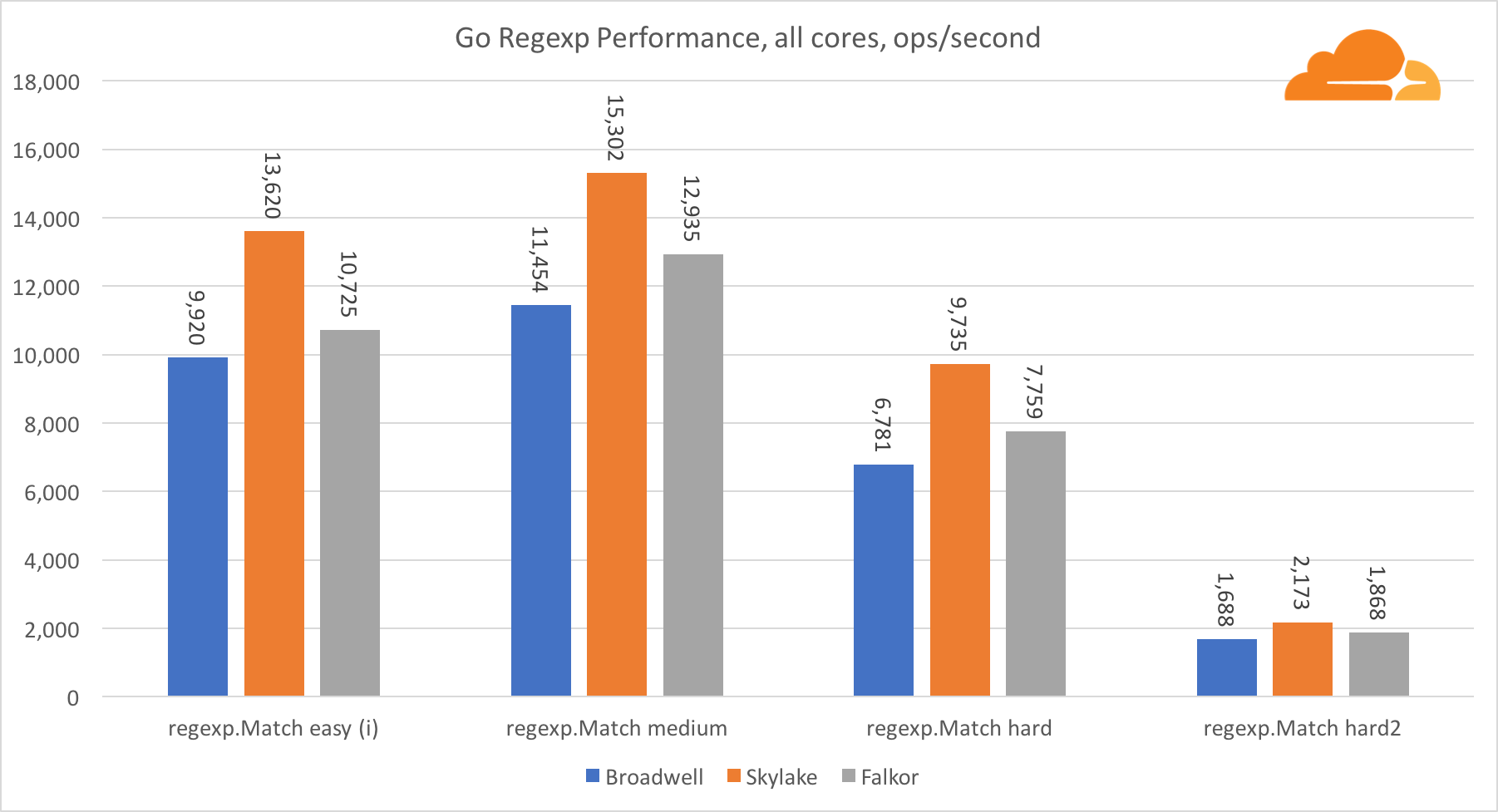
No Falkor, o desempenho do Go regexp não é muito bom. Ele ocupa o segundo lugar em testes médios e complexos, graças a um número maior de núcleos, mas, no entanto, o Skylake é muito mais rápido.
