
Qual é a diferença entre o Machine Learning e a análise de dados, que fica em Odnoklassniki e como iniciar sua jornada no machine learning - falamos sobre isso na décima segunda edição de talk shows para programadores.
Vídeo no canal TechnostreamO anfitrião do programa é Pavel Shcherbinin, diretor técnico de projetos de mídia, e o convidado é Dmitry Bugaychenko, analista da Odnoklassniki.
00:56 Dmitry Bugaychenko: da terceirização à OK e à atividade científica
02:42 Por que combinar trabalho na universidade e em uma grande empresa
02:57 Onde o aprendizado de máquina é aplicado em OK
03:49 Aprendizado de máquina e análise de dados - qual a diferença?
05:08 Screencast “Analisamos bem o público com a ajuda da análise de dados”
22:34 Os colegas de classe
são um serviço de namoro?
24:07 Por onde começar o aprendizado do Machine Learning?
25:33 Devo participar de campeonatos de aprendizado de máquina?
26:53 Como começar a praticar em OK
28:18 Manual de aprendizado de máquina
30:28 Eventos de aprendizado de máquina
32:48 Como o pipeline de dados está organizado em OK (mostrado no quadro)
43:42 Pesquisa Blitz
Conte um pouco sobre você.Podemos assumir que minha carreira começou em 1999, quando entrei na matemática. Por cinco anos, ele estudou ativamente matemática, programação e várias disciplinas relacionadas. Depois, trabalhou por um longo período em uma empresa de terceirização. A terceirização é uma experiência muito interessante. Consegui trabalhar em uma ampla variedade de projetos, desde escrever um driver para uma geladeira até criar sistemas corporativos distribuídos.
Durante todo esse tempo, além do trabalho principal, lecionei na universidade para manter contato com a comunidade acadêmica, o que foi bastante difícil. Quando em 2011 fui convidado para Odnoklassniki para participar de sistemas de recomendação, foi uma chance muito boa, da qual aproveitei. Aqui, é possível combinar a preparação matemática da universidade e a experiência prática de programação. No entanto, continuo a ensinar na universidade.
O ensino leva muito tempo?1,5 dia por semana vai para a universidade, mas vale a pena, porque já temos três dos meus ex-alunos na equipe. Ou seja, a universidade também funciona como uma forja de pessoal.
No trabalho, relacione-se com calma ao fato de que você se foi por 1,5 dias?Renunciou. Todo mundo entende qual é o lucro disso, então não encontro nenhuma oposição.
Diga-me onde o aprendizado de máquina é usado no Odnoklassniki.Temos muitas aplicações. Historicamente, o primeiro sistema de aprendizado de máquina foi a recomendação musical. Tudo começou em 2011. Houve simplesmente um crescimento explosivo: a recomendação das comunidades, a recomendação dos amigos, "talvez vocês se conheçam", tenta classificar o conteúdo no feed da pessoa. Agora muitos projetos estão sendo desenvolvidos. Independentemente de qual parte do Odnoklassniki você cutuca, existem componentes relacionados ao aprendizado de máquina ou à análise de dados.
Ajude nossos leitores a separar esses dois conceitos: aprendizado de máquina e análise de dados.Os dados são analisados por uma pessoa para encontrar alguns padrões, conexões, testar algumas hipóteses. Para isso, são utilizados vários meios de estatística matemática. O aprendizado de máquina é um método mais avançado de busca de padrões, usando técnicas geralmente baseadas em algum tipo de modelo grande e complexo com um grande número de parâmetros.
Estamos tentando selecionar os parâmetros desse modelo para que ele descreva bem o fenômeno de que precisamos. Existem muitos algoritmos diferentes, métodos para enumerar parâmetros, mas tudo isso é feito para encontrar alguma regularidade. Por exemplo, de acordo com os dados de uma postagem em uma rede social, avalie a probabilidade de uma pessoa em particular colocar uma "classe" nessa postagem. Ou seja, o aprendizado de máquina é uma ferramenta para análise de dados.
