
Nosso dia começa com a frase "Bom dia!". Durante o dia, conversamos com colegas, parentes, amigos e até estranhos que pedem orientações para o metrô mais próximo. Falamos mesmo quando não há ninguém ao nosso redor para perceber melhor nosso próprio raciocínio. Tudo isso é nosso discurso - um presente verdadeiramente incomparável com muitas outras possibilidades do corpo humano. A fala nos permite estabelecer conexões sociais, expressar pensamentos e emoções, nos expressar, por exemplo, em canções.
E assim, carros inteligentes apareceram na vida das pessoas. Uma pessoa, por curiosidade ou com sede de novas conquistas, está tentando ensinar a máquina a falar. Mas, para falar, você precisa ouvir e ouvir. Hoje em dia é difícil se surpreender com um programa (por exemplo, Siri) que reconhece a fala, encontra um restaurante no mapa, liga para a mãe e até conta uma piada. Ela entende muito, não tudo, é claro, mas muito. Mas nem sempre foi assim, naturalmente. Décadas atrás, era para a felicidade, quando uma máquina podia entender pelo menos uma dúzia de palavras.
Hoje, mergulharemos na história de como a humanidade foi capaz de falar com a máquina, que os avanços ao longo dos séculos nessa área serviram de ímpeto para o desenvolvimento da tecnologia de reconhecimento de fala. Também analisamos como os dispositivos modernos percebem e processam nossas vozes. Vamos lá
As origens do reconhecimento de fala
O que é fala? Grosso modo, isso é som. Portanto, para reconhecer a fala, primeiro você precisa reconhecer o som e gravá-lo.
Agora temos iPods, tocadores de MP3, antes de haver gravadores, gramofones e gramofones ainda mais antigos. Estes são todos os dispositivos para reproduzir sons. Mas quem foi o progenitor de todos eles?
 Thomas Edison com sua invenção. 1878 ano
Thomas Edison com sua invenção. 1878 anoEra um fonógrafo. 29 de novembro de 1877, o grande inventor Thomas Edison demonstrou sua nova criação, capaz de gravar e reproduzir sons. Foi um avanço que despertou o maior interesse da sociedade.
O princípio do fonógrafo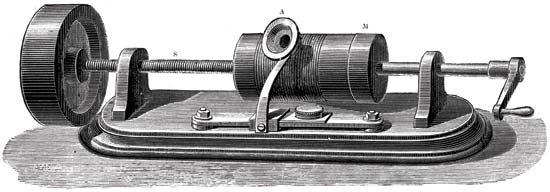
As principais partes do mecanismo de gravação de som eram um cilindro revestido com papel alumínio e uma agulha de corte. A agulha se moveu ao longo de um cilindro que girava. E vibrações mecânicas foram capturadas usando uma membrana de microfone. Como resultado, a agulha deixou marcas na folha. Como resultado, recebemos um cilindro com um registro. Para reproduzi-lo, o mesmo cilindro foi usado inicialmente como durante a gravação. Mas a folha era muito frágil e se esgotou rapidamente, porque os registros duraram pouco. Então eles começaram a aplicar cera, que cobria o cilindro. Para prolongar a existência dos registros, eles começaram a copiar usando galvanoplastia. Através do uso de materiais mais duros, as cópias duraram muito mais tempo.
