 Postado por Igor Masternaya, Desenvolvedor Sênior, DataArt Java Community Leader
Postado por Igor Masternaya, Desenvolvedor Sênior, DataArt Java Community LeaderDe 18 a 19 de maio, o JEEÑonf foi realizado em Kiev, um dos eventos mais esperados para toda a comunidade Java da Europa Oriental. A DataArt fez parceria com a conferência. Oradores de todo o mundo falaram em quatro estágios: Volker Simonis, representante da SAP na
JCP e colaborador do OpenJDK, Jürgen Höller, engenheiro-chefe da Pivotal, pai do amado Spring Framework, Klaus Ibsen, criador do Apache Camel, e Hugh McKee, evangelista da Lightbend.
A programação foi muito movimentada: em dois dias, mais de 50 apresentações, 45 minutos cada. 10 minutos de intervalo - e corra para um novo relatório. Levará muito tempo para assistir a todos os vídeos quando eles aparecerem na rede. Portanto, descreverei brevemente os relatórios que achei mais interessantes e que visitei pessoalmente.
15 anos de primavera
A conferência foi aberta por Jürgen Höller. Ele falou sobre a história de 15 anos (!) Do Spring Framework, desde as configurações XML “favoritas” na versão 0.9 até o reativo Spring WebFlux, que surgiu de projetos de pesquisa influenciados pelo
Manifesto Reativo . Jürgen falou sobre a coexistência do Spring MVC e Spring WebFlux no Spring WEB, explicou por que eles decidiram não integrá-los. O fato é que a principal abstração do Spring MVC é a API Servlet 3.0 e o IO de bloqueio, enquanto o Spring WebFlux usa a abstração de Streams Reativos e o IO sem bloqueio. Você pode executar seu serviço no SpringWebFlux em qualquer servidor que suporte IO sem bloqueio: Netty, novas versões do Tomcat (> 8.5), Jetty. Criar controladores WebFlux reativos não é muito diferente de criá-los usando o Spring MVC, mas ainda existem diferenças. Ao processar uma solicitação do usuário, o controlador reativo não a processa no sentido usual, mas cria um pipeline para processar a solicitação. O distribuidor chama o método do controlador, que cria um pipeline e o fornece imediatamente como um fluxo do editor. O fluxo do editor no Reactive Spring é apresentado como duas abstrações: Flux / Mono. O fluxo retorna um fluxo de objetos, enquanto o Mono sempre retorna um único objeto.
Jürgen também mencionou a conveniência de usar o estilo Java 8 ao trabalhar com o Spring 5.0 e prometeu um candidato ao lançamento do Spring 5.1 em julho de 2018 e um lançamento em setembro, que oferecerá suporte ao Java 11 e funcionará no ajuste fino dos novos recursos do Spring 5.0
Integração Python / Java
Havia muitos relatórios, e escolher o mais interessante no próximo slot era difícil. As descrições eram igualmente interessantes, por isso confiei em meus instintos e decidi ouvir Tamas Rozman, vice-presidente da BlackRock da Hungria. Mas seria melhor se eu escutasse novamente sobre o Sourcing de Eventos e o CQRS. A julgar pela descrição, a empresa está envolvida na Data Science para um grande fundo de investimento. O objetivo do relatório era mostrar como eles criaram um sistema escalável e estável, igualmente conveniente para analistas de dados com seu Python e para desenvolvedores Java do sistema principal. No entanto, parecia-me duvidoso que o sistema construído realmente se mostrasse conveniente. Para fazer amizade com Python e Java, os engenheiros da BlackRock tiveram a idéia de iniciar um intérprete Python como um processo a partir de um aplicativo Java. Eles chegaram a isso por várias razões:
- O Jython (Python na JVM) não se encaixou devido à base de código desatualizada 2.7 vs CPython 3.6.
- Eles consideraram a opção de reescrever a lógica da Ciência de Dados em Java como um processo muito longo.
- O Apache Spark decidiu não aceitar, porque, como o orador explicou, você não pode misturar cargas de trabalho escritas em Java e Python. Embora não esteja claro por que a UDF e a UDFA não se encaixam [ 2 ]. Além disso, o Spark não se encaixava, porque eles já tinham algum tipo de estrutura de trabalho e realmente não queriam introduzir uma nova. E, como se viu, eles também não têm Big Data e todo o processamento se resume a estatísticas de patéticos arquivos de 100 MB.