Uma análise mais detalhada do processo mostra que muito tempo é gasto na função bytes.IndexByte. Essa função possui uma implementação de assembler para amd64 (runtime.indexbytebody), mas a principal implementação é para Go. Durante testes leves, o regexp gastou ainda mais tempo com esse recurso, o que explica a diferença maior.
Ir stringsOutra biblioteca importante para o servidor da Web são as seqüências de caracteres Go. Testei apenas a classe principal do Replacer.
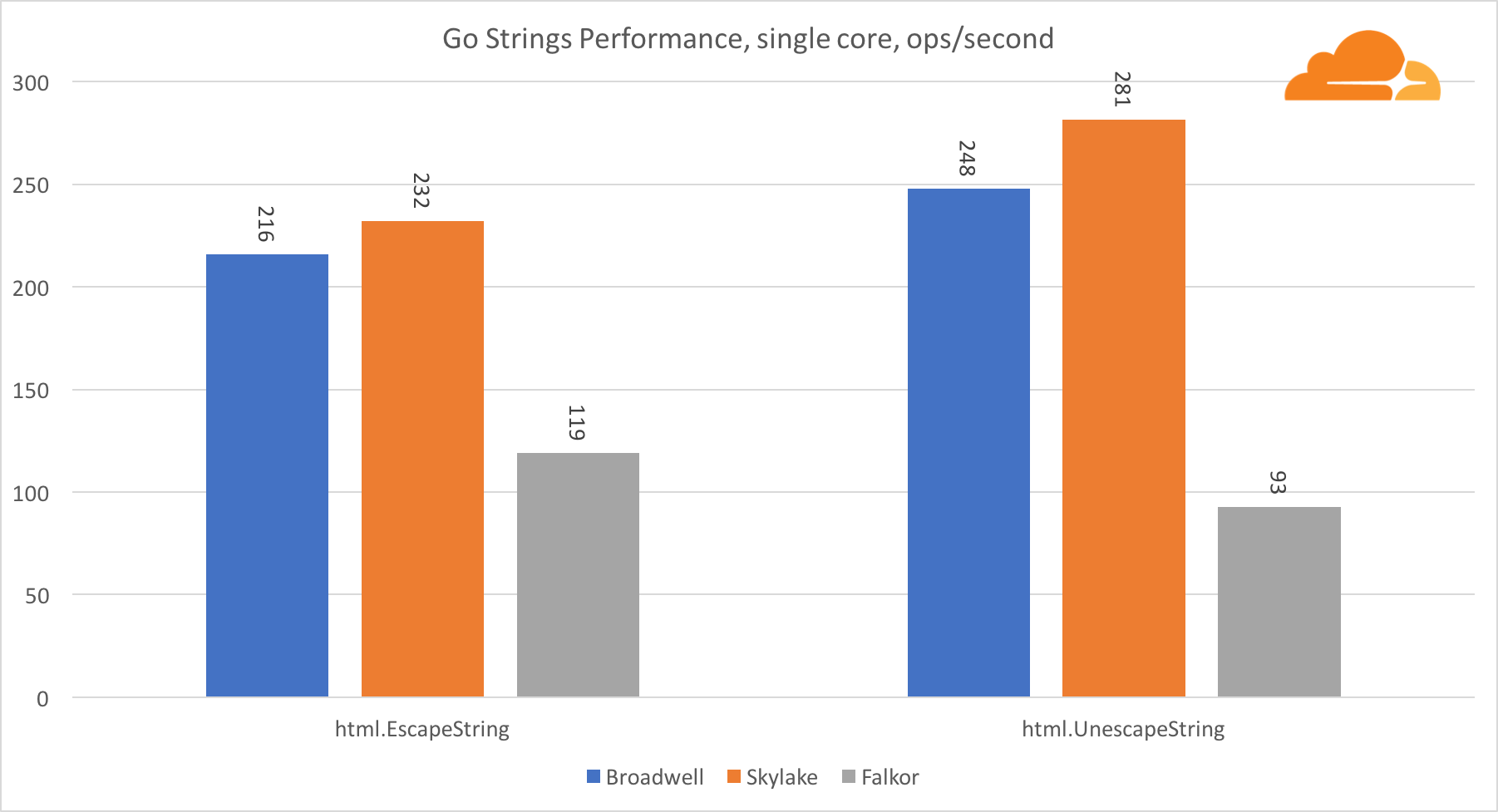
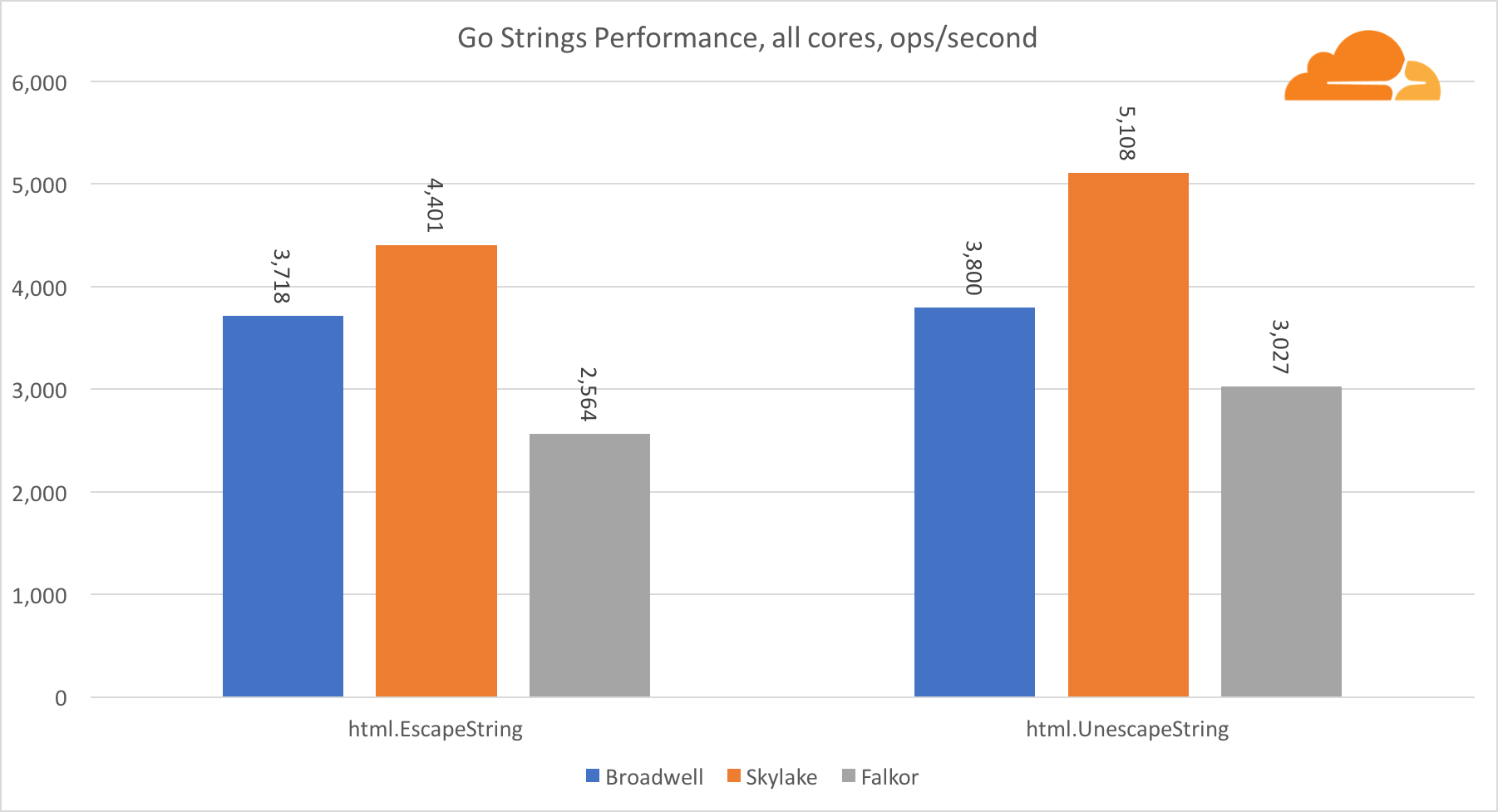
Neste teste, Falkor está novamente atrasado, mesmo atrás de Broadwell. Uma análise mais detalhada revela uma longa permanência na função runtime.memmove. Você sabe o que? Ela possui um código assembler perfeitamente otimizado para amd64 que usa o AVX2, mas apenas o assembler mais simples que copia 8 bytes de cada vez. Alterando 3 linhas neste código e usando as instruções LDP / STP (carregamento de par / armazenamento de par), você pode copiar 16 bytes por vez, o que aumentou o desempenho do memmove em 30%, o que, por sua vez, acelera o EscapeString e o UnescapeString em 20%. E esta é apenas a ponta do iceberg.
