Em 28 de maio, na conferência
RootConf 2018, realizada como parte do
festival RIT ++ 2018, na seção "Logging and Monitoring", foi entregue um relatório "Monitoring and Kubernetes". Ele conta sobre a experiência de monitorar a instalação com o Prometheus, que foi obtida por Flant como resultado da operação de dezenas de projetos Kubernetes em produção.

Por tradição, temos o prazer de apresentar um
vídeo com um relatório (cerca de uma hora,
muito mais informativo
que o artigo) e o aperto principal em forma de texto. Vamos lá!
O que é monitoramento?
Existem muitos sistemas de monitoramento:

Parece que pegar e instalar um deles - isso é tudo, a questão está encerrada. Mas a prática mostra que não é assim. E aqui está o porquê:
- Velocímetro mostra velocidade . Se medirmos a velocidade uma vez por minuto pelo velocímetro, a velocidade média, calculada com base nesses dados, não coincidirá com os dados do odômetro. E se, no caso de um carro, isso é óbvio, então, quando se trata de muitos e muitos indicadores para o servidor, muitas vezes esquecemos.
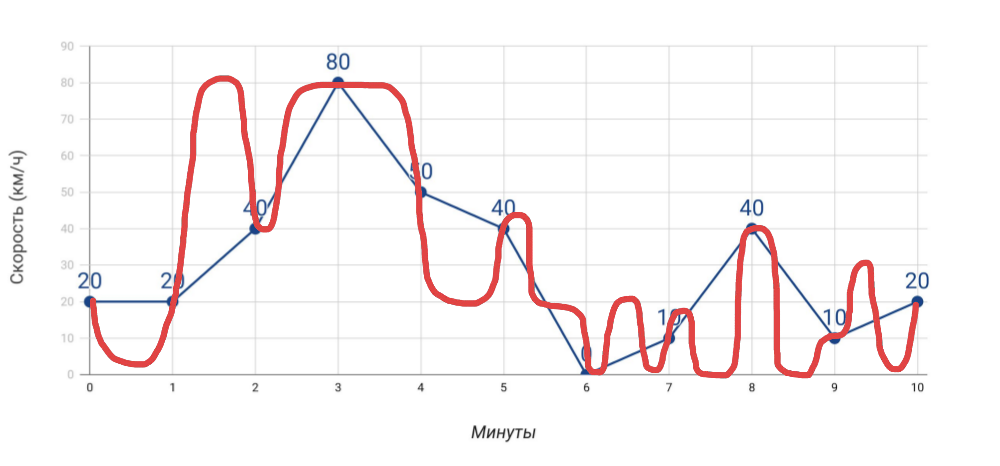
O que medimos e como realmente viajamos - Mais medições . Quanto mais indicadores diferentes obtivermos, mais preciso será o diagnóstico dos problemas ... mas apenas com a condição de que sejam indicadores realmente úteis, e não apenas tudo o que você conseguiu coletar.
- Alertas . Não há nada complicado no envio de alertas. No entanto, dois problemas típicos: a) alarmes falsos ocorrem com tanta frequência que paramos de responder a qualquer alerta; b) os alertas chegam em um momento em que é tarde demais (tudo já explodiu). E alcançar no monitoramento que esses problemas não surgiram é arte genuína!
O monitoramento é um conjunto de três camadas, cada uma das quais é crítica:
- Antes de tudo, este é um sistema que permite a prevenção de acidentes , a notificação de acidentes (se eles não puderam ser evitados) e o diagnóstico rápido de problemas.
- O que é necessário para isso? Dados precisos , gráficos úteis (olhe para eles e entenda onde está o problema), alertas relevantes (cheguem na hora certa e contenham informações claras).
- E, para que tudo isso funcione, é necessário um sistema de monitoramento .
A configuração adequada de um sistema de monitoramento que realmente funciona não é uma tarefa fácil, exigindo uma abordagem criteriosa da implementação, mesmo sem o Kubernetes. Mas o que acontece com sua aparência?
Especificações de monitoramento do Kubernetes
No. 1. Maior e mais rápido
O Kubernetes está mudando bastante porque a infraestrutura está ficando maior e mais rápida. Se anteriormente, com servidores comuns de ferro, seu número era muito limitado e o processo de adição era muito longo (demorava dias ou semanas); então, nas máquinas virtuais, o número de entidades aumentava significativamente e o tempo de sua introdução na batalha era reduzido para segundos.
Com o Kubernetes, o número de entidades cresceu em uma ordem de magnitude, sua adição é totalmente automatizada (gerenciamento de configuração é necessário, porque sem uma descrição, um novo pod simplesmente não pode ser criado), toda a infraestrutura se tornou muito dinâmica (por exemplo, os pods são excluídos e liberados toda vez são criados novamente).