A comunicação do Java com o processo Python foi organizada usando arquivos mapeados na memória (um arquivo é usado como arquivo de dados de entrada) e comandos (o segundo arquivo é a saída do processo Python). Assim, a comunicação era algo na forma de:
Java: calcExr | 1 + javaFunc (sqrt (36))
Python: 1 + javaFunct | 6
Java: 1 + sucesso | 64
Python: sucesso | 65
Os principais problemas dessa integração, Tamas chamou de sobrecarga durante a serialização e desserialização dos parâmetros de entrada / saída.

CDS do aplicativo Java 10
Após uma apresentação sobre os meandros da execução do Python, eu realmente queria ouvir algo profundamente técnico do mundo Java. Então, fui ao relatório de Volker Simonis, no qual ele falou sobre o recurso de compartilhamento de dados da classe Application do
Java 10+ . No mundo moderno, construído em microsserviços no Docker, a capacidade de compartilhar Java Codecache e Metaspace acelera o lançamento do aplicativo e economiza memória. A imagem mostra os resultados do lançamento de tomates dockerized com um arquivo compartilhado / compartilhado das classes Tomcat. Como você pode ver, para o segundo processo, algumas páginas na memória já estão marcadas como shared_clean - o que significa que o processo atual e pelo menos um processo (o segundo tomcat em execução) se refere a eles.

Detalhes sobre como jogar com o CDS no OpenJDK 10 podem ser encontrados em:
App CDS . Além de dividir as classes de aplicativos entre os processos, no futuro está planejado o compartilhamento de cadeias
internas no
JEP-250 .
Principais limitações do AppCDS:
Não funciona com classes de até 1,5.
- Você não pode usar classes carregadas de arquivos (apenas arquivos .jar).
- Classes modificadas pelo carregador de classes não podem ser usadas.
- Classes carregadas por vários carregadores de classe podem ser reutilizadas apenas uma vez.
- A reescrita do código de bytes não funciona, o que pode levar a quedas de desempenho de até 2%. JDK-8074345

Pipeline de processamento de idioma natural com Apache Spark
O relatório sobre a PNL e o Apache Spark foi apresentado por Vitaliy Kotlyarenko - engenheiro da Grammarly. Vitaliy mostrou como a Grammarly protótipo de NLP-Jobs no Apache Zeppelin. Um exemplo foi a construção de um pipeline simples para modelagem temática com base no algoritmo
LDA do arquivo
comum da Internet de
