
Os desenvolvedores que sabem e sabem como trabalhar com o git cresceram em uma ordem de magnitude recentemente. Você se acostuma com a velocidade de execução dos comandos. Você se acostuma com a conveniência das ramificações e com a reversão fácil das alterações. A resolução de conflitos é tão comum que os programadores estão acostumados a resolver heroicamente conflitos onde não deveriam estar.
Nossa equipe da Directum está desenvolvendo uma ferramenta de desenvolvimento para soluções de plataforma. Se você viu o 1C, pode imaginar o ambiente de trabalho de nossos "clientes" - desenvolvedores de aplicativos. Usando essa ferramenta de desenvolvimento, um desenvolvedor de aplicativos cria uma solução de aplicativos para os clientes.
Nossa equipe enfrentou a tarefa de simplificar a vida de nossos candidatos. Somos mimados com chips modernos do Visual Studio, ReSharper e IDEA. Os candidatos exigiram que integássemos o git fora da caixa na ferramenta.
Essa é a dificuldade. Na ferramenta para cada tipo de entidade (contrato, relatório, diretório, módulo), um bloqueio pode estar presente. Um desenvolvedor começou a editar o tipo de entidade e o bloqueou até concluir as alterações e as comprometeu com o servidor. Outros desenvolvedores no momento veem o mesmo tipo de entidade somente leitura. O desenvolvimento lembrava trabalhar no SVN ou enviar um documento do Word por correio entre vários usuários. Quero tudo de uma vez, mas talvez apenas um.
Cada tipo de entidade pode ter muitos manipuladores (abrir um documento, validar antes de salvar, gravar no banco de dados), no qual você deseja escrever um código que funcione com uma instância específica da entidade. Por exemplo, bloqueie os botões, exiba uma mensagem para o usuário ou crie uma nova tarefa para os artistas. Todo o código dentro da estrutura da API fornecida pela plataforma. Manipuladores são classes nas quais existem muitos métodos. Quando duas pessoas precisaram corrigir o mesmo arquivo com o código, não foi possível fazer isso, porque a plataforma bloqueou todo o tipo de entidade junto com o código dependente.
Nossos praticantes percorreram todo o caminho. Eles silenciosamente se compraram uma cópia "ilegal" do nosso ambiente de desenvolvimento, comentaram a parte de bloqueio e fundiram nossos compromissos para si mesmos. O código do aplicativo foi mantido sob o git, confirmado por meio de ferramentas de terceiros (git bash, SourceTree e outros). Tiramos nossas conclusões:
- Nossa equipe subestimou a disposição dos desenvolvedores de aplicativos de se ajustarem à plataforma. Enorme respeito e honra!
- A solução que eles propuseram não é adequada para produção. Com o git, as mãos de uma pessoa estão desatadas e ele é capaz de criar qualquer coisa. Para apoiar toda a diversidade será estúpido, não sequestrar. Além disso, será necessário educar os clientes da plataforma. Documentar todos os comandos git da plataforma deixaria a equipe de documentação louca.

O que você quer do Git
Portanto, distribuir para produção com git out não é bom. Decidimos, de alguma forma, encapsular a lógica das operações principais e limitar seu número. Pelo menos para o primeiro lançamento. A lista de equipes foi reduzida quanto possível e permaneceu:
- status
- comprometer
- puxar
- empurrar
- reset --hard para HEAD
- redefinir para a última confirmação "servidor"
Para o primeiro lançamento, eles decidiram se recusar a trabalhar com ramificações. Não que isso seja muito difícil, apenas a equipe não encontrou o recurso de tempo.
Periodicamente, nossos parceiros enviam o desenvolvimento de aplicativos e perguntam: "Algo não funciona para nós. O que estamos fazendo de errado?". Nesse caso, o aplicativo se carrega com o desenvolvimento de outra pessoa e analisa o código. Isso costumava funcionar assim:
- O desenvolvedor levou o arquivo com o desenvolvimento;
- Mudou o banco de dados local nas configurações;
- Despejou o desenvolvimento de outra pessoa em sua base;
- Depurado, encontrado erros;
- Recomendações emitidas;
- Ele retornou seu desenvolvimento de volta.
