Olá Habr! Por fim, esperamos por outra parte da série de materiais da pós-graduação de nossos programas de
Big Data Specialist e
Deep Learning , Cyril Danilyuk, sobre o uso do Mask R-CNN, as redes neurais atualmente populares, como parte de um sistema de classificação de imagens, a saber avaliar a qualidade de um prato preparado usando um conjunto de dados de sensores.
Depois de examinar o conjunto de dados de brinquedos que consiste em imagens de sinais de trânsito no
artigo anterior , podemos agora resolver o problema que eu enfrentei na vida real:
“É possível implementar o algoritmo Deep Learning, que poderia distinguir pratos de alta qualidade de pratos ruins, um de cada vez? fotos? " . Em suma, a empresa queria o seguinte:
O que uma empresa representa quando pensa em aprendizado de máquina:Este é um exemplo de um problema incorreto: nesse caso, é impossível determinar se existe uma solução, se é única e estável. Além disso, a declaração do problema em si é muito vaga, sem mencionar a implementação de sua solução. Obviamente, este artigo não é dedicado à eficácia das comunicações ou do gerenciamento de projetos, mas é importante observar:
nunca assuma projetos nos quais o resultado final não esteja definido e registrado na declaração de trabalho. Uma das maneiras mais confiáveis de lidar com essa incerteza é primeiro construir um protótipo e, em seguida, usando novos conhecimentos, estruturar o restante da tarefa. Foi o que fizemos.
Declaração do problema
No meu protótipo, concentrei-me em um prato do menu - uma omelete - e construí um pipeline escalável, que determina a "qualidade" da omelete na saída. Isso pode ser descrito em mais detalhes da seguinte maneira:
- Tipo de problema: classificação em várias classes com 6 classes discretas de qualidade: boa (boa), gema quebrada (com gema que se espalha), assada demais ( cozida demais), dois ovos (dois ovos), quatro ovos (quatro ovos), peças mal colocadas (com peças espalhadas em um prato) .
- Conjunto de dados: 351 fotografias coletadas manualmente de várias omeletes. Amostras de treinamento / validação / teste: 139/32/180 fotos mistas.
- Etiquetas de classe: cada foto corresponde a uma etiqueta de classe correspondente a uma avaliação subjetiva da qualidade da omelete.
- Métrica: entropia cruzada categórica.
- Conhecimento mínimo do domínio: uma omelete de “qualidade” deve ter a seguinte aparência: consiste em três ovos, uma pequena quantidade de bacon, uma folha de salsa no centro, não tem gemas espalhadas nem pedaços cozidos demais. Além disso, a composição geral deve "parecer boa", ou seja, as peças não devem estar espalhadas por todo o prato.
- Critério de conclusão: o melhor valor de entropia cruzada na amostra de teste entre todos os possíveis após duas semanas de desenvolvimento do protótipo.
- O método de visualização final: t-SNE no espaço de dados de uma dimensão menor.
 Imagens de entrada
Imagens de entradaO principal objetivo do pipeline é aprender a combinar vários tipos de sinais (por exemplo, imagens de diferentes ângulos, um mapa de calor, etc.), tendo recebido uma representação pré-compactada de cada um deles e passando esses recursos pelo classificador de rede neural para a previsão final. Assim, podemos realizar nosso protótipo e torná-lo praticamente aplicável em outros trabalhos. Abaixo estão alguns dos sinais usados no protótipo:
- Máscaras dos principais ingredientes (Máscara R-CNN): Sinal nº 1 .
- O número de ingredientes principais no quadro., Número do sinal 2 .
- Colheita RGB de pratos com omelete sem fundo. Por uma questão de simplicidade, decidi não adicioná-los ao modelo ainda, embora sejam o sinal mais óbvio: no futuro, você pode treinar a rede neural convolucional para classificação usando alguma função adequada de perda de trigêmeos , calcular incorporação de imagens e cortar a distância L2 da corrente Imagens para aperfeiçoar. Infelizmente, não tive a oportunidade de testar essa hipótese, pois a amostra de teste consistia em apenas 139 objetos.
Vista geral do gasoduto
Observo que terei que pular algumas etapas importantes, como análise exploratória de dados, construção de um classificador básico e rotulagem ativa (meu termo proposto, que significa anotação semi-automática de objetos, inspirada no pipeline de
demonstração Polygon-RNN ) para o Mask R-CNN (mais sobre isso nas próximas postagens).