rastreamento . Os resultados da modelagem de tópicos foram usados para filtrar sites com conteúdo inadequado, como um exemplo da função de controle dos pais. Para criar o pipeline, usamos os scripts Terraform e o cluster do
AWS EMR Spark, que permitem implantar o Spark Cluster com o YARN na Amazon. Esquematicamente, o pipeline fica assim:
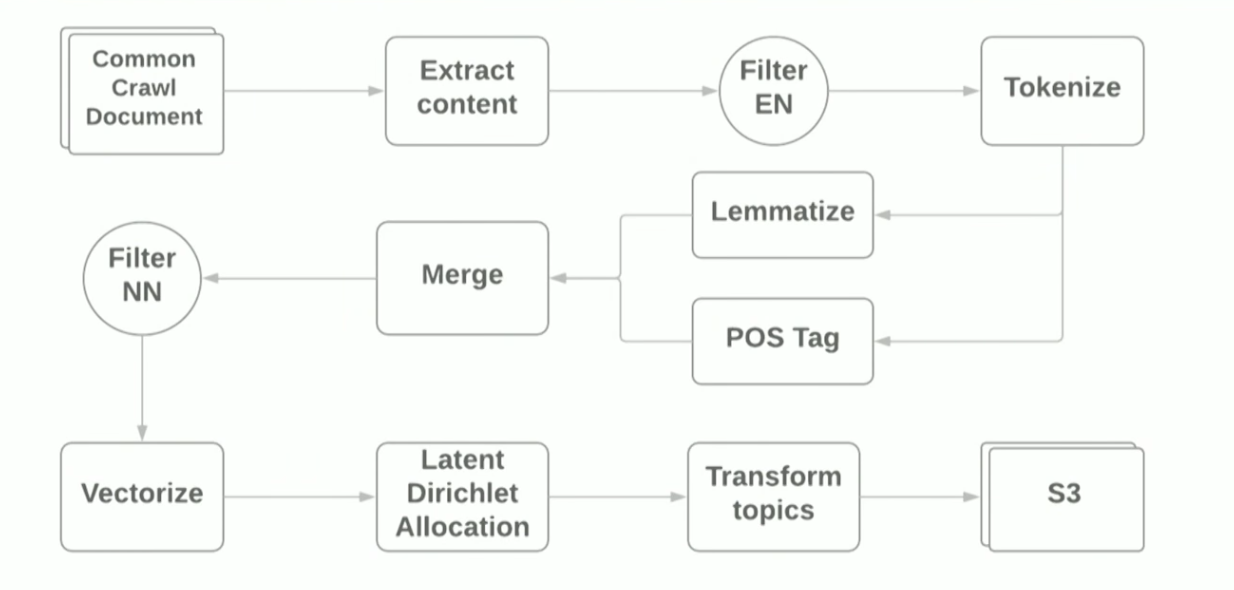
O objetivo do relatório era mostrar que o uso de estruturas modernas para criar um protótipo para tarefas de ML é bastante simples; no entanto, usando bibliotecas padrão, você ainda encontra dificuldades. Por exemplo:
- Na primeira etapa da leitura dos arquivos WARC usando a biblioteca HadoopInputFormat , o IllegalStateExceptions às vezes travava devido a cabeçalhos de arquivo incorretos, a biblioteca precisava ser reescrita e os arquivos incorretos ignorados.
- As dependências da goiaba - a biblioteca de definição de linguagem - colidiram com as dependências que o Spark arrasta consigo mesma. O Java 8 ajudou, com a ajuda da qual foi possível lançar dependências na goiaba na biblioteca usada.
Durante a demonstração, monitoramos a execução da tarefa usando a interface do usuário padrão do Spark e o subsistema de monitoramento
Ganglia , que fica automaticamente disponível quando implantado no AWS EMR. O autor concentrou-se no Server Load Distribution, que mostra a distribuição de carga entre os nós no cluster, e deu conselhos gerais sobre como otimizar o trabalho do Spark Job: aumentar o número de partições, otimizar a serialização de dados e analisar os logs do GC. Você pode ler mais sobre como otimizar trabalhos do Spark
aqui . Os arquivos de origem da demonstração podem ser encontrados no
github do autor do relatório.
Graal, Truffle, SubstrateVM e outras vantagens: o que são e por que você precisa deles
O mais esperado para mim foi um relatório de Oleg Chirukhin do JUG.ru. Ele contou como otimizar o código finalizado usando o Graal. O que é o Graal? The Grail é uma marca do
Oracle Labs que combina o compilador JIT (just-in-time), a estrutura para escrever linguagens DSL - Truffle - e a JVM especial (
SubstrateVM ) - uma máquina virtual universal
de mundo fechado na qual você pode escrever em JavaScript, Ruby, Python, Java, Scala. O relatório enfocou o compilador JIT e seus testes em produção.
Primeiro, lembre-se do processo de execução de código pela máquina Java e observe que o Java já possui dois compiladores: C1 (compilador do cliente) e C2 (compilador do servidor). Graal pode ser usado como um compilador C2.
