
Hoje, o CERN é um dos maiores usuários do Kubernetes no mundo. De acordo com estatísticas recentes, 210 grupos europeus de K8s foram lançados nesta organização europeia por trás do Large Hadron Collider (LHC) e vários outros projetos de pesquisa conhecidos, servindo centenas de milhares de tarefas simultaneamente. Esta história de sucesso é sobre eles.
Contêineres CERN: início
Para aqueles que estão pelo menos superficialmente familiarizados com as atividades do CERN, não é segredo que muita atenção é dada nessa organização a tecnologias de informação relevantes: lembre-se de que este é o berço da World Wide Web e, entre os méritos mais recentes, você pode se lembrar de sistemas de grade (incluindo o
LHC Computing Grid ), um
circuito integrado especializado,
distribuição Scientific Linux e até
sua própria licença de hardware aberto. Como regra, esses projetos, sejam eles de software ou hardware, estão conectados à principal criação do CERN - LHC. Isso também se aplica à infraestrutura de TI do CERN, que atende amplamente às suas próprias necessidades.
 No data center do CERN em Genebra
No data center do CERN em GenebraAs informações mais antigas disponíveis ao público sobre o uso prático de contêineres na infraestrutura da organização, encontradas, datam de abril de 2016. Como parte de um relatório "interno" de
Containers and Orchestration na CERN Cloud , os funcionários do CERN conversaram sobre como eles usam o OpenStack Magnum
(um componente do OpenStack para trabalhar com mecanismos de orquestração de contêineres) para fornecer suporte para contêineres na nuvem (CERN Cloud) e sua orquestração. Já mencionando Kubernetes, os engenheiros pretendiam ser independentes do instrumento escolhido de orquestração, apoiando outras opções: Docker Swarm e Mesos.
Nota : A própria nuvem do OpenStack foi introduzida na infraestrutura de produção do CERN vários anos antes, em 2013. Em fevereiro de 2017, 188 mil núcleos, 440 TB de RAM estavam disponíveis nessa nuvem, foram criados 4 milhões de máquinas virtuais (das quais 22 mil estavam ativas).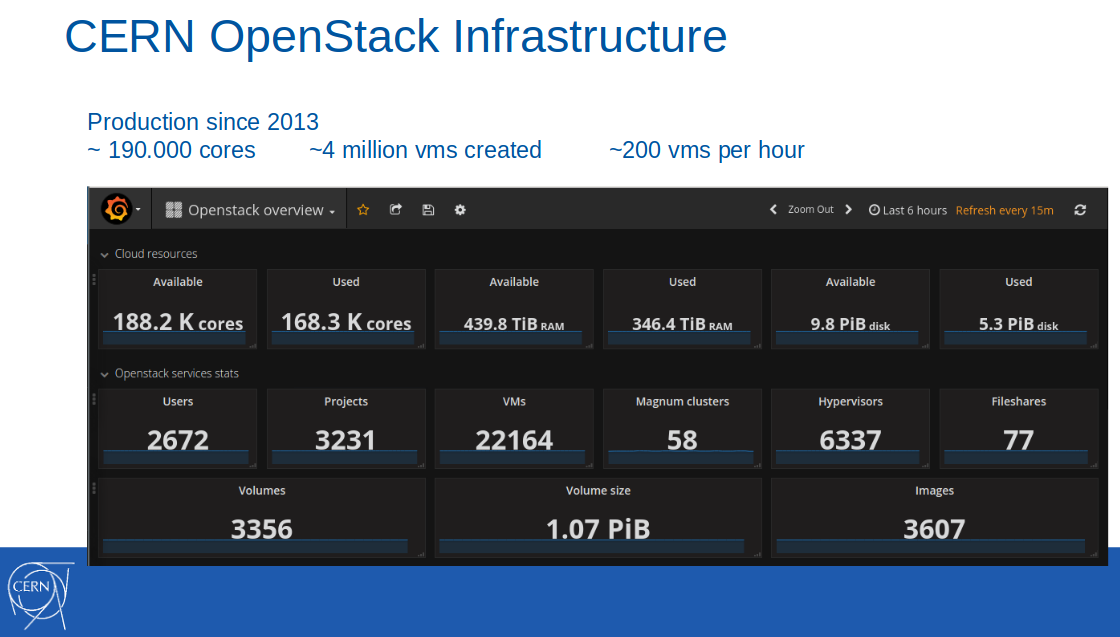
Naquela época, o suporte a contêineres no formato Containers-a-a-Service foi posicionado como um serviço piloto e foi usado em dez projetos de TI da organização. Entre os cenários de aplicativos, a integração contínua com o GitLab CI era necessária para criar e implantar aplicativos em contêineres do Docker.
