Os desenvolvedores do Google Brain provaram que imagens "conflitantes" podem conter uma pessoa e um computador; e as possíveis consequências são assustadoras.
Na foto acima - à esquerda não há dúvida de um gato. Mas você pode dizer com certeza se o gato está à direita ou apenas um cachorro que se parece com ele? A diferença entre os dois é que o caminho certo é feito usando um algoritmo especial que não fornece modelos de computador chamados "redes neurais convolucionais" (CNNs, rede neural convolucional, a seguir denominada SNA) para concluir inequivocamente isso na imagem. Nesse caso, o SNS acredita que isso é mais um cachorro do que um gato, mas o mais interessante - a maioria das pessoas pensa da mesma maneira.
Este é um exemplo do que é chamado de "imagem contraditória" (doravante denominado KARP): é especialmente modificado para enganar o SNA e impedir que o conteúdo seja identificado corretamente. Os pesquisadores do Google Brain queriam entender se é possível fazer com que as redes neurais biológicas funcionem mal em nossas cabeças da mesma maneira e, como resultado, criaram opções que afetam igualmente carros e pessoas, fazendo-os pensar que estão procurando algo que na verdade não.
O que são imagens conflitantes?
Em quase todos os lugares, para reconhecimento no SNA, são utilizados algoritmos de classificação visual. Ao "mostrar" ao programa um grande número de ilustrações diferentes com os pandas, você pode treiná-lo para reconhecer os pandas, pois ele aprende por comparação, a fim de destacar um recurso comum para todo o conjunto. Assim que o SNA (também chamado de
"classificadores" ) coletar uma variedade suficiente de "sinais de panda" nos dados de treinamento, ele poderá reconhecer o panda em qualquer nova imagem que forneça.
Reconhecemos os pandas por suas características abstratas: pequenas orelhas pretas, grandes cabeças brancas, olhos pretos, pêlo e todo esse jazz. O SNA faz o contrário, o que não é surpreendente, uma vez que a quantidade de informações sobre o ambiente que as pessoas interpretam a cada minuto é muito maior. Portanto, levando em consideração as especificidades dos modelos, é possível influenciar as imagens de maneira a torná-las "inconsistentes", misturando-as com dados cuidadosamente calculados, após o qual o resultado para uma pessoa parecerá quase com o original, mas completamente diferente para o
classificador , que começará a cometer erros ao tentar determinar conteúdo.
Aqui está um exemplo de panda:
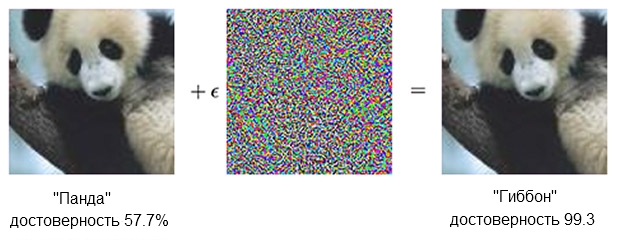 A imagem de um panda, combinada com indignação, pode convencer o classificador de que ele é realmente um gibão.Fonte: OpenAIO classificador
A imagem de um panda, combinada com indignação, pode convencer o classificador de que ele é realmente um gibão.Fonte: OpenAIO classificador baseado no SNA tem certeza de que o panda à esquerda é de cerca de 60%. Mas se você suplementar ("criar indignação") a fonte adicionando algo que parece apenas ruído caótico, o mesmo classificador terá 99,3% de certeza de que agora está olhando o gibão. Pequenas mudanças que não podem ser vistas com clareza dão origem a um ataque muito bem-sucedido, mas funcionará apenas em um modelo de computador específico e não executará aquelas que poderiam ser "aprendidas" em outra coisa.
Para criar conteúdo que provoque uma reação errada entre um grande e diversificado número de analistas artificiais, deve-se agir com mais grosseria - pequenas correções não afetarão. O que funciona de maneira confiável não pode ser feito com "pequenos meios". Em outras palavras, se você deseja que o conteúdo funcione de todos os ângulos e distâncias, é necessário intervir de forma mais significativa ou, como alguém diria, mais óbvio.
À vista - um homem
Aqui estão dois exemplos de Carp rudes, onde uma pessoa pode detectar facilmente interferências.
 Fonte: IA aberta à esquerda, Google Brain à direita
Fonte: IA aberta à esquerda, Google Brain à direitaA imagem do gato à esquerda, que o SNS é definido como um computador, foi feita usando "geometria quebrada". Se você olhar mais de perto (ou mesmo não estiver muito próximo), verá que existem várias estruturas angulares e em forma de caixa que podem se parecer com a forma de uma unidade de sistema. E a imagem da banana à direita, que é reconhecida como uma torradeira, dá constantemente um falso positivo de qualquer ponto de vista. No momento, as pessoas encontrarão uma banana aqui, no entanto, uma engenhoca estranha ao lado dela tem alguns sinais de uma torradeira - e isso faz com que seja um tolo em tecnologia.
Quando você cria uma imagem “contraditória” adequada e garantida de que precisa vencer uma empresa inteira de modelos reconhecedores, isso muitas vezes leva ao aparecimento de um “fator humano”. Em outras palavras, o que confunde uma única rede neural pode não ser percebida como um problema, e quando você tenta obter um rebus definitivamente adequado para enganar cinco ou dez de uma vez, verifica-se que funciona com base em mecanismos que, se as pessoas são completamente inúteis.
Como resultado, não há absolutamente nenhuma necessidade de tentar forçar uma pessoa a acreditar que um gato angular é um gabinete de computador, e a soma de uma banana e uma mancha estranha parece uma torradeira. É muito melhor, ao criar CARPs projetados para você e eu, focar imediatamente no uso de modelos que percebem o mundo como as pessoas.
Enganando o olho (e o cérebro)
O SNA com treinamento profundo e visão humana é um pouco semelhante, mas basicamente a rede neural "olha" as coisas "de maneira semelhante ao computador". Por exemplo, quando ela recebe uma imagem, ela "vê" uma grade estática de pixels retangulares ao mesmo tempo. O olho funciona de maneira diferente, uma pessoa percebe detalhes altos em um setor de cerca de cinco graus em cada lado da linha de visão, mas fora dessa zona, a atenção aos detalhes diminui linearmente.
Assim, diferentemente de uma máquina, digamos, desfocar as bordas de uma imagem não funcionará com uma pessoa e simplesmente passará despercebido. Os pesquisadores foram capazes de simular esse recurso adicionando uma "camada de retina" que alterava os dados fornecidos pelo SNA para a aparência do olho, com o objetivo de limitar a rede neural ao mesmo quadro da visão normal.
Note-se que uma pessoa lida com suas deficiências de percepção pelo fato de o olhar não ser direcionado para um ponto, mas se mover constantemente, examinando toda a imagem, mas também foi possível compensar as condições do experimento, nivelando as diferenças entre o SNA e as pessoas.
Nota do próprio trabalho:
Cada experimento começou com uma mira de instalação, que apareceu no centro da tela por 500-1000 milissegundos, e cada sujeito foi instruído a fixar o olhar na mira.O uso da "camada retiniana" foi o último passo a ser adotado como parte de um "ajuste fino" do aprendizado de máquina para "características humanas". Durante a geração das amostras, eles foram conduzidos através de dez modelos diferentes, cada um dos quais deveria ter chamado claramente, digamos, um gato, por exemplo, um cachorro. Se o resultado foi "10 em 10 estavam equivocados", o material foi submetido a teste em seres humanos.
Isso funciona?
Três grupos de fotos foram envolvidos no experimento: “animais de estimação” (cães e gatos), “vegetais” (abobrinha e brócolis) e “ameaças” (aranhas e cobras, embora, como proprietário da cobra, eu sugerisse um termo diferente para avaliação). Para cada grupo, o sucesso era contado se a pessoa escolhida escolhesse a coisa errada - chamava o cachorro de gato e vice-versa. Os participantes sentaram-se em frente a um monitor que exibia uma imagem por cerca de 60 ou 70 milissegundos e precisaram pressionar um dos dois botões para indicar o objeto. Como a imagem foi mostrada por um período muito curto, isso suavizou a diferença entre como as pessoas e as redes neurais percebem o mundo; a ilustração no título, aliás, é impressionante em sua persistência de erro.
O que os sujeitos mostraram pode ser uma imagem não modificada (imagem), um CarP "comum" (adv), um CarP "invertido" (flip), no qual o ruído foi virado de cabeça para baixo antes da aplicação ou um CarP "falso", no qual uma camada com foi aplicado ruído a uma imagem que não pertence a nenhum dos tipos do grupo (falso). As duas últimas opções foram usadas para controlar a natureza da perturbação (a estrutura do ruído afetará de outra forma de cabeça para baixo, ou simplesmente "não comer?"). Além disso, elas possibilitaram entender se a interferência engana completamente as pessoas ou apenas reduz um pouco a precisão.
Nota do próprio trabalho:
Falso: uma condição foi adicionada para forçar o sujeito a cometer um erro. Nós o adicionamos, porque se as alterações iniciais reduzirem a precisão do observador, isso pode ser devido a uma diminuição na qualidade da imagem direta. Para mostrar que os CARPs realmente funcionam em cada classe, introduzimos opções em que nenhuma opção poderia estar correta e sua precisão era 0, e observamos exatamente qual era a resposta "certa" nesse caso. Demonstramos imagens arbitrárias do ImageNet, que foram afetadas por uma ou outra classe do grupo, mas não se encaixavam em nenhuma delas. O participante do experimento teve que determinar o que estava à sua frente. Por exemplo, poderíamos mostrar uma imagem de um avião distorcida aplicando ruído de "cachorro", embora durante o experimento o sujeito devesse ter reconhecido apenas um gato ou um cachorro.Aqui está um exemplo mostrando uma porcentagem do número de pessoas que foram capazes de identificar claramente uma imagem como um cachorro, dependendo de como o ruído foi usado. Deixe-me lembrá-lo, foram apenas 60 a 70 milissegundos para dar uma olhada e tomar uma decisão.
 Fonte: Google Brain
Fonte: Google Brain
Foto original com um cachorro; Carpa com um cachorro, aceito por um homem e um computador como gato; controle a imagem com uma camada de ruído virada de cabeça para baixo.E aqui estão os resultados finais:
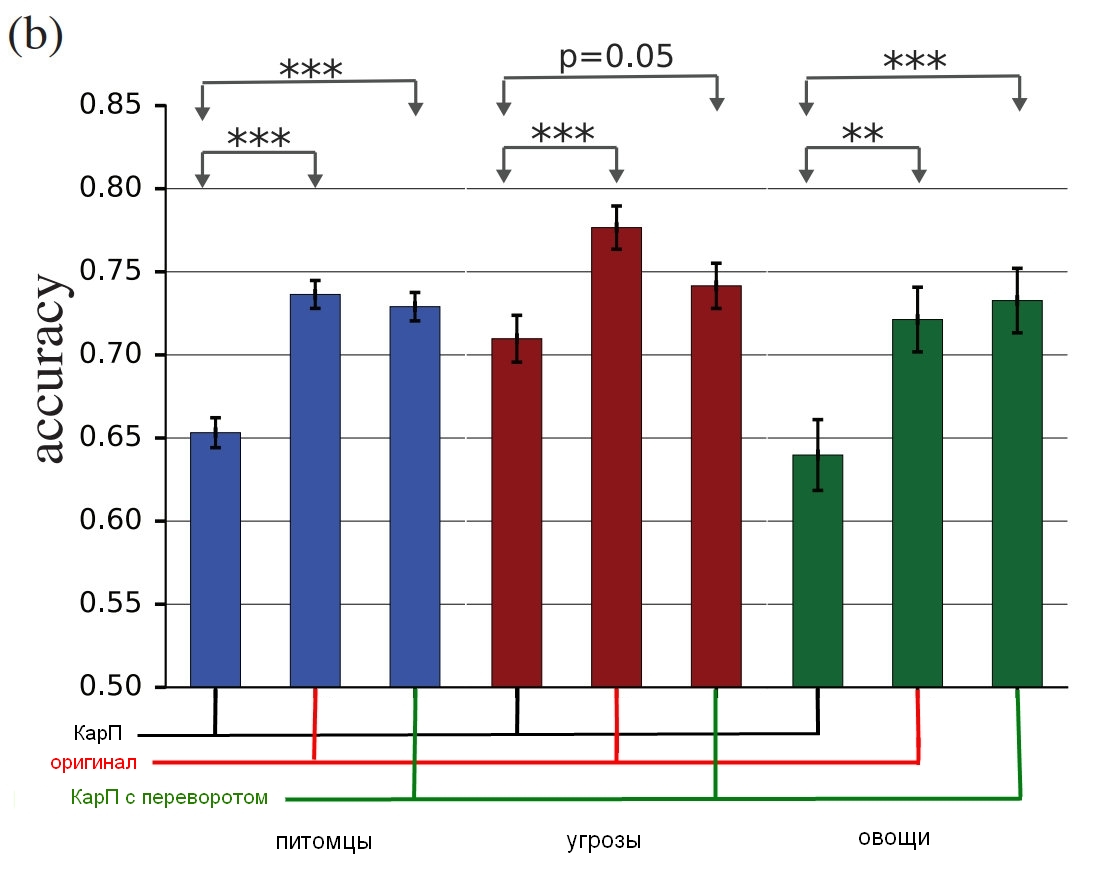 Fonte: Google Brain
Fonte: Google Brain
Os resultados do estudo, como as pessoas verdadeiras identificam essas imagens em comparação com as distorcidas.O gráfico mostra a precisão da partida. Se você escolhe um gato e ele realmente é um gato, a precisão aumenta. Se você escolhe um gato, mas na verdade é um cachorro, transformado por ruído em uma espécie de gato, a precisão é reduzida.
Como você pode ver, as pessoas são muito mais corretas na seleção de imagens não corrigidas ou com camadas de ruído invertidas do que na seleção de imagens "inconsistentes". Isso prova que o princípio do ataque à percepção pode ser transferido dos computadores para nós.
Os impactos não apenas são inegavelmente eficazes, como também são mais finos do que o esperado - sem gatos box ou pseudo-torradeiras, ou algo assim. Como vimos ambas as camadas com ruído e imagens antes e após o processamento, precisamos descobrir o que exatamente nos confunde nisso. Embora os pesquisadores sejam cautelosos, afirmando que "nossos exemplos são feitos especialmente para enganar a cabeça, então você deve ter cuidado ao usar pessoas como experimentais para estudar o efeito".
No futuro, a equipe tentará derivar algumas regras gerais para certas categorias de modificação, incluindo “
destruição das bordas de um objeto , especialmente por impactos médios, perpendiculares à linha da borda;
correção de áreas limítrofes aumentando o contraste enquanto texturiza a borda;
alterando a textura ;
usando partes escuras "imagens nas quais o nível de impacto na percepção é alto, apesar de pequenos distúrbios". A seguir, são apresentados exemplos de áreas circuladas em vermelho nas quais os métodos descritos são mais bem visualizados.
 Fonte: Google Brain
Fonte: Google Brain
Exemplos de imagens com diferentes princípios de distorçãoQual é o resultado?
A linha inferior é que isso é mais, muito mais do que apenas um truque inteligente. Os caras do Google Brain confirmaram que podem criar uma técnica eficaz de engano, mas não entendem completamente por que isso funciona, levando em consideração o nível de abstração, e é possível que este seja literalmente um nível básico de realidade:
Nosso projeto levanta questões fundamentais sobre como as CARPs funcionam, como as redes neurais e o cérebro funcionam. Você conseguiu transferir ataques do SNA para o cérebro porque as representações semânticas das informações nelas são semelhantes? Ou porque ambas as representações correspondem a um certo modelo semântico geral, que existe naturalmente no mundo circundante?
Concluindo, se você realmente quer ficar um pouco paranóico, os pesquisadores ficam felizes em fazer um favor, apontando que “o reconhecimento visual dos objetos ... é difícil fazer uma avaliação objetiva. A “Fig. 1” é objetivamente verdadeira em um cão ou é um gato objetivo que pode fazer as pessoas pensarem que é um cachorro? ” Em outras palavras, a imagem realmente se transforma em um objeto ou apenas faz você pensar de maneira diferente?
É assustador aqui (e eu digo seriamente "assustador") que, no final, você pode encontrar maneiras de influenciar qualquer fato, porque a distância entre manipular o SNA e manipular uma pessoa obviamente não é muito grande. Consequentemente, as tecnologias de aprendizado de máquina podem potencialmente ser usadas para distorcer imagens ou vídeos da maneira correta, o que substituirá nossa percepção (e a reação correspondente), e nem entenderemos o que aconteceu. Do relatório:
Por exemplo, um conjunto de modelos com treinamento aprofundado pode ser treinado nas avaliações das pessoas sobre o nível de confiança em certos tipos de pessoas, características, expressões. Tornar-se-á possível gerar indignações “conflitantes” que aumentarão ou diminuirão o sentimento de “credibilidade”, e esses materiais “aprimorados” podem ser usados em clipes de notícias ou publicidade política.
No futuro, os riscos teóricos incluem a possibilidade de criar estímulos sensoriais que invadem o cérebro de várias formas e com eficiência muito alta. Como você sabe, muitos animais são vistos como vulneráveis a estímulos acima do limite. Digamos que os cucos possam simultaneamente fingir estar desamparados e fazer uma ligação melancólica, o que, em conjunto, faz com que pássaros de outras raças alimentem filhotes de cuco antes de seus próprios filhos. Amostras "conflitantes" podem ser consideradas como uma forma peculiar de estimulação de super limiar para redes neurais. E o fato de que estímulos excessivos, que em teoria têm muito mais probabilidade de afetar uma pessoa do que apenas fazê-la pendurar uma etiqueta "um gato" na imagem de um cachorro, estão causando uma preocupação considerável, podem ser criados usando uma máquina e depois transferidos para as pessoas.
Certamente, esses métodos podem ser usados “para o bem”, e várias opções já foram propostas, como “aprimorar as características das imagens para aumentar o nível de concentração, por exemplo, ao controlar a situação do ar ou analisar imagens de raios-X, já que este trabalho é monótono e as consequências descuido pode ser terrível. " Além disso, "os designers de interface do usuário podem usar perturbações para desenvolver interfaces mais intuitivas". Hummm. Certamente é ótimo, mas de alguma forma estou mais preocupado com a questão de invadir meu cérebro e definir o nível de confiança nas pessoas, sabe?
Algumas das questões colocadas serão objeto de pesquisas futuras - pode-se descobrir o que exatamente torna as imagens específicas mais adequadas para transmitir um erro a uma pessoa, e isso pode fornecer novas pistas para a compreensão dos princípios do cérebro. E isso, por sua vez, ajudará a criar redes neurais mais avançadas que aprenderão mais rápido e melhor. Mas devemos ter cuidado e lembrar que, como computadores, às vezes não é tão difícil nos enganar.
O projeto
" Exemplos Adversários que Enganam a Visão Humana e a Computador , de Gamaleldin F. Elsayed, Shreya Shankar, Brian Cheung, Nicolas Papernot, Alex Kurakin, Ian Goodfellow e Jascha Sohl-Dickstein, do Google Brain" , pode ser baixado do
arXiv . E se você precisar de fotos mais controversas que funcionem com as pessoas, o material de apoio está
aqui .