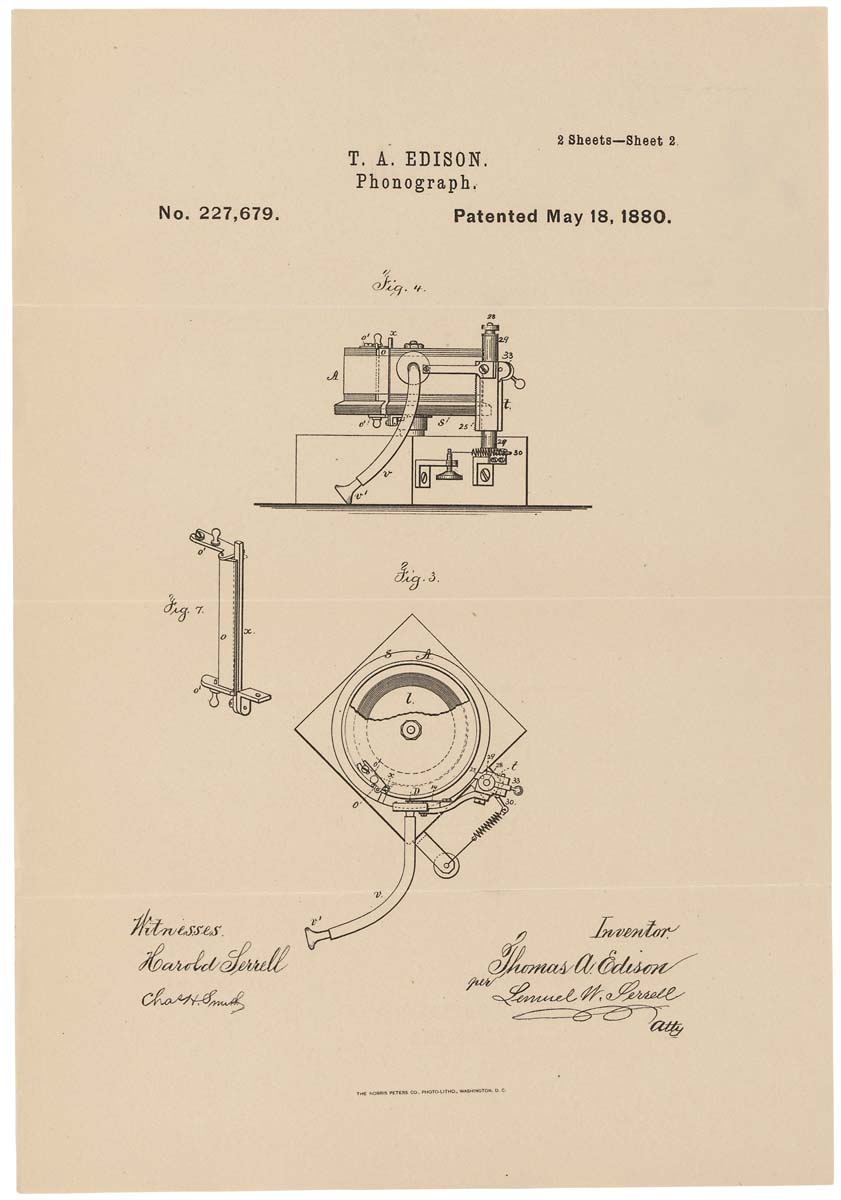 Ilustração esquemática de um fonógrafo em uma patente. 1880, 18 de maio
Ilustração esquemática de um fonógrafo em uma patente. 1880, 18 de maioDadas as desvantagens acima, o fonógrafo, embora fosse uma máquina interessante, mas não foi varrida das prateleiras. Somente com o advento do fonógrafo do disco - mais conhecido como gramofone - chegou o reconhecimento público. A novidade permitiu fazer gravações mais longas (o primeiro fonógrafo podia gravar apenas alguns minutos), o que serviu por muito tempo. E o próprio gramofone estava equipado com um alto-falante que aumentava o volume da reprodução.
Thomas Edison originalmente concebeu o fonógrafo como um dispositivo para gravar conversas telefônicas, como os modernos gravadores de voz. No entanto, sua criação ganhou grande popularidade na reprodução de obras musicais. Tendo servido como o começo para a formação da indústria fonográfica.
Discurso "órgão"
A Bell Labs é famosa por suas invenções no campo das telecomunicações. Uma dessas invenções foi a Voder.
Em 1928, Homer Dudley começou a trabalhar em um vocoder, um dispositivo capaz de sintetizar fala. Falaremos sobre ele mais tarde. Agora vamos considerar sua parte - o vader.