Você e eu podemos desmascarar um dos mitos sobre Odnoklassniki, segundo o qual esse público tem um público muito idoso?Não tem problema Este é um mapa que reflete em tempo real os logins de cada usuário específico. Ou seja, cada ponto é uma pessoa que efetuou login e faz algo no Odnoklassniki.
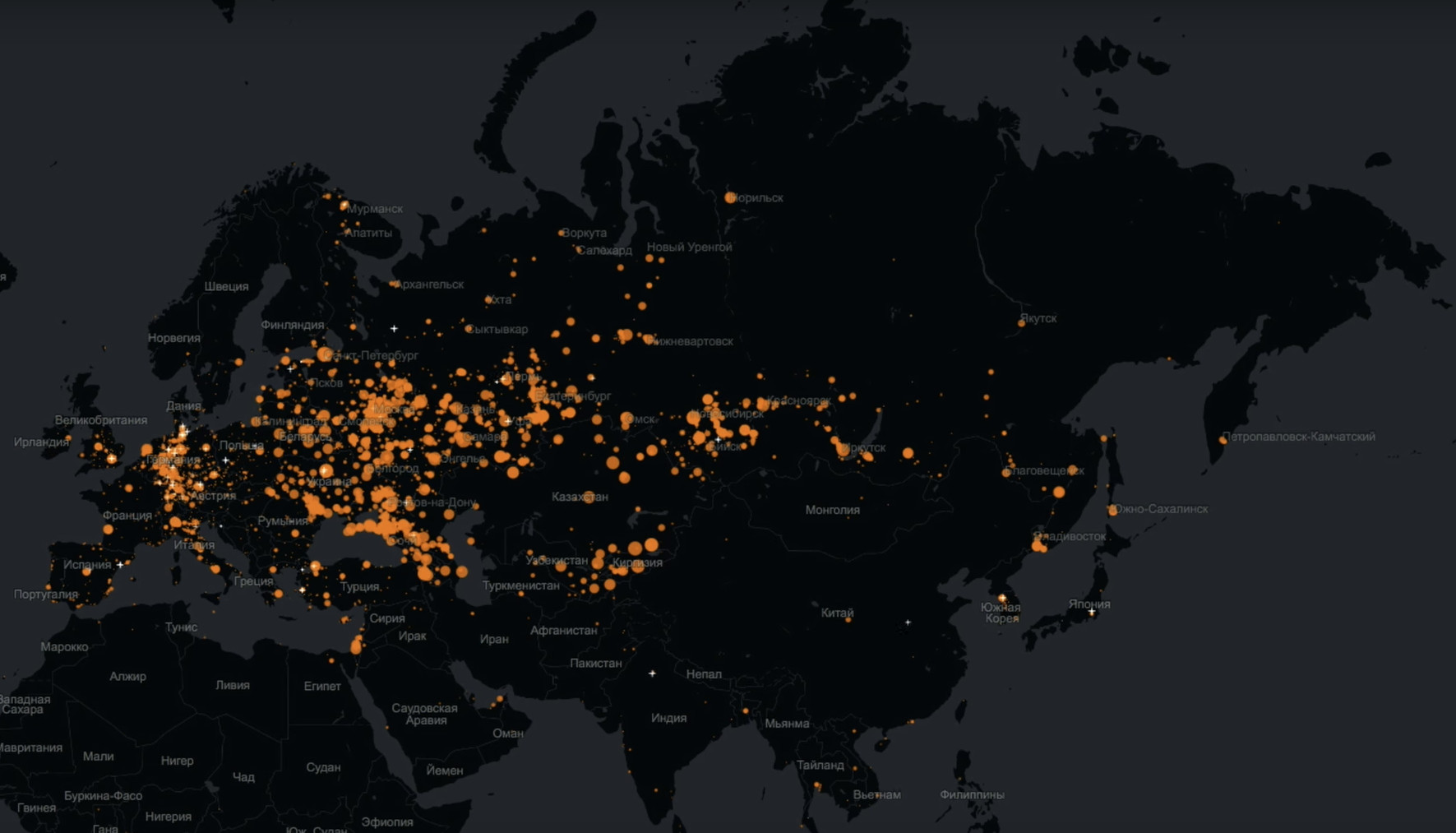
Grandes círculos vermelhos são cidades das quais muitos usuários chegaram até nós. É muito claramente visível aqui que Odnoklassniki não está apenas vivo, eles cobrem quase toda a Eurásia.
