Este blog geralmente é dedicado ao reconhecimento de placas. Mas, trabalhando nessa tarefa, chegamos a uma solução interessante que pode ser facilmente aplicada a uma ampla gama de tarefas de visão computacional. Vamos falar sobre isso agora: como criar um sistema de reconhecimento que não o decepcione. E se você falhar, pode dizer a ela onde está o erro, treinar novamente e ter uma solução um pouco mais confiável do que antes. Bem-vindo ao gato!

O que aconteceu?
Imagine, você enfrentou a tarefa: encontrar pizza na foto e determinar que tipo de pizza é.
Vamos seguir brevemente o caminho padrão que frequentemente seguimos. Porque Para entender como fazer ... não precisa.
Etapa 1: pegue a base
 Etapa 2:
Etapa 2: para garantir a confiabilidade do reconhecimento, note-se que existe pizza e o que é histórico (portanto, incluiremos uma rede neural de segmentação no procedimento de reconhecimento, mas geralmente vale a pena):
 Etapa 3:
Etapa 3: colocamos em uma "forma normalizada" e classificamos usando outra rede neural convolucional:

Ótimo! Agora temos uma base de treinamento. Em média, o tamanho da base de treinamento pode ser de vários milhares de imagens.
Tomamos 2 redes de convolução, por exemplo, Unet e VGG. O primeiro é treinado nas imagens de entrada, depois normalizamos a imagem e treinamos o VGG para classificação. Funciona muito bem, transferimos para o cliente e consideramos o dinheiro ganho honestamente.
Não funciona assim!
Infelizmente, quase nunca. Existem vários problemas sérios que surgem durante a implementação:
- Variabilidade dos dados de entrada. Estudamos em um exemplo, na realidade, tudo saiu de maneira diferente. Sim, apenas durante a operação, algo deu errado.
- Muitas vezes, a precisão do reconhecimento permanece insuficiente. Quero 99,5%, mas passa de 60% a 90% em um bom dia. Mas eles queriam, como regra geral, automatizar uma solução que funcione e até melhor que as pessoas!
- Essas tarefas geralmente são terceirizadas, o que significa que os contratos já estão fechados, os atos são assinados e o proprietário da empresa deve decidir se deve investir na revisão ou abandonar completamente a decisão.
- Sim, apenas começa a se degradar com o tempo, como em qualquer sistema complexo, se você não envolver especialistas que participaram da criação ou o mesmo nível de qualificação.