A nova metodologia não se encaixava na abordagem antiga. Eu tive que esmagar minha cabeça. A equipe propôs duas abordagens para resolver esse problema:
- Armazene todo o desenvolvimento em um repositório git. Se necessário, trabalhe com a decisão de outra pessoa de criar uma ramificação temporária.
- Armazene o desenvolvimento de diferentes equipes em diferentes repositórios. Mova as configurações das pastas carregadas no ambiente para o arquivo de configuração.
Decidimos seguir o segundo caminho. O primeiro parecia mais difícil de implementar e, além disso, era mais fácil dar um tiro no pé com a troca de ramificação.
Mas o segundo também não é doce. Os comandos descritos acima devem funcionar não apenas no mesmo repositório, mas com vários de uma vez. Há uma alteração nos tipos de entidade de diferentes repositórios? Nós mostramos em uma janela. Isso é mais conveniente e transparente para o desenvolvedor de aplicativos. Pressionando o botão de confirmação, a ferramenta confirma alterações em cada um dos repositórios. Por conseguinte, os comandos pull / push / reset "under the hood" funcionam com repositórios fisicamente diferentes.

Libgit2sharp
Para trabalhar com o git, escolhemos entre duas opções:
- Trabalhe com o git instalado no sistema, puxando-o pelo Process.Start e analisando a saída.
- Use libgit2sharp, que via pinvoke puxa a biblioteca libgit2.
Pareceu-nos que usar uma biblioteca pronta é uma solução razoável. Em vão. Eu vou te contar um pouco mais tarde porque. No início, a biblioteca nos deu a oportunidade de lançar rapidamente um protótipo funcional.
Primeira iteração de desenvolvimento
Foi possível implementar em cerca de um mês. Na verdade, estragar o git foi rápido, e na maioria das vezes tentamos curar as feridas que foram abertas devido ao corte do antigo mecanismo de armazenamento de arquivos de origem. Tudo o que o git status retornou foi retornado à interface. Clicar em cada arquivo exibe diff. Parecia uma interface git gui.