Vamos calcular quantos usuários colocaram "classe" em Odnoklassniki ontem e ver a distribuição etária.
Onde começa a codificação? Obviamente, da importação de vários dados úteis para o cálculo agregado futuro. Nossa ferramenta principal é o
Spark , para acesso ao qual usamos a frente da web do
Zeppelin . Basicamente, os dados vêm através do
Apache Kafka , são empacotados e divididos em diferentes blocos. Nesse caso, estamos interessados no bloco que descreve a atividade do usuário de ontem, em particular as classes. Há um campo no qual os dados demográficos dos usuários são armazenados, incluindo aniversários.

A saída é o ano de nascimento dos dez primeiros registros. Agora vamos tentar criar alguns agregados a partir disso. Queremos contar o número de usuários únicos. Precisamos de identificação e ano de nascimento, agrupar por ano e calcular o número de usuários únicos. E vamos jogar um pouco: certamente haverá pessoas cujo ano de nascimento não é indicado; portanto, as filtraremos para que não causem ruído no gráfico.
Para fazer o cálculo, o sistema precisa extrair cerca de 1 TB de dados. Obtemos o resultado e o apresentamos graficamente:

O pico da idade cai em 1983 - 35 anos. Isso é usuários bastante antigos para si.
Para representar melhor a situação, não há informações suficientes de uma fonte. Se estamos falando de dados demográficos de usuários, a fonte mais interessante para comparação são as estatísticas da população da Rússia. No site da