Como resultado, para muitos que tocaram toda essa mecânica com as mãos, fica claro que tudo deve acontecer de uma maneira completamente diferente. Algo assim:
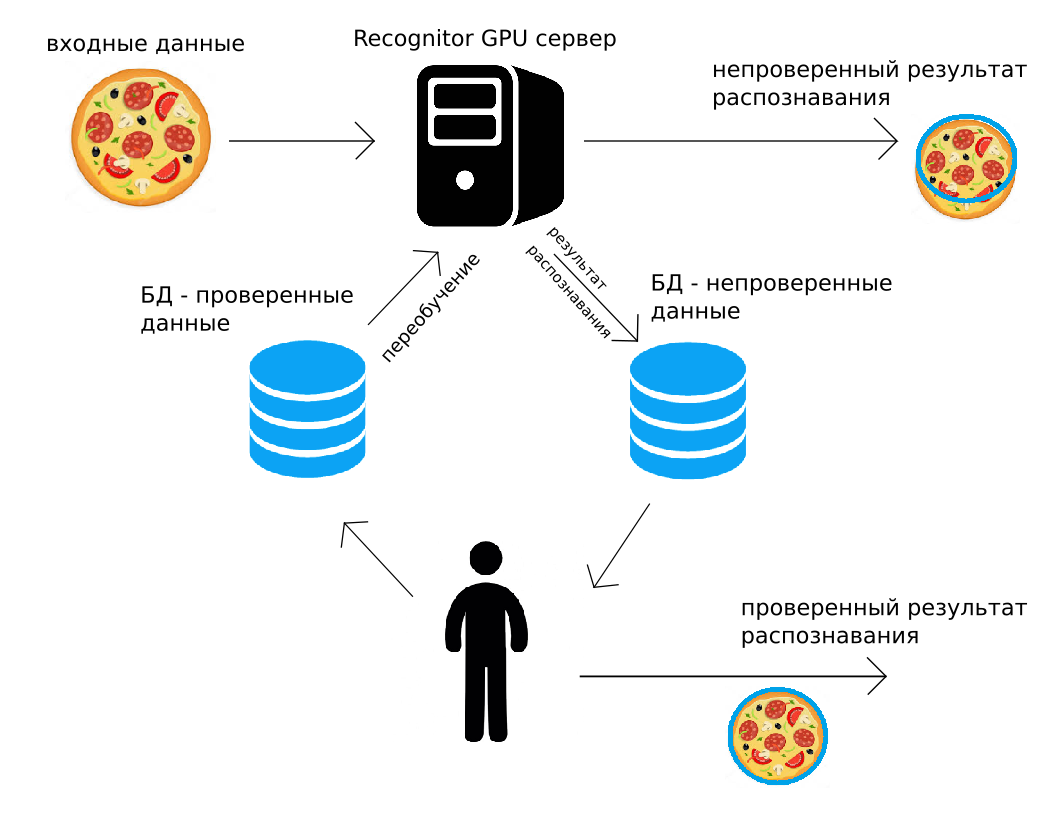
Os dados são enviados para o nosso servidor (via http POST ou usando a API Python), o servidor da GPU o reconhecerá "como pôde", retornando imediatamente o resultado. Ao longo do caminho, o mesmo resultado de reconhecimento e a imagem são adicionados ao arquivo. Uma pessoa então controla todos os dados ou uma parte aleatória deles, corrige-os. O resultado corrigido é colocado no segundo arquivo. E então, quando for conveniente fazer isso (por exemplo, à noite), todas as redes neurais convolucionais usadas para reconhecimento serão recicladas, usando os dados que a pessoa corrigiu.
Esse circuito de reconhecimento, supervisão humana e treinamento adicional resolve muitos dos problemas listados acima. Além disso, nas soluções em que é necessária alta precisão, pode ser usada saída verificada pelo homem. Parece que esse uso de dados verificados por humanos é muito caro, mas além disso mostraremos que quase sempre faz sentido econômico.
Exemplo real
Implementamos o princípio descrito e o aplicamos com sucesso em várias tarefas reais. Um deles é o reconhecimento de números nas imagens de contêineres em terminais ferroviários retirados de um tablet. É bastante conveniente - aponte o tablet para o recipiente, obtenha o número reconhecido e opere com ele no programa do tablet.
Um exemplo típico de instantâneo:

Na imagem, o número é quase perfeito, apenas muito ruído visual. Mas sombras severas, neve, layouts inesperados de letras, inclinações ou perspectivas sérias ocorrem ao fotografar.
E assim parece um conjunto de páginas da web nas quais toda a "mágica" acontece:
1) Carregar o arquivo no servidor (é claro, isso pode ser feito não a partir da página html, mas usando Python ou qualquer outra linguagem de programação):
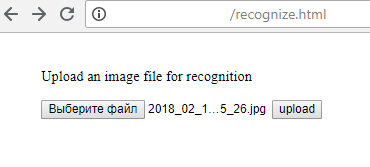
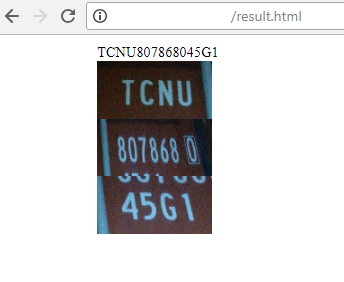
2) O servidor retorna o resultado do reconhecimento:
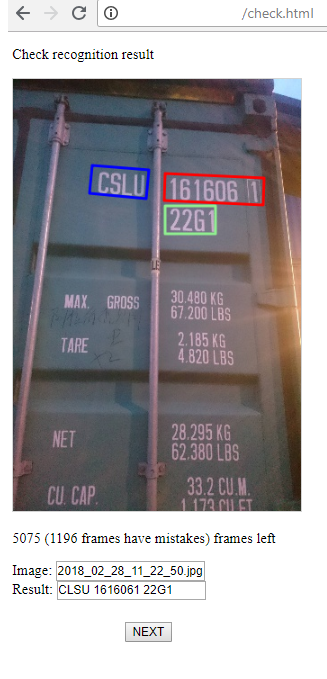
3) E esta é uma página para o operador que monitora o sucesso do reconhecimento e, se necessário, corrige o resultado. Existem duas etapas: a busca por áreas de grupos de símbolos, seu reconhecimento. O operador pode corrigir tudo isso se ele vir um erro.
