Exemplo de operação AttnGAN. Na linha superior, há várias imagens de diferentes resoluções geradas por uma rede neural. A segunda e terceira linhas mostram o processamento das cinco palavras mais adequadas por dois modelos de atenção da rede neural para desenhar as seções mais relevantesA criação automática de imagens a partir de descrições de texto em um idioma natural é um problema fundamental para muitos aplicativos, como geração de arte e design de computadores. Esse problema também estimula o progresso no campo do treinamento de IA multimodal com uma relação entre visão e linguagem.
Pesquisas recentes de pesquisadores nessa área são baseadas em redes adversárias generativas (GANs). A abordagem geral é traduzir toda a descrição do texto no vetor de sentença global. Essa abordagem demonstra vários resultados impressionantes, mas tem as principais desvantagens: a falta de detalhes claros no nível da palavra e a incapacidade de gerar imagens de alta resolução. Uma equipe de desenvolvedores da Universidade de Lichai, da Universidade de Rutgers, da Universidade de Duke (todos os EUA) e da Microsoft propôs sua
própria solução para o problema: a nova rede neural
Attentive Generator Adversarial Network (AttnGAN) representa uma melhoria na abordagem tradicional e permite a mudança em vários estágios da imagem gerada, alterando palavras individuais no texto descrição.
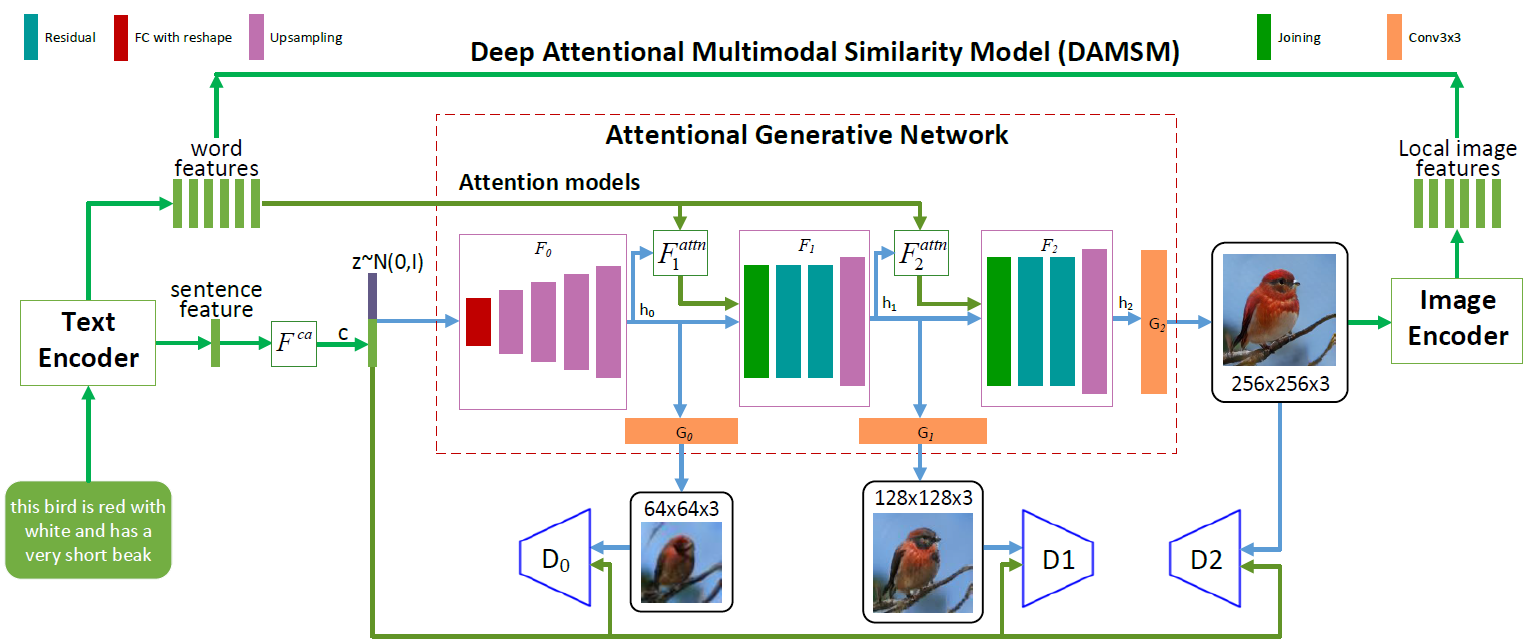 Arquitetura de rede neural AttnGAN. Cada modelo de atenção recebe automaticamente condições (isto é, vetores de vocabulário correspondentes) para gerar diferentes áreas da imagem. O módulo DAMSM fornece granularidade adicional para a função de perda de conformidade na tradução de imagem para texto na rede generativa
Arquitetura de rede neural AttnGAN. Cada modelo de atenção recebe automaticamente condições (isto é, vetores de vocabulário correspondentes) para gerar diferentes áreas da imagem. O módulo DAMSM fornece granularidade adicional para a função de perda de conformidade na tradução de imagem para texto na rede generativaComo você pode ver na ilustração que descreve a arquitetura da rede neural, o modelo AttnGAN tem duas inovações em comparação às abordagens tradicionais.
Em primeiro lugar, é uma rede contraditória, que se refere à atenção como um fator de aprendizado (Rede Adversária Geradora de Atenção). Ou seja, implementa o mecanismo de atenção, que determina as palavras mais adequadas para gerar as partes correspondentes da imagem. Em outras palavras, além de codificar a descrição completa do texto no espaço vetorial global de frases, cada palavra individual também é codificada como um vetor de texto. No primeiro estágio, a rede neural generativa usa o espaço vetorial global de sentenças para renderizar uma imagem de baixa resolução. Nas etapas a seguir, ela usa o vetor de imagem em cada região para consultar vetores de dicionário, usando a camada de atenção para formar o vetor de contexto da palavra. Em seguida, o vetor de imagem regional é combinado com o vetor de contexto de palavras correspondente para formar um vetor de contexto multimodal, com base no qual o modelo gera novos recursos de imagem nas respectivas regiões. Isso permite aumentar efetivamente a resolução de toda a imagem como um todo, pois em cada estágio há mais e mais detalhes.
A segunda inovação de rede neural da Microsoft é o módulo DAMSM (Deep Attention Multimodal Similarity Model). Usando o mecanismo de atenção, este módulo calcula o grau de similaridade entre a imagem gerada e a sentença de texto, usando as informações do nível do espaço vetorial das sentenças e um nível bem detalhado dos vetores do dicionário. Assim, o DAMSM fornece granularidade adicional para a função de perda de ajuste na tradução da imagem para o texto ao treinar o gerador.
Graças a essas duas inovações, a rede neural AttnGAN mostra resultados significativamente melhores que os melhores dos sistemas GAN tradicionais, escrevem os desenvolvedores. Em particular, a pontuação máxima de criação conhecida para redes neurais existentes foi aprimorada em 14,14% (de 3,82 para 4,36) no conjunto de dados CUB e em 170,25% (de 9,58 para 25,89). no conjunto de dados COCO mais sofisticado.
É difícil superestimar a importância desse desenvolvimento. A rede neural AttnGAN mostrou pela primeira vez que uma rede geracional-adversária multicamada, que se refere à atenção como um fator de aprendizado, é capaz de determinar automaticamente condições no nível da palavra para gerar partes individuais de uma imagem.
O artigo científico foi
publicado em 28 de novembro de 2017 no site de pré-impressão arXiv.org (arXiv: 1711.10485v1).