Saudações à comunidade ilustre!
A repetição é a mãe da aprendizagem, e a compreensão da análise é uma habilidade muito útil para qualquer programador. Por isso, quero abordar esse tópico novamente e falar desta vez sobre análise usando o método de descida recursiva (LL), sem formalismos (você sempre pode usá-los posteriormente volte).
Como escreve o grande D. Strogov, "entender é simplificar". Portanto, para entender o conceito de análise usando o método de descida recursiva (também conhecido como análise LL), simplificamos a tarefa o máximo possível e escrevemos manualmente um analisador de um formato semelhante ao JSON, mas mais simples (se desejar, você pode expandi-lo para um analisador JSON completo, se quer se exercitar). Vamos escrever, tendo como base a ideia de
cortar o barbante .
Nos livros clássicos e nos cursos de design de compiladores, eles geralmente começam a explicar o tópico de análise e interpretação, destacando várias fases:
- Análise lexical: dividindo o texto de origem em uma matriz de substrings (tokens ou tokens)
- Análise: construindo uma árvore de análise a partir de uma matriz de tokens
- Interpretação (ou compilação): percorrendo a árvore resultante na ordem desejada (direta ou reversa) e executando algumas ações de interpretação ou geração de código em algumas etapas desta travessia
realmente não é assimporque no processo de análise, já temos uma sequência de etapas, que é uma sequência de visitas aos nós da árvore, a própria árvore de forma explícita pode não existir, mas ainda não iremos aprofundar. Para quem quer ir mais fundo, existem links no final.
Agora, quero usar uma abordagem ligeiramente diferente para o mesmo conceito (análise de LL) e mostrar como você pode construir um analisador de LL com base na idéia de cortar uma string: os fragmentos são cortados da string original durante a análise, tornam-se menores e depois analisados exposto o resto da linha. Como resultado, chegamos ao mesmo conceito de descida recursiva, mas de uma maneira ligeiramente diferente do que normalmente é feito. Talvez esse caminho seja mais conveniente para entender a essência da ideia. E se não, ainda é uma oportunidade de observar uma descida recursiva de um ângulo diferente.
Vamos começar com uma tarefa mais simples: existe uma linha com delimitadores e quero escrever uma iteração sobre seus valores. Algo como:
String names = "ivanov;petrov;sidorov"; for (String name in names) { echo("Hello, " + name); }
Como isso pode ser feito? A maneira padrão é converter a sequência delimitada em uma matriz ou lista usando String.split (em Java) ou names.split (",") (em javascript) e iterar através da matriz. Mas vamos imaginar que não queremos ou não podemos usar a conversão em uma matriz (por exemplo, de repente, se programarmos na linguagem de programação AVAJ ++, na qual não há estrutura de dados de "matriz"). Você ainda pode escanear a string e rastrear os delimitadores, mas também não usarei esse método, porque torna o código do loop de iteração complicado e, mais importante, vai contra o conceito que quero mostrar. Portanto, relacionaremos a uma string delimitada da mesma maneira que relacionamos a listas na programação funcional. E lá eles sempre definem as funções head (obtém o primeiro elemento da lista) e tail (obtém o restante da lista). A partir dos primeiros dialetos do Lisp, onde essas funções eram chamadas de maneira horrível e não intuitiva: car e cdr (car = conteúdo do registro de endereços, cdr = conteúdo do registro de decréscimo. Lendas antigas são profundas, sim, eheheh.).
Nossa linha é uma linha delimitada. Destaque os divisores em roxo:
E realce os itens da lista em amarelo:

Assumimos que nossa linha é mutável (pode ser alterada) e escrevemos uma função:
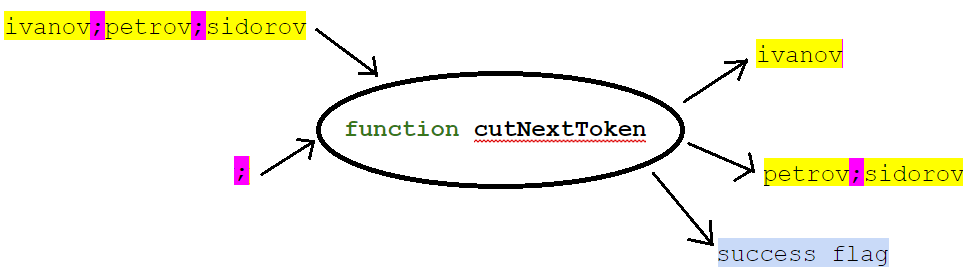
Sua assinatura, por exemplo, pode ser:
public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token)
Na entrada da função, fornecemos uma lista (na forma de uma string com delimitadores) e, de fato, o valor do delimitador. Na saída, a função retorna o primeiro elemento da lista (segmento de linha para o primeiro separador), o restante da lista e o sinal de se o primeiro elemento foi retornado. Nesse caso, o restante da lista é colocado na mesma variável em que estava a lista original.
