DBMSs em colunas desenvolvidos ativamente nos zero anos, no momento em que encontraram seu nicho e praticamente não competem com os sistemas minúsculos tradicionais. Sob o corte, o autor entende se uma solução universal é possível e quão prática é.
"Há progresso em tudo... Não tenha medo de que eles chamem você para o escritório e digam:" Consultamos aqui e amanhã você será esquartejado ou queimado por sua própria escolha. "Seria uma escolha difícil. Acho que ele ficaria perplexo com muitos de nós.
Yaroslav Hasek. Aventuras do bravo soldado Schweik.
Antecedentes
Quantos bancos de dados existem, tanto é esse confronto ideológico. Por curiosidade, o autor encontrou um livro de J. Martin da IBM [1] nos caixotes do lixo em 1975 e imediatamente tropeçou nas palavras (p. 183): “Relações binárias são usadas em obras, ou seja, relações de apenas dois domínios. Sabe-se que as relações binárias dão a maior flexibilidade à base. No entanto, em tarefas comerciais, relações de vários graus são convenientes. ” Relações são entendidas aqui como relações relacionais. E os trabalhos mencionados são datados de 1967 ... 1970.
Deixe o Sybase IQ foi a primeira coluna DBMS usada industrialmente, mas pelo menos no nível das idéias, tudo foi falado 25 anos antes.
No momento, os seguintes DBMSs são suportados em colunas ou em um grau ou outro (isso é considerado principalmente
aqui ):
Comercial
Código aberto e gratuito
Diferenças
Uma relação relacional é uma coleção de tuplas, essencialmente uma tabela bidimensional. Conseqüentemente, existem duas opções de armazenamento - em linha ou em coluna. A separação é um pouco artificial, lógica. Os desenvolvedores de banco de dados deixaram de planejar
planilhas de percussão . É tarefa dos administradores do DBMS decompor os dados do DBMS de maneira ideal em sistemas de arquivos, mas como os sistemas de arquivos organizam os dados em discos físicos é conhecido principalmente pelos desenvolvedores de sistemas de arquivos.
Seria lógico deixar o DBMS decidir em qual ordem armazenar os dados. Aqui estamos falando de alguns DBMS hipotéticos que suportam ambas as opções para organizar o armazenamento de dados e têm a capacidade de atribuir uma tabela a qualquer uma delas. Não consideramos uma opção bastante popular oferecer suporte a dois bancos de dados - um para o trabalho e o segundo para análises / relatórios. Além de índices de coluna no Microsoft SQL Server. Não porque é ruim, mas para testar a hipótese de que existe uma maneira mais elegante.
Infelizmente, nenhum DBMS hipotético pode escolher a melhor maneira de armazenar dados. Porque não entende como vamos usar esses dados. E sem isso, é impossível fazer uma escolha, embora seja muito importante.
A qualidade mais valiosa de um DBMS é a capacidade de processar dados rapidamente (e requisitos de
ACID , é claro). A velocidade do DBMS é determinada principalmente pelo número de operações do disco. Dois casos extremos surgem disso:
- Os dados são alterados / adicionados rapidamente, você precisa ter tempo para escrever. A solução óbvia: uma linha (tupla), se possível, está localizada em uma página, não pode ser feita mais rapidamente.
- Os dados são alterados extremamente raramente ou não são alterados, lemos os dados várias vezes e apenas um pequeno número de colunas está envolvido por vez. Nessa situação, é lógico usar uma variante de armazenamento em colunas, e ao ler o número mínimo possível de páginas aumentará.
Mas esses são casos extremos, na vida tudo não é tão óbvio.
- Se você quiser ler a tabela inteira, do ponto de vista do número de páginas, os dados não serão importantes linha por linha ou coluna. Ou seja, há alguma diferença, é claro, na versão em colunas, temos a capacidade de compactar melhor as informações, mas no momento isso não é importante.