Vá conclusãoO suporte a aarch64 é bastante decepcionante. Tenho o prazer de anunciar que tudo foi compilado e funcionou perfeitamente, mas no lado do desempenho, poderia ser melhor. Ficamos com a impressão de que a maior parte do esforço foi gasta no back-end do compilador, e a biblioteca estava quase intocada. Existem muitas otimizações de baixo nível, por exemplo, minha correção addMulVVW, que levou 20 minutos. A Qualcomm e outros fornecedores de ARMv8 pretendem gastar recursos técnicos significativos para corrigir a situação, mas qualquer um pode realmente contribuir para o Go. Portanto, se você quiser deixar sua marca na história, agora é a hora.
Luajit
Lua é a cola que mantém o Cloudflare unido.
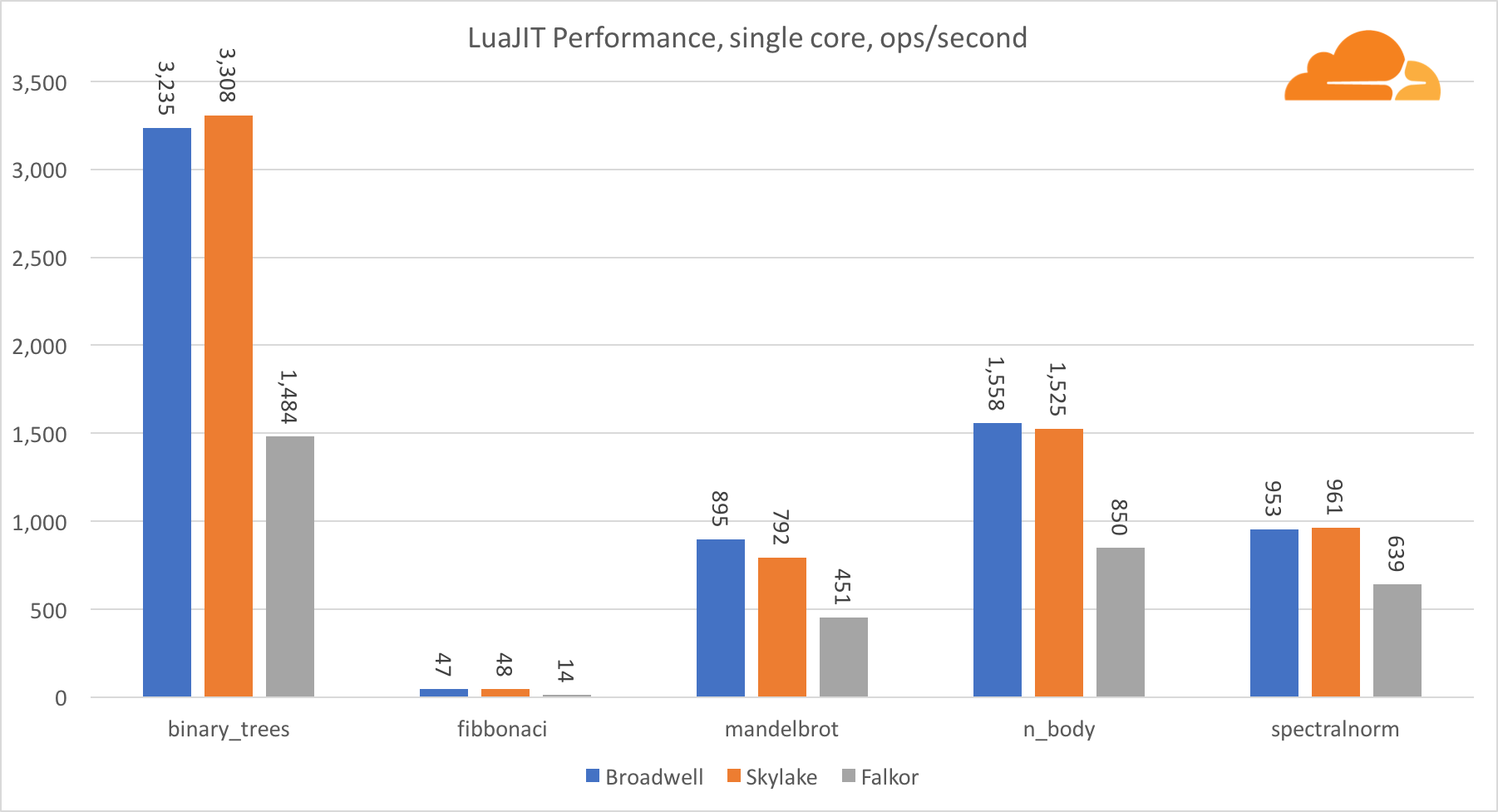
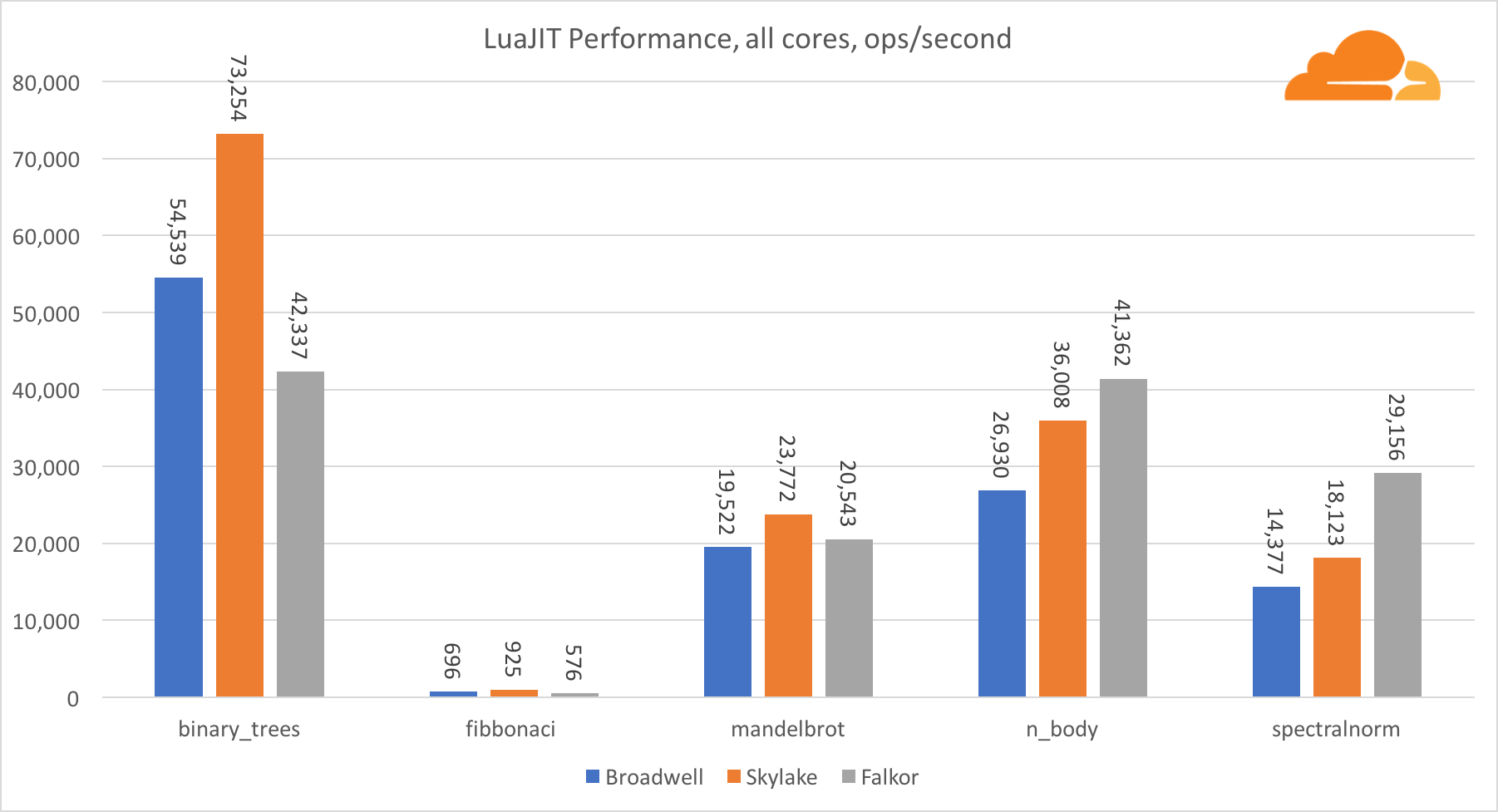
Com exceção do teste binary_trees, o desempenho do LuaJIT no ARM é muito competitivo. Ele vence dois testes e o terceiro fica frente a frente com os concorrentes.