Segunda iteração de desenvolvimento
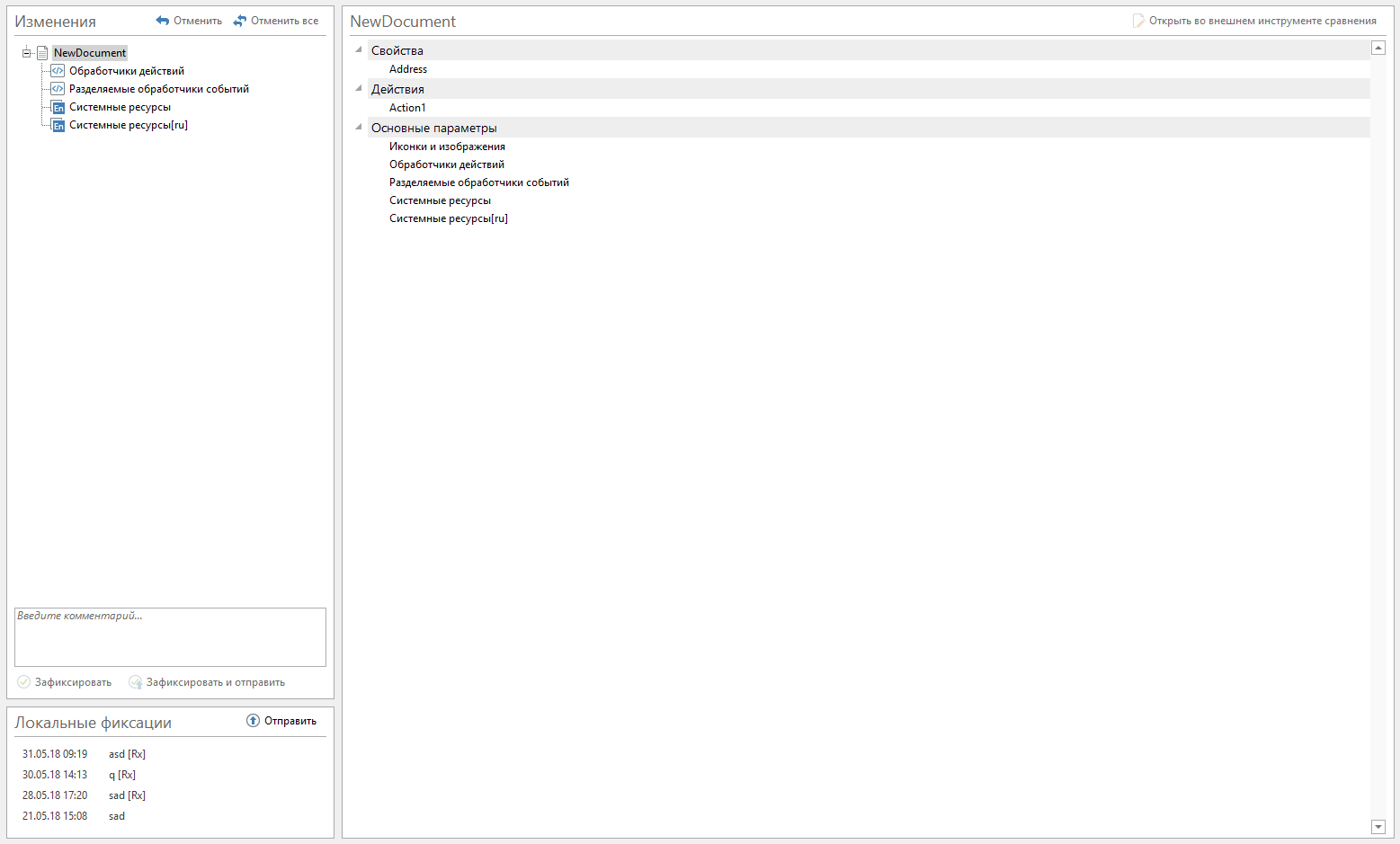
A primeira opção foi excessivamente informativa. Com cada tipo de entidade, muitos arquivos são associados ao mesmo tempo. Esses arquivos criaram ruído e ficou claro que tipos de entidades foram alteradas e o que exatamente.
Arquivos agrupados por tipo de entidade. Cada arquivo recebeu um nome legível por humanos, o mesmo da GUI. Os metadados do tipo de entidade são descritos em JSON. Eles também precisavam ser apresentados em um formato legível por humanos. A análise das alterações nas versões json "antes" e "depois" foi iniciada usando a biblioteca jsondiffpatch e, em seguida, eles escreveram sua própria implementação da comparação JSON (a seguir chamarei jsondiff). Executamos os resultados da comparação através de analisadores que produzem registros legíveis por humanos. Muitos arquivos foram ocultados, deixando uma entrada simples na árvore de alterações.
O resultado final é o seguinte:
Tendo problemas com a libgit2
O Libgit2 gerou um grande número de surpresas inesperadas. Lidar com alguns estava além do poder de um tempo razoável. Vou lhe contar o que me lembro.
Inesperado e difícil de reproduzir cai em algumas operações padrão. "Nenhum erro fornecido pela biblioteca nativa" nos diz o wrapper. Ótimo. Você está xingando, está reconstruindo a biblioteca nativa na depuração, está repetindo um caso descartado anteriormente, mas não falha no modo de depuração. Reconstrua na versão e caia novamente.
Se uma ferramenta de terceiros, por exemplo, SourceTree, estiver sendo executada em paralelo com a libgit2sharp, a confirmação poderá não confirmar alguns arquivos. Ou congela ao exibir diferenças em alguns arquivos. Assim que você tenta depurar, você não pode se reproduzir.
Em uma de nossas aplicações, a implementação do analógico de git status levou 40 segundos. Quarenta Carl! Ao mesmo tempo, o git lançado a partir do console funcionou como deveria por um segundo. Passei alguns dias para resolver o problema. Ao procurar por mudanças, o Libgit2 analisa os atributos de arquivo das pastas e os compara com a entrada no índice. Se a hora da modificação for diferente, algo mudou dentro da pasta e você precisará procurar dentro e / ou procurar nos arquivos. E se nada mudou, você não deve subir lá dentro. Aparentemente, essa otimização também está no console git. Não sei por que motivo, mas apenas uma pessoa no índice git mtime mudou. Por causa disso, o git sempre verificava o conteúdo de TODOS os arquivos no repositório quanto a alterações.
Mais perto do lançamento, nossa equipe cedeu aos desejos da equipe de aplicativos e substituiu o git pull por fetch + rebase + autostash . E então vários bugs vieram até nós, incluindo "Nenhum erro fornecido pela biblioteca nativa".
status, pull e rebase funcionam muito mais tempo do que chamar comandos do console.
Mesclagem automática
Os arquivos em desenvolvimento são divididos em dois tipos:
- Arquivos que o aplicativo vê na ferramenta de desenvolvimento. Por exemplo, código, imagens, recursos. Esses arquivos precisam ser mesclados como o git.
- Arquivos JSON criados pelo ambiente de desenvolvimento, mas o desenvolvedor do aplicativo os vê apenas na forma de uma GUI. Eles precisam resolver automaticamente conflitos.
- Arquivos gerados que são recriados automaticamente ao trabalhar com a ferramenta de desenvolvimento. Esses arquivos não entram no repositório, a ferramenta imediatamente coloca cuidadosamente .gitignore.
Com uma nova maneira, dois aplicadores diferentes foram capazes de alterar o mesmo tipo de entidade.
Por exemplo, Sasha alterará as informações sobre como armazenar o tipo de uma entidade no banco de dados e gravará um manipulador para o evento save, e Sergey estilizará a representação da entidade. Do ponto de vista do git, isso não será um conflito e as duas alterações serão mescladas sem complexidade.
E então Sasha alterou a propriedade Property1 e definiu um manipulador para ela. Sergey criou a propriedade Property2 e definiu o manipulador. Se você observar a situação de cima, suas alterações não entrarão em conflito, embora do ponto de vista do git os mesmos arquivos sejam afetados.
Eu queria que o instrumento fosse capaz de resolver essa situação por conta própria.
Um exemplo de algoritmo para mesclar dois JSON em caso de conflito:
Faça o download do JSON base git.
Faça o download do nosso JSON gita.
Baixando o JSON deles de um git.
Utilizando o jsondiff, formamos patches de software base e aplicamos aos deles. O JSON resultante é chamado P1.
Usando jsondiff, formamos patches de software básicos e aplicamos aos nossos. O JSON resultante é chamado P2.
Idealmente, após a aplicação dos adesivos P1 === P2. Nesse caso, escreva P1 no disco.
- No caso imperfeito (quando o conflito foi realmente encontrado), sugerimos que o usuário escolha entre P1 e P2 com a capacidade de terminar manualmente. Nós escrevemos a seleção no disco.
Após a mesclagem, verificamos se o estado sem erros de validação chegou. Se você não chegou, cancele a mesclagem e peça ao usuário para repeti-la. Esta não é a melhor solução, mas pelo menos garante que a partir da segunda ou terceira tentativa, a fusão ocorrerá sem consequências desagradáveis.
Sumário
- Os açougueiros estão felizes por poderem usar legalmente.
- A introdução do desenvolvimento acelerado do git.
- Fusões automáticas geralmente parecem mágicas.
- Colocamos a rejeição futura da libgit2 em favor da invocação do processo git.