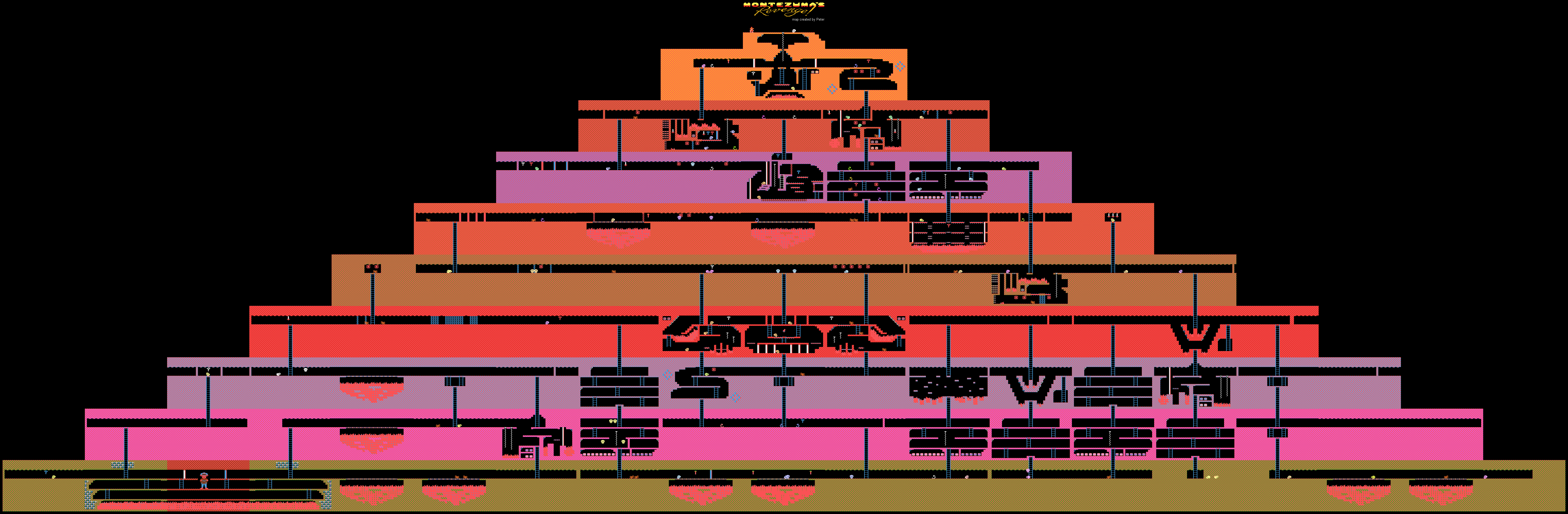
 Níveis de jogo de Atari da vingança de Montezuma
Níveis de jogo de Atari da vingança de MontezumaO DeepMind
demonstrou o processo de aprendizado da IA (sua forma fraca) para a passagem de jogos no Atari. O treinamento foi realizado demonstrando o sistema de transmissão de videogame do YouTube. Este método é usado por muitos jogadores humanos que, por um motivo ou outro, não conseguiram passar por algum tipo de jogo.
Geralmente, para resolver esse problema, é necessário usar o chamado método de
aprendizado por reforço . Essa técnica é bastante popular, pois permite treinar bots para executar várias tarefas específicas. Assim que o sistema obtém qualquer resultado, recebe uma pequena recompensa.
Os desenvolvedores criam algoritmos e modelos capazes de avaliar o ambiente de jogo, incluindo possíveis recompensas pela conclusão (pontos, bônus etc.). Tais sistemas aprendem o jogo passo a passo, passando gradualmente para a final.
O novo método desenvolvido no DeepMind é diferente de todos os outros. Os especialistas da empresa foram capazes de treinar a IA para jogar com a Atari, como Revenge, Pitfall e Private Eye, de Montezuma. Ao mesmo tempo, a ênfase nos pontos e prêmios não foi dada - o treinamento foi realizado nos tutoriais do YouTube. E isso nos permitiu alcançar resultados incomuns para a IA.
O fato é que jogos como a mesma Vingança de Montezuma são difíceis de entender pelas máquinas. Não há tarefa clara, não está claro para onde ir, quais itens coletar e o que fazer com eles no futuro. A máquina está simplesmente perdida, porque no processo de promoção não recebe recompensas e o treinamento com reforços aqui se torna inútil ou quase inútil.
No jogo em questão, você precisa controlar um personagem chamado Panama Joe. No final, ele deve chegar ao tesouro no antigo templo. Segundo a lenda, esses tesouros pertencem a Montezuma. Primeiro você precisa encontrar o primeiro item crítico para passar no jogo - a chave de ouro. Para detectá-lo, você precisa executar cerca de 100 etapas. Mas isso é se você souber o que fazer. Caso contrário, há um grande número de possibilidades 100 das
18 ações iniciais. Isso é demais para qualquer IA criada pelo homem. Bem, você não receberá uma recompensa aqui, tudo é muito, muito específico.
Uma maneira de informar ao computador o que fazer é demonstrar os cenários da passagem. Na verdade, não apenas carros, mas também as pessoas aprendem a executar várias tarefas por exemplos. Dançar, as ações do artista, soldar - tudo isso é melhor visto uma vez e não 100 vezes para ouvir como fazê-lo.
O DeepMind chegou à conclusão de que essa é a melhor maneira de mostrar ao computador como concluir uma tarefa com um resultado implícito. A tecnologia criada por especialistas realmente ajudou. Dois métodos foram usados para ensinar o exemplo: TDC (classificação da distância temporal) e CDC (classificação da distância temporal modal).
No primeiro caso, as IAs são treinadas para determinar a distância no ambiente do jogo, para observar a diferença entre dois quadros diferentes. A IA também “entende” o que precisa ser feito para mudar de um lugar para outro. Para o treinamento no YouTube, os vídeos recebem pares de quadros em ordem aleatória.
No segundo caso, a "compreensão" do acompanhamento sonoro também é adicionada. Os sons em quase todos os jogos correspondem ao desempenho de determinadas ações. Por exemplo, pulando, obtendo itens etc. Assim, o computador é treinado para perceber os sons como elementos importantes do jogo. O vídeo + som permite que o computador funcione muito bem no processo de aprovação do jogo.
Aqui estão as ações da IA treinada na vingança de Montezuma. A passagem dos outros dois jogos mencionados no começo está
aqui .
É verdade que não era possível abandonar completamente o papel das recompensas - até agora, a IA depende dos mesmos pontos. Mas o método usual de ensino do sistema, usado anteriormente, não permitiu chegar ao menos à chave de ouro, para a qual são dados os primeiros cem pontos. Então a IA, como um gatinho cego, cutucou em todas as direções, sem entender o que fazer. É verdade que o sistema de "reforço" também é modificado.
No processo de passar cada 16º quadro de vídeo do registro de aprovação de jogos de IA, ele é comparado com os quadros do vídeo que passam pelo jogo pelas pessoas. Se a comparação mostrar um alto grau de similaridade, a IA receberá uma recompensa. Com o tempo, a IA começa a executar a mesma sequência de ações que uma pessoa, para obter um quadro semelhante.
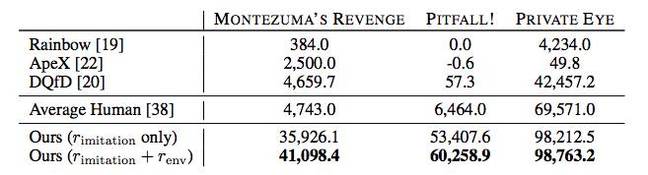
Além disso, a IA em muitos casos mostra melhores resultados do que jogadores humanos ou outros algoritmos de passagem, incluindo Rainbow, ApeX e DQfD.
Em princípio, tudo isso é impressionante, mas até agora os benefícios práticos das realizações do DeepMind não são claros. É possível usar o método de ensino de IA proposto pela empresa em outro lugar que não seja a passagem de jogos antigos? Mas, conhecendo as realizações do DeepMind no campo da IA, não há dúvida de que, de uma maneira ou de outra, tudo isso pode ser usado para fins práticos - é improvável que os especialistas começem a trabalhar na questão por uma questão de "diversão".