- Mas em termos de desempenho, há uma diferença porque com a gravação linha a linha, a leitura do disco ocorrerá de forma mais linear. Menos discos rígidos avançam visivelmente mais rapidamente. Uma leitura de arquivo mais previsível durante a gravação linha a linha permite que o sistema operacional (SO) use o cache do disco com mais eficiência. Isso é importante mesmo para unidades SSD, porque o carregamento por suposição ( leia a seguir ) geralmente leva ao sucesso.
- A atualização nem sempre altera o registro inteiro. Suponha que um caso comum seja uma alteração em duas colunas. Será bom que os dados dessas colunas estejam em uma página, porque você só precisa de um bloqueio de página por registro em vez de dois. Por outro lado, se os dados estiverem espalhados pelas páginas, isso possibilita que diferentes transações alterem os dados de uma linha sem conflitos.
Aqui está um olhar mais atento. Uma opção hipotética é tornar a tabela em minúscula ou colunar, o DBMS deve fazer no momento de sua criação. Mas, para fazer essa escolha, seria bom saber, por exemplo, como vamos mudar essa tabela. Talvez você deva jogar uma moeda?
- Suponha que usamos uma estrutura em árvore (ex: índice clusterizado) para armazenamento. Nesse caso, adicionar dados ou mesmo alterá-los pode levar ao reequilíbrio da árvore ou de sua parte. No armazenamento de linhas, existe (pelo menos um) bloqueio de gravação, o que pode afetar uma parte significativa da tabela. Na versão colunar, essas histórias ocorrem com muito mais frequência, mas causam muito menos danos porque dizem respeito apenas a uma coluna específica.
- Considere filtrar por índice. Suponha que a amostra seja suficientemente escassa. A gravação linha a linha tem preferência, pois, nesse caso, a proporção de informações úteis a serem lidas para a empresa é melhor.
- Se a filtragem fornecer um fluxo mais denso e apenas uma pequena parte das colunas for necessária, a versão em colunas se tornará mais barata. Onde está a divisão entre esses casos, como determiná-lo?
Em outras palavras, em hipótese alguma nosso DBMS hipotético assumirá a responsabilidade de escolher entre as opções de armazenamento de linha e coluna; isso deve ser feito pelo designer do banco de dados.
No entanto, dado o exposto, o designer do banco de dados também será uma escolha muito difícil. Ele confundiria muitos de nós.
E se
Em essência, as variantes em colunas e em linhas - os casos extremos de uma idéia - cortam a tabela em "faixas" e armazenam dados linha por linha dentro de cada fita. Em um caso, a fita é uma e, no outro, degenera em uma coluna.
Então, por que não permitir opções intermediárias - se os dados de algumas colunas forem lidos juntos, mesmo que estejam na mesma fita. E se não houver dados (NULLs) na fita, nada precisará ser armazenado. Ao mesmo tempo, o problema do tamanho máximo da linha é removido - você pode dividir a tabela quando houver o risco de a linha não caber em uma página.
Essa ideia não é tão original, o autor teve a chance de ver a mesma e aplicá-la ele mesmo. O elemento novidade é permitir que o designer do banco de dados determine como sua tabela será dividida em partes e de que forma os dados serão colocados no disco.
Fizemos isso por nós mesmos da seguinte maneira:
- ao criar uma tabela, informações sobre nossas preferências são transmitidas ao processador SQL usando pragmas
- inicialmente, ao criar uma tabela, supõe-se que toda a linha esteja localizada em uma página da árvore B
- no entanto, você pode usar - - #pragma page_break
para informar ao processador SQL que as seguintes colunas estarão localizadas em outra página (em outra árvore) - uso - - #pragma column_based
nos permite dizer concisa que as colunas que vão além estão localizadas em sua própria árvore - - - #pragma row_based
cancela a ação baseada em column_ - portanto, a tabela consiste em uma ou mais árvores B, cujo primeiro elemento-chave é um campo de IDENTIDADE oculto. Acredita-se que a ordem na qual os registros são criados (pode se correlacionar com a ordem na qual os registros são lidos) também é importante e não deve ser negligenciada. A chave primária é uma árvore separada, no entanto, isso não se aplica ao tópico.