4) Aqui está uma página simples onde você pode começar a treinar para cada um dos estágios de reconhecimento e, executando, veja a perda atual.
Minimalismo severo, mas funciona muito bem!
Como isso pode parecer do lado de uma empresa que planeja usar a abordagem descrita (ou nossa experiência e servidores Reconhecedores)?
- Redes neurais de ponta são selecionadas. Se tudo for baseado em soluções depuradas existentes, você poderá iniciar o servidor e configurar a marcação em uma semana.
- Um fluxo de dados (de preferência interminável) é organizado no servidor, várias centenas de quadros são marcados.
- O treinamento começa. Se tudo "se encaixar", o resultado será de 60 a 70% do reconhecimento bem-sucedido, o que ajuda muito a marcar mais.
- Em seguida, começa o trabalho sistemático de apresentar todas as situações possíveis, verificando os resultados do reconhecimento, editando e treinando novamente. Conforme você aprende, a incorporação do sistema em um processo de negócios está se tornando cada vez mais econômica.
Quem mais faz isso?
O tema do loop fechado não é novo. Muitas empresas oferecem sistemas de processamento de dados de um tipo ou de outro. Mas o paradigma do trabalho pode ser construído de maneiras completamente diferentes:
- Os Nvidia Digits são alguns modelos muito bons e poderosos envolvidos em uma GUI intuitiva, na qual o usuário precisa anexar suas fotos e JSON. A principal vantagem - um conhecimento mínimo de programação e administração oferece uma boa solução. Menos - esta solução pode estar longe de ser ótima (por exemplo, não é possível pesquisar números de carros via SSD). E para entender como otimizar a solução, o usuário não possui conhecimento suficiente. Se ele tem conhecimento suficiente, ele não precisa de DÍGITOS. O segundo menos - você precisa ter seu próprio equipamento para configurar e implantar tudo.
- Serviços de marcação, como Mechanical Turk, Toloka, Supervise.ly. Os dois primeiros fornecem ferramentas de marcação, bem como pessoas que podem marcar os dados. Este último fornece ótimas ferramentas, mas sem pessoas. Através dos serviços, você pode automatizar o trabalho humano, mas precisa ser um especialista na definição da tarefa.
- Empresas que já treinaram e fornecem uma solução fixa (Microsoft, Google, Amazon). Leia mais sobre eles aqui (https://habr.com/post/312714/). Suas decisões não são flexíveis, nem sempre "sob o capô" serão as melhores decisões necessárias no seu caso. Em geral, quase sempre isso não ajuda.
- Empresas que trabalham especificamente com seus dados, por exemplo ScaleAPI (https://www.scaleapi.com/). Eles têm uma ótima API, para o cliente será uma caixa preta. Dados de entrada - resultado de saída. É muito provável que por dentro existam as melhores soluções de automação, mas isso não importa para você. Soluções bastante caras em termos de um quadro, mas se seus dados são realmente valiosos - por que não?
- Empresas que possuem as ferramentas para realizar um ciclo quase completo com as próprias mãos. Por exemplo, PowerAI da IBM . É quase como DIGITS, mas você só precisa marcar os conjuntos de dados. Além disso, ninguém otimiza redes e soluções neurais. Mas muitos casos foram resolvidos. O modelo de rede neural resultante é implantado para você e receberá acesso http. Aqui há a mesma desvantagem dos dígitos - você precisa entender o que fazer. É o seu caso que pode "não convergir" ou simplesmente exigir uma abordagem incomum ao reconhecimento. Em geral, a solução é perfeita se você tiver uma tarefa bastante padrão, com objetos bem separáveis que precisam ser classificados.
- Empresas que resolvem exatamente o seu problema com suas ferramentas. Não existem muitas empresas desse tipo. Na realidade, eu me referiria apenas a CrowdFlower a eles. Aqui, por dinheiro razoável, eles colocam rabiscos, alocam um gerente, implantam seus servidores, onde seus modelos serão lançados. E por dinheiro mais sério, eles poderão alterar ou otimizar suas decisões para sua tarefa.