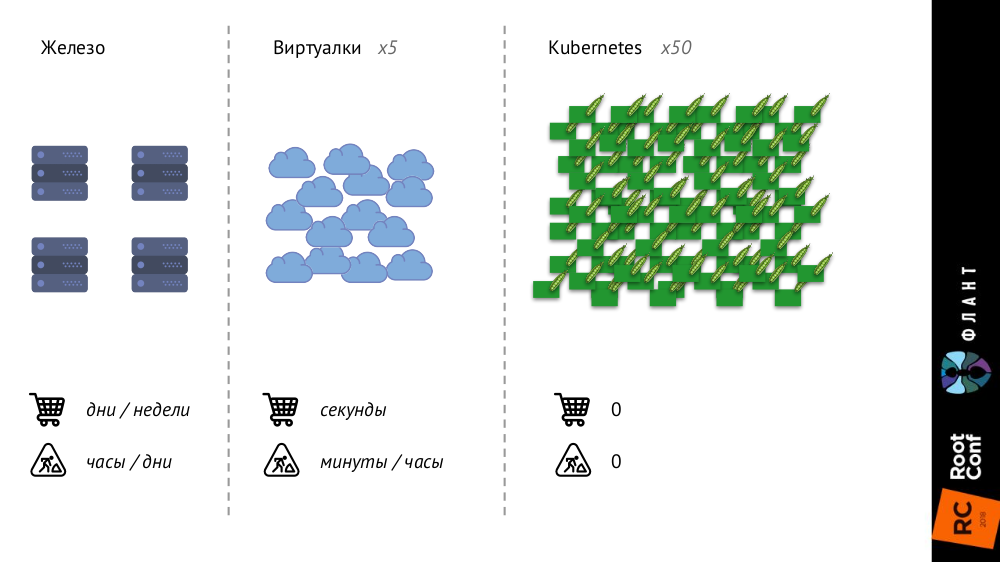
O que isso muda?
- Em princípio, paramos de observar vagens ou contêineres individuais - agora estamos interessados apenas em grupos de objetos .
- A descoberta de serviços se torna estritamente obrigatória , porque as "velocidades" já são tais que, em princípio, não podemos iniciar / excluir manualmente novas entidades, como antes, quando novos servidores foram comprados.
- A quantidade de dados está crescendo significativamente . Se métricas anteriores foram coletadas de servidores ou máquinas virtuais, agora de pods, cujo número é muito maior.
- A mudança mais interessante que chamei de " fluxo de metadados " e vou falar mais sobre isso.
Vou começar com esta comparação:
- Quando você envia seu filho para o jardim de infância, ele recebe uma caixa pessoal, que é atribuída a ele para o próximo ano (ou mais) e na qual seu nome é indicado.
- Quando você chega à piscina, seu armário não é assinado e é emitido para você por uma "sessão".
Portanto,
os sistemas clássicos de monitoramento pensam que são um jardim de infância , não uma piscina: eles assumem que o objeto de monitoramento os procurou para sempre ou por um longo tempo, e lhes dão armários de acordo. Mas as realidades em Kubernetes são diferentes: um pod chegou à piscina (isto é, foi criado), nadou (até uma nova implantação) e saiu (foi destruído) - tudo isso acontece de forma rápida e regular. Assim, o sistema de monitoramento deve entender que os objetos que monitora têm uma vida curta e devem ser capazes de esquecê-lo completamente no momento certo.
No. 2. A realidade paralela existe
Outro ponto importante - com o advento do Kubernetes, temos simultaneamente duas "realidades":
- Kubernetes mundo em que existem namespaces, implantações, pods, contêineres. Este é um mundo complexo, mas é lógico, estruturado.
- O mundo "físico", composto por muitos (literalmente - montões) de contêineres em cada nó.
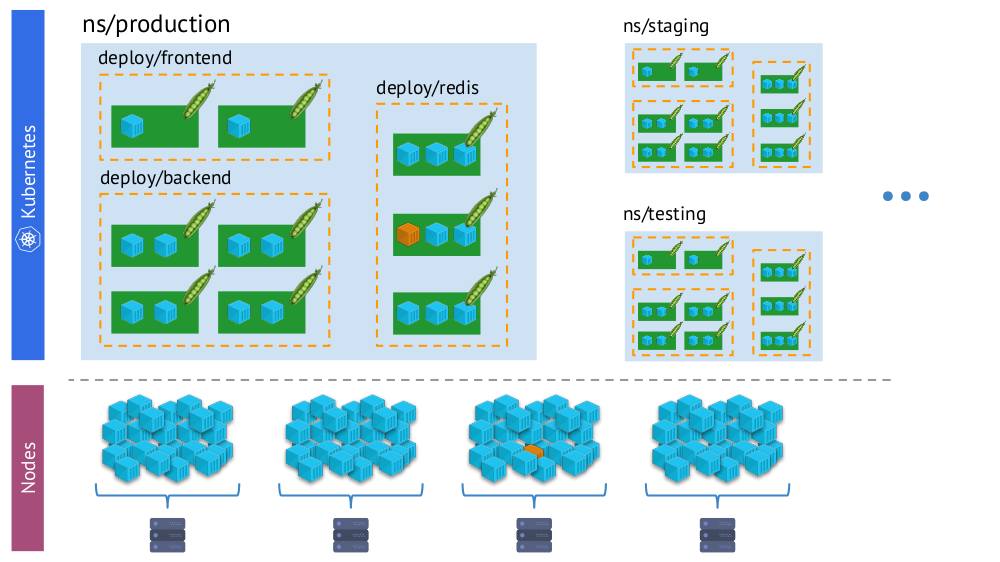 Um e o mesmo contêiner na “realidade virtual” do Kubernetes (acima) e no mundo físico dos nós (abaixo)
Um e o mesmo contêiner na “realidade virtual” do Kubernetes (acima) e no mundo físico dos nós (abaixo)E no processo de monitoramento, precisamos
comparar constantemente
o mundo físico dos contêineres com a realidade do Kubernetes . Por exemplo, quando olhamos para algum espaço para nome, queremos saber onde estão localizados todos os seus contêineres (ou os contêineres de uma de suas lareiras). Sem isso, os alertas não serão visuais e convenientes de usar - porque é importante entendermos quais objetos eles estão relatando.