 Ilustração esquemática de um vader
Ilustração esquemática de um vaderO princípio básico do vader era dividir a fala humana em componentes acústicos. A máquina era extremamente complexa e apenas um operador treinado poderia operá-la.
Vader imitou os efeitos do trato vocal humano. Havia dois sons principais que o operador poderia escolher com o pulso. Os pedais foram utilizados para controlar o gerador de oscilações descontínuas (zumbido), criando vogais sonoras e sons nasais. Um tubo de descarga de gás (assobio) criou sibilantes (consoantes fricativas). Todos esses sons passaram por um dos 10 filtros que foram selecionados com as teclas. Também havia teclas especiais para sons como "p" ou "d" e para os africados "j" na palavra "maxilar" e "ch" na palavra "queijo".
Este pequeno trecho da apresentação do vader demonstra claramente o princípio de sua operação e ações do operadorUm operador pode produzir um discurso validamente reconhecível somente após vários meses de prática e treinamento intensos.
Pela primeira vez, a transportadora foi demonstrada em uma exposição em Nova York em 1939.
Salvando através da síntese de fala
Agora considere um vocoder, parte do qual foi o motorista mencionado acima.
 Um dos modelos de vocoder: HY-2 (1961)
Um dos modelos de vocoder: HY-2 (1961)O vocoder foi originalmente planejado para economizar os recursos de frequência dos links de rádio ao transmitir mensagens de voz. Em vez da própria voz, foram transmitidos os valores de seus parâmetros específicos, processados pelo sintetizador de fala na saída.
A base do vocoder era três propriedades principais:
- gerador de ruído (sons consoantes);
- gerador de tons (vogais);
- filtros formais (recriando as características individuais do alto-falante).
Apesar de seu objetivo sério, o vocoder atraiu a atenção de músicos eletrônicos. A conversão do sinal da fonte e a reprodução em outro dispositivo possibilitou a obtenção de diversos efeitos, como o efeito de um instrumento musical cantando em uma "voz humana".
Máquina de contagem
Em 1952, as tecnologias não eram tão avançadas quanto são agora. Mas isso não impediu os cientistas entusiasmados de definir tarefas impossíveis, segundo muitos. Então, cavalheiros Stephen Balashek (S. Balashek), Ralon Biddulf (R. Biddulph) e K.Kh. Davis (KH Davis) decidiu ensinar a máquina a entender seu discurso. Seguindo a ideia, o carro de Audrey surgiu. Suas capacidades eram muito limitadas - ela só conseguia reconhecer números de 0 a 9. Mas isso já era suficiente para declarar com segurança um avanço na tecnologia de computadores.
 Audrey com um de seus criadores (de acordo com a Internet, me corrija se não estiver)
Audrey com um de seus criadores (de acordo com a Internet, me corrija se não estiver)Apesar de suas pequenas capacidades, Audrey não podia se orgulhar das mesmas dimensões. Ela era uma “garota” bastante grande - o gabinete do relé tinha quase 2 metros de altura e todos os elementos ocupavam uma pequena sala. O que não é surpreendente para computadores da época.
O procedimento de interação entre o operador e Audrey também teve algumas condições. O operador falou as palavras (números, neste caso) no monofone de um telefone comum; não deixe de suportar uma pausa de 350 milissegundos entre cada palavra. Audrey aceitou as informações, traduziu-as para o formato eletrônico e acendeu uma lâmpada específica correspondente a um dígito específico. Sem mencionar o fato de que nem todo operador pode obter uma resposta exata. Para alcançar uma precisão de 97%, o operador tinha que ser uma pessoa que praticava conversas com Audrey há muito tempo. Em outras palavras, Audrey entendeu apenas seus criadores.
Mesmo levando em conta todas as deficiências de Audrey, que não estão associadas a erros de design, mas às limitações da tecnologia da época, ela se tornou a primeira estrela no horizonte de máquinas que entendem a voz humana.