Grandes empresas trabalham com eles - ebay, oracle, tesco, adobe. A julgar pela sua abertura, eles interagem com sucesso com pequenas empresas.
Como isso difere do desenvolvimento personalizado do EPAM, por exemplo? O fato de que tudo está pronto aqui. 99% da solução não é escrita, mas montada a partir de módulos prontos: marcação de dados, seleção de rede, treinamento, desenvolvimento. As empresas que desenvolvem sob encomenda não possuem essa velocidade, a dinâmica do desenvolvimento de soluções e a infraestrutura finalizada. Acreditamos que a tendência e a abordagem identificadas pela CrowdFlower são verdadeiras.
Para quais tarefas isso funciona?
Talvez 70% das tarefas sejam automatizadas dessa maneira. As tarefas mais adequadas são o reconhecimento diversificado de áreas que contêm texto. Por exemplo, placas de matrícula de carros, sobre as quais
já falamos , números de trens (
aqui está o nosso exemplo, há dois anos ), inscrições em contêineres.

Muitas informações técnicas simbólicas são reconhecidas nas fábricas para explicar os produtos e sua qualidade.
Essa abordagem ajuda muito no reconhecimento de produtos nas prateleiras e etiquetas de preços, embora sejam necessárias soluções de reconhecimento bastante complicadas.

Mas você pode escapar das tarefas com informações técnicas. Qualquer semântica, seja segmentação de instância, com a detecção de carros, argali, alces e peles de focas, também cairá perfeitamente nessa abordagem.

Uma direção muito promissora é manter a comunicação com as pessoas nos bots de bate-papo por voz e texto. Haverá uma maneira bastante incomum de marcar: contexto, tipo de frase, seu “preenchimento”. Mas o princípio é o mesmo: trabalhamos de modo automático, uma pessoa controla a correção do entendimento e das respostas. Você pode recorrer à assistência do operador em caso de tom insatisfeito ou irritado do cliente. À medida que os dados se acumulam, nós treinamos novamente.
Como trabalhar com vídeo?
Se você ou dentro da sua empresa tiver desenvolvido as competências necessárias (um pouco de experiência em Machine Learning, trabalhando com o zoológico Framework, tanto offline quanto online), não haverá dificuldade em resolver problemas simples de visão computacional: segmentação, classificação, reconhecimento de texto e outro
Mas para o vídeo, nem tudo é tão bom. Como você marca essas quantidades infinitas de dados? Por exemplo, pode acontecer que a cada poucos segundos um objeto (ou vários objetos) apareça no quadro que precise ser marcado. Como resultado, tudo isso pode se transformar em uma visualização quadro a quadro e ocupa tantos recursos que nem é preciso falar sobre controle adicional por uma pessoa após o lançamento de uma solução. Mas isso pode ser superado se você apresentar o vídeo da maneira correta para destacar os quadros com uma área de interesse.
Por exemplo, deparamos com enormes séries de vídeos em que era necessário destacar um único objeto específico - o acoplamento das plataformas ferroviárias. E realmente não foi fácil. Acontece que nem tudo é tão assustador, se você ampliar o monitor, escolher uma taxa de quadros, por exemplo, 10FPS e colocar 256 quadros em uma imagem, ou seja, 25.6s em uma imagem:

Provavelmente parece assustador. Mas, na realidade, leva cerca de 15s para clicar em um único quadro, escolhendo o centro do acoplamento do carro no quadro. E mesmo uma pessoa em um dia ou dois pode marcar pelo menos 10 horas de vídeo. Obtenha mais de 30 mil exemplos para treinamento. Além disso, a passagem de plataformas na frente da câmera, neste caso, não é um processo contínuo (mas raro, deve-se notar), é bastante realista, mesmo em tempo quase real, corrigir a máquina de reconhecimento, reabastecendo a base de treinamento! E se o reconhecimento ocorrer na maioria dos casos corretamente, uma hora de vídeo poderá ser superada em alguns minutos. E, em geral, negligenciar o controle total da pessoa não é economicamente rentável.
Ainda é mais fácil se o vídeo precisar ser marcado como "sim / não" em vez da localização do objeto. Afinal, os eventos geralmente ficam "presos juntos" e, com um toque do mouse, você pode marcar até 16 quadros por vez.