Vale ressaltar que o teste binary_trees é extremamente importante, pois envolve muitos ciclos de alocação de memória e coleta de lixo. Exige uma consideração mais meticulosa no futuro.
Nginx
Como uma carga de trabalho NGINX, decidi criar uma que se parecesse com o servidor real.
Eu configurei um servidor que serve o arquivo HTML usado no teste gzip em https usando o conjunto de criptografia ECDHE-ECDSA-AES128-GCM-SHA256.
Ele também usa LuaJIT para redirecionar a solicitação recebida, remover todas as quebras de linha e espaços extras do arquivo HTML ao adicionar um carimbo de data / hora. O HTML é compactado usando o brotli 5.
Cada servidor foi configurado para funcionar com tantos usuários quanto processadores virtuais. 40 para Broadwell, 48 para Skylake e 46 para Falkor.
Como cliente deste teste, usei o programa hey, executado em 3 servidores Broadwell.
Ao mesmo tempo que o teste, fizemos leituras de energia dos blocos BMC correspondentes de cada servidor.
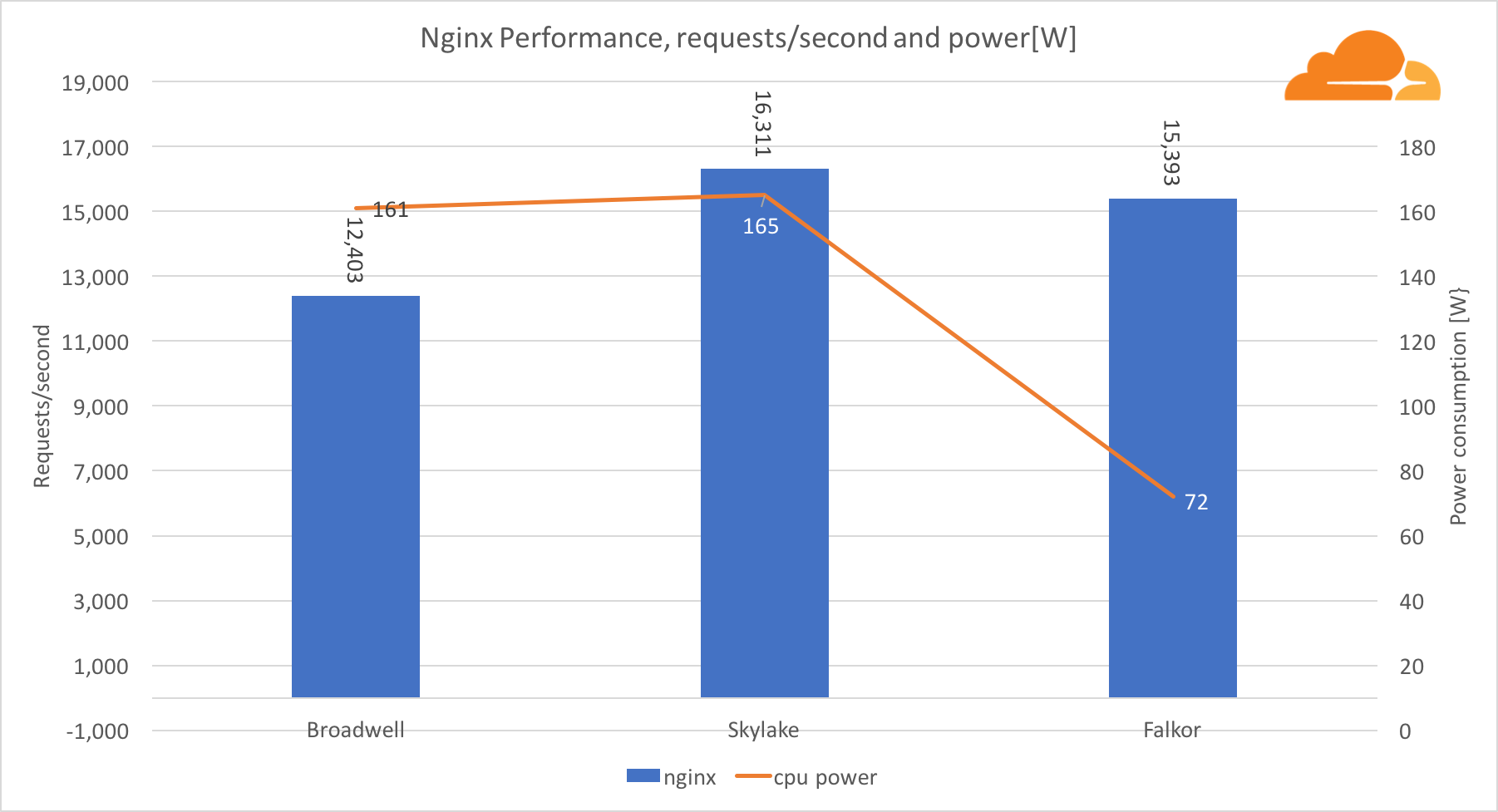
Com a carga de trabalho, o NGINX Falkor atendeu quase o mesmo número de solicitações do servidor Skylake, e ambos estavam significativamente à frente do Broadwell. As leituras de energia obtidas no BMC mostram que isso aconteceu quando a energia foi consumida metade do que os outros processadores. Isso significa que a Falkor conseguiu obter 214 solicitações / W, Skylake - 99 solicitações / W e Broadwell - 77 solicitações / W.
Fiquei surpreso que Skylake e Broadwell consomem quase a mesma quantidade de energia, dado que são produzidos da mesma maneira, e Skylake tem mais núcleos.
O baixo consumo de energia da Falkor não é surpreendente, pois os processadores Qualcomm são conhecidos por sua alta eficiência energética, o que lhes permitiu ocupar uma posição dominante no mercado de processadores para dispositivos móveis.
Conclusão
A amostra de Falkor realmente me impressionou. Essa é uma grande melhoria em relação às tentativas anteriores em servidores baseados em ARM. Obviamente, comparando o núcleo com o núcleo, o Intel Skylake é muito melhor, mas se observarmos o nível do sistema, o desempenho se torna muito atraente.