Rosstat, baixei os dados sobre os anos de nascimento dos russos, coletados em 2016.
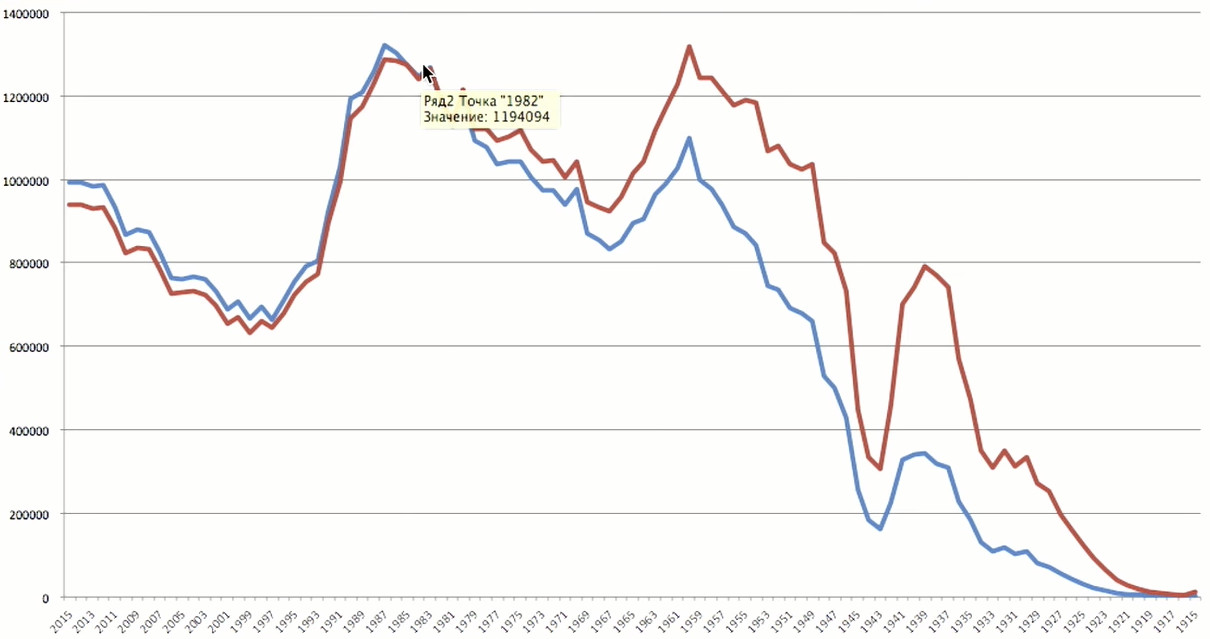
O pico estatístico está muito próximo do pico, de acordo com Odnoklassniki - temos usuários nascidos em 1983 e Rosstat - 1987. O que me impressionou foram duas grandes falhas. O poço do início da década de 1940 é a Grande Guerra Patriótica. A guerra nos custou não apenas mais de 20 milhões de mortos, mas também milhões de nascituros. Este é o poço demográfico que ainda está sendo sentido. O segundo poço - os anos 90. E ainda não nos recuperamos totalmente dessa crise. Vemos a mesma imagem nos dados de Odnoklassniki: após 1990, houve um forte declínio. Ainda não podemos ter pessoas nascidas em 2015, porque a idade mínima para inscrição é de 5 anos.
Adicione o atributo de gênero à nossa amostra e grupo, não apenas por ano, mas também por sexo.
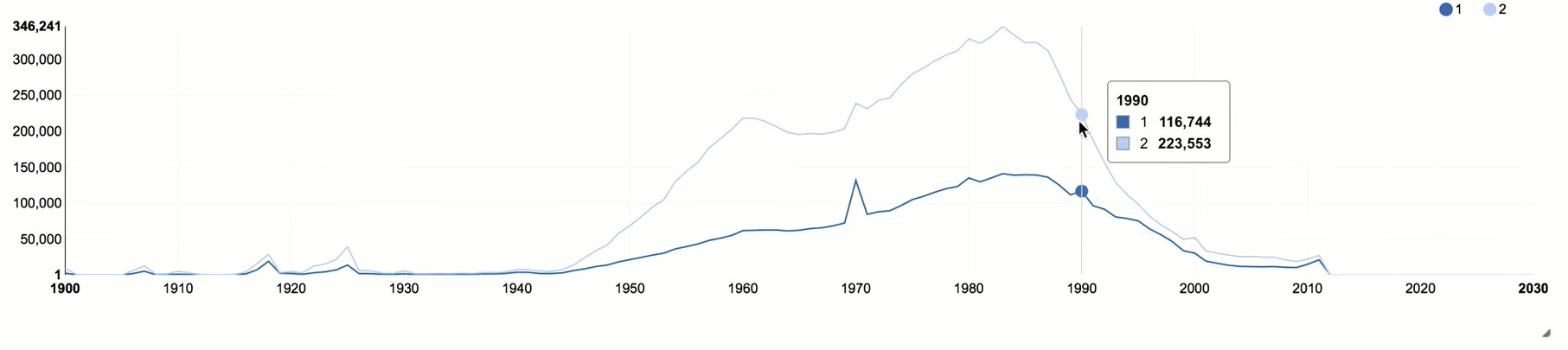
Após 1990, há um declínio acentuado, que se correlaciona com a situação geral da idade na Rússia. As mulheres colocam a "classe" muito mais ativamente, quase o dobro dos homens. Esta é uma imagem bastante típica para as redes sociais, porque as mulheres são mais ativas socialmente que os homens.
Você também pode prestar atenção a vários picos que se correlacionam com os anos "redondos". Com base nesses picos, pode-se avaliar a influência de bots ou pessoas que distorcem deliberadamente sua idade, porque nesses casos geralmente indicam algum tipo de data redonda.