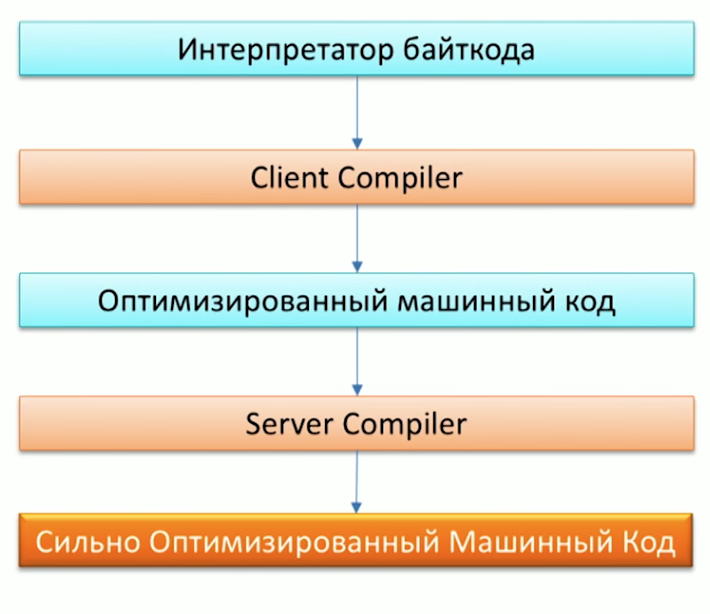
Quando perguntado por que precisávamos de outro compilador, um dos funcionários do Oracle Labs, Dr. Chris Seaton, respondeu muito bem no artigo
Entendendo como Graal Funciona . Em resumo, a idéia original do projeto Graal, bem como do projeto
Metropolis , é reescrever partes do código da JVM escrito em C ++ em Java. Isso tornará possível no futuro complementar convenientemente o código. Por exemplo, uma das otimizações -
Análise de escape artificial - já está no Graal, mas não no Hotspot -
porque expandir o código Graal é muito mais fácil do que o código C2 .
Parece ótimo, mas como isso funcionará na prática no meu projeto, você pergunta? Graal é adequado para projetos:
- Que desarrumam muito, criando muitos objetos pequenos.
- Escrito no estilo do Java 8, com um monte de fluxos e lambdas.
- Usando linguagens diferentes: Ruby, Java, R.
Um dos primeiros em produção, o Graal começou a ser usado no Twitter. Você pode ler mais sobre isso em uma entrevista com Christian Talinger, publicada em Habré (
entrevista_1 e
entrevista_2 ). Lá, ele explica que, ao substituir o C2 pelo Graal, o Twitter começou a economizar cerca de 8% da utilização da CPU, o que é bastante bom, considerando o tamanho da organização.
Na conferência, também pudemos verificar a velocidade do Graal lançando um dos pontos de referência da Scala - o
Scala DaCapo . Como resultado, no Graal, a referência passou em ~ 7000 ms e em uma JVM regular em ~ 14000 ms! Por que isso aconteceu, você pode ver olhando para os testes do gclog. O número de falhas na Alocação ao usar o Graal é significativamente menor que o do Hotspot. No entanto, você ainda não pode dizer que o Graal será a solução para os problemas de desempenho do seu aplicativo Java. Oleg também mostrou uma história de fracasso em seu relatório, comparando o trabalho do
Apache Ignite sob o Graal e sem ele - não houve alteração perceptível no desempenho.

Projetando microsserviços tolerantes a falhas
Outro relatório sobre arquitetura de microsserviço à prova de falhas foi lido por Orkhan Gasimov do AppsFlyer. Ele introduziu padrões de design populares para criar aplicativos distribuídos. Podemos muito bem conhecer muitos deles, mas andar por aí e relembrar cada um deles não vai doer nada.
Os principais problemas de tolerância a falhas de serviços com os quais os padrões descritos no relatório são chamados a combater são: rede, picos de carga, mecanismos RPC de comunicação entre serviços.
Para resolver problemas com a rede, quando um dos serviços não estiver mais disponível, precisamos da capacidade de substituí-lo rapidamente por outro. Na prática, isso pode ser conseguido com várias instâncias do mesmo serviço e uma descrição de caminhos alternativos para essas instâncias, que é um padrão de
descoberta de serviço . Envolver-se em serviços de
pulsação e registrar novos serviços será uma instância separada - Service Registry. É costume usar o conhecido
tratador ou
cônsul como registro de serviço. Os quais, por sua vez, também têm uma natureza distribuída e suportam tolerância a falhas.
Tendo resolvido os problemas com a rede, passamos ao problema de picos de carga quando alguns serviços estão sob carga e processam solicitações muito mais lentamente do que o modo normal. Para resolvê-lo, você pode usar o padrão de
dimensionamento automático . Ele assumirá não apenas a tarefa de dimensionar automaticamente serviços altamente carregados, mas também interromperá as instâncias após o período de pico de carregamento.
O capítulo final do relatório do autor era uma descrição de possíveis problemas de comunicação interna entre serviços da RPC. Urahan prestou atenção especial à tese "O usuário não deve esperar por uma mensagem de erro por muito tempo". Essa situação pode surgir se sua solicitação for processada pela cadeia de serviços e o problema estiver no final da cadeia: consequentemente, o usuário pode esperar que a solicitação seja processada por cada um dos serviços da cadeia e apenas no último estágio receber um erro. O pior de tudo é que, se o serviço final estiver sobrecarregado e, após uma longa espera, o cliente receberá um HTTP-ERROR: 500 sem sentido.