A única coisa, como regra, é o uso de duas etapas na análise do vídeo: pesquise "quadros ou áreas de interesse" e trabalhe com cada um desses quadros (ou sequência de quadros) por outros algoritmos.
Economia máquina-humana
Quanto o custo do processamento de dados visuais pode ser otimizado? De uma forma ou de outra, é estritamente necessário ter uma pessoa para controlar o reconhecimento de dados. Se esse controle for seletivo, os custos serão insignificantes. Mas se estamos falando sobre controle total, então quanto pode ser benéfico? Acontece que isso faz sentido quase sempre, se antes uma pessoa executava a mesma tarefa sem a ajuda de uma máquina.
Vamos pegar o não o melhor exemplo desde o início: pesquise pizza na imagem, marcação e seleção de tipo (e, na realidade, várias outras características). Embora a tarefa não seja tão sintética quanto possa parecer. Existe, na realidade, o controle da aparência dos produtos de rede de franquia.
Suponha que o reconhecimento usando um servidor GPU exija 0,5s de tempo da máquina, para uma pessoa marcar completamente um quadro por cerca de 10s (escolha o tipo de pizza e sua qualidade de acordo com vários parâmetros) e verifique se tudo foi detectado corretamente pelo computador, você precisa de 2s. Obviamente, haverá um desafio em como é conveniente apresentar esses dados, mas esses tempos são bastante comparáveis à nossa prática.
Precisamos de mais informações para o custo do layout manual e do aluguel de um servidor GPU. Como regra, você não precisa confiar em uma carga completa do servidor. Seja possível atingir o carregamento de 100.000 quadros por dia (serão necessários 60% da capacidade de processamento de uma GPU) com um custo estimado de um aluguel mensal de servidores de 60.000 rublos. Acontece 2 centavos para a análise de um quadro na GPU. Uma análise manual a um custo de 30.000 r por 40 horas de tempo de trabalho custará 26 copias por quadro.
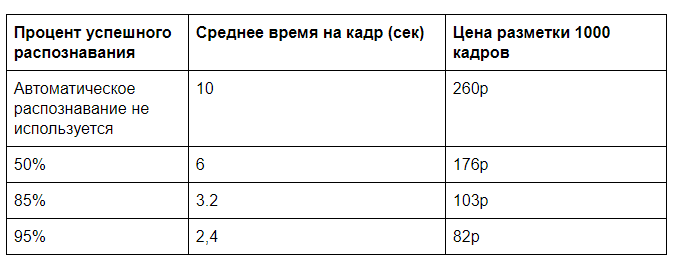
E se você remover posteriormente o controle total, poderá conseguir um preço de quase 20 rublos por 1000 quadros. Se houver muitos dados de entrada, é possível otimizar algoritmos de reconhecimento, trabalhar na transferência de dados e obter eficiência ainda maior.
Na prática, descarregar uma pessoa conforme o sistema de reconhecimento aprende tem outro significado importante - torna muito mais fácil dimensionar seu produto. Um aumento significativo na quantidade de dados permite que você treine melhor o servidor de reconhecimento, e a precisão aumenta. E o número de funcionários envolvidos no processo de processamento de dados aumentará não proporcionalmente ao volume de dados, o que simplificará significativamente o crescimento da empresa do ponto de vista organizacional.
Como regra, quanto mais texto e contornos você precisar inserir manualmente, mais lucrativo será o uso do reconhecimento automático.
E tudo isso muda?
Claro, não todos. Mas agora algumas áreas do negócio não são tão loucas quanto antes.
Deseja fazer um serviço offline sem uma pessoa na instalação? Plante um operador remotamente e monitore
em câmeras para cada cliente? Acontecerá um pouco pior do que uma pessoa viva no local. Sim, e os operadores precisam de quase mais. E se você descarregar o operador a cada 5 vezes? Pode ser um salão de beleza sem recepção, controle na fábrica e sistemas de segurança. 100% de precisão não é necessária - você pode excluir completamente o operador da corrente.
É possível organizar sistemas contábeis bastante complexos para os serviços existentes, a fim de aumentar sua eficiência: controle de passageiros, veículos, horário dos serviços, onde existe o risco de "contornar" a bilheteria, etc.
Se a tarefa estiver no nível atual de desenvolvimento da visão computacional e não exigir soluções completamente novas, isso não exigirá investimentos sérios no desenvolvimento.