Como isso pode parecer na prática?
Por exemplo, assim:
CREATE TABLE twomass_psc ( ra double precision, decl double precision, …
Por exemplo, a tabela principal do atlas
2MASS é tirada, a legenda
aqui e
aqui .
J ,
H ,
K - sub-bandas de infravermelho, faz sentido armazenar dados neles juntos, pois na pesquisa eles são processados juntos. Aqui,
por exemplo :
A primeira foto que apareceu.
Ou
aqui , ainda mais bonito:
É hora de confirmar que isso faz algum sentido prático.
Resultados
Abaixo é apresentado:
- diagrama de fases (número X da página gravada, número Y da última gravada anteriormente) do procedimento para gravar páginas (números lógicos) no disco ao criar uma tabela em duas versões
- em uma coluna, é designado como by_1
- e para uma tabela cortada em 16 colunas, é designada como by_16
- colunas totais 181

Vamos dar uma olhada em como funciona:
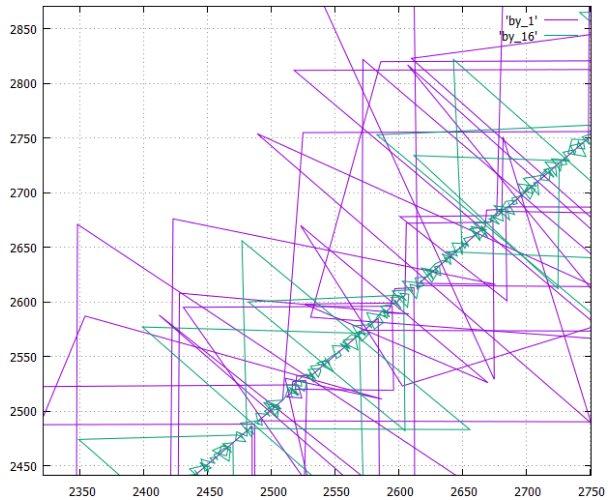
- A opção by_16 é visivelmente mais compacta, o que é lógico, o máximo - a opção de linha daria apenas uma linha reta (com valores extremos).
- Outliers triangulares - registre páginas intermediárias de árvores B.
- O registro de dados é mostrado, obviamente, a leitura será mais ou menos assim.
- Foi dito acima que todas as opções registram a mesma quantidade de informações e o fluxo que precisa ser subtraído é aproximadamente o mesmo (± eficiência de compactação).
Mas aqui é claramente mostrado que, em uma versão em colunas, as árvores crescem em velocidades diferentes devido às especificidades dos dados (em uma coluna, elas repetem e comprimem muito bem, na outra coluna - ruído do ponto de vista do compressor). Como resultado, algumas árvores correm à frente, outras se atrasam; ao ler, obtemos objetivamente um modo de leitura "rasgado" que é muito desagradável para o sistema de arquivos. - Portanto, by_16 é muito mais preferível para leitura do que em colunas, é quase igual em conforto do que em linhas.
- Mas, ao mesmo tempo, a variante by_16 tem as principais vantagens de uma variante em colunas no caso em que é necessário um pequeno número de colunas. Especialmente se você não dividir a mesa mecanicamente por 16 peças, mas significativamente, depois de analisar as probabilidades de seu uso conjunto.
Fontes
[1] J. Martin. Organização de bancos de dados em sistemas de computação. O mundo, 1978
[2]
Índices de colunas, características de uso[3] Daniel J. Abadi, Samuel Madden, Nabil Hachem.
ColumnStores vs. RowStores: Quão diferentes são realmente? , Anais da Conferência Internacional ACM SIGMOD sobre Gerenciamento de Dados, Vancouver, BC, Canadá, junho de 2008
[4] Michael Stonebraker, Uğur Çetintemel.
“Tamanho único”: uma idéia cujo tempo chegou e se foi , 2005