Como resultado, tivemos a oportunidade de escrever assim:
StringBuilder names = new StringBuilder("ivanov;petrov;sidorov"); StringBuilder name = new StringBuilder(); while(cutNextToken(names, ";", name)) { System.out.println(name); }
Saídas conforme o esperado:
ivanov
Petrov
sidorov
Fizemos sem conversão para ArrayList, mas estragamos a variável names, e agora ela possui uma string vazia. Ainda não parece muito útil, como se eles mudassem o furador de sabão. Mas vamos mais longe. Lá veremos por que era necessário e para onde nos levaria.
Agora vamos analisar algo mais interessante: uma lista de pares de valores-chave. Essa também é uma tarefa muito comum.
StringBuilder pairs = new StringBuilder("name=ivan;surname=ivanov;middlename=ivanovich"); StringBuilder pair = new StringBuilder(); while (cutNextToken(pairs, ";", pair)) { StringBuilder paramName = new StringBuilder(); StringBuilder paramValue = new StringBuilder(); cutNextToken(pair, "=", paramName); cutNextToken(pair, "=", paramValue); System.out.println("param with name \"" + paramName + "\" has value of \"" + paramValue + "\""); }
Conclusão:
param with name "name" has value of "ivan" param with name "surname" has value of "ivanov" param with name "middlename" has value of "ivanovich"
Também é esperado. E o mesmo pode ser alcançado com o String.split, sem cortar as linhas.
Mas digamos que agora queríamos complicar nosso formato e passar de um valor-chave simples para um formato aninhado que lembra o JSON. Agora queremos ler algo assim:
{'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}}
Que separador separa? Se for uma vírgula, em um dos tokens teremos a linha
'birthdate':{'year':'1984'
Obviamente não é o que precisamos. Portanto, devemos prestar atenção à estrutura da linha que queremos analisar.
Começa com uma chaveta e termina com uma chaveta (combinada com ela, o que é importante). Dentro desses colchetes há uma lista de pares 'chave': 'valor', cada par é separado do próximo par por vírgula. A chave e o valor são separados por dois pontos. Uma chave é uma sequência de letras entre apóstrofos. O valor pode ser uma sequência de caracteres entre apóstrofos ou a mesma estrutura, começando e terminando com chaves emparelhadas. Chamamos essa estrutura de palavra "objeto", como é habitual em JSON.
Acabamos de descrever informalmente a gramática do nosso formato semelhante a JSON. Normalmente, as gramáticas são descritas de maneira inversa, formal e a notação BNF ou suas variações são usadas para escrevê-las. Mas agora eu posso ficar sem ele e veremos como você pode "cortar" essa linha para que ela possa ser analisada de acordo com as regras desta gramática.
De fato, nosso "objeto" começa com uma chave de abertura e termina com um par que a fecha. O que uma função que analisa esse formato pode fazer? Provavelmente, o seguinte:
- verifique se a sequência passada começa com uma chave de abertura
- verifique se a sequência passada termina com um par de chaves de fechamento
- se ambas as condições forem verdadeiras, corte os colchetes de abertura e fechamento e o que resta, passe para a função que analisa a lista de pares 'chave': 'valor'
Observe: as palavras “função analisando este formato” e “função analisando a lista de pares 'chave': 'valor'” apareceram. Temos dois recursos! Essas são as mesmas funções que, na descrição clássica do algoritmo de descida recursiva, são chamadas de “funções de análise de símbolos não-terminais” e que dizem que “para cada símbolo não-terminal, é criada sua própria função de análise”. O que, de fato, analisa isso. Podemos nomear eles, digamos, parseJsonObject e parseJsonPairList.
Agora também precisamos prestar atenção, pois temos o conceito de "parênteses", além do conceito de "separador". Se cortar uma linha para o próximo separador (dois pontos entre uma chave e um valor, uma vírgula entre os pares “chave: valor”), a função cutNextToken foi suficiente para nós, agora que podemos usar não apenas uma string, mas também um objeto, precisamos função “cortar para o próximo par de colchetes”. Algo assim:

Essa função corta um fragmento da linha do colchete de abertura para o par que o fecha, dados os parênteses, se houver. Obviamente, você não pode se limitar a colchetes, mas use uma função semelhante para cortar várias estruturas de blocos que podem ser aninhadas: blocos de operadores começam..end, if..endif, for..endfor e similares.