O futuro na caixa de sapatos
Em 1961, no IBM Advanced Systems Development Laboratory, um novo dispositivo milagroso foi desenvolvido - o Shoebox, que pode reconhecer 16 palavras (exclusivamente em inglês) e números de 0 a 9. O autor deste computador foi William C. Dersch.
 Shoebox da IBM
Shoebox da IBMO nome incomum correspondia à aparência da máquina, era de tamanho e formato como uma caixa de sapatos. A única coisa que chamou minha atenção foi o microfone, que estava conectado aos três filtros de áudio necessários para reconhecer sons altos, médios e baixos. Os filtros foram conectados a um decodificador lógico (circuito lógico diodo-transistor) e a um mecanismo de interruptor de luz.
O operador levou o microfone à boca e pronunciou uma palavra (por exemplo, número 7). A máquina converteu dados acústicos em sinais eletrônicos. O resultado do entendimento foi a inclusão de uma lâmpada com a assinatura "7". Além de entender palavras individuais, o Shoebox poderia entender problemas aritméticos simples (como 5 + 6 ou 7-3) e dar a resposta certa.
Shoebox foi introduzido por seu criador em 1962 na Seattle World Expo.
Conversa telefônica com o carro
Em 1971, a IBM, conhecida por seu amor por invenções e tecnologias inovadoras, decidiu colocar o reconhecimento de fala em prática. O sistema de identificação automática de chamadas permitiu que um engenheiro localizado em qualquer lugar dos Estados Unidos ligasse para um computador em Raleigh, Carolina do Norte. O chamador pode fazer uma pergunta e receber uma resposta por voz. A singularidade deste sistema estava na compreensão das muitas vozes, dada a sua tonalidade, ênfase, volume de fala, etc.
Harpia voando alto
O Gabinete de Projetos de Pesquisa Avançada do Departamento de Defesa (DARPA) anunciou o lançamento de um programa de pesquisa e desenvolvimento de reconhecimento de fala em 1971, que visa criar uma máquina capaz de reconhecer 1.000 palavras. Um projeto ousado, dado o sucesso de seu antecessor, nas dezenas de palavras. Mas não há limite para a capacidade de recursos humanos. E em 1976, a Universidade Carnegie Mellon demonstra Harpy, capaz de reconhecer 1011 palavras.
Harpy Video DemonstrationA universidade já desenvolveu sistemas de reconhecimento de fala - Hearsay-1 e Dragon. Eles foram usados como base para a implementação do Harpy.
No Hearsay-1, o conhecimento (isto é, um dicionário de máquina) é representado na forma de procedimentos e no Dragon - na forma de uma rede de Markov com uma transição probabilística a priori. Na Harpy, decidiu-se usar o modelo mais recente, mas sem essa transição.
Neste vídeo, o princípio de operação é descrito em mais detalhes.
Simplificando, você pode representar uma rede - uma sequência de palavras e suas combinações, além de sons com uma única palavra, para que a máquina entenda as diferentes pronúncias da mesma palavra.
Harpy entendeu cinco operadores, incluindo três homens e duas mulheres. Isso falou sobre os maiores recursos de computação desta máquina. A precisão do reconhecimento de fala foi de aproximadamente 95%.
Tangora by IBM
No início dos anos 80, a IBM decidiu desenvolver um sistema capaz de reconhecer mais de 20.000 palavras até o meio da década. Assim nasceu Tangora, no trabalho em que modelos ocultos de Markov foram usados. Apesar do vocabulário bastante impressionante, o sistema não exigiu mais de 20 minutos de colaboração com o novo operador (a pessoa que fala) para aprender a reconhecer sua fala.
Boneca viva
Em 1987, a empresa de brinquedos Worlds of Wonder lançou uma novidade revolucionária - uma boneca falante chamada Julie. A característica mais impressionante do brinquedo dinamarquês foi a capacidade de treiná-lo para reconhecer o discurso do proprietário. Julie poderia falar muito bem. Além disso, a boneca estava equipada com muitos sensores, graças aos quais reagiu ao ser apanhada, agradada ou transferida de uma sala escura para uma iluminada.