 Da apresentação ao relatório do CERN de 8 de abril de 2016
Da apresentação ao relatório do CERN de 8 de abril de 2016O lançamento deste serviço em produção estava previsto para o terceiro trimestre de 2016.
Nota : Vale a pena notar separadamente que os funcionários do CERN invariavelmente colocam suas melhores práticas no upstream dos projetos de código aberto usados, incluindo e vários componentes do OpenStack, que neste caso eram Magnum, fantoche-magnum, Rally, etc.Milhões de solicitações por segundo com o Kubernetes
Em junho do mesmo ano (2016), o serviço no CERN ainda
possuía status de pré-produção:
"Estamos gradualmente avançando para um modo de produção completo para incluir Containers como serviço no conjunto padrão de serviços de TI disponíveis no CERN".
E então, inspirados na
publicação no blog Kubernetes sobre o atendimento de 1 milhão de solicitações HTTP por segundo sem tempo de inatividade durante a atualização do serviço nos K8s, os engenheiros da organização científica decidiram repetir esse sucesso em seu cluster no OpenStack Magnum, Kubernetes 1.2 e uma base de hardware de 800 núcleos de CPU.
Além disso, eles decidiram não se limitar a uma simples repetição do experimento e aumentaram com êxito o número de solicitações para 2 milhões por segundo, preparando simultaneamente vários patches para o mesmo OpenStack Magnum e fazendo testes com diferentes números de nós no cluster (300, 500 e 1000).
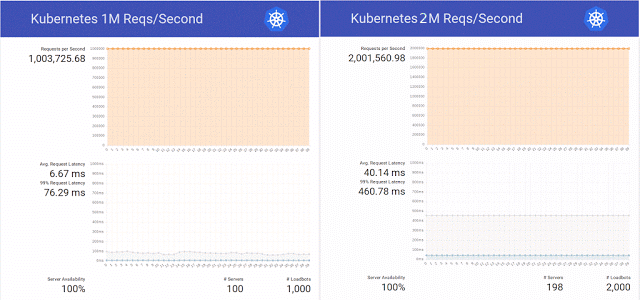
Resumindo os resultados desse teste, os engenheiros notaram novamente que "também existem Swarm e Mesos, e planejamos realizar testes em breve". Se o assunto chegou a esses testes, a Internet não é conhecida, mas até o final desse ano, o experimento com o Kubernetes
continuou - já com 10 milhões de solicitações por segundo. O resultado foi bastante positivo, mas foi limitado a uma marca de sucesso de pouco mais de 7 milhões - devido a um problema de rede não relacionado ao OpenStack.
Engenheiros especializados em OpenStack Heat e Magnum também mediram que eram necessários 23 minutos para escalar o cluster de 1 a 1000 nós, avaliando-o como um bom resultado
(consulte também a apresentação Rumo a 10.000 contêineres no OpenStack no OpenStack Summit Barcelona 2016) .
Contêineres no CERN: transição para produção
Em fevereiro do ano seguinte (2017), os contêineres do CERN já eram amplamente utilizados para resolver problemas de vários campos: processamento em lote, aprendizado de máquina, gerenciamento de infraestrutura, implantação contínua ... Isso foi anunciado no relatório “
OpenStack Magnum at CERN. Dimensionando clusters de contêineres para milhares de nós "(
vídeo ) no FOSDEM 2017:

Também informou que o uso da Magnum no CERN entrou na fase de produção em outubro de 2016 e novamente enfatizou o apoio de três instrumentos para orquestração: Kubernetes, Docker Swarm e Mesos. Por que isso era tão importante,
explicou em um de seus discursos (OpenStack Summit em Boston, maio de 2017) Ricardo Rocha, do departamento de TI do CERN:
“A Magnum também nos permite escolher um mecanismo de contêiner, que foi muito valioso para nós. Grupos de pessoas que defendiam o Kubernetes trabalhavam na organização, mas havia também aqueles que já usavam o Mesos, e alguns até trabalharam com o Docker usual, querendo continuar a confiar na API do Docker, e o Swarm tem um grande potencial aqui. Queríamos obter facilidade de uso, não exigir que as pessoas entendessem padrões complexos para configurar seus clusters. ”
Naquela época, o CERN usava cerca de 40 clusters no Kubernetes, 20 no Docker Swarm e 5 no Mesosphere DC / OS.