Para combater essas situações, você pode usar
Timeout s, no entanto, solicitações que ainda podem ser processadas corretamente podem cair no tempo limite. Para fazer isso, a lógica de tempo limite pode ser complicada e um valor limite especial para o número de erros de serviço por intervalo de tempo pode ser adicionado. Quando o número de erros excede o valor limite, entendemos que o serviço está sob carga e o consideramos indisponível, proporcionando o tempo necessário para lidar com as tarefas atuais. Esta abordagem descreve o padrão do
disjuntor . Você também pode usar o CircuitBreaker.html "> Circuit Beaker como uma métrica adicional para o monitoramento, o que permite responder rapidamente a possíveis problemas e identificar claramente quais cadeias de serviço estão enfrentando. Para fazer isso, cada chamada de serviço deve estar envolvida no disjuntor.
Também no relatório, o autor lembrou o padrão de
redundância N-Modular , projetado para "processar solicitações mais rapidamente, se possível", e forneceu um belo exemplo de seu uso para validar o endereço de um cliente. A solicitação em seu sistema através do cache de endereços foi enviada imediatamente a vários provedores de mapas geográficos, como resultado da qual a resposta mais rápida venceu.
Além dos padrões descritos, foram mencionados os seguintes:
- Padrão Fast Path , que pode ser aplicado, por exemplo, ao armazenar em cache os resultados da consulta. O acesso ao cache é o caminho rápido.
- Error Kernel pattern - um padrão do mundo de Akka que envolve dividir uma tarefa em subtarefas e delegar subtarefas a atores posteriores. Dessa maneira, a flexibilidade de processar erros de execução de subtarefa é alcançada.
- Instance Healer , que assume a existência de um serviço especial - um supervisor que gerencia outros serviços e responde a mudanças em seu estado. Por exemplo, em caso de erros no serviço, o supervisor pode reiniciar o serviço problemático.

Fornecimento de Eventos em Cluster e CQRS com Akka e Java
O último relatório que quero chamar sua atenção foi lido por um dos arquitetos e evangelistas de Lightbend Hugh McKee. Lightbend (anteriormente Typesafe) é algo como Oracle, mas para a linguagem Scala. A empresa também está desenvolvendo ativamente a estrutura
Akka.io. Em um relatório, Hugh falou sobre a implementação da popular abordagem
CQRS (Command Query Responsibility Commands / SEGREGATION) na estrutura Akka. Esquematicamente, a arquitetura do sistema CQRS fica assim:
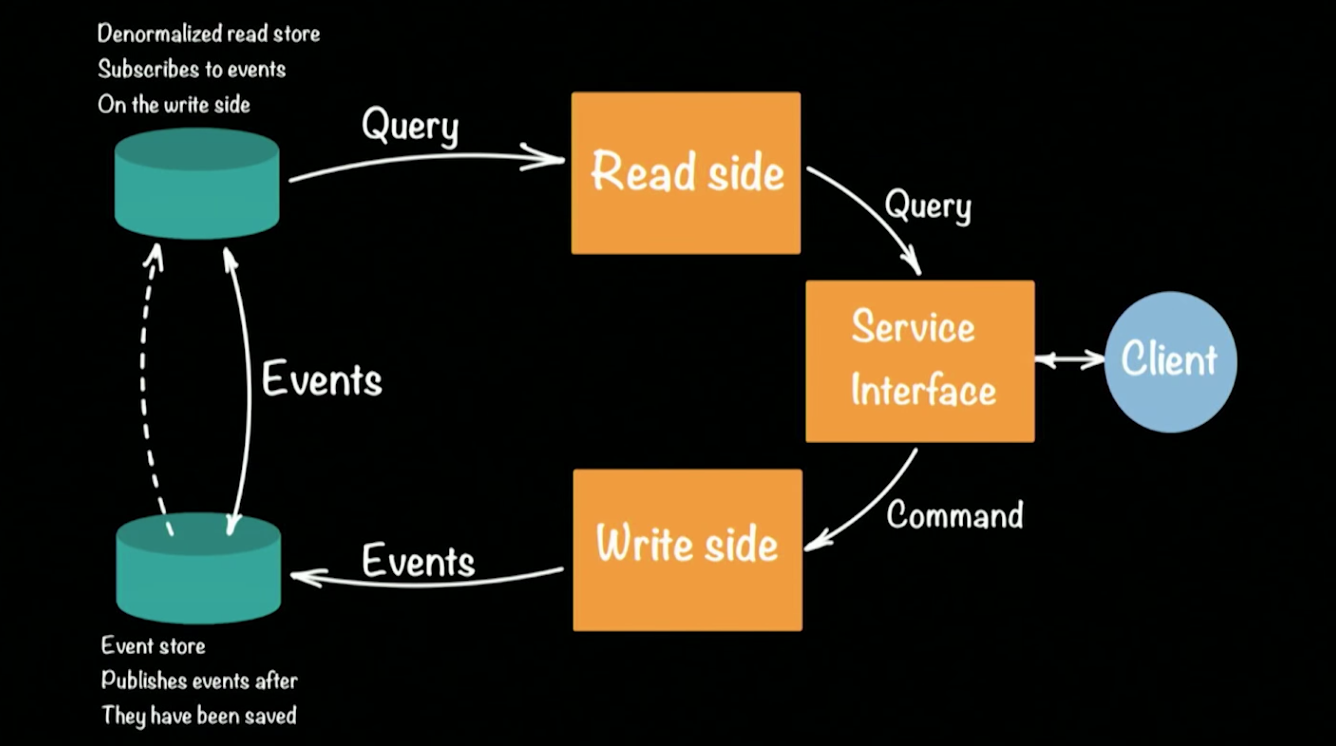