O comercial de Worlds of Wonder, Julie, mostrando seus recursosSeus olhos e lábios eram móveis, o que criou uma imagem ainda mais animada. Além da boneca em si, foi possível comprar um livro em que figuras e palavras eram feitas na forma de adesivos especiais. Se você segurar os bonecos com os dedos sobre eles, ele expressará o que "sente" ao toque. Doll Julie foi o primeiro dispositivo com uma função de reconhecimento de fala, disponível para qualquer pessoa.
O primeiro software de ditado

Em 1990, a Dragon Systems lançou o primeiro software de computador pessoal baseado no reconhecimento de fala - DragonDictate. O programa funcionou exclusivamente no Windows. O usuário teve que fazer pequenas pausas entre cada palavra para que o programa pudesse analisá-las. No futuro, apareceu uma versão mais perfeita que permite que você fale continuamente - Dragon NaturallySpeaking (é o que está disponível agora, enquanto o DragonDictate original parou de atualizar desde o Windows 98). Apesar de sua "lentidão", o DragonDictate ganhou grande popularidade entre os usuários de PC, especialmente entre as pessoas com deficiência.
Esfinge não egípcia
A Universidade Carnegie Mellon, que já "se acendeu" anteriormente, tornou-se o berço de outro sistema de reconhecimento de fala historicamente importante - a Esfinge 2.
 Criador da Esfinge Xuedong Huang
Criador da Esfinge Xuedong HuangO autor direto do sistema foi Xuedong Huang. Sphinx 2 foi distinguido de seu antecessor por sua velocidade. O sistema estava focado no reconhecimento de fala em tempo real para programas que usam a linguagem falada (todos os dias). Entre os recursos do Sphinx 2 estavam: formação de hipóteses, alternância dinâmica entre modelos de linguagem, detecção de equivalentes etc.
O código Sphinx 2 tem sido usado em muitos produtos comerciais. E em 2000, no site SourceForge, Kevin Lenzo postou o código-fonte do sistema para visualização geral. Aqueles que desejam estudar o código fonte do Sphinx 2 e suas outras variações podem seguir o
link .
Ditado médico
Em 1996, a IBM lançou o MedSpeak, o primeiro produto comercial com reconhecimento de fala. Era para usar esse programa em médicos para compilar registros médicos. Por exemplo, uma radiologista, examinando as fotos da paciente, fez seus comentários, que o sistema MedSpeak traduziu em texto.
Antes de passar para os representantes mais famosos de programas com reconhecimento de fala, vamos analisar rapidamente mais alguns eventos históricos relacionados a essa tecnologia.
Blitz histórico
- 2002 - A Microsoft integra o reconhecimento de fala em todos os seus produtos do Office;
- 2006 - A Agência de Segurança Nacional dos EUA começa a usar programas de reconhecimento de fala para identificar palavras-chave limitadas nos registros de conversas;
- 2007 (30 de janeiro) - A Microsoft lança o Windows Vista - o primeiro sistema operacional com reconhecimento de fala;
- 2007 - O Google apresenta o GOOG-411 - um sistema de encaminhamento de telefone (uma pessoa liga para um número, informa qual organização ou pessoa de que precisa e o sistema os conecta). O sistema funcionou nos EUA e no Canadá;
- 2008 (14 de novembro) - O Google lança a pesquisa por voz em dispositivos móveis para iPhone. Este foi o primeiro uso da tecnologia de reconhecimento de fala em telefones celulares;
E agora chegamos ao período em que muitas pessoas se depararam com a tecnologia de reconhecimento de fala.
Senhoras não brigam
Em 4 de outubro de 2011, a Apple anunciou o Siri, cuja decodificação fala por si mesma - a Interface de interpretação e reconhecimento de fala (ou seja, a Interface de interpretação e reconhecimento de fala).

A história do desenvolvimento da Siri é muito longa (na verdade, possui 40 anos de trabalho) e interessante. O próprio fato de sua existência e ampla funcionalidade é o trabalho conjunto de muitas empresas e universidades. No entanto, não vamos nos concentrar neste produto, porque o artigo não é sobre a Siri, mas sobre o reconhecimento de fala em geral.
A Microsoft não quis se afastar, porque em 2014 (2 de abril) eles anunciaram sua assistente digital virtual Cortana.

A funcionalidade da Cortana é semelhante à do concorrente Siri, com exceção de um sistema mais flexível para configurar o acesso às informações.
Debate sobre Cortana ou Siri. Quem é melhor? " realizados desde a sua aparição no mercado. Como, em geral, e a luta entre usuários de iOS e Android. Mas isso é bom. Os produtos concorrentes, na tentativa de parecerem melhores que seus rivais, fornecerão cada vez mais novas oportunidades, desenvolverão e usarão tecnologias e técnicas mais avançadas na mesma esfera de reconhecimento de fala. Tendo apenas um representante em qualquer campo da tecnologia do consumidor, não há necessidade de falar sobre seu rápido desenvolvimento.
Um pequeno vídeo engraçado da conversa entre Siri e Cortana (obviamente construído, mas não menos engraçado). Atenção!: Neste vídeo há palavrões.
Conversa com carros. Como eles nos entendem?
Como mencionei anteriormente, a grosso modo, a fala é sólida. E qual é o som do carro? Essas são mudanças (flutuações) na pressão do ar, ou seja, ondas sonoras. Para que a máquina (computador ou telefone) possa reconhecer a fala, você deve primeiro considerar essas flutuações. A frequência de medição deve ser pelo menos 8.000 vezes por segundo (ainda melhor - 44.100 vezes por segundo). Se as medições forem realizadas com grandes interrupções de tempo, obteremos um som impreciso, o que significa fala ilegível. O processo descrito acima é conhecido como digitalização de 8kHz ou 44.1kHz.
Quando os dados sobre as vibrações das ondas sonoras são coletados, eles precisam ser classificados. Como na pilha geral, temos sons de fala e secundários (ruído da máquina, farfalhar papel, som de um computador em funcionamento etc.). A condução de operações matemáticas nos permite eliminar precisamente nosso discurso, que precisa de reconhecimento.
A seguir, é apresentada a análise da onda sonora selecionada - a fala. Uma vez que consiste em muitos componentes separados que formam certos sons (por exemplo, "ah" ou "ee"). Destacar esses recursos e convertê-los em equivalentes numéricos permite definir palavras específicas.
, , 40 (44, , 100), .. . , , . . , , «» , ( , , , ..), . , «t» «sTar» «t» «ciTy» -.
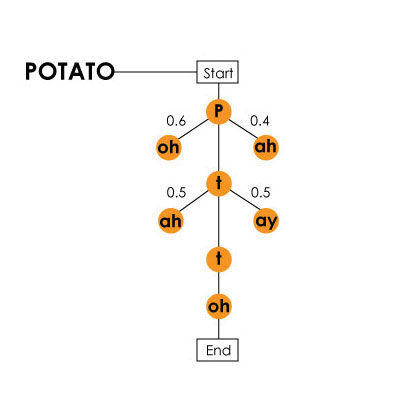 «potato» () / Harpy
«potato» () / Harpy, , . , «hang ten», — «hey, ngten», «ngten».
, , . , (), , №2 №1. «What do cats like for breakfast?» «water gaslight four brick vast?». , . . , , , . .
, . , , .
, . . - , ( , ), . . , , , . , -, , .
. 25% 3 6 !
! VPS (KVM) , , — !
VPS (KVM) c ( VPS (KVM) — E5-2650v4 (6 Cores) / 10GB DDR4 / 240GB SSD 4TB HDD / 1Gbps 10TB — $29 / , RAID1 RAID10) , , , , , «»!
. c Dell R730xd 5-2650 v4 9000 ? Dell R730xd 2 ? 2 Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 $249 !