Também estamos interessados na distribuição geográfica de nossos usuários. Precisamos de um ID de usuário para contar visitantes únicos e os endereços de residência indicados nos perfis. Agrupe por cidade e calcule a unidade. Classifique pelo número de usuários em ordem decrescente e deixe apenas as primeiras 200 cidades. Executar agregação:

Esta é a principal cidade em termos de número de colegas de classe que os escolheram. Naturalmente, Moscou está na liderança. O sul da Rússia está representado muito melhor que o noroeste. Temos usuários nos EUA, Canadá, muito na Alemanha, muito em Israel. Fato interessante: 36 mil pessoas de Yuzhno-Sakhalinsk gostavam de cada dia. E no total, segundo a Wikipedia, 180 mil pessoas vivem na cidade. 20% da população de Yuzhno-Sakhalinsk foi para Odnoklassniki e colocou uma "classe".

Aumente o zoom e veja o que acontece em Moscou e na região de Moscou.

As repúblicas da Ásia Central, Moldávia e Ucrânia estão muito bem representadas em Odnoklassniki.

Você pode ver imediatamente onde eles tentaram bloquear o acesso à nossa rede social e onde não.
Como você pode ver, o Odnoklassniki é um produto dinâmico e animado usado por jovens e idosos de todo o mundo, às vezes até onde você não espera. Entre todas as categorias de idade, temos mais de 30 anos.
As redes sociais são construídas em torno das comunidades. Muitas vezes acontece que se uma comunidade entrou em uma determinada rede social, ela sabe muito pouco sobre outras redes sociais. Portanto, por exemplo, a comunidade profissional de jornalistas pode ter a ilusão de que Odnoklassniki é principalmente um público idoso. De fato, esta é a opinião subjetiva de alguma comunidade. Temos usuários com idade entre 50 e 60 anos, há crianças em idade escolar, jovens com 20 anos, pessoas maduras e maduras entre 30 e 35 anos.
A cobertura do Odnoklassniki é em todas as regiões da Rússia, países vizinhos, Ucrânia, Bielorrússia e Ásia Central. Representamos muito bem diásporas, por exemplo, a diáspora alemã de emigrantes russos, a diáspora americana e a israelense. Eles se comunicam bastante ativamente com seus parentes que permaneceram na Rússia e nas antigas repúblicas soviéticas. Deste ponto de vista, o Odnoklassniki contribui muito bem para a implementação da função básica de uma rede social - para manter contatos entre pessoas que moram longe uma da outra.
Há uma opinião de que Odnoklassniki é tão atraente para muitos porque é uma maneira fácil de encontrar amigos e conhecidos de seus amigos e parentes. Ou seja, o Odnoklassniki é apresentado como um serviço de namoro. Quanto custa esse modo de namoro e faz parte da ideologia de Odnoklassniki?A necessidade de conhecer outras pessoas, incluindo o sexo oposto, é uma necessidade humana básica. Naturalmente, é expresso em qualquer rede social. Mas, em Odnoklassniki, ele se expressa nem mais nem menos do que em outras redes sociais. Não temos ênfase nos serviços de namoro. A ideologia do desenvolvimento de nossa rede social é baseada em um valor comum como a comunicação entre as pessoas. Não é tão importante para nós se serão colegas de turma que se dispersaram para diferentes cidades ou pessoas que estão procurando um companheiro. Ambas as opções nos convêm perfeitamente. Estamos felizes por as pessoas se encontrarem e se comunicarem. Mas nada mais
Você faz muito aprendizado de máquina. Este tópico agora excita muitos. Por onde começar, como entrar nesta profissão?Primeiro, você precisa obter algum conhecimento. Não há problemas com isso, existem cursos maravilhosos no
Coursera , no
Stepik e em alguns programas universitários que fornecem muito bom conhecimento básico sobre aprendizado de máquina. Para realmente ingressar nesta esfera, você precisa de um objetivo e entender onde pode aplicá-lo. Porque apenas ouvir um curso abstrato está longe de ser tão eficaz como se você realmente resolvesse um problema ou um problema.