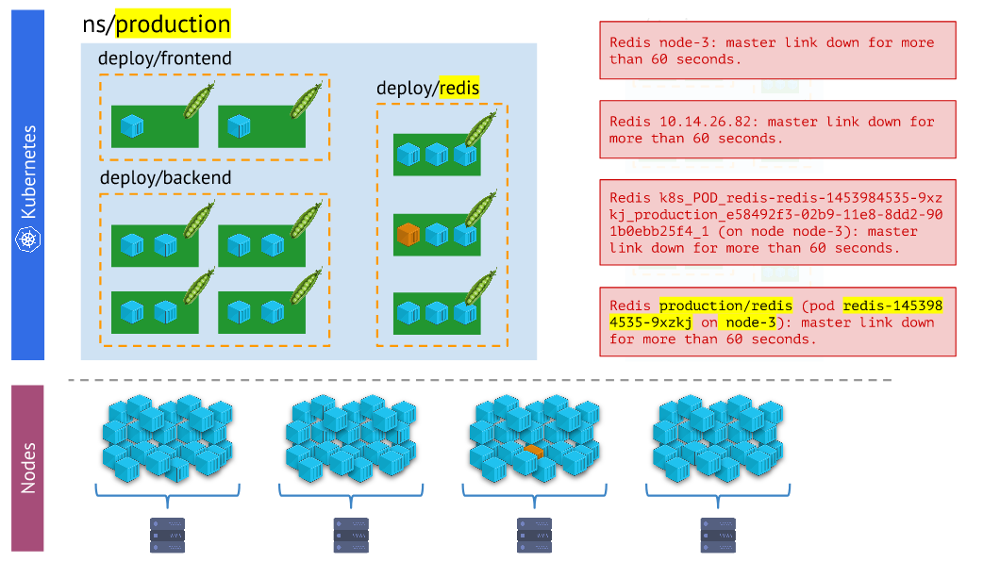 Diferentes tipos de alertas - o último é mais visual e conveniente no trabalho do que o restoAs conclusões
Diferentes tipos de alertas - o último é mais visual e conveniente no trabalho do que o restoAs conclusões aqui são:
- O sistema de monitoramento deve usar as primitivas internas do Kubernetes.
- Há mais de uma realidade: geralmente os problemas não acontecem com a lareira, mas com um nó específico, e precisamos entender constantemente em que tipo de "realidade" eles estão.
- Em um cluster, como regra, existem vários ambientes (além da produção), o que significa que isso deve ser levado em consideração (por exemplo, para não receber alertas noturnos sobre problemas no desenvolvedor).
Portanto, temos três condições necessárias para que tudo dê certo:
- Entendemos bem o que é monitoramento.
- Conhecemos seus recursos, que aparecem no Kubernetes.
- Adotamos o Prometeu.
E assim, para realmente funcionar, resta apenas fazer
muito esforço! A propósito, por que exatamente Prometeu?
Prometeu
Há duas maneiras de responder à pergunta sobre a escolha do Prometheus:
- Veja quem e o que geralmente é usado para monitorar o Kubernetes.
- Considere suas vantagens técnicas.
No primeiro, usei os dados da pesquisa do The New Stack (do e-book
O estado do ecossistema Kubernetes ), segundo o qual o Prometheus é pelo menos mais popular do que outras soluções (tanto de código aberto quanto de SaaS), e, se você observar, possui uma vantagem estatística em cinco vezes .
Agora vamos ver como o Prometheus funciona, em paralelo com a forma como seus recursos se combinam com o Kubernetes e resolvem desafios relacionados.
Como o Prometheus está estruturado?