Dê uma olhada em todo o pipeline em geral:
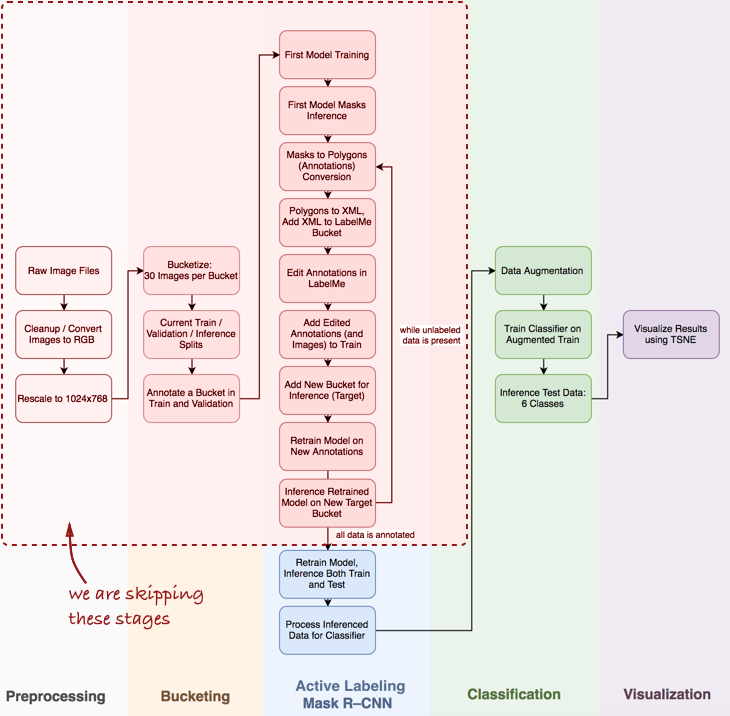 Neste artigo, estamos interessados nos estágios do Mask R-CNN e na classificação dentro do pipeline.
Neste artigo, estamos interessados nos estágios do Mask R-CNN e na classificação dentro do pipeline.A seguir, consideraremos três etapas: 1) usando o Mask R-CNN para criar máscaras de ingredientes para omeletes; 2) classificador ConvNet baseado em Keras; 3) visualização dos resultados usando t-SNE.
Etapa 1: mascarar o R-CNN e as máscaras de construção
A máscara R-CNN (MRCNN) esteve recentemente no auge da popularidade. A partir do
artigo original do
Facebook e terminando com o
Data Science Bowl 2018 no Kaggle, o Mask R-CNN se estabeleceu como uma arquitetura poderosa para a segmentação de instância (ou seja, não apenas a segmentação de imagem pixel por pixel, mas também a separação de vários objetos pertencentes à mesma classe ) Além disso, é um prazer trabalhar com a
implementação do MRCNN da Matterport em Keras. O código é bem estruturado, possui boa documentação e funciona imediatamente, embora mais lentamente do que o esperado.
Na prática, especialmente no desenvolvimento de um protótipo, é fundamental ter uma rede neural convolucional pré-treinada. Na maioria dos casos, o conjunto de dados marcado pelo cientista de dados é muito limitado ou não existe, enquanto o ConvNet exige muitos dados marcados para obter convergência (por exemplo, o conjunto de dados ImageNet contém 1,2 milhão de imagens marcadas). Aqui, a
transferência de aprendizado vem ao resgate: podemos fixar o peso das camadas convolucionais e treinar apenas o classificador. A correção de camadas convolucionais é importante para pequenos conjuntos de dados, pois essa técnica impede a reciclagem.
Aqui está o que eu recebi após a primeira era de reciclagem:
 Resultado da segmentação de objetos: todos os principais ingredientes reconhecidos
Resultado da segmentação de objetos: todos os principais ingredientes reconhecidosNo próximo estágio do pipeline (
Process Inferenced Data for Classifier ), é necessário cortar a parte da imagem que contém a placa e extrair a máscara binária bidimensional de cada ingrediente nesta placa:
 Imagem recortada com os principais ingredientes em forma de máscaras binárias.
Imagem recortada com os principais ingredientes em forma de máscaras binárias.Essas máscaras binárias são então combinadas em uma imagem de 8 canais (desde que eu defini 8 classes de máscara para MRCNN) e obtemos o
sinal número 1 :
 Sinal nº 1 : imagem de 8 canais composta por máscaras binárias. Em cores para melhor visualização.
Sinal nº 1 : imagem de 8 canais composta por máscaras binárias. Em cores para melhor visualização.Para obter o
sinal número 2 , contei o número de vezes que cada ingrediente é encontrado na colheita do prato e obtive um conjunto de vetores de características, cada um dos quais corresponde à sua colheita.