No caso dos estudantes, a opção ideal são dissertações e dissertações. E mesmo nesse caso, tento não deixar a tarefa de cima para baixo, mas para ajudar as idéias a virem dos alunos, eles terão muito mais motivação.
Ou seja, tendo definido uma meta, ouça os cursos on-line e tente aplicar o conhecimento. E tudo vai acabar.
Parece-me que existem tarefas suficientes hoje. Um grande número de competições de Sberbank, Tinkoff e muitas outras empresas acontece no torneio.Claro. Mas eles estão focados, antes de tudo, naqueles que já estão intimamente envolvidos no aprendizado de máquina. Além disso, muitas vezes em tais competições, pode-se observar não o aprendizado de máquina, mas o ódio. Os modelos treinados no skittle não ajudarão a resolver problemas práticos, porque eles dirigem muitos parâmetros. Como resultado, os modelos se especializam especificamente em competições específicas no pino, e somente neles são obtidos resultados. E se você transferir esses modelos para o mundo real, eles não funcionarão.
A melhor prática é a prática. Como começar a praticar com sua equipe?Existem muitas maneiras. Se falamos de equipes de pesquisa, temos um projeto chamado OK Data Science Lab, no qual fornecemos recursos de computação, dados, nosso conhecimento e experiência para pessoas que desejam desenvolver suas idéias relacionadas ao aprendizado de máquina e análise de dados. E não necessariamente para uma rede social. Por exemplo, temos um estudo em que o autor tenta entender o que é mais interessante para os alunos modernos.
Se você é especialista e procura trabalho, sempre temos muitas vagas relacionadas ao aprendizado de máquina. Visite-nos para uma entrevista.
Existe algum livro, um leitor de aprendizado de máquina?Esse é um campo de mudanças tão rápidas que escrever um livro ou leitor de aprendizado de máquina é muito ambicioso. Eu posso recomendar o trabalho clássico "
Elementos da aprendizagem estatística ". Trata-se dos métodos mais básicos de aprendizado de máquina, originários das estatísticas.
Sergey Nikolenko publicou um livro sobre aprendizado de máquina profundo.Na minha opinião, o aprendizado profundo não é por onde começar. Se você já possui o aprendizado de máquina clássico, essa é uma boa opção. Mas se você ainda não conhece as técnicas clássicas, é errado começar imediatamente com o aprendizado profundo, porque muitas vezes afasta o pesquisador do problema, essa é uma ferramenta muito poderosa. Antes de aplicá-lo, você precisa analisar o problema "manualmente" de maneiras mais simples. E só então, com uma compreensão da área de assunto, passe para o aprendizado profundo. Caso contrário, seu modelo aprenderá, mas você não. Quando você se torna mais burro do que o seu modelo, é, para dizer o mínimo, ineficaz. Você não pode desenvolver mais o modelo, e este é um beco sem saída. Portanto, é melhor se tornar proficiente no ML clássico. Isso não significa que você precise passar anos, é bem possível dominar em um tempo razoável.
Você tem algum evento de aprendizado de máquina?Temos uma série de
hackathons do
SNA Hackathon . Até agora, duas vezes se passaram. Pela primeira vez, o hackathon foi dedicado à análise do texto e à tentativa de prever quantas "aulas" um determinado post ganharia. O segundo hackathon ocorreu um ano atrás e foi dedicado à análise de gráficos. Houve muitos eventos interessantes. Fornecemos informações sobre as "amizades" de alguns de nossos usuários, ao que parece, um pequeno pedaço de dados com cerca de 1 GB. Mas quando os participantes que queriam enviar suas previsões tentaram trabalhar com ele, quase ninguém conseguiu, mesmo em máquinas com 16 e 32 GB de memória tudo caiu, entrou em troca, não quis trabalhar. Tivemos até que explicar apressadamente como e como não trabalhar com dados.
Verificou-se que muitos especialistas em aprendizado de máquina, mesmo bastante avançados, surgiram e começaram a esquecer os princípios básicos da programação. Esqueça o que é o boxe, como as tabelas de hash são estruturadas, qual sobrecarga de memória pode ser se você usar tabelas de hash. Se você não pensa sobre tudo isso e o faz de frente em Python, Java ou Scala, os problemas descritos serão descritos. Fizemos uma demonstração em Python, o mesmo rake está em outros idiomas. Um gráfico de 40 milhões de links, que caberia em 200 MB de memória, explode acentuadamente em 20 GB simplesmente porque você esqueceu como as estruturas básicas de dados são organizadas. Foi muito impressionante então. Mesmo se você é um especialista em aprendizado de máquina, não deve esquecer os conceitos básicos de programação.
Como o seu fluxo de trabalho de processamento de dados é organizado?Os usuários interagem com todo um ecossistema de nossos produtos. Podemos distinguir condicionalmente dois níveis: aplicativos front-end (aplicativos móveis, portal, versão móvel, vários aplicativos adicionais) e lógica de negócios. As frentes geralmente interagem com os usuários e têm acesso a um número muito limitado de servidores; portanto, existem alguns métodos especiais na lógica de negócios que permitem que as frentes registrem dados.
Esses dados se enquadram no barramento de dados único Apache Kafka. Essa é a vez que se tornou um padrão do setor usado para coletar dados brutos. Naturalmente, é difícil analisar dados brutos em Kafka, para que eles sejam transferidos regularmente para o Hadoop grande e espesso. Alguém pode dizer que o Hadoop é o século passado, agora o Spark governa. Mas o Hadoop é uma plataforma na qual você pode executar muitas ferramentas. Temos várias ferramentas de análise girando sobre o Hadoop. Costumo recorrer a essa classificação:
- O estilo de entrada de dados .
- Processamento em lote. Há uma quantidade de dados que você processa de alguma forma.
- Processamento de fluxo. Você trabalha com dados em tempo real provenientes diretamente de fluxos, neste caso do nosso Kafka.
Se durante o processamento em lote houver atrasos bastante sérios - coletamos estatísticas durante o dia e você treina o modelo à noite, no caso do processamento de streaming, os atrasos são medidos em unidades de segundos entre o recebimento dos dados e seu processamento.
- Análise operacional . Isso é controle e monitoramento de processos. Serve produção, deve funcionar por si só, sem intervenção humana.
- Análise interativa . O que uma pessoa faz. A velocidade da reação é importante aqui: eles fizeram alguma coisa, obtiveram o resultado.
Em cada um desses nichos, temos nosso próprio ecossistema de produtos. Por exemplo, a análise operacional em lote usa principalmente o MapReduce clássico, o Apache Tez e um pouco do Spark. Se estamos falando sobre análise interativa de lotes, essas são Spark Spark e as linguagens de script Pig e Hive.
Obviamente, não há uma linha clara, porque algumas linguagens interativas são frequentemente usadas para análise operacional de lotes. Apache Samza. LinkedIn. 2014 . , Spark Streaming, -.
- production, . , Kafka, . Kafka — , , . , Kafka , Streaming Index. Kafka : Casandra , SMC.
, , 99 %. - Streaming Index, . , , , «» , . , .
, , -. ?Mac.
IDE?Idea.
: ?.
?, .
, IT- 10 ?, .
?: , . , , , .
?, . . , , . , , .
, . «»?O mesmo que os jornalistas: quantas pessoas restam em Odnoklassniki.Que super-herói você gostaria de ser?Provavelmente Tony Stark.Homem de Ferro?Sim
PorqueTecnologia.