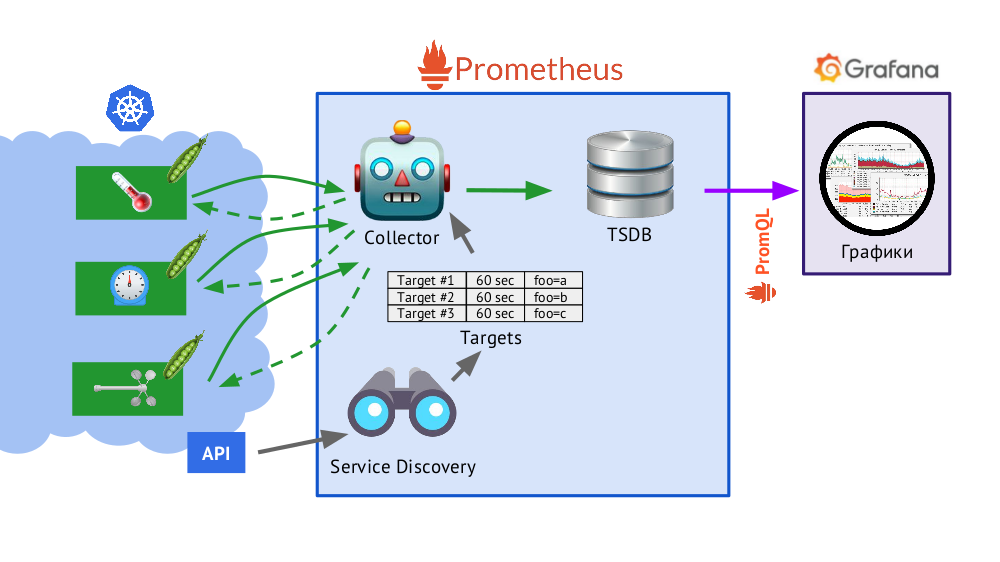
O Prometheus é escrito em Go e distribuído como um único arquivo binário, no qual tudo está embutido. O algoritmo básico para sua operação é o seguinte:

- O coletor lê a tabela de destinos , ou seja, uma lista de objetos a serem monitorados e a frequência de suas pesquisas (por padrão - 60 segundos).
- Depois disso, o coletor envia uma solicitação HTTP para cada pod de que você precisa e recebe uma resposta com um conjunto de métricas - pode haver cem, mil, dez mil ... Cada métrica possui um nome, valor e rótulos .
- A resposta recebida é armazenada no banco de dados TSDB , onde o registro de data e hora do recebimento e os rótulos do objeto do qual foi retirado são adicionados aos dados métricos recebidos.
Brevemente sobre TSDBTSDB - banco de dados de séries temporais (DB para séries temporais) on Go, que permite armazenar dados por um número especificado de dias e o faz com muita eficiência (em tamanho, memória e entrada / saída). Os dados são armazenados apenas localmente, sem cluster e replicação, o que é um plus (funciona de maneira simples e garantida) e um sinal de menos (não há dimensionamento horizontal do armazenamento), mas, no caso do Prometheus, o sharding é bem feito, federação - mais sobre isso posteriormente.
- Apresentado no esquema, o Service Discovery é um mecanismo de descoberta de serviço integrado ao Prometheus que permite receber dados (por meio da API Kubernetes) para criar uma tabela de objetivos pronta para uso.
Como é esta tabela? Para cada entrada, ele armazena o URL usado para obter métricas, a frequência de chamadas e rótulos.
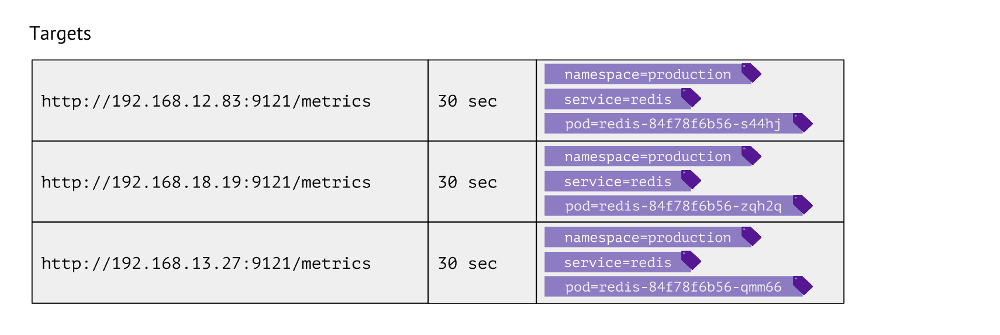
Os rótulos são usados para justapor os "mundos" de Kubernetes com o físico. Por exemplo, para encontrar um pod com o Redis, precisamos ter o namespace dos valores, o serviço (usado em vez da implantação devido aos recursos técnicos de um caso específico) e o pod real. Assim, esses três rótulos são armazenados nas entradas da tabela de metas para as métricas do Redis.
Essas entradas na tabela são formadas com base na
scrape_configs do Prometheus na qual os objetos de monitoramento são descritos: na seção
scrape_configs ,
scrape_configs definidas, indicando por quais rótulos procurar objetos para monitorar, como filtrá-los e quais rótulos devem ser registrados.
Quais dados o Kubernetes coleta?