A versão de produção do Centriq SoC conterá 48 núcleos Falkor operando em frequências de até 2,6 GHz, o que proporciona um aumento potencial de desempenho de 8%.
Obviamente, o Skylake que testamos não é um carro-chefe como a Platinum, com 28 núcleos, mas esses 28 núcleos custam muito e consomem 200W, enquanto tentamos otimizar nossos custos e aumentar o desempenho em 1 watt.
No momento, estou mais preocupado com o fraco desempenho do idioma Go, mas isso mudará assim que os servidores baseados em ARM ocuparem seu nicho no mercado.
O desempenho C e o LuaJIT são muito competitivos e, em muitos casos, superiores ao Skylake. Em quase todos os testes, Falkor provou ser um substituto digno para Broadwell.
A maior vantagem para a Falkor no momento é o baixo consumo de energia. Embora o TDP seja de 120W, durante meus testes esse número nunca excedeu 89W (para testes de avanço). , Skylake Broadwell 160W, TDP 170W.
Como um anúncio. Estes não são apenas servidores virtuais! Estes são VPS (KVM) com unidades dedicadas, que não podem ser piores que servidores dedicados e, na maioria dos casos - melhor!
Fabricamos VPS (KVM) com unidades dedicadas na Holanda e nos EUA (configurações de VPS (KVM) - E5-2650v4 (6 núcleos) / 10GB DDR4 / 240GB SSD ou 4TB HDD / 1Gbps 10TB disponíveis a um preço excepcionalmente baixo - de US $ 29 / mês , opções com RAID1 e RAID10 estão disponíveis) , não perca a chance de fazer um pedido para um novo tipo de servidor virtual, onde todos os recursos pertencem a você, como em um dedicado, e o preço é muito mais baixo, com um hardware muito mais produtivo!
Como construir a infraestrutura do edifício. classe usando servidores Dell R730xd E5-2650 v4 custando 9.000 euros por um centavo? Dell R730xd 2 vezes mais barato? Somente nós temos
2 TVs Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 a partir de US $ 249 na Holanda e nos EUA!