Em 29 de maio,
foi realizada mais uma conferência em 2018 - a maior e a anual conferência Yandex. Havia três seções no YaC deste ano: tecnologias de marketing, cidade inteligente e segurança da informação. Na perseguição, publicamos um dos principais relatórios da terceira seção - de Yuri Leonovich
tracer0tong da empresa japonesa Rakuten.
Como nos autenticamos? No nosso caso, não há nada de extraordinário, mas quero mencionar um método. Além dos tipos tradicionais - captcha e senhas de uso único - usamos o Proof of Work, PoW. Não, não mineramos bitcoins nos computadores dos usuários. Usamos o PoW para desacelerar o atacante e, às vezes, até bloquear completamente, forçando-o a resolver uma tarefa muito difícil, na qual ele passará muito tempo.
- Trabalho na Rakuten International Corporation. Quero falar sobre várias coisas: um pouco sobre mim, sobre nossa empresa, sobre como avaliar o custo dos ataques e entender se você precisa fazer alguma prevenção contra fraudes. Quero contar como coletamos nossa prevenção contra fraudes e quais modelos usamos deram bons resultados na prática, como eles funcionaram e o que pode ser feito para evitar ataques de fraude.

Sobre mim brevemente. Ele trabalhou na Yandex, esteve envolvido na segurança de aplicativos da Web e, na Yandex, também criou um sistema para evitar ataques de fraude. Sou capaz de desenvolver serviços distribuídos, tenho um conhecimento matemático que ajuda no uso do aprendizado de máquina na prática.
Rakuten não é muito conhecido na Federação Russa, mas acho que todos sabem disso por duas razões. Dos mais de 70 de nossos serviços na Rússia, o Rakuten Viber é conhecido e, se houver fãs de futebol aqui, você deve saber que nossa empresa é a patrocinadora geral do clube de futebol de Barcelona.
Como temos tantos serviços, temos nossos próprios sistemas de pagamento, cartões de crédito e muitos programas de recompensa, estamos constantemente sujeitos a ataques de criminosos cibernéticos. E, naturalmente, sempre solicitamos às empresas sistemas de proteção contra fraudes.
Quando uma empresa nos pede para criar um sistema de proteção contra fraudes, sempre enfrentamos algum dilema. Por um lado, há uma solicitação para que haja uma alta taxa de conversão, para que o usuário possa se autenticar convenientemente com os serviços e fazer compras. E da nossa parte, da parte dos guardas de segurança, quero menos reclamações, menos contas invadidas. E nós, por nossa parte, queremos aumentar o preço do ataque.
Se você for comprar um sistema de prevenção de fraudes ou tentar fazer isso sozinho, primeiro será necessário avaliar os custos.

Em nossa opinião, precisamos de prevenção de fraudes? Contamos com o fato de termos alguns tipos de perdas financeiras por fraude. Essas são perdas diretas - o dinheiro que você devolverá aos seus clientes se eles forem roubados por intrusos. Esse é o custo de um serviço de suporte técnico que se comunicará com os usuários e resolverá conflitos. Esta é uma devolução de mercadorias que geralmente são entregues em endereços falsos. E há custos diretos no desenvolvimento do sistema. Se você criou um sistema de proteção contra fraudes, implantou-o em alguns servidores, pagará pela infraestrutura, pelo desenvolvimento de software. E há um terceiro aspecto muito importante dos danos causados pelos atacantes - lucros perdidos. Consiste em vários componentes.
De acordo com nossos cálculos, há um parâmetro muito importante - o valor da vida útil, LTV, ou seja, o dinheiro que o usuário gasta em nossos serviços é reduzido significativamente. Porque na metade dos casos de fraude, os usuários simplesmente deixam seu serviço e não retornam.
Também pagamos dinheiro pela publicidade e, se o usuário sair, ele será perdido. Esse é o custo de aquisição do cliente, CAC. E se tivermos muitos usuários automatizados que não são pessoas reais - temos usuários ativos mensais falsos, números da MAU, que também afetam os negócios.
Vamos olhar do outro lado, dos atacantes.
Alguns oradores disseram que os atacantes estão usando ativamente as redes de bots. Mas não importa qual método eles usem, eles ainda precisam investir dinheiro, pagar pelo ataque, eles também gastam algum dinheiro. Nossa tarefa, quando criamos um sistema de prevenção de fraudes, é encontrar um equilíbrio que o invasor gaste muito dinheiro e gastemos menos. Isso faz com que um ataque não seja rentável, e os atacantes simplesmente vão embora para interromper outro serviço.

Para nossos serviços de danos, dividimos os ataques em quatro tipos. Isso é direcionado ao tentar invadir uma conta, uma conta. Ataques de um usuário ou de um pequeno grupo de pessoas. Ou ataques mais perigosos para nós, maciços e não direcionados, quando atacantes atacam muitas contas, cartões de crédito, números de telefone etc.

Vou te contar o que acontece, como eles nos atacam. O principal tipo mais óbvio de ataque que todos conhecem é a quebra de senha. No nosso caso, os atacantes estão tentando resolver os números de telefone, tentando validar os números de cartão de crédito. Alguma variedade está presente.
Registro em massa de contas, para nós é obviamente prejudicial. Vou dar um exemplo mais tarde.
O que é gravado? Contas falsas, alguns produtos inexistentes, estão tentando enviar spam nas mensagens de feedback. Eu acho que isso é relevante e semelhante para muitas empresas comerciais.
Ainda existem problemas que não são óbvios para o comércio eletrônico, mas óbvios para o Yandex - ataques ao orçamento de publicidade, clique em fraude. Bem, ou apenas o roubo de dados pessoais.

Eu darei um exemplo Tivemos um ataque bastante interessante a um serviço que vende livros eletrônicos; havia uma oportunidade para qualquer usuário se registrar e começar a vender seu trabalho eletrônico, uma oportunidade para apoiar escritores iniciantes.
O atacante registrou uma conta principal legal e vários milhares de contas falsas de lacaios. E ele gerou um livro falso, apenas a partir de frases aleatórias, não havia sentido nele. Ele colocou no mercado, e nós tínhamos uma empresa de marketing, cada lacaio tinha, condicionalmente, 1 dólar, que ele poderia gastar em um livro. E esse livro falso custa US $ 1.
Uma invasão de asseclas foi organizada - contas falsas. Todos eles compraram este livro, o livro subiu nas classificações, tornou-se um best-seller, um atacante aumentou o preço para US $ 10 condicionais. E desde que o livro se tornou um best-seller, as pessoas comuns começaram a comprá-lo, e reclamações caíram sobre nós de que estávamos vendendo alguns produtos de baixa qualidade, um livro com um conjunto de palavras sem sentido. O atacante recebeu um lucro.
Não há um nono ponto: ele foi preso mais tarde pela polícia. Portanto, o lucro não foi para o futuro.
O principal objetivo de todos os atacantes no nosso caso é gastar o mínimo de dinheiro possível e aproveitar o máximo possível.

Existem invasores, uma pessoa que está simplesmente tentando burlar a lógica comercial. Mas observo que não consideramos esses ataques uma prioridade, porque, em termos da proporção do número de contas invadidas e de dinheiro roubado, elas representam um risco baixo para nós. Mas o principal problema para nós são as redes de bots.

Estes são sistemas distribuídos em massa, eles atacam nossos serviços de todo o planeta, de diferentes continentes, mas possuem alguns recursos que facilitam o manuseio deles. Como em qualquer sistema distribuído grande, os nós de botnet executam mais ou menos as mesmas tarefas.
Outra coisa importante - agora, como muitos colegas observaram, as redes bot estão distribuídas em todos os tipos de dispositivos inteligentes, roteadores domésticos, alto-falantes inteligentes, etc. Mas esses dispositivos têm especificações de hardware baixas e não podem executar scripts complexos.
Por outro lado, para um invasor, alugar um botnet para DDoS simples é bastante barato e também é necessário pesquisar senhas por contas. Mas se você precisar implementar algum tipo de lógica comercial especificamente para seu aplicativo ou serviço, o desenvolvimento e o suporte de uma botnet se tornarão muito caros. Geralmente, um invasor simplesmente aluga parte de uma botnet finalizada.
Eu sempre associo um ataque de botnet ao desfile de Pikachu em Yokohama. Temos 95% do tráfego malicioso proveniente de botnets.