- Primeiro, o assistente no Kubernetes é bastante complicado - e é essencial monitorar o estado de seu trabalho (kube-apiserver, kube-controller-manager, kube-scheduler, kube-scheduler, kube-etcd3 ...); além disso, está vinculado ao nó do cluster.
- Em segundo lugar, é importante saber o que está acontecendo no Kubernetes.Para fazer isso, obtemos dados de:
- kubelet - esse componente Kubernetes está sendo executado em cada nó do cluster (e se conecta ao assistente do K8s); o cAdvisor é incorporado a ele (todas as métricas por contêineres) e também armazena informações sobre volumes persistentes conectados;
- métricas do estado do kube - na verdade, este é o Exportador do Prometheus para a API do Kubernetes (permite obter informações sobre objetos armazenados no Kubernetes: pods, serviços, implantações etc.); por exemplo, não saberemos sem ele status de contêiner ou lareira);
- exportador de nó - fornece informações sobre o próprio nó, métricas básicas no sistema Linux (CPU, diskstats, meminfo etc. ).
- A seguir, estão os componentes do Kubernetes , como kube-dns, kube-prometheus-operator e kube-prometheus, ingress-nginx-controller, etc.
- A próxima categoria de objetos a monitorar é na verdade o software lançado no Kubernetes. Esses são serviços típicos de servidor como nginx, php-fpm, Redis, MongoDB, RabbitMQ ... Fazemos isso sozinhos para que, quando adicionamos determinados rótulos ao serviço, ele automaticamente comece a coletar os dados necessários, o que cria o painel atual no Grafana.
- Por fim, a categoria para todo o resto é personalizada . As ferramentas do Prometheus permitem automatizar a coleta de métricas arbitrárias (por exemplo, o número de pedidos) adicionando simplesmente um rótulo de
prometheus-custom-target à descrição do serviço.

Gráficos
Os dados recebidos
(descritos acima) são usados para enviar alertas e criar gráficos.
Desenhamos gráficos usando
Grafana . E um "detalhe" importante aqui é o
PromQL , a linguagem de consulta do Prometheus que se integra perfeitamente ao Grafana.
É bastante simples e conveniente para a maioria das tarefas
(mas, por exemplo, juntar junções já é inconveniente, mas você ainda precisa) . O PromQL permite que você resolva todas as tarefas necessárias: selecione rapidamente as métricas necessárias, compare valores, realize operações aritméticas nelas, agrupe, trabalhe com intervalos de tempo e muito mais. Por exemplo:

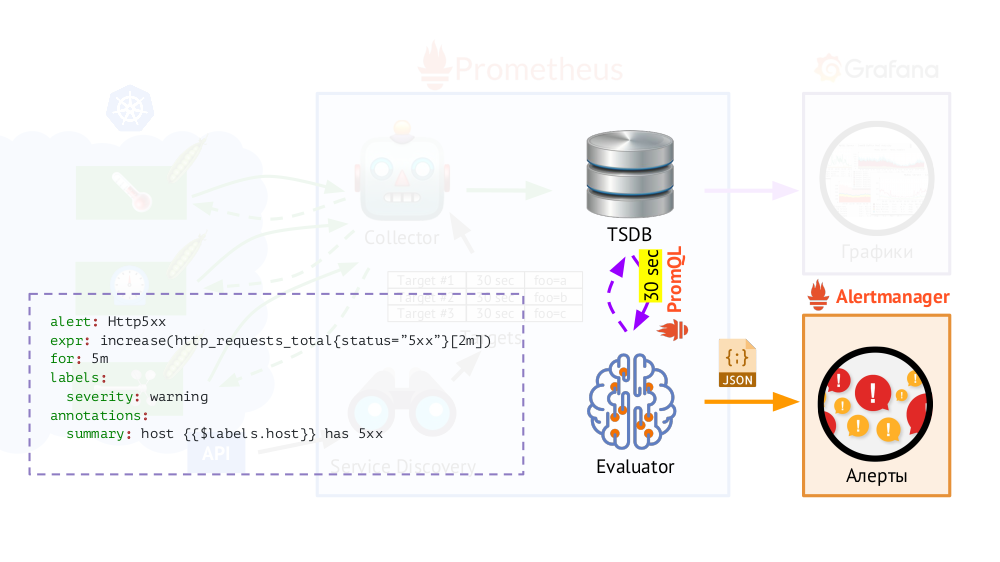
Além disso, o Prometheus possui um
Avaliador , que, usando o mesmo PromQL, pode acessar o TSDB com a frequência especificada. Por que isso? Exemplo: comece a enviar alertas nos casos em que, de acordo com as métricas disponíveis, tivermos um erro 500 no servidor da web nos últimos 5 minutos. Além dos rótulos que estavam na solicitação, o Avaliador adiciona outros dados aos alertas (como configuramos), após o que são enviados no formato JSON para outro componente do Prometheus -
Alertmanager .
O Prometheus periodicamente (uma vez a cada 30 segundos) envia alertas ao Alertmanager, que os deduplica (tendo recebido o primeiro alerta, ele será enviado e os próximos não serão enviados novamente).