Etapa 2: Classificador ConvNet em Keras
O classificador CNN foi implementado do zero usando Keras. Eu queria combinar vários sinais (
sinal número 1 e
sinal número 2 , bem como a possível adição de dados no futuro) e deixar que as redes neurais os usassem para fazer previsões sobre a qualidade do prato. A arquitetura apresentada abaixo é experimental e longe do ideal:

Algumas palavras sobre a arquitetura do classificador:
- Módulo convolucional em várias escalas : inicialmente escolhi um filtro 5x5 para camadas convolucionais, mas isso só levou a um resultado satisfatório. As melhorias foram obtidas aplicando o AveragePooling2D em várias camadas com filtros diferentes: 3x3, 5x5, 7x7, 11x11. Uma camada convolucional 1x1 adicional foi adicionada na frente de cada uma das camadas para reduzir a dimensão. Esse componente é um pouco como um módulo de iniciação , embora eu não planejasse construir uma rede muito profunda.
- Filtros maiores : usei filtros maiores, porque ajudam a extrair facilmente sinais maiores da imagem de entrada (que em si é essencialmente uma camada de ativação com 8 filtros - a máscara de cada ingrediente pode ser considerada como um filtro separado).
- Combinando sinais : na minha implementação ingênua, apenas uma camada foi usada para conectar dois conjuntos de atributos: máscaras binárias processadas ( sinal nº 1 ) e ingredientes contados ( sinal nº 2 ). No entanto, apesar de sua simplicidade, a adição do Sinal No. 2 tornou possível reduzir a métrica de entropia cruzada de 0,8 para [0,7, 0,72] .
- Logits : em termos de TensorFlow, logit é uma camada na qual tf.nn.softmax_cross_entropy_with_logits é aplicado para calcular a perda de lotes .
Etapa 3: visualização dos resultados usando t-SNE
Para visualizar os resultados do classificador nos dados de teste, usei o t-SNE - um algoritmo que permite transferir os dados de origem para um espaço de menor dimensão (para entender o princípio do algoritmo, recomendo a leitura
do artigo original , é extremamente informativo e bem escrito).
Antes da visualização, tirei imagens de teste, extraí a camada de logite do classificador e apliquei o algoritmo t-SNE nesse conjunto de dados. Embora eu não tenha tentado valores diferentes do parâmetro perplexity, o resultado ainda parece muito bom:
 O resultado do t-SNE nos dados de teste com previsões do classificador
O resultado do t-SNE nos dados de teste com previsões do classificadorObviamente, essa abordagem é imperfeita, mas funciona. Pode haver algumas melhorias possíveis:
- Mais dados. As redes de convolução exigem muitos dados e eu tinha apenas 139 imagens para treinamento. Técnicas como o aumento de dados funcionam bem (usei D4 ou aumento dédrico simétrico , resultando em mais de 2 mil imagens), mas ter mais dados reais ainda é extremamente importante.
- Função de perda mais adequada. Para simplificar, usei a entropia cruzada categórica, o que é bom porque funciona imediatamente. A melhor opção seria usar a função de perda, que leva em consideração a variação dentro das classes, por exemplo, a função de perda de trigêmeos (consulte o artigo do FaceNet ).
- Melhorando a arquitetura do classificador. O classificador atual é essencialmente um protótipo, cujo único objetivo é criar máscaras binárias e combinar vários conjuntos de recursos para formar um único pipeline.
- Layout de imagem aprimorado. Fiquei muito desleixado ao marcar imagens manualmente: o classificador fez esse trabalho melhor do que eu em uma dúzia de imagens de teste.
Conclusão Finalmente, deve-se reconhecer que a empresa não possui dados, nem explicações, nem mesmo uma tarefa mais claramente definida que precisa ser resolvida. E isso é bom (caso contrário, por que eles precisam de você?), Porque seu trabalho é usar várias ferramentas, processadores com vários núcleos, modelos pré-treinados e uma mistura de conhecimentos técnicos e de negócios para criar valor adicional na empresa.
Comece pequeno: um protótipo funcional pode ser criado a partir de vários blocos de código de brinquedo e aumentará significativamente a produtividade de novas conversas com a gerência da empresa. Este é o trabalho de um cientista de dados - para oferecer aos negócios novas abordagens e idéias.
20 de setembro de 2018 inicia o
“Big Data Specialist 9.0” , onde, entre outras coisas, você aprenderá como visualizar dados e entender a lógica de negócios por trás dessa ou daquela tarefa, o que ajudará a apresentar de maneira mais eficaz os resultados do seu trabalho aos colegas e à gerência.