Hugh tomou o protótipo de um banco como exemplo de sistema em funcionamento. Um cliente na arquitetura CQRS executa duas operações: consulta, comando. Cada equipe (por exemplo, uma transação bancária que transfere dinheiro de uma conta para outra) gera um evento (um fato consumado) que será registrado na EventStore (por exemplo: Cassandra). A agregação da cadeia (depositar dinheiro em uma conta, transferir conta a conta, sacar em um caixa eletrônico) de eventos forma o estado atual do cliente, seu saldo de dinheiro na conta. As solicitações para o estado atual vão para um repositório separado, uma captura instantânea do repositório de eventos, pois não faz sentido manter um histórico completo de uma conta bancária. É suficiente atualizar periodicamente o elenco de status para cada usuário.
Essa abordagem possibilita a recuperação automática quando ocorrem erros: para isso, precisamos obter a última conversão do estado do usuário e aplicar a ele todos os eventos que ocorreram antes do erro. Devido à presença de dois armazenamentos, a arquitetura do CQRS tolera bem os picos de carga (picos) emergentes. Um grande número de eventos carregará o Armazenamento de Eventos, mas não afetará o Armazenamento de Leitura, e os usuários ainda poderão atender às consultas no banco de dados.
Vamos voltar à criação de protótipos do sistema bancário no Akka e no CQRS. Cada cliente do banco / conta / equipe possível no sistema será representado por um (!)
Ator . Um grande banco pode suportar centenas de milhares de contas, e isso não será um problema para a Akka. A estrutura pronta para uso suporta cluster e pode ser executada em centenas de JVMs. Se uma das máquinas do cluster falhar, a Akka fornecerá mecanismos especiais que respondem automaticamente a essas situações: no nosso caso, o ator do cliente pode ser recriado novamente em qualquer máquina disponível no cluster e seu status será lido novamente no repositório.
Um encadeamento separado não é criado para um ator - isso possibilita suportar dezenas de milhares de atores em uma única JVM. Ao mesmo tempo, o ator garante que cada solicitação seja processada separadamente (!) Na ordem de recebimento das solicitações. Essa garantia elimina automaticamente possíveis condições de corrida ao processar solicitações. Você pode entender o protótipo do sistema em mais detalhes, abrindo seu código usando os links no GitHub. Cada subprojeto mostra a implementação dos estágios mais complexos da construção de um protótipo:
vespas.
Os registros de todos os relatórios aparecerão online dentro de algumas semanas. Espero que este artigo o ajude a determinar a ordem de exibição, principalmente porque acho que vale a pena assistir às apresentações.