 Nota : Nós não usamos o Alertmanager em casa, mas enviamos dados do Prometheus diretamente para o nosso sistema, com o qual nossos atendentes trabalham, mas isso não importa no esquema geral.
Nota : Nós não usamos o Alertmanager em casa, mas enviamos dados do Prometheus diretamente para o nosso sistema, com o qual nossos atendentes trabalham, mas isso não importa no esquema geral.Prometeu em Kubernetes: o panorama geral
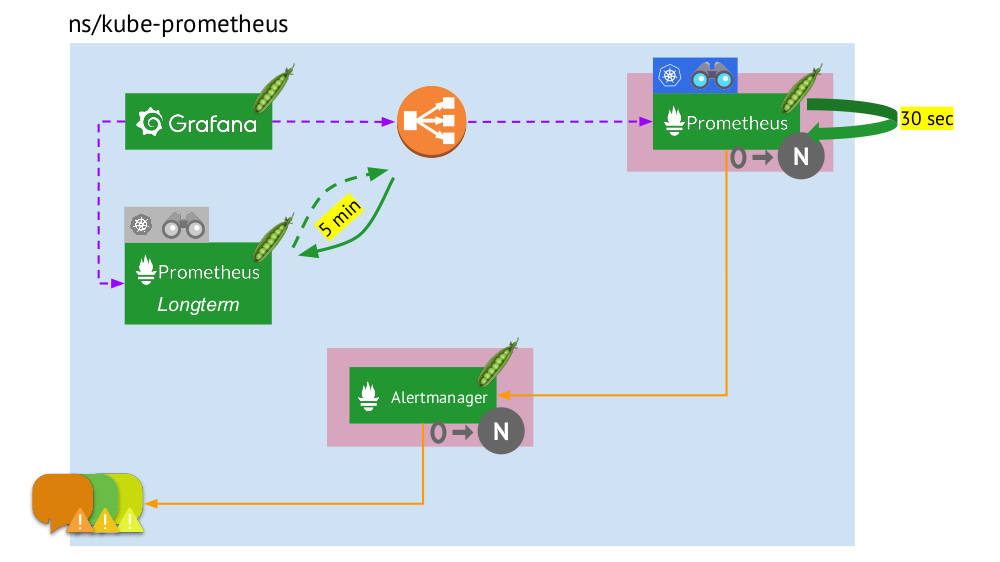
Agora vamos ver como esse pacote completo do Prometheus funciona no Kubernetes:
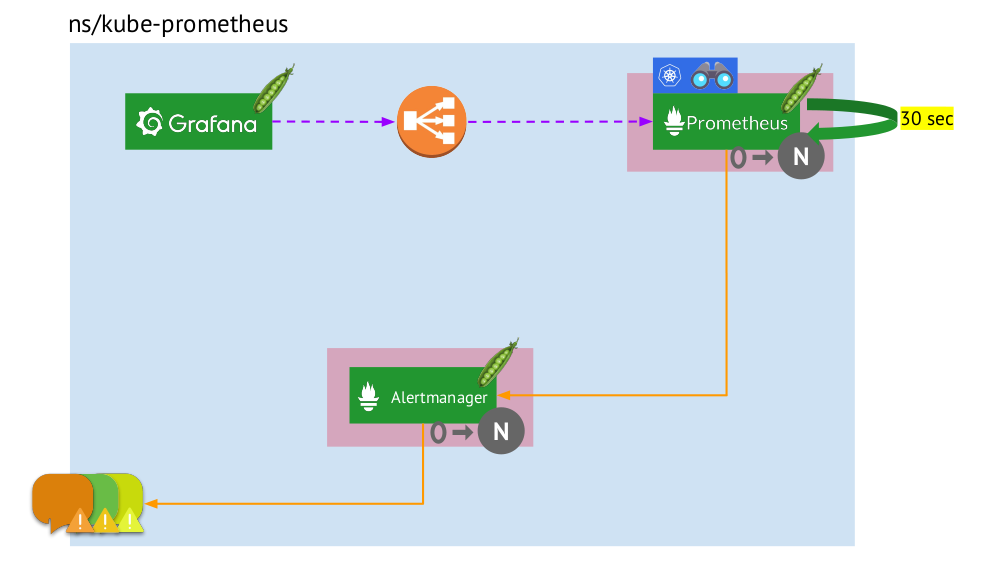
- O Kubernetes possui seu próprio namespace para Prometheus (temos o
kube-prometheus na ilustração) . - Esse espaço para nome hospeda o pod com a instalação do Prometheus, que a cada 30 segundos coleta métricas de todos os destinos recebidos por meio da descoberta de serviços no cluster.
- Ele também abriga um pod com o Alertmanager, que recebe dados do Prometheus e envia alertas (para correio, Slack, PagerDuty, WeChat, integração de terceiros e assim por diante ) .
