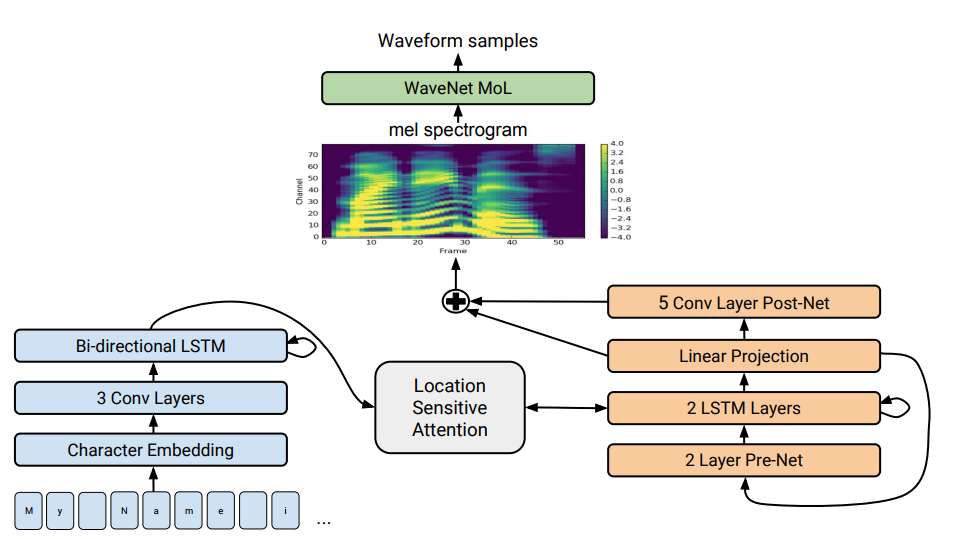
 Arquitetura Tacotron 2. Na parte inferior da ilustração, são mostrados modelos de oferta a oferta que traduzem uma sequência de letras em uma sequência de atributos no espaço 80-dimensional. Para uma descrição técnica, consulte um artigo científico.
Arquitetura Tacotron 2. Na parte inferior da ilustração, são mostrados modelos de oferta a oferta que traduzem uma sequência de letras em uma sequência de atributos no espaço 80-dimensional. Para uma descrição técnica, consulte um artigo científico.A síntese da fala - a reprodução artificial da fala humana a partir de um texto - é tradicionalmente considerada um dos componentes da inteligência artificial. Anteriormente, esses sistemas só podiam ser vistos em filmes de ficção científica, mas agora funcionam literalmente em todos os smartphones: são Siri, Alice e similares. Mas eles não expressam frases muito realistas: voz inanimada, as palavras são separadas umas das outras.
O Google
desenvolveu um sintetizador de fala avançado de última geração. É chamado Tacotron 2 e é baseado em uma rede neural. Para demonstrar suas capacidades, a empresa publicou
exemplos de síntese . Na parte inferior da página, com exemplos, você pode fazer um teste e tentar determinar onde o texto é entregue pelo sintetizador de fala e onde a pessoa está. Determinar a diferença é quase impossível.
Apesar de décadas de pesquisa, a síntese da fala continua sendo uma tarefa urgente para a comunidade científica. Nos últimos anos, diferentes técnicas prevaleceram nessa área: a síntese concatenativa com a escolha de fragmentos foi recentemente considerada a mais avançada - o processo de combinação de pequenos fragmentos sonoros pré-gravados, bem como a síntese paramétrica estatística da fala, na qual o vocoder sintetizou caminhos de pronúncia suave. O segundo método resolveu muitos problemas de síntese concatenativa com artefatos nas fronteiras entre fragmentos. No entanto, em ambos os casos, o som sintetizado parecia distorcido e não natural em comparação com a fala humana.
Depois veio o mecanismo de som WaveNet (um modelo generativo de formas de onda no domínio do tempo), que pela primeira vez foi capaz de mostrar a qualidade do som comparável à humana. Agora é usado no sistema de síntese de
voz Deep Voice 3 .
No início de 2017, o Google introduziu a
arquitetura de oferta a oferta da
Tacotron . Gera espectrogramas de amplitudes a partir de uma sequência de caracteres. O Tacotron simplifica o transportador tradicional de motores de áudio. Aqui, os recursos linguísticos e acústicos são gerados por uma única rede neural treinada apenas em dados. A frase "sentença a sentença" significa que a rede neural estabelece uma correspondência entre uma sequência de letras e uma sequência de atributos para a codificação do som. Os sinais são gerados em um espectrograma de áudio de 80 dimensões com quadros de 12,5 milissegundos.
A rede neural aprende não apenas a pronúncia das palavras, mas também características específicas da voz, como volume, velocidade e entonação.
Então, as ondas sonoras são geradas diretamente usando o algoritmo Griffin-Lim (para estimativa de fase) e a transformada inversa de Fourier a curto prazo. Como os autores observaram, essa era uma solução temporária para demonstrar os recursos da rede neural. De fato, o mecanismo WaveNet e similares criam um som melhor que o algoritmo Griffin-Lim e sem artefatos.
No sistema Tacotron 2 modificado, especialistas do Google ainda conectavam o vocoder WaveNet à rede neural. Assim, a rede neural cria espectrogramas e, em seguida, uma versão modificada do WaveNet gera som a 24 kHz.
A rede neural aprende independentemente (de ponta a ponta) com o som de uma voz humana, acompanhada de texto. Uma rede neural bem treinada lê os textos de tal maneira que é quase impossível distinguir do som da fala humana, como pode ser visto em
exemplos reais .
Os pesquisadores observam que o sistema Deep Voice 3 usa uma abordagem semelhante, mas a qualidade de sua síntese ainda não pode ser comparada à fala humana. Mas o Tacotron 2 pode ver os resultados do teste MOS (Average Opinion Score Score) na tabela.
Há outro sintetizador de fala que também funciona em uma rede neural - esse é o
Char2Wav , mas possui uma arquitetura completamente diferente.
Os cientistas dizem que, em geral, a rede neural funciona bem, mas ainda tem dificuldade em pronunciar algumas palavras complexas (como
decoro ou
merlot ). E, às vezes, produz aleatoriamente ruídos estranhos - as razões para isso agora estão sendo esclarecidas. Além disso, o sistema não é capaz de trabalhar em tempo real e os autores ainda não foram capazes de assumir o controle do mecanismo, ou seja, definir a entonação desejada para ele, por exemplo, uma voz feliz ou triste. Cada um desses problemas é interessante por si só, eles escrevem.
O artigo científico foi
publicado em 16 de dezembro de 2017 no site de pré-impressão arXiv.org (arXiv: 1712.05884v1).