Um ano depois, em maio de 2018, a situação mudou significativamente. Na apresentação do
CERN Experiences with Multi-Cloud Federated Kubernetes (
vídeo ) de Ricardo e seu colega (Clenimar Filemon) no KubeCon Europe 2018, novos detalhes sobre o uso do Kubernetes se tornaram conhecidos. Agora, não é apenas uma das ferramentas de orquestração de contêineres disponíveis para usuários de uma organização científica, mas também uma tecnologia importante para toda a infraestrutura, que permite - graças à federação - expandir significativamente a nuvem de computação adicionando recursos de terceiros (GKE, AKS, Amazon, Oracle ...) às suas próprias instalações.
Nota : A federação no Kubernetes é um mecanismo especial que simplifica o gerenciamento de vários clusters, sincronizando os recursos localizados neles e detectando serviços automaticamente em todos os clusters. O caso real de seu aplicativo está trabalhando com uma variedade de clusters Kubernetes distribuídos por diferentes provedores (seus datacenters, serviços em nuvem de terceiros).Como você pode ver neste slide, que demonstra algumas características quantitativas do data center do CERN em Genebra ...

... a infraestrutura interna da organização cresceu tremendamente. Por exemplo, o número de núcleos disponíveis para o ano quase dobrou - já para 320 mil. Os engenheiros foram além e combinaram vários de seus data centers, tendo atingido a disponibilidade de 700 mil núcleos na nuvem CERN, que estão envolvidos na execução paralela de 400 mil tarefas (para reconstrução de eventos, calibração de detectores, simulações, análise de dados etc.) ...
Porém, no contexto deste artigo, o fato de já existirem 210 clusters Kubernetes, cujos tamanhos variaram bastante (de 10 a 1000 nós), é de maior interesse.
Federação com Kubernetes
No entanto, as capacidades internas do CERN nem sempre eram suficientes - por exemplo, para períodos de fortes explosões de carga: antes de grandes conferências internacionais sobre física e no caso de grandes campanhas para a reconstrução de experimentos. Um caso de uso notável que requer grandes recursos é o CERN Batch Service, que responde por cerca de 80% dos recursos de computação da organização.
No coração deste sistema está a estrutura de código aberto
HTCondor , projetada para resolver problemas da categoria HTC (computação de alto rendimento). O daemon StartD é responsável pelos cálculos nele, que inicia em cada nó e é responsável por iniciar a carga de trabalho nele. Foi ele quem foi contêiner no CERN com o objetivo de lançar no Kubernetes e em outras federações.
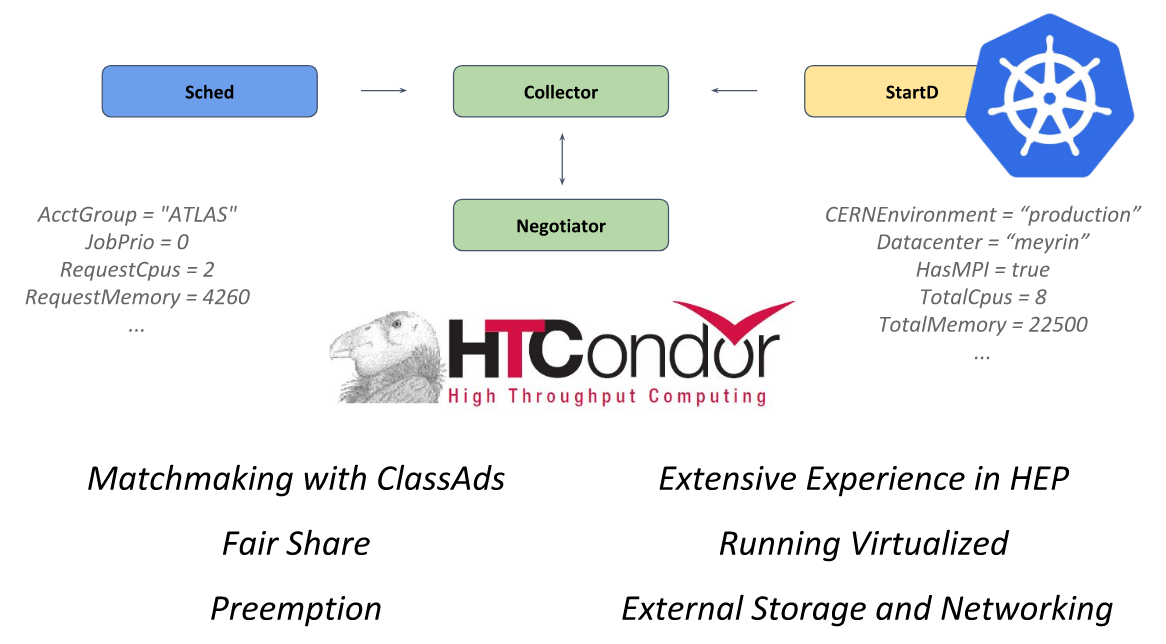 HTCondor da apresentação do CERN na KubeCon Europe 2018
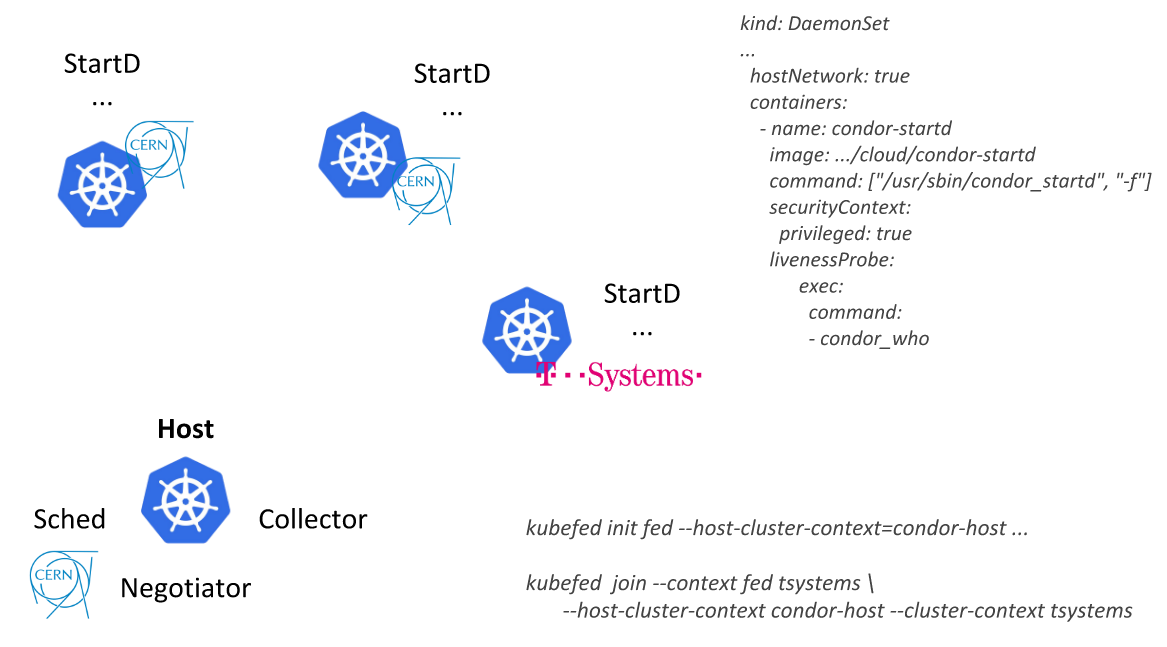
HTCondor da apresentação do CERN na KubeCon Europe 2018Seguindo esse caminho, os engenheiros do CERN conseguiram descrever um único recurso (
DaemonSet com um contêiner onde o StartD é iniciado a partir do HTCondor) e implantá-lo nos nós de todos os clusters federados do Kubernetes: primeiro como parte de seu datacenter e depois conectando fornecedores externos (nuvem pública da T-Systems e outras empresas):
Outra aplicação é uma plataforma analítica baseada em
REANA ,
RECAST e
Yadage . Diferente do CERN Batch Service, que é um software "estabelecido" na organização, este é um novo desenvolvimento, que levou imediatamente em conta as especificidades do aplicativo junto com o Kubernetes. Os fluxos de trabalho neste sistema são implementados de forma que cada etapa seja convertida em
Job for Kubernetes.
Se, inicialmente, todas essas tarefas foram executadas em um único cluster, com o tempo, as solicitações aumentaram e "hoje é nossa melhor federação de casos de uso no Kubernetes". Assista a um pequeno vídeo com sua demonstração
neste fragmento da performance de Ricardo Rocha
PS
Informações adicionais sobre a extensão atual do uso de TI no CERN podem ser encontradas no
site da organização .
Outros artigos do ciclo