- O Prometheus está enfrentando um balanceador de carga - um serviço regular em Kubernetes - e o Grafana acessa o Prometheus por meio dele. Para garantir a tolerância a falhas, o Prometheus usa vários pods com instalações do Prometheus, cada um dos quais coleta todos os dados e os armazena em seu TSDB. Através do balanceador, Grafana atinge um deles.
- O número de pods com o Prometheus é controlado pela configuração StatefulSet - geralmente fazemos no máximo dois pods, mas você pode aumentar esse número. Da mesma forma, o Alertmanager é implantado através do StatefulSet, cuja tolerância a falhas é necessária pelo menos 3 pods (já que é necessário um quorum para tomar decisões sobre o envio de alertas).
O que está faltando aqui? ..
Federação para Prometeu
Quando os dados são coletados a cada 30 (ou 60) segundos, o local para armazená-los rapidamente termina e, pior ainda, requer muitos recursos de computação (ao receber e processar um número tão grande de pontos do TSDB). Mas queremos armazenar e ter a capacidade de baixar informações por
grandes e e intervalos de tempo . Como conseguir isso?
É suficiente adicionar
mais uma instalação do Prometheus (a
longo prazo ) ao esquema geral, no qual o Service Discovery está desabilitado, e na tabela de objetivos há o único registro estático que leva ao Prometheus
principal (
principal ).
Isso é possível graças à federação : o Prometheus permite retornar os valores mais recentes de todas as métricas em uma única consulta. Portanto, a primeira instalação do Prometheus ainda funciona (acessa a cada 60 ou, por exemplo, 30 segundos) a todos os destinos no cluster Kubernetes e a segunda - uma vez a cada 5 minutos, recebe dados do primeiro e o armazena para poder assistir dados por um longo período ( mas sem detalhes profundos).
 A segunda instalação do Prometheus não precisa do Service Discovery e a tabela de objetivos consistirá em uma linha
A segunda instalação do Prometheus não precisa do Service Discovery e a tabela de objetivos consistirá em uma linha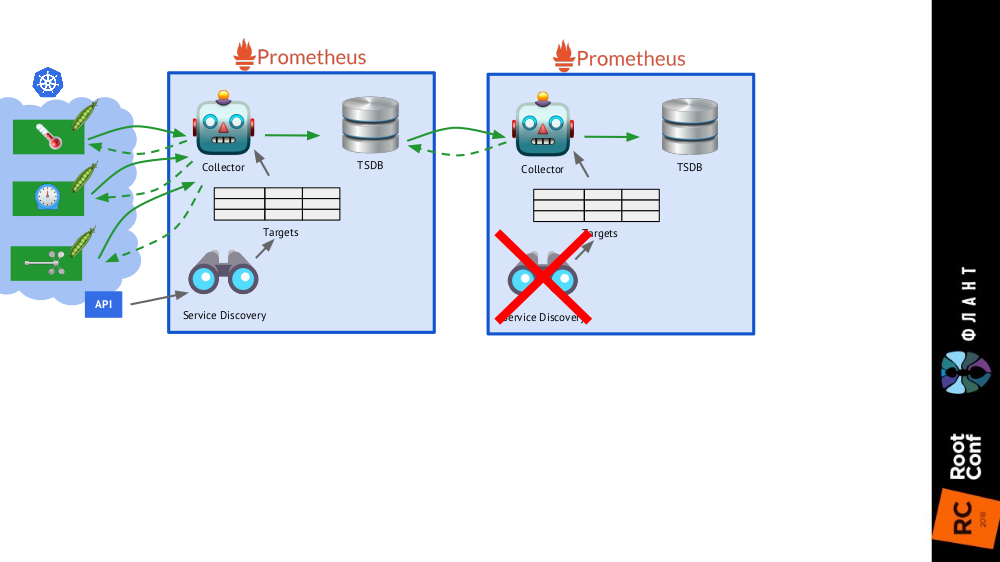 O quadro completo com as instalações do Prometheus de dois tipos: principal (superior) e de longo prazo
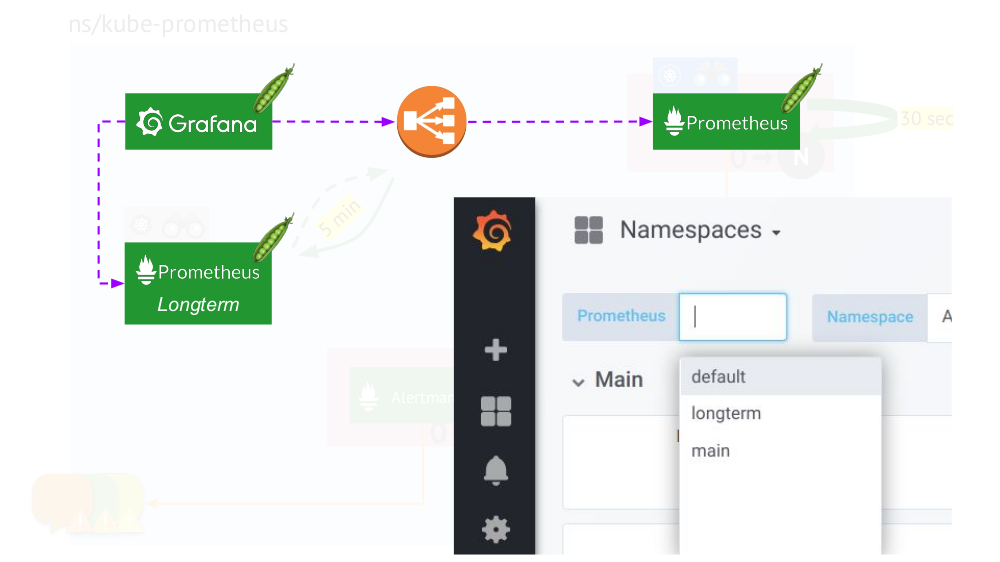
O quadro completo com as instalações do Prometheus de dois tipos: principal (superior) e de longo prazoO toque final é
conectar o Grafana às instalações do Prometheus e criar painéis de maneira especial para que você possa alternar entre as fontes de dados (
principal ou a
longo prazo ). Para fazer isso, usando o mecanismo de modelo, substitua a variável
$prometheus vez da fonte de dados em todos os painéis.