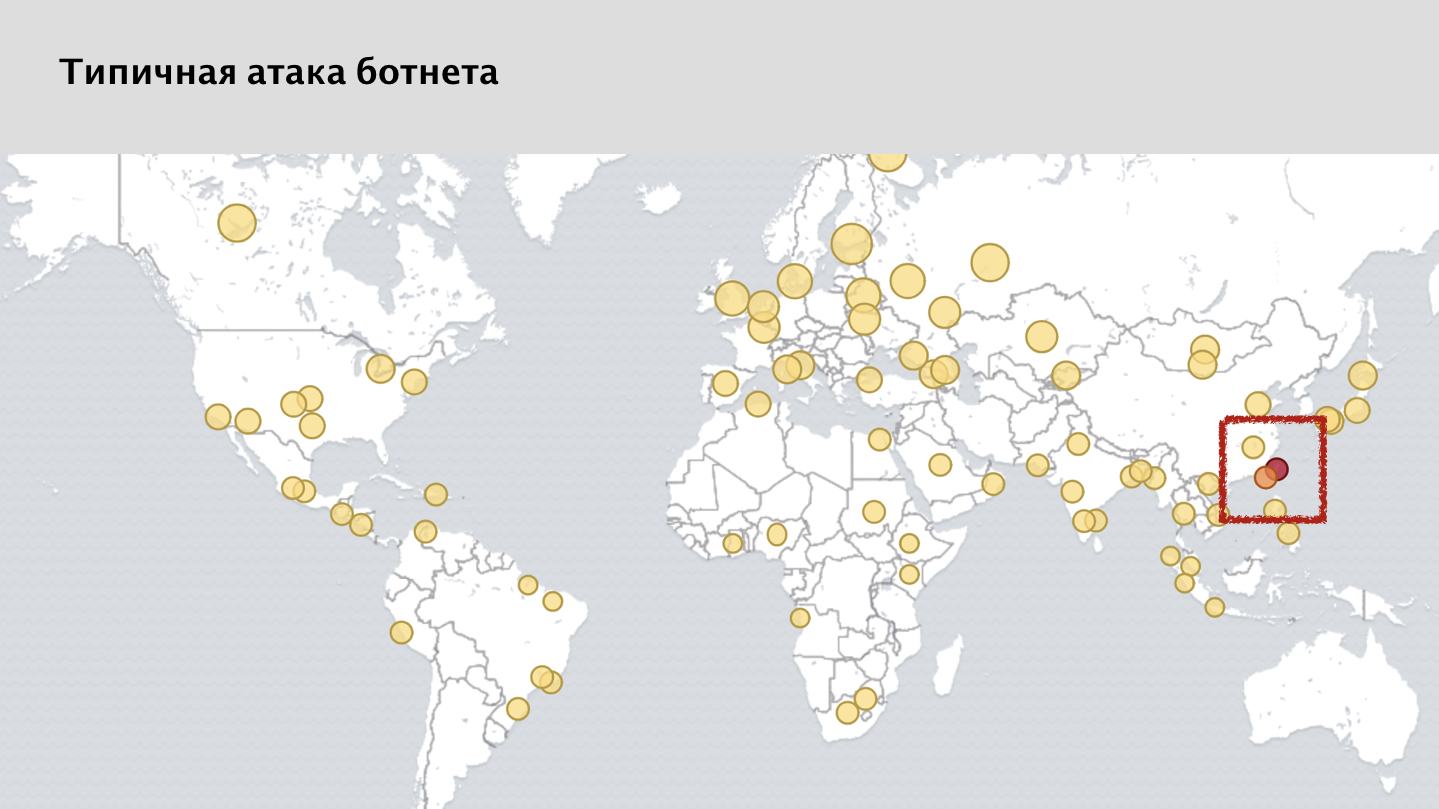
Se você observar a captura de tela do nosso sistema de monitoramento, verá muitas manchas amarelas - estas são solicitações bloqueadas de vários nós. E aqui, uma pessoa atenta pode perceber que eu meio que disse que o ataque é distribuído igualmente pelo mundo. Mas há uma clara anomalia no mapa, um ponto vermelho na área de Taiwan. Este é um caso bastante curioso.
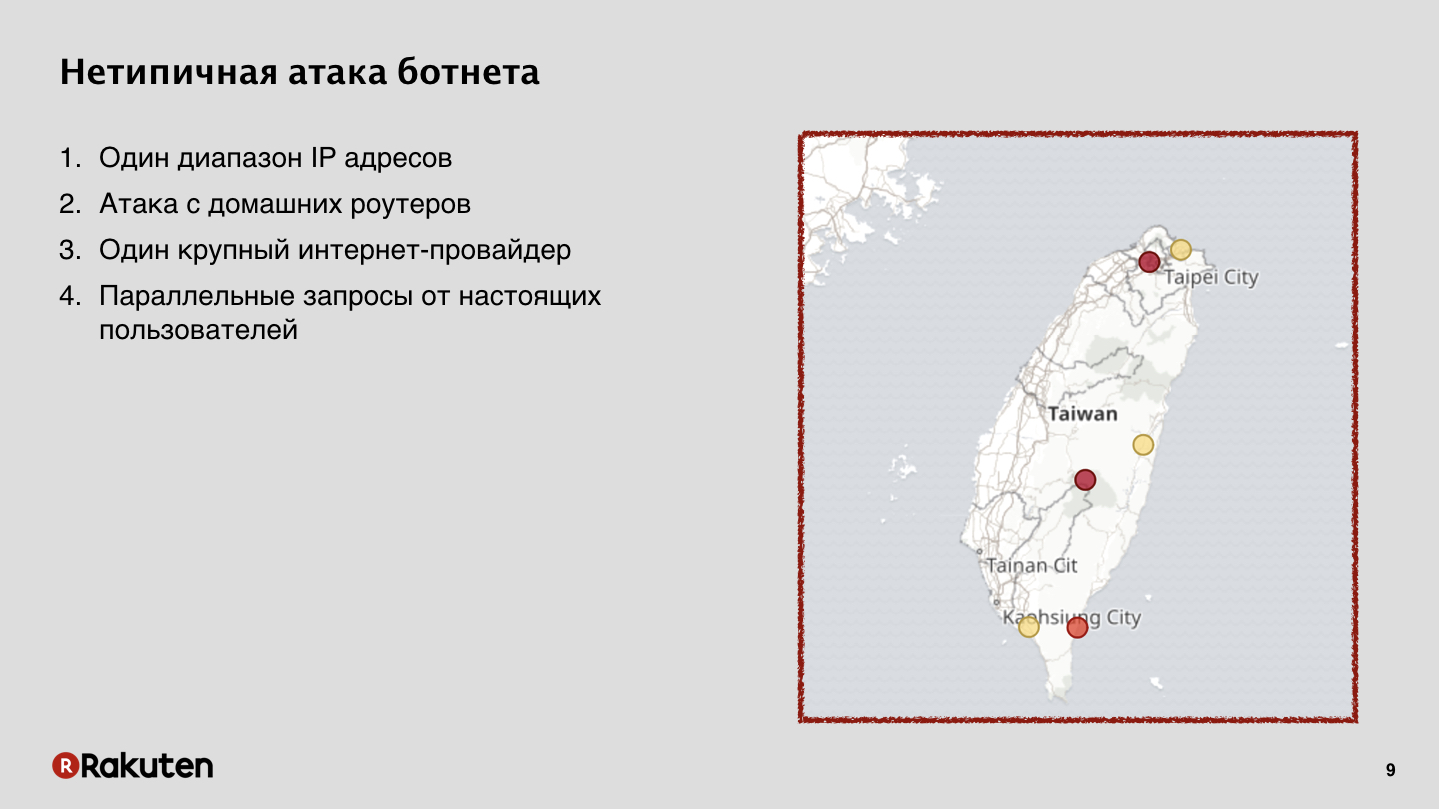
Esse ataque veio de roteadores domésticos. Em Taiwan, um grande provedor de serviços de Internet foi hackeado, o que forneceu a Internet para a maioria dos habitantes da ilha. E, para nós, era um problema muito grande, relacionado ao fato de muitos usuários legais, ao mesmo tempo em que ocorreu o ataque, acessarem e trabalharem com nossos serviços nos mesmos endereços IP. Paramos com sucesso esse ataque, mas foi muito difícil.
Se falamos sobre escopo, sobre a superfície, sobre o que protegemos. Se você possui um pequeno site de comércio eletrônico ou um pequeno serviço regional, não há problemas específicos. Você tem um servidor, talvez vários, ou máquinas virtuais na nuvem. Bem, usuários, maus, bons, que vêm até você. Não há nenhum problema específico para proteger.
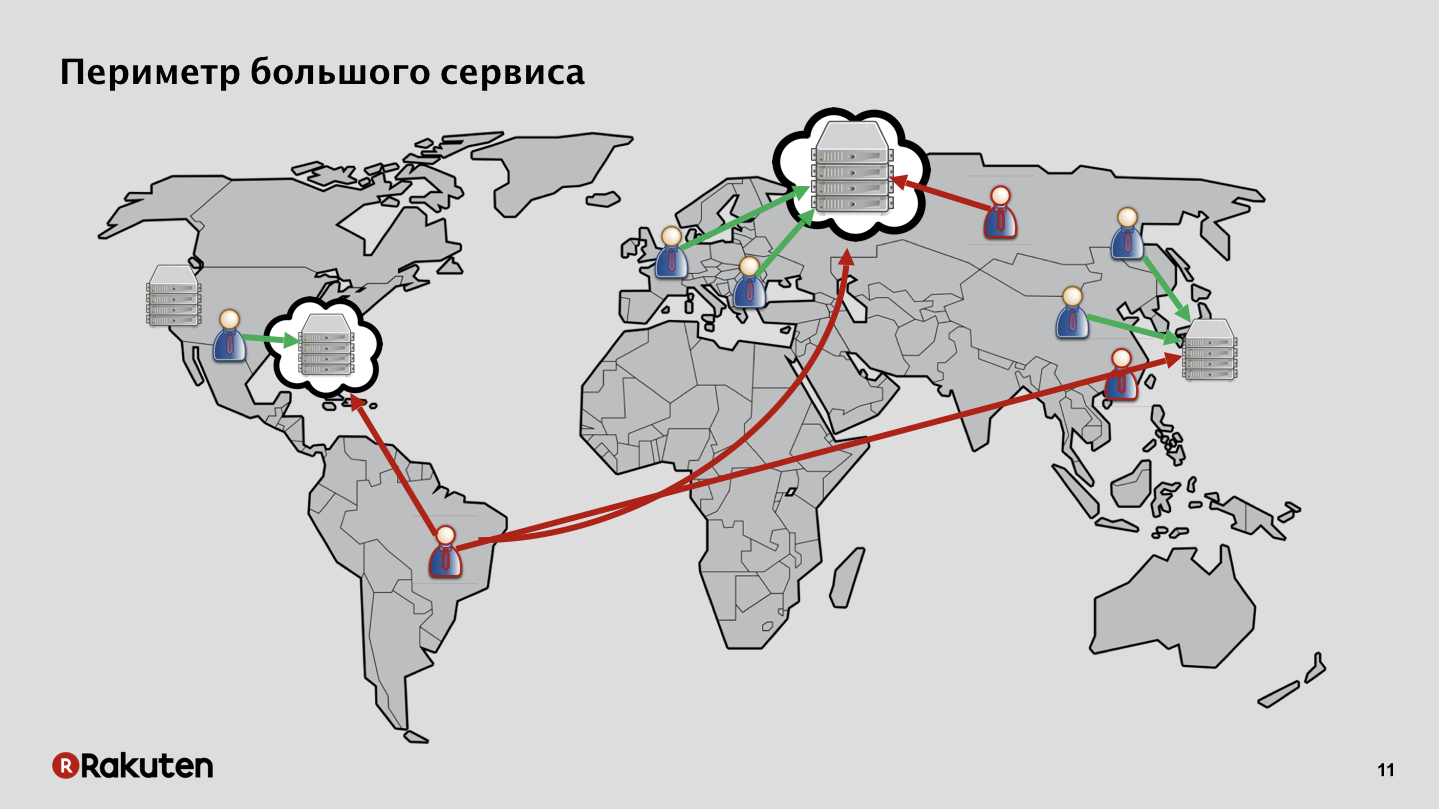
No nosso caso, tudo é mais complicado, a superfície de ataque é enorme. Temos serviços implantados em nossos próprios data centers, na Europa, no sudeste da Ásia, nos EUA. Também temos usuários em diferentes continentes, bons e ruins. Além disso, alguns serviços são implantados na infraestrutura de nuvem, e não na nossa.
Com tantos serviços e uma infraestrutura tão extensa, é muito difícil defender. Além disso, muitos de nossos serviços oferecem suporte a vários tipos de aplicativos e interfaces de clientes. Por exemplo, temos um serviço de TV Rakuten que funciona em TVs inteligentes e a proteção é totalmente especial para isso.

Para resumir o problema, um grande número de usuários circula em seu sistema, como pessoas em uma loja no cruzamento em Shibuya. E entre tantas pessoas, é necessário identificar e capturar os agressores. Ao mesmo tempo, existem muitas portas em sua loja e há ainda mais pessoas.
Então, do que e como montamos nosso sistema?
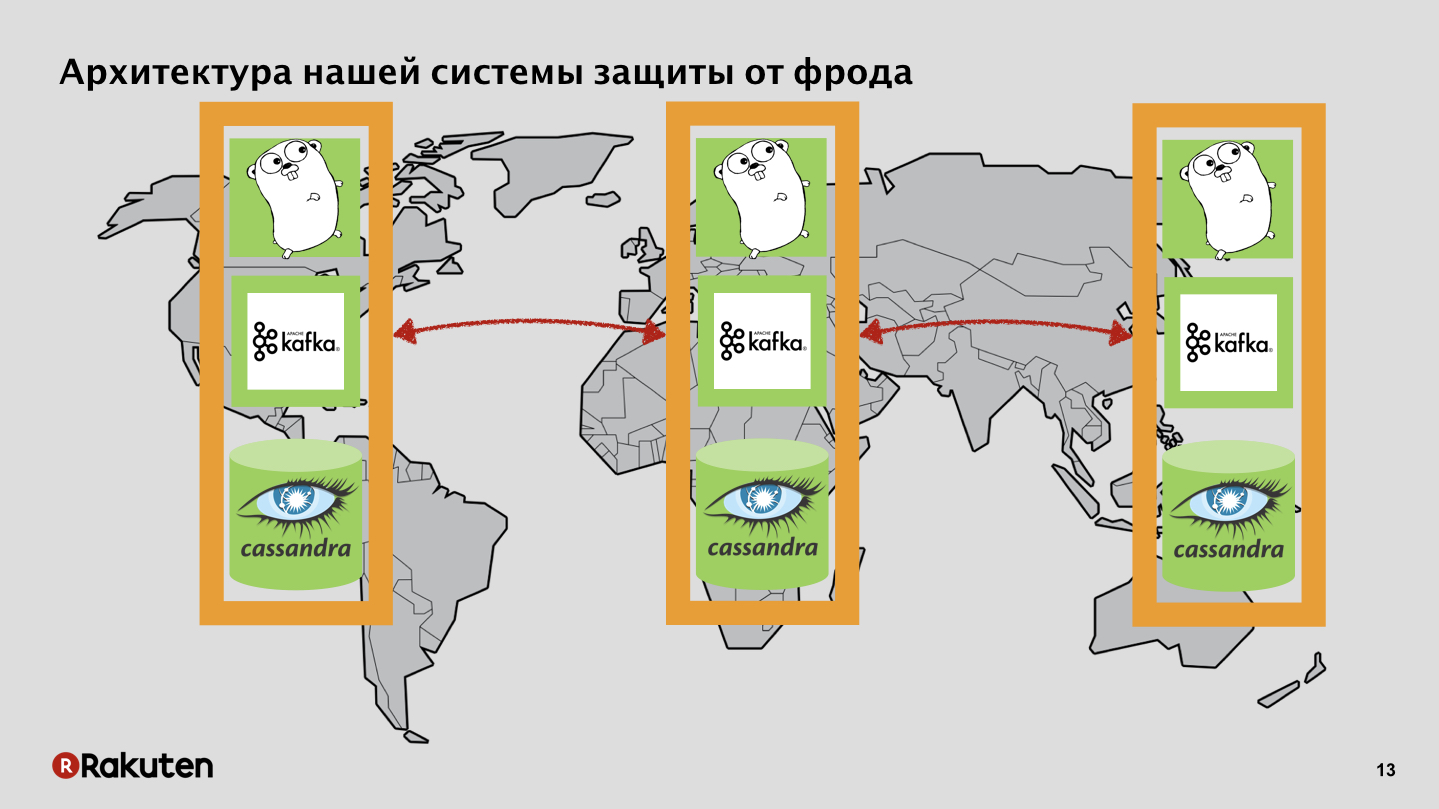
Conseguimos usar apenas componentes de código aberto, era barato o suficiente. Usou o poder de muitos "esquilos". Uma parte significativa do software foi escrita no idioma Golang. Filas de mensagens e bancos de dados usados. Por que precisamos disso? Tínhamos dois objetivos: coletar dados sobre o comportamento do usuário e calcular a reputação, tomar algumas ações para reconhecer se um usuário é bom ou ruim.
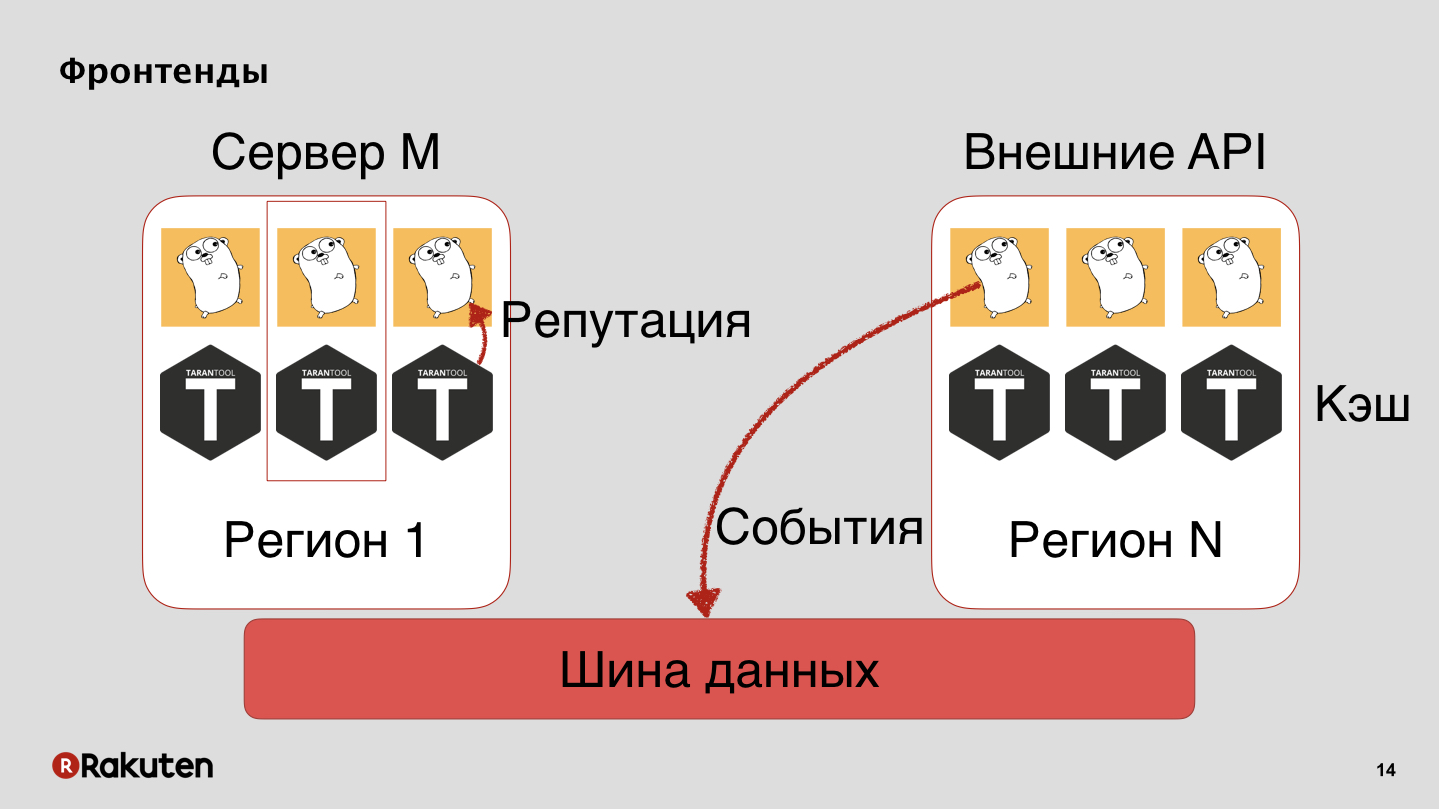
Temos muitos níveis no sistema, usamos os frontends escritos em Golang e Tarantool como base de cache. Nosso sistema é implantado em todas as regiões onde nossas empresas estão localizadas. Transmitimos eventos através do barramento de dados e a partir dele obtemos uma reputação.
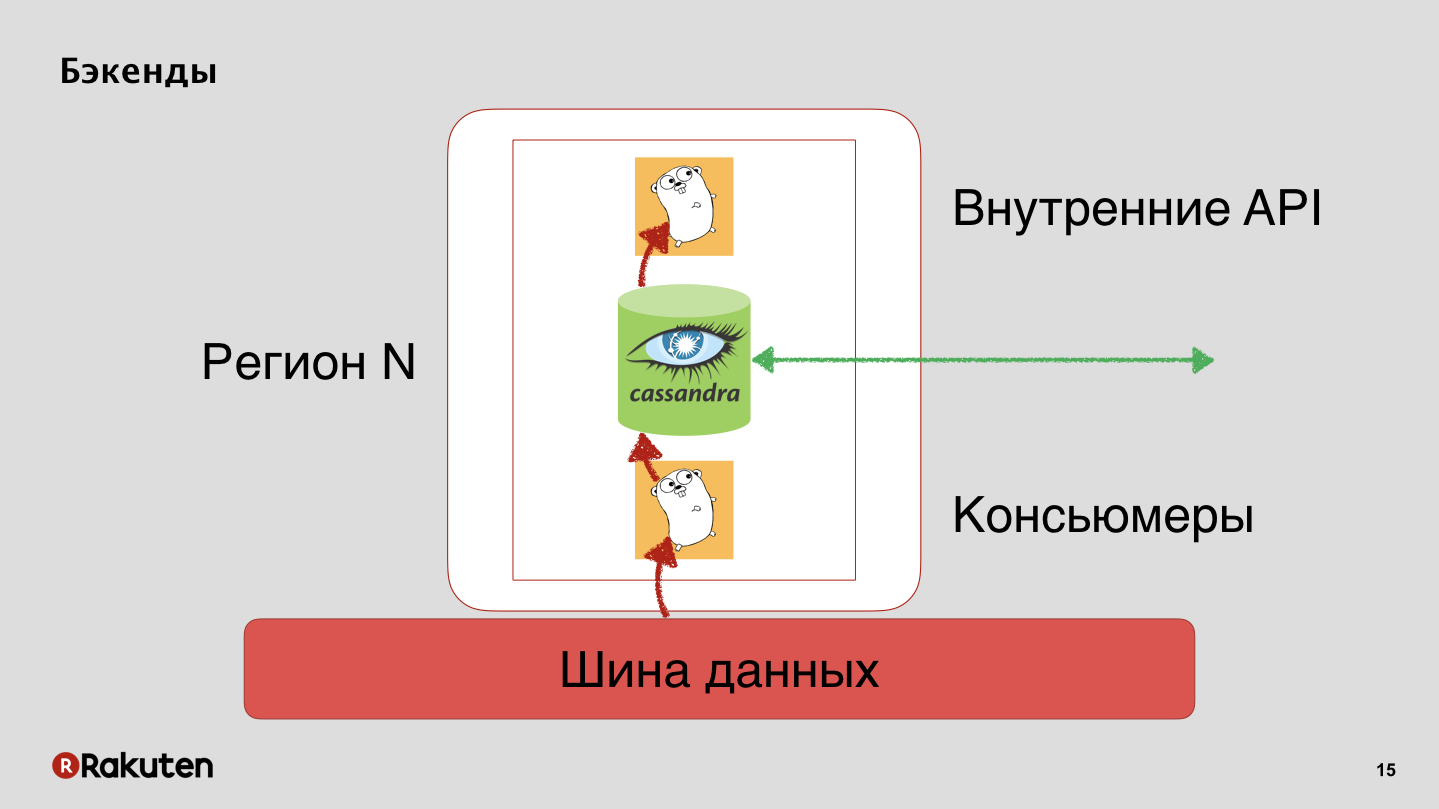
Temos back-ends que também replicam o status da reputação do usuário com o Cassandra.
Barramento de dados, nada secreto, Apache Kafka.
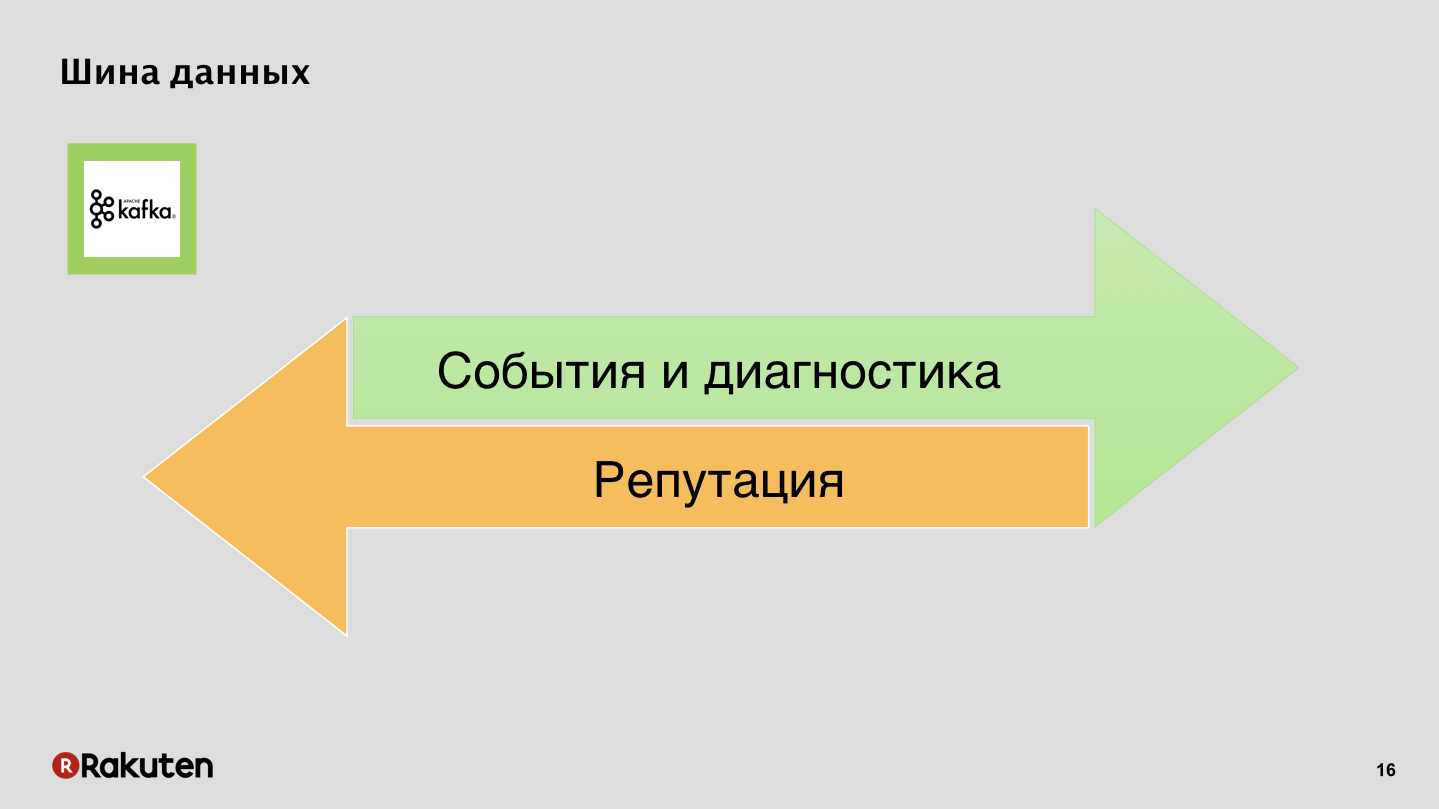
Eventos e registros em uma direção, reputação na outra.
E, naturalmente, o sistema tem um cérebro que pensa se o usuário é ruim ou bom, a atividade é ruim ou boa. O cérebro é construído no Apache Storm, e a parte divertida é o que acontece lá dentro.
Mas, primeiro, mostrarei como coletamos dados e como bloquear invasores.
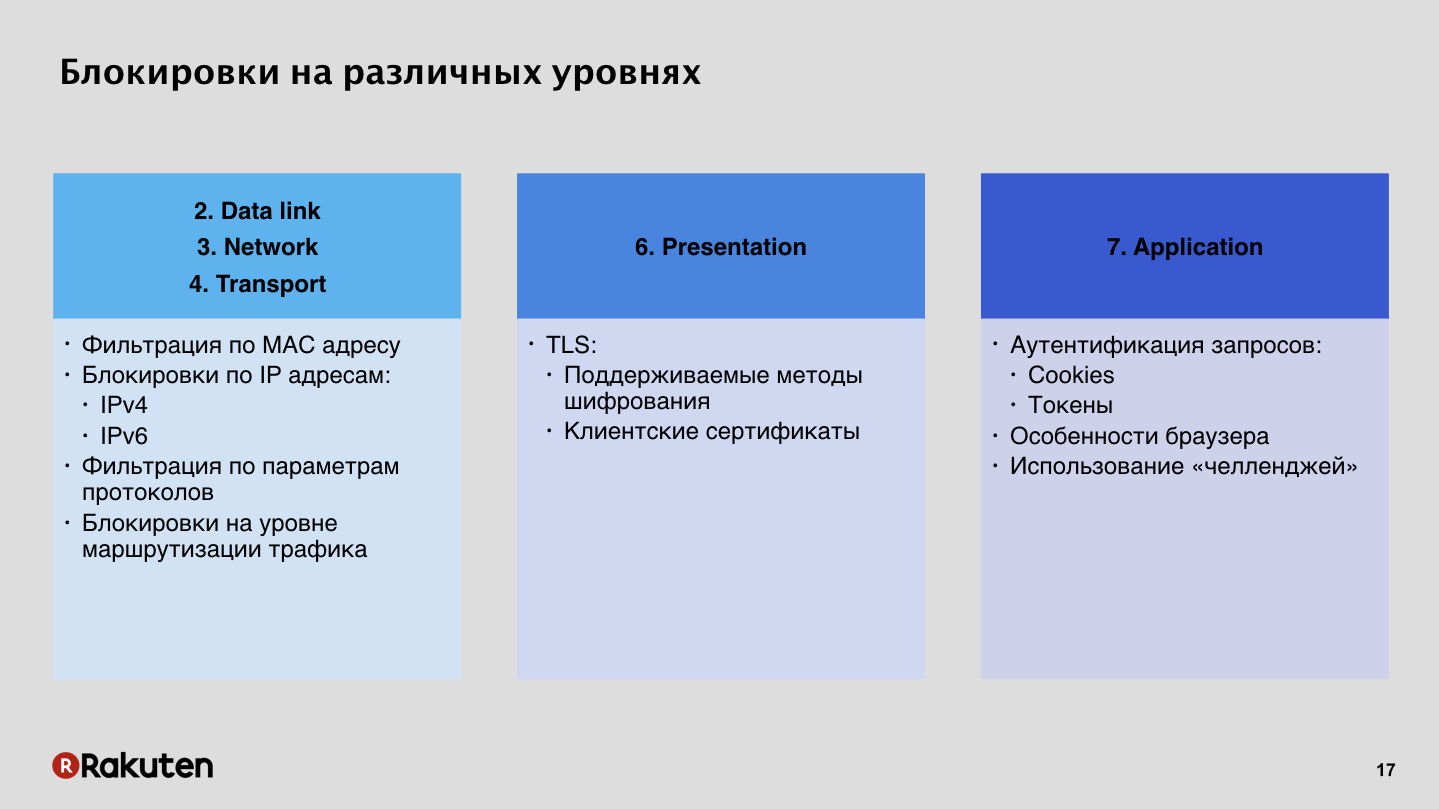
Existem muitas abordagens. Alguns deles já foram mencionados por colegas da Yandex em seu primeiro relatório. Como bloquear intrusos? Anton Karpov disse que os firewalls são ruins, não gostamos deles. Na verdade, ele pode ser bloqueado por endereços IP, o tópico para a Rússia é muito relevante, mas esse método não nos convém. Preferimos usar bloqueios de nível superior, no sétimo nível, no nível do aplicativo, usando autenticação de solicitações usando tokens, cookies de sessão.
Porque Vamos ver primeiro os bloqueios baixos.
Esta é uma maneira barata, todo mundo sabe como usá-lo, todo mundo tem firewalls nos servidores. Um monte de instruções na Internet, não há problemas para bloquear o usuário por IP. Mas quando você bloqueia o usuário em um nível baixo, ele não tem como ignorar seu sistema de proteção de alguma forma, se esse foi um falso positivo. Os navegadores modernos estão mais ou menos tentando mostrar uma bela mensagem de erro ao usuário, mas ainda assim, uma pessoa não pode ignorar seu sistema de nenhuma maneira, porque um usuário comum não pode alterar arbitrariamente seus endereços IP. Portanto, acreditamos que esse método não é muito bom e hostil. Além disso, o IPv6 se move pelo planeta, se você tiver alguma tabela bloqueada, e depois de algum tempo, levará muito tempo para procurar endereços nessas tabelas e não haverá futuro para esses bloqueios.

Nosso método é bloqueios no nível superior. Preferimos autenticar solicitações, porque para nós é uma oportunidade de se adaptar de maneira muito flexível à lógica comercial de nossos aplicativos. Tais métodos têm vantagens e desvantagens. A desvantagem é o alto custo de desenvolvimento, a grande quantidade de recursos que você precisa investir em infraestrutura e a arquitetura desses sistemas, com toda sua aparente simplicidade, ainda é complicada.
Você ouviu em relatórios anteriores sobre vários métodos baseados em biometria, coleta de dados. Obviamente, também pensamos nisso, mas aqui é muito fácil violar a privacidade do usuário coletando os dados errados que o usuário deseja confiar a você.
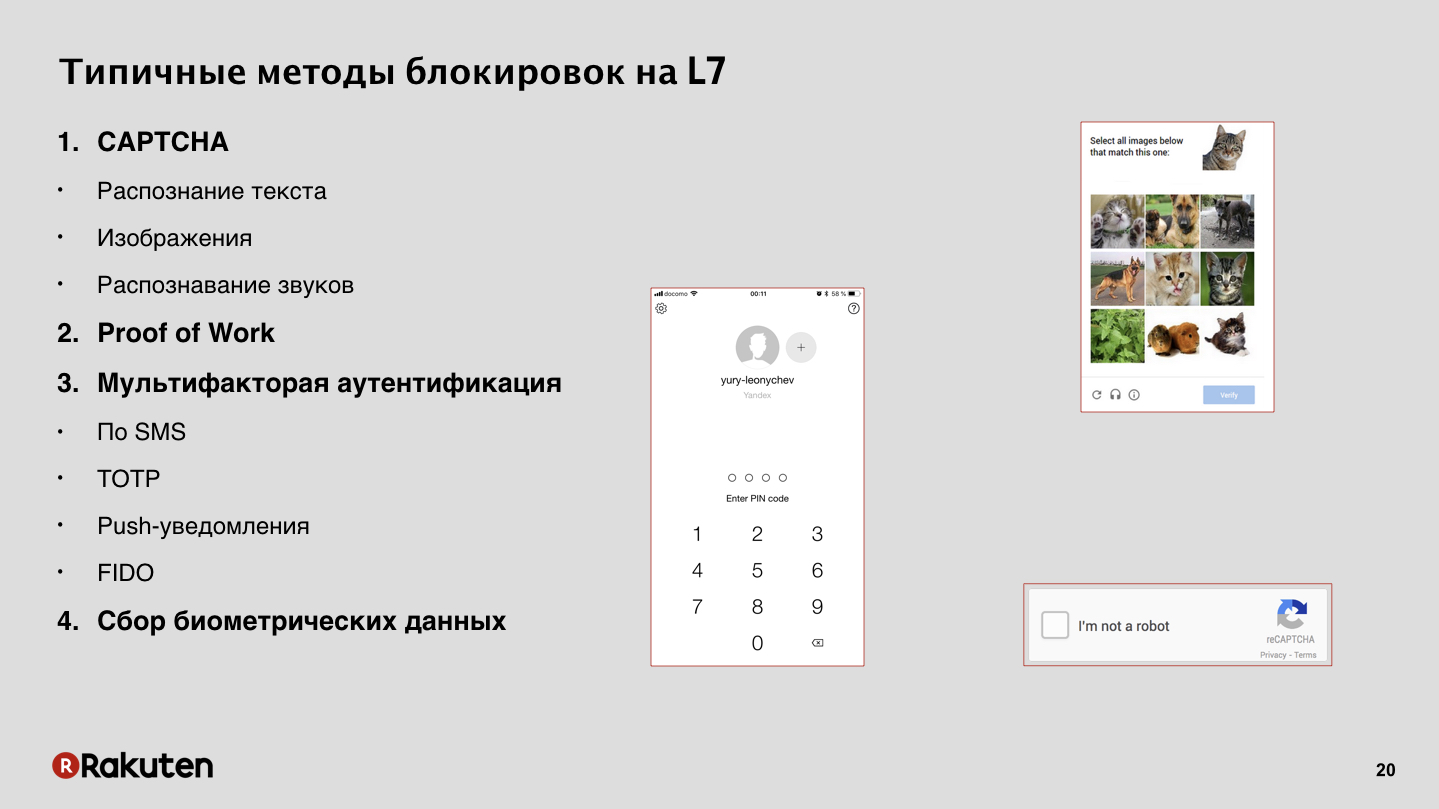
Como nos autenticamos? No nosso caso, não há nada de extraordinário, mas quero mencionar um método. Além dos tipos tradicionais - captcha e senhas de uso único - usamos o Proof of Work, PoW. Não, não mineramos bitcoins nos computadores dos usuários. Usamos o PoW para desacelerar o atacante e, às vezes, até bloquear completamente, forçando-o a resolver uma tarefa muito difícil, na qual ele passará muito tempo.
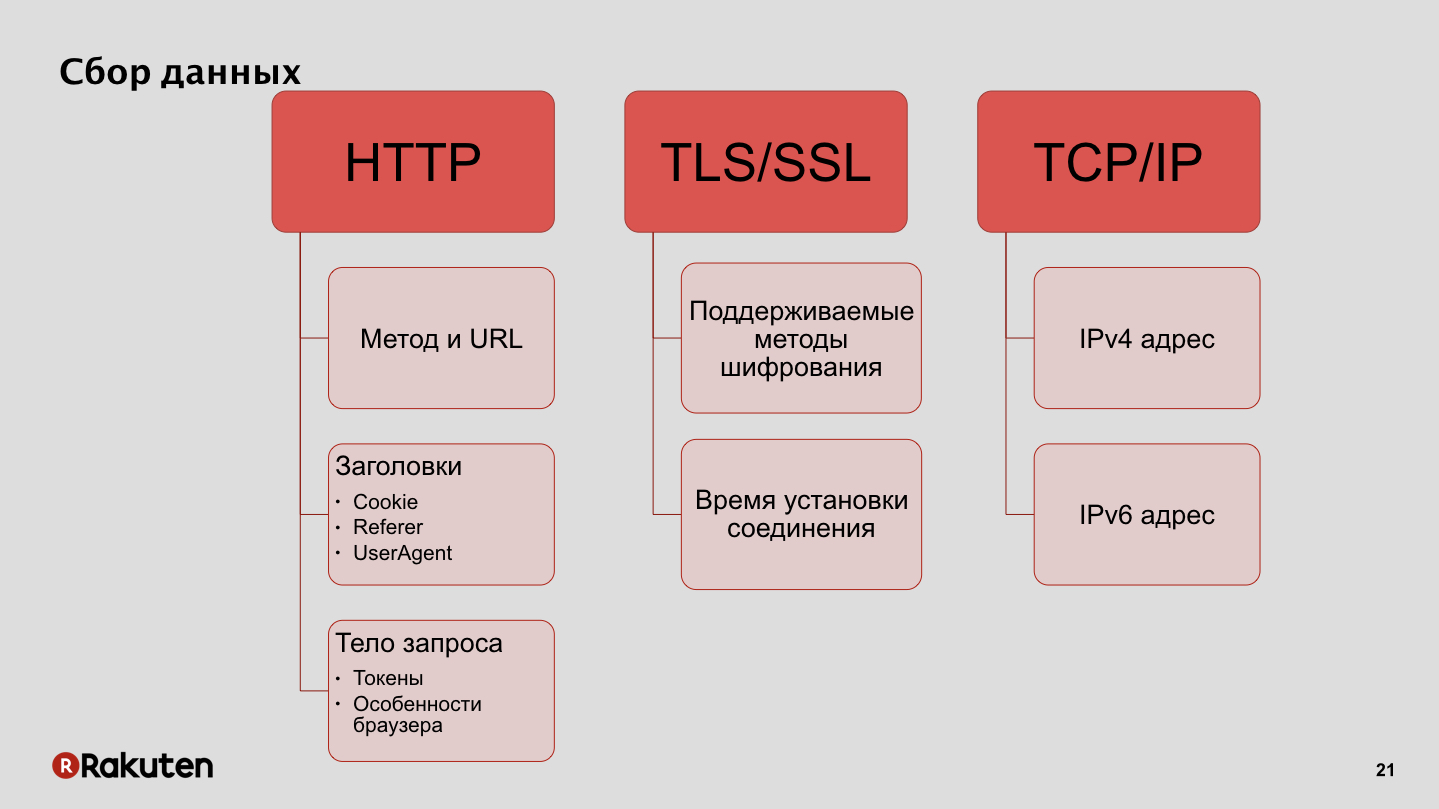
Como coletamos dados? Usamos endereços IP como um dos recursos, também uma das fontes de dados para nós são os protocolos de criptografia suportados pelos clientes e o tempo de configuração da conexão. Além disso, os dados que coletamos dos navegadores dos usuários, os recursos desses navegadores e os tokens que usamos para autenticar solicitações.
Como detectar intrusos? Você provavelmente espera que eu diga que construímos uma enorme rede neural e imediatamente capturamos todos. Na verdade não. Utilizamos uma abordagem multinível. Isso se deve ao fato de termos muitos serviços, grandes volumes de tráfego e, se você tentar colocar um sistema de computação complexo em tais volumes, provavelmente será muito caro e diminuirá a velocidade dos serviços. Portanto, começamos com um método banal simples: começamos a contar quantas solicitações vêm de endereços diferentes, de navegadores diferentes.

Esse método é muito primitivo, mas permite filtrar ataques maciços estúpidos como DDoS, quando você anomalias pronunciadas aparecem no tráfego. Nesse caso, você tem certeza absoluta de que é um invasor e pode bloqueá-lo. Mas esse método é adequado apenas no nível inicial, porque evita apenas os ataques mais difíceis.
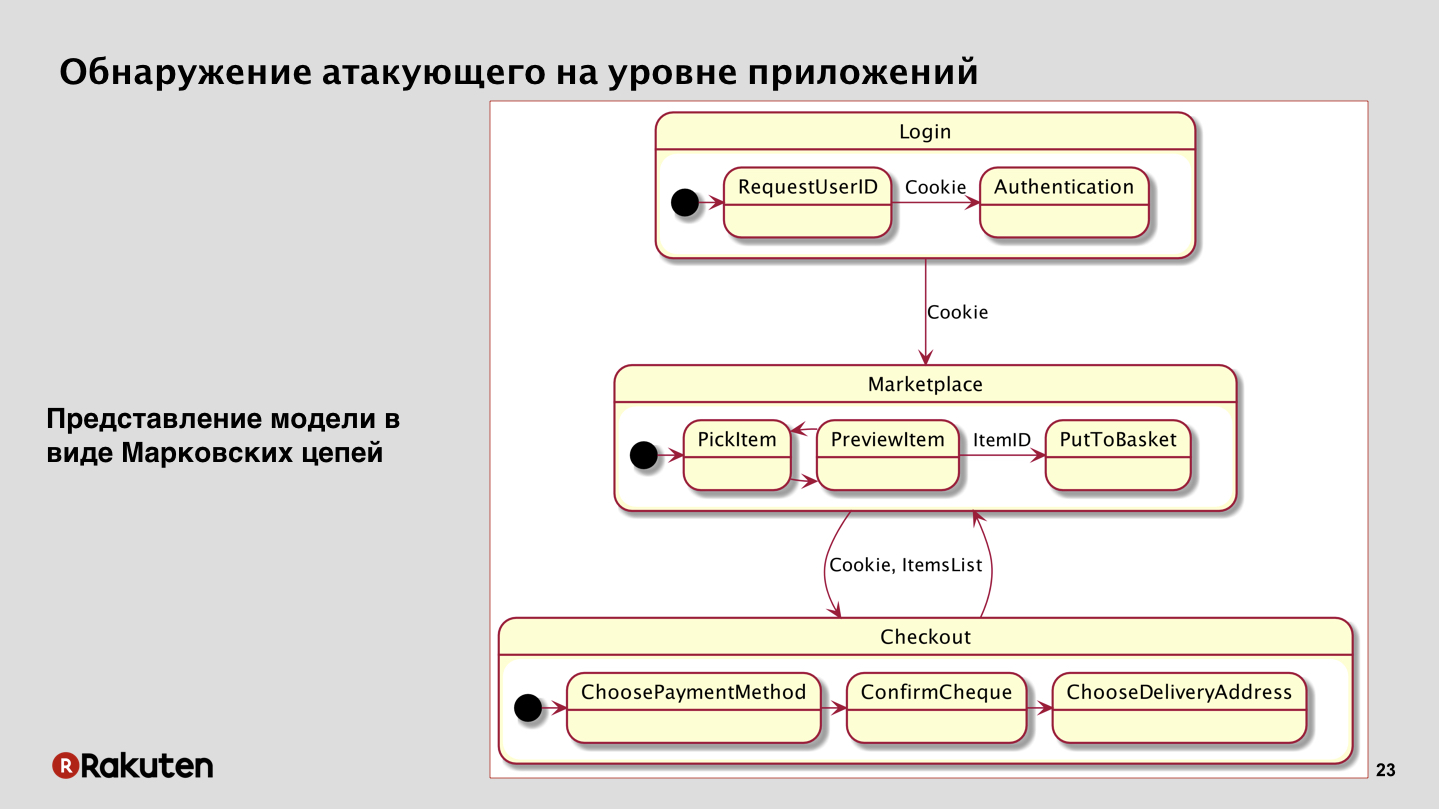
Depois disso, chegamos ao próximo método. Decidimos nos concentrar no fato de termos uma lógica comercial de aplicativos, e um invasor nunca pode simplesmente entrar em seu serviço e roubar dinheiro. Se ele não quebrou, é claro. No nosso caso, se você observar o esquema mais simplificado de algum mercado abstrato, veremos que o usuário deve fazer login primeiro, apresentar suas credenciais, receber cookies de sessão, depois ir ao mercado, procurar mercadorias lá e colocá-las na cesta. Depois disso, ele continua pagando pela compra, seleciona o endereço, o método de pagamento e, no final, clica em "pagar" e, finalmente, ocorre a compra de mercadorias.
Veja bem, um invasor precisa executar várias etapas. E essas transições entre estados, entre serviços se assemelham a um modelo matemático - são cadeias de Markov, que também podem ser usadas aqui. Em princípio, no nosso caso, eles mostraram resultados muito bons.

Eu posso dar um exemplo simplificado. Grosso modo, há um momento em que um usuário se autentica, quando escolhe compras e efetua um pagamento e, por exemplo, é óbvio como um invasor pode se comportar de maneira anormal, ele pode tentar fazer login várias vezes com contas diferentes. Ou ele pode adicionar produtos errados ao carrinho que os usuários comuns compram. Ou executa um número anormalmente grande de ações.
As cadeias de Markov geralmente consideram estados. Também decidimos acrescentar tempo a esses estados. Os invasores e os usuários normais se comportam de maneira muito diferente no tempo, e isso também ajuda a separá-los.
As cadeias de Markov são um modelo matemático bastante simples, são muito fáceis de contar em tempo real e permitem adicionar outro nível de proteção, eliminando outra parte do tráfego.
A próxima etapa. Pegamos os atacantes estúpidos, pegamos os atacantes da mente. Agora os mais inteligentes são deixados. Para invasores complicados, são necessários recursos adicionais. O que podemos fazer?
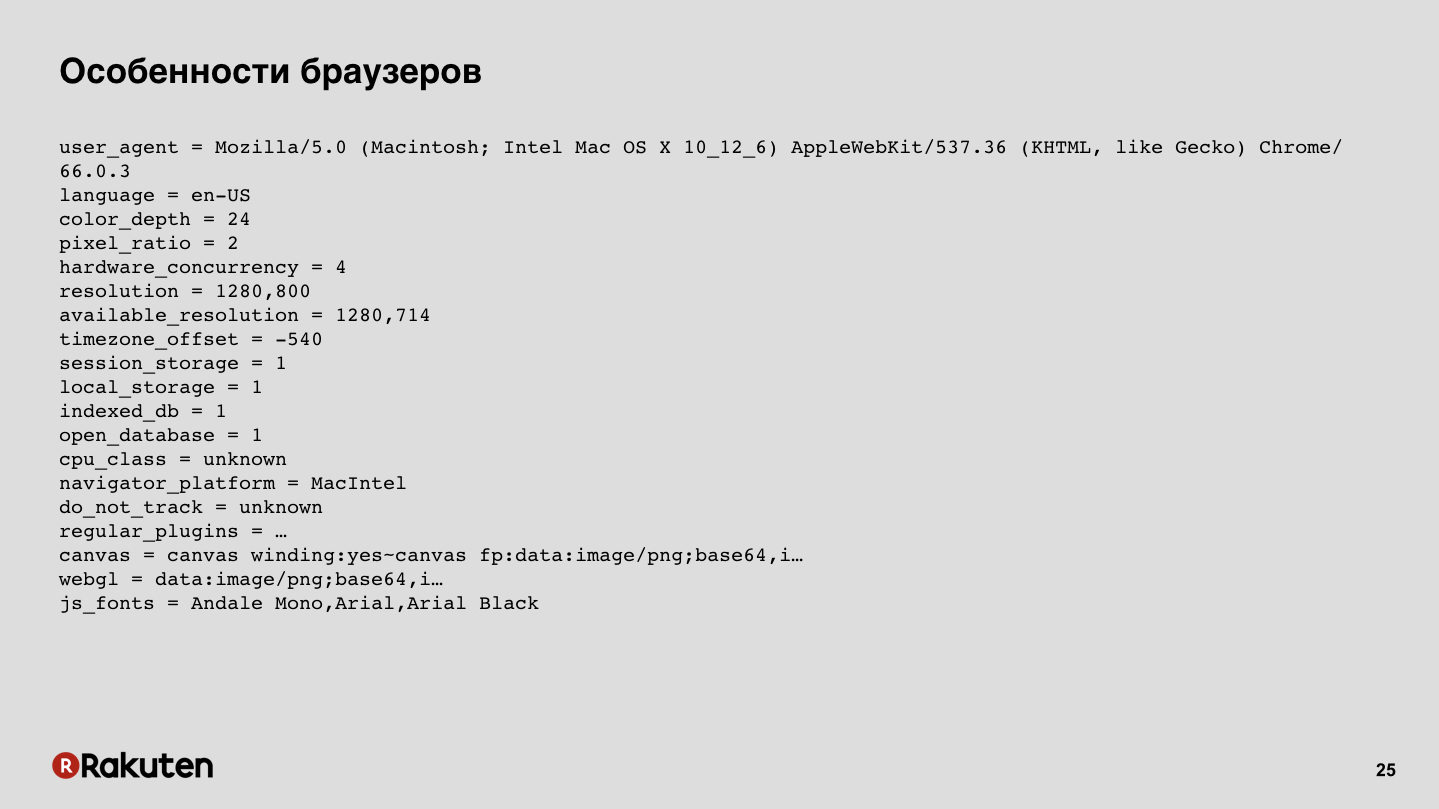
Podemos coletar algumas impressões digitais dos navegadores. Agora, os navegadores são sistemas bastante complexos, possuem muitos recursos suportados, executam JS, possuem vários recursos de baixo nível e tudo isso pode ser coletado, todos esses dados. No slide, há um exemplo de saída de uma das bibliotecas de código aberto.
Além disso, você pode coletar dados sobre como o usuário interage com seu serviço, como ele move o mouse, como ele toca em um dispositivo móvel, como ele rola a tela. Essas coisas são coletadas, por exemplo, pelo Yandex.Metrica. , , .
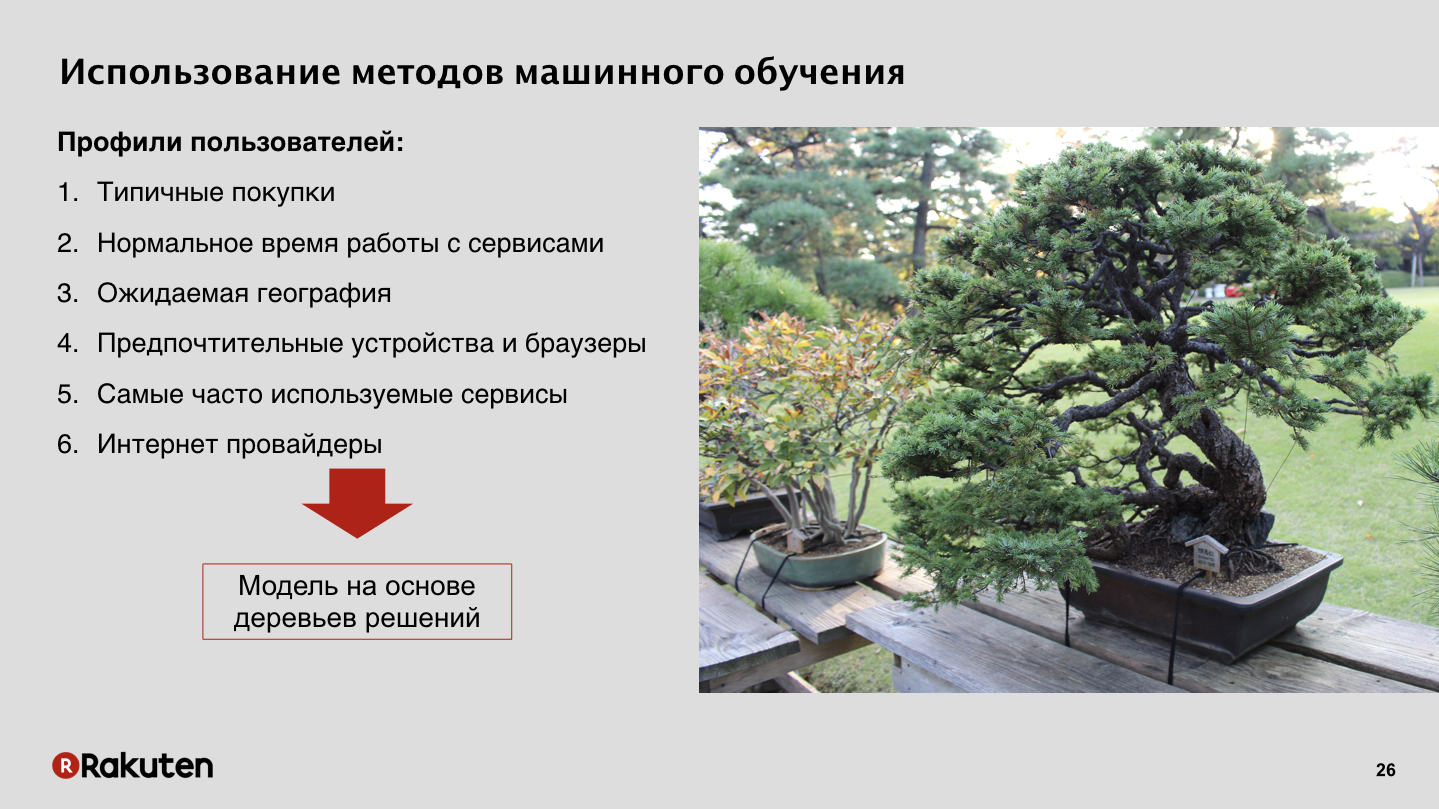
, . ? , , , , . , . machine learning, decision tree, . Decision tree if-else, , . , . - , - — , , .
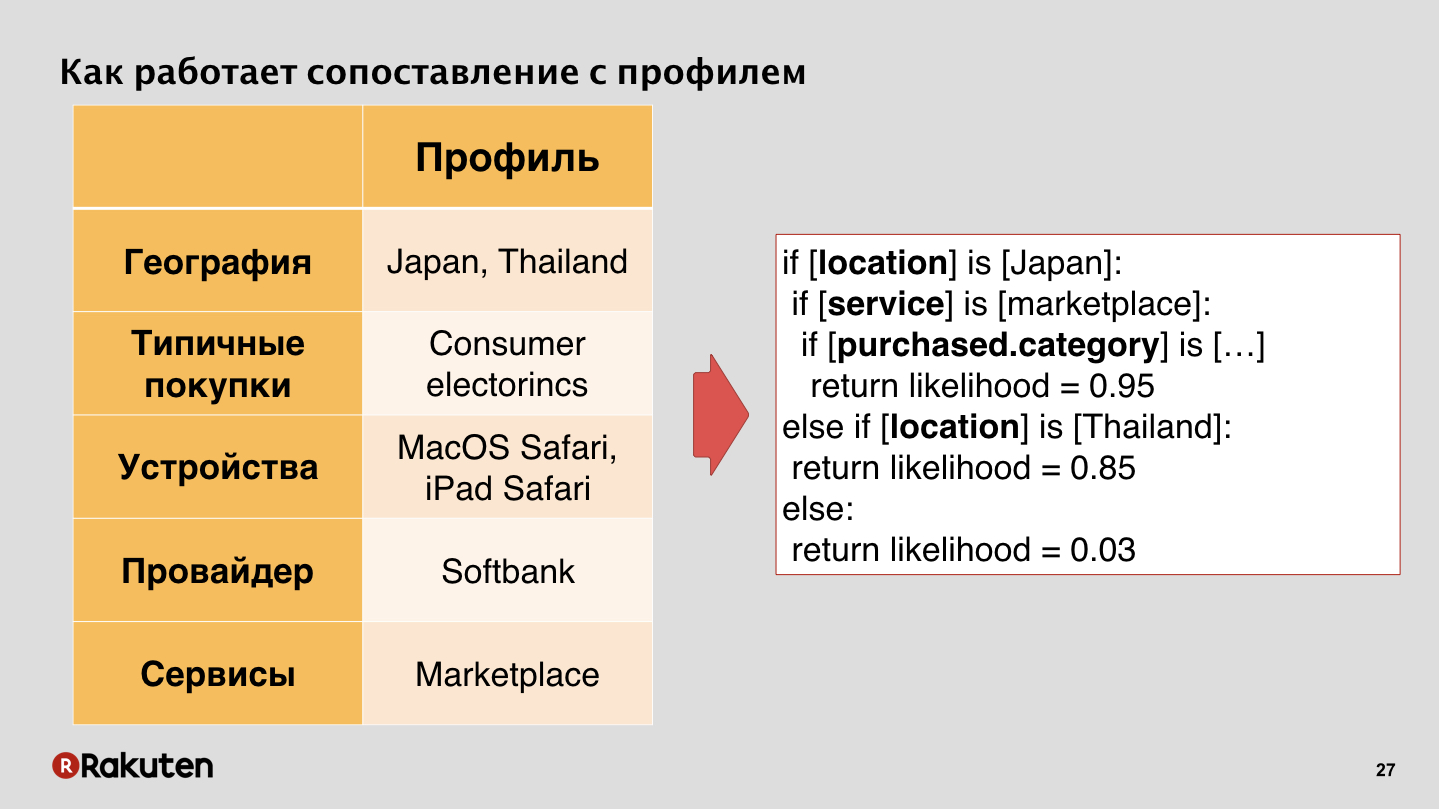
, , , - , , , Softbank, . , , . - , , , .
, , iTunes — , - , .
, , , .

. , ? , . , , , . , .
. , . . : . , .