Vamos desenhar graficamente o que acontecerá com a string. Cor turquesa - isso significa que digitalizamos a linha para o símbolo destacado em turquesa para determinar o que devemos fazer em seguida. Violeta é “o que cortar, é quando cortamos os fragmentos destacados em violeta da linha e continuamos analisando o que resta dela ainda mais.

Para comparação, a saída do programa (o texto do programa é fornecido no apêndice) que analisa esta linha:
Demonstração de análise de estrutura semelhante a JSON
ok, about to parse JSON object {'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'}} ok, about to parse pair list 'name':'ivan','surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'name' found VALUE of type STRING:'ivan' ok, about to parse pair list 'surname':'ivanov','birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'surname' found VALUE of type STRING:'ivanov' ok, about to parse pair list 'birthdate':{'year':'1984','month':'october','day':'06'} found KEY: 'birthdate' found VALUE of type OBJECT:{'year':'1984','month':'october','day':'06'} ok, about to parse JSON object {'year':'1984','month':'october','day':'06'} ok, about to parse pair list 'year':'1984','month':'october','day':'06' found KEY: 'year' found VALUE of type STRING:'1984' ok, about to parse pair list 'month':'october','day':'06' found KEY: 'month' found VALUE of type STRING:'october' ok, about to parse pair list 'day':'06' found KEY: 'day' found VALUE of type STRING:'06'
A qualquer momento, sabemos o que esperamos encontrar em nossa linha de entrada. Se inserimos a função parseJsonObject, esperamos que o objeto tenha sido passado para lá, e podemos verificar isso pela presença de um parêntese de abertura e fechamento no início e no final. Se inserimos a função parseJsonPairList, esperamos uma lista de pares "chave: valor" lá e depois de "mordermos" a chave (antes do separador ":"), esperamos que a próxima coisa que "mordamos" seja valor. Podemos observar o primeiro caractere do valor e tirar uma conclusão sobre seu tipo (se for o apóstrofo, então o valor será do tipo "string", se o colchete de abertura for o valor do tipo "objeto").
Assim, cortando fragmentos da cadeia, podemos analisá-la pelo método de análise de cima para baixo (descida recursiva). E quando podemos analisar, podemos analisar o formato que precisamos. Ou crie seu próprio formato conveniente para nós e desmonte-o. Ou crie uma linguagem específica de domínio (DSL) para nossa área específica e crie um intérprete para ela. E para construí-lo corretamente, sem decisões torturadas em regexp ou máquinas de estado criadas por si mesmo que surgem para programadores que estão tentando resolver algum problema que requer análise, mas que não possuem o material.
Aqui. Parabéns a todos pelo próximo verão e desejo-lhe felicidades, amor e parsers funcionais :)
Para leitura adicional:
Ideológico: alguns artigos longos, mas que valem a pena, por Steve Yeegge:
Comida rica para programadoresAlgumas citações de lá:
Você aprende compiladores e começa a escrever suas próprias DSLs ou obtém um idioma melhor
A primeira grande fase do pipeline de compilação é a análise
O problema de PinóquioCitação de lá:
Conversões de tipo, estreitamento e ampliação de conversões, funções de amigo para ignorar as proteções de classe padrão, colocando minilangues em strings e analisando-as manualmente , existem dezenas de maneiras de ignorar os sistemas de tipos em Java e C ++ e os programadores as usam o tempo todo , porque (pouco eles sabem) eles estão realmente tentando criar software, não hardware.
Técnico: dois artigos sobre análise sobre a diferença entre as abordagens LL e LR:
Análise LL e LR DesmistificadaLL e LR no contexto: por que as ferramentas de análise são difíceisE ainda mais profundamente no tópico: como escrever um intérprete Lisp em C ++
Intérprete Lisp em 90 linhas de C ++Aplicação. Código de exemplo (java) que implementa o analisador descrito no artigo: package demoll; public class DemoLL { public boolean cutNextToken(StringBuilder svList, String separator, StringBuilder token) { String s = svList.toString(); if (s.trim().isEmpty()){ return false; } int sepIndex = s.indexOf(separator); if (sepIndex == -1) {