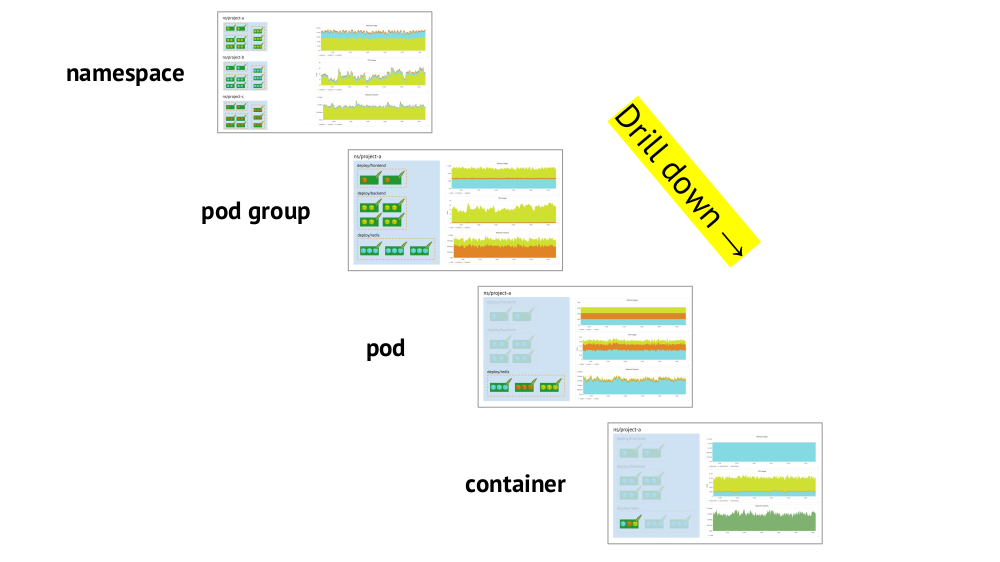
O que mais é importante nos gráficos?
Dois pontos-chave a serem considerados na organização de agendas são o suporte às primitivas do Kubernetes e a capacidade de
detalhar rapidamente da imagem geral (ou uma "exibição" inferior)) para um serviço específico e vice-versa.
O suporte a primitivos (namespaces, pods etc.) já foi mencionado - essa é uma condição necessária em princípio para um trabalho confortável nas realidades do Kubernetes. E aqui está um exemplo sobre drill down:
- Observamos os gráficos do consumo de recursos em três projetos (ou seja, três espaços para nome) - vemos que a parte principal da CPU (ou memória, ou rede, ...) fica no projeto A.
- Observamos os mesmos gráficos, mas já para os serviços do Projeto A: qual deles consome mais CPU?
- Passamos aos gráficos do serviço desejado: qual pod é "culpado"?
- Passamos aos gráficos do grupo desejado: qual recipiente é o "culpado"? Este é o objetivo desejado!
Sumário
- Declare com precisão o que é o monitoramento. (Deixe o “bolo de três camadas” servir como um lembrete disso ... assim como o fato de que assar com competência não é fácil, mesmo sem o Kubernetes!)
- Lembre-se de que o Kubernetes adiciona especificações obrigatórias: agrupamento de destinos, descoberta de serviços, grandes quantidades de dados, fluxo de metadados. Além disso:
- sim, alguns deles são magicamente resolvidos em Prometeu;
- no entanto, resta outra parte que precisa ser monitorada de maneira independente e cuidadosa.
E lembre-se de que o
conteúdo é mais importante que um sistema , ou seja, gráficos e alertas corretos são primários, e não o Prometheus (ou qualquer outro software similar) como tal.

Vídeos e slides
Vídeo da apresentação (cerca de uma hora):
Apresentação do relatório:
PS
Outros relatórios em nosso blog:
Você também pode estar interessado nas seguintes publicações: