
O Instagram possui um dos maiores bancos de dados do Apache Cassandra no mundo. O projeto começou a usar o Cassandra em 2012 para substituir o Redis e dar suporte à implementação de recursos de aplicativos como um sistema de reconhecimento de fraude, Tape e Direct. No início, os clusters Cassandra trabalhavam na AWS, mas depois os engenheiros os migraram para a infraestrutura do Facebook, juntamente com todos os outros sistemas do Instagram. Cassandra teve um desempenho muito bom em termos de confiabilidade e tolerância a falhas. Ao mesmo tempo, as métricas de latência ao ler dados podem claramente ser aprimoradas.
No ano passado, a equipe de suporte ao Instagram de Cassandra começou a trabalhar em um projeto destinado a reduzir significativamente a latência na leitura de dados no Cassandra, que os engenheiros chamavam de Rocksandra. Neste artigo, o autor conta o que levou a equipe a implementar esse projeto, as dificuldades que precisavam ser superadas e as métricas de desempenho que os engenheiros usam nos ambientes de nuvem internos e externos.
Motivos para a transição
O Instagram usa ativamente e amplamente o Apache Cassandra como um serviço de armazenamento de valor-chave. A maioria das solicitações do Instagram acontece on-line, portanto, para fornecer uma experiência de usuário confiável e agradável para centenas de milhões de usuários do Instagram, os SLAs são muito exigentes no desempenho do sistema.
O Instagram adere a uma classificação de confiabilidade de cinco a nove. Isso significa que o número de falhas em um determinado momento não pode exceder 0,001%. Para melhorar o desempenho, os engenheiros monitoram ativamente a taxa de transferência e latências de vários clusters Cassandra e garantem que 99% de todas as solicitações se ajustem a um determinado indicador (atraso P99).
Abaixo está um gráfico que mostra o atraso de um dos clusters de combate do Cassandra no lado do cliente. Azul indica a velocidade média de leitura (5 ms) e laranja indica a velocidade de leitura para 99%, variando de 25 a 60 ms. Suas alterações são altamente dependentes do tráfego do cliente.
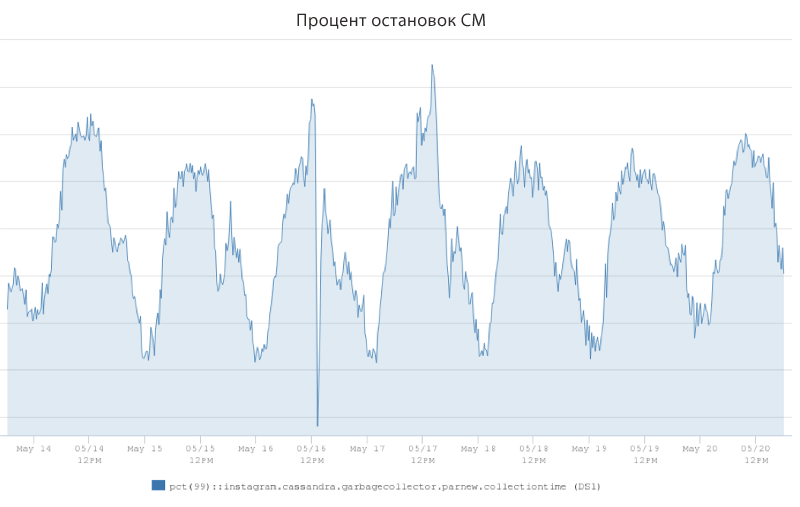

O estudo constatou que as fortes explosões de atraso se devem em grande parte ao trabalho do coletor de lixo da JVM. Os engenheiros introduziram uma métrica chamada "porcentagem de paradas para SM" para medir a porcentagem de tempo gasto em "parar o mundo" pelo servidor Cassandra e foi acompanhada por uma negação de serviço para solicitações de clientes. Aqui está o gráfico acima, mostrando a quantidade de tempo (em porcentagem) que foi parar no SM, usando o exemplo de um dos servidores de combate Cassandra. O indicador variou de 1,25% nos horários de menor tráfego a 2,5% nos horários de pico de carga.
O gráfico mostra que esta instância do servidor Cassandra pode gastar 2,5% do seu tempo coletando lixo em vez de atender solicitações do cliente. As operações preventivas do coletor obviamente tiveram um impacto significativo no atraso do P99 e, portanto, ficou claro que, se pudéssemos reduzir a taxa de parada do CM, os engenheiros poderiam reduzir significativamente a taxa de atraso do P99.
Solução
O Apache Cassandra é um banco de dados distribuído baseado em Java com seu próprio mecanismo de armazenamento de dados baseado em árvores LSM. Os engenheiros descobriram que os componentes do mecanismo, como uma tabela de memória, ferramenta de compactação, caminhos de leitura / gravação e alguns outros, criaram muitos objetos na memória dinâmica Java, o que levou a JVM a executar muitas operações aéreas adicionais. Para reduzir o impacto dos mecanismos de armazenamento no trabalho do coletor de lixo, a equipe de suporte considerou várias abordagens e finalmente decidiu desenvolver um mecanismo C ++ e substituir o existente por ele.
Os engenheiros não queriam fazer tudo do zero e, portanto, decidiram usar o RocksDB como base.
O RocksDB é um banco de dados incorporado de código aberto de alto desempenho para armazenamento de valores-chave. Ele é escrito em C ++ e sua API possui ligações de idioma oficiais para C ++, C e Java. O RocksDB é otimizado para alto desempenho, especialmente em unidades rápidas, como SSDs. É amplamente utilizado na indústria como um mecanismo de armazenamento para MySQL, mongoDB e outros bancos de dados populares.
Dificuldades
No processo de implementação do novo mecanismo de armazenamento no RocksDB, os engenheiros enfrentaram três tarefas difíceis e as resolveram.
A primeira dificuldade foi que o Cassandra ainda carece de uma arquitetura que permita a conexão de processadores de dados de terceiros. Isso significa que o trabalho do mecanismo existente está bastante interconectado com outros componentes do banco de dados. Para encontrar um equilíbrio entre refatoração em larga escala e iterações rápidas, os engenheiros definiram a API do novo mecanismo, incluindo as interfaces mais comuns de leitura, gravação e fluxo. Assim, a equipe de suporte conseguiu implementar novos mecanismos de processamento de dados para a API e inseri-los nos caminhos de execução de código apropriados no Cassandra.
A segunda dificuldade foi que Cassandra suportou tipos de dados estruturados e esquemas de tabela, enquanto o RocksDB apenas forneceu interfaces de valor-chave. Os engenheiros definiram cuidadosamente os algoritmos de codificação e decodificação para dar suporte ao modelo de dados Cassandra como parte das estruturas de dados RocksDB e garantiram a continuidade da semântica de consultas semelhantes entre os dois bancos de dados.
A terceira dificuldade foi associada a um componente tão importante para qualquer componente de banco de dados distribuído como trabalhar com fluxos de dados. Sempre que um nó é adicionado ou removido de um cluster Cassandra, ele precisa distribuir corretamente os dados entre nós diferentes para equilibrar a carga no cluster. As implementações existentes desses mecanismos foram baseadas na obtenção de dados detalhados do mecanismo de banco de dados existente. Portanto, os engenheiros tiveram que separá-los um do outro, criar uma camada de abstração e implementar uma nova opção para processar fluxos usando a API RocksDB. Para obter alta taxa de transferência de fluxos, a equipe de suporte agora distribui os dados em arquivos sst temporários e depois usa a API RocksDB especial para "engolir" os arquivos, permitindo que eles sejam carregados simultaneamente na instância do RocksDB.
Indicadores de desempenho
Após quase um ano de desenvolvimento e teste, os engenheiros concluíram a primeira versão da implementação e a lançaram com sucesso em vários clusters do Instagram Instagram Cassandra. Em um dos clusters de combate, o atraso do P99 caiu de 60 ms para 20 ms. As observações também mostraram que as paradas de SM nesse cluster caíram de 2,5% para 0,3%, ou seja, quase 10 vezes!
Os engenheiros também queriam verificar se o Rocksandra poderia ter um bom desempenho em um ambiente de nuvem pública. A equipe de suporte configurou um cluster Cassandra na AWS usando três instâncias i2.8 xlarge EC2, cada uma com um processador de 32 núcleos, 244 GB de RAM e um ataque zero a quatro unidades flash NVMe.
Para testes comparativos, usamos o
NDBench e o esquema de tabela padrão da estrutura.
TABLE emp ( emp_uname text PRIMARY KEY, emp_dept text, emp_first text, emp_last text )
Os engenheiros pré-carregaram 250 milhões de 6 linhas de 6 KB cada (aproximadamente 500 GB de dados são armazenados em cada servidor). Em seguida, configure 128 leitores e gravadores no NDBench.
A equipe de suporte testou várias cargas e mediu as latências médias / P99 / P999 de leitura e gravação. Os gráficos abaixo mostram que o Rocksandra mostrou latências de leitura e gravação significativamente mais baixas e mais estáveis.


Os engenheiros também verificaram a carga no modo de leitura sem escrever e descobriram que, com o mesmo atraso de leitura P99 (2 ms), o Rocksandra é capaz de fornecer um aumento de mais de 10 vezes na velocidade de leitura de informações (300 K / s para Rocksandra versus 30 K / s para C * 3.0).


Planos futuros
A equipe de suporte do Instagram abriu o código e a
estrutura do
Rocksandra para avaliar o desempenho . Você pode baixá-los no Github e tentar em seu próprio ambiente. Não deixe de nos contar o que aconteceu!
Como próxima etapa, a equipe está trabalhando ativamente para adicionar um suporte mais amplo à funcionalidade C *, como índices secundários, correções e muito mais. Além disso, os engenheiros estão desenvolvendo a
arquitetura do mecanismo de banco de dados de plug-in em C * para transferir ainda mais esses desenvolvimentos para a comunidade Apache Cassandra.
