Adicionado por: good discussion on Hacker NewsDavid Yu, no GitHub, desenvolveu um
teste de desempenho interessante para chamadas de função por meio de várias interfaces externas (Foreign Function Interfaces,
FFI ).
Ele criou um arquivo de objeto compartilhado (
.so ) com uma função simples C. Em seguida, ele escreveu um código para chamar essa função repetidamente por cada FFI com uma dimensão de tempo.
Para C "FFI", ele usou o link dinâmico padrão, não
dlopen() . Essa diferença é muito importante, pois realmente afeta os resultados do teste. Você pode argumentar quão honesta essa comparação é com a FFI real, mas ainda é interessante medir.
O resultado de referência mais surpreendente é que
o FFI
de LuaJIT é
significativamente mais rápido que C. É cerca de 25% mais rápido que uma chamada C nativa para uma função de objeto compartilhado. Como uma linguagem de script de tipo fraco e dinâmico pode ultrapassar a referência C? O resultado é preciso?
De fato, isso é bastante lógico. O teste é executado no Linux, portanto, o atraso vem da Tabela de Ligação de Procedimentos (PLT). Eu preparei um experimento realmente simples para demonstrar o efeito na planície antiga C:
https://github.com/skeeto/dynamic-function-benchmarkAqui estão os resultados do Intel i7-6700 (Skylake):
plt: 1.759799 ns/call
ind: 1.257125 ns/call
jit: 1.008108 ns/callExistem três tipos diferentes de chamadas de função:
- Via PLT.
- Chamada de função indireta (via
dlsym(3) ) - Chamada de função direta (através de uma função compilada JIT)
Como você pode ver, o último é o mais rápido. Geralmente não é usado em programas C, mas é uma opção natural na presença de um compilador JIT, incluindo, obviamente, LuaJIT.
No meu benchmark, a função
empty() é chamada:
void empty(void) { }
Compile em um objeto compartilhado:
$ cc -shared -fPIC -Os -o empty.so empty.c
Como na
comparação anterior do
PRNG , o benchmark tantas vezes quanto possível chama essa função antes do alarme disparar.
Tabelas de layout de procedimento
Quando um programa ou biblioteca chama uma função em outro objeto compartilhado, o compilador não pode saber onde essa função estará na memória. As informações são encontradas apenas em tempo de execução quando o programa e suas dependências são carregados na memória. Geralmente, a função está localizada em locais aleatórios, por exemplo, de acordo com a randomização do espaço de endereço (Randomização de Layout do Espaço de Endereço, ASLR).
Como resolver esse problema? Bem, existem várias opções.
Uma delas é marcar todas as chamadas em metadados binários. O construtor de tempo de execução dinâmico
insere o endereço correto em todas as chamadas. O mecanismo específico depende do
modelo de código usado durante a compilação.
A desvantagem dessa abordagem é que ela diminui o carregamento, aumenta o tamanho dos arquivos binários e reduz a
troca de páginas de código entre diferentes processos. O download é mais lento porque todos os pares de discagem dinâmica precisam ser corrigidos com o endereço correto antes de iniciar o programa. O binário está inchado porque cada entrada precisa de um lugar na tabela. E a falta de compartilhamento está associada a uma alteração nas páginas de código.
Por outro lado, a sobrecarga de invocar funções dinâmicas pode ser eliminada, o que fornece um desempenho semelhante ao JIT, conforme mostrado no benchmark.
A segunda opção é rotear todas as chamadas dinâmicas por meio de uma tabela. O ponto de discagem original refere-se ao esboço nesta tabela e, a partir daí, à função dinâmica real. Com essa abordagem, o código não precisa ser corrigido, o que leva a uma
troca trivial entre processos. Para cada função dinâmica, você precisa corrigir apenas um registro na tabela. Além disso, essas correções podem ser feitas
preguiçosamente , na primeira chamada da função, o que acelera o carregamento ainda mais.
Nos sistemas binários ELF, essa tabela é chamada de Tabela de Ligação de Procedimentos (PLT). O próprio PLT não é realmente corrigido - é exibido como somente leitura para o restante do código. Em vez disso, a Global Offset Table (GOT) é corrigida. O stub PLT recupera o endereço de uma função dinâmica do GOT e salta
indiretamente para esse endereço. Para carregar preguiçosamente endereços de função, essas entradas GOT são inicializadas com o endereço da função que encontra o caractere de destino, atualiza o GOT com esse endereço e depois passa para a função. As chamadas subseqüentes usam um endereço detectado preguiçosamente.
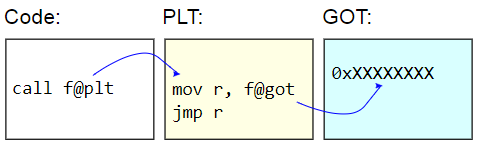
A desvantagem do PLT é a sobrecarga adicional de chamar uma função dinâmica, que é o que apareceu no benchmark. Como o benchmark mede
apenas chamadas de função, a diferença parece bastante significativa, mas na prática geralmente é próxima de zero.
Aqui está a referência:
volatile sig_atomic_t running; static long plt_benchmark(void) { long count; for (count = 0; running; count++) empty(); return count; }
Como
empty() está em um objeto compartilhado, a chamada passa pelo PLT.
Chamadas dinâmicas indiretas
Outra maneira de chamar funções dinamicamente é percorrer o PLT e obter o endereço da função de destino no programa, por exemplo, via
dlsym(3) .
void *h = dlopen("path/to/lib.so", RTLD_NOW); void (*f)(void) = dlsym("f"); f();
Se o endereço da função for recebido, o custo será menor do que a função chama pelo PLT. Não há função intermediária do stub e acesso ao GOT. (Cuidado: se o programa possui um registro PLT para esta função, o
dlsym(3) pode realmente retornar um endereço de stub).
Mas este ainda é um desafio
indireto . Nas arquiteturas convencionais,
as chamadas
diretas de função recebem seu endereço relativo imediato. Ou seja, o objetivo da chamada é um deslocamento codificado do ponto de chamada. A CPU pode descobrir para onde a chamada irá muito antes.
As chamadas indiretas têm mais custos indiretos. Primeiro, o endereço precisa ser armazenado em algum lugar. Mesmo que seja apenas um registro, seu uso aumenta o déficit de registros. Segundo, chamadas indiretas provocam um preditor de ramificação na CPU, impondo carga adicional ao processador. Na pior das hipóteses, uma chamada pode até parar o pipeline.
Aqui está a referência:
volatile sig_atomic_t running; static long indirect_benchmark(void (*f)(void)) { long count; for (count = 0; running; count++) f(); return count; }
A função passada para esse benchmark é extraída usando o
dlsym(3) , portanto o compilador não pode
fazer algo complicado , como converter essa chamada indireta de volta em direta.
Se o corpo do loop for complexo o suficiente para causar um déficit de registros e, assim, fornecer o endereço para a pilha, esse benchmark também não poderá ser honestamente comparado ao PLT.
Chamadas diretas de função
Os dois primeiros tipos de chamadas de funções dinâmicas são simples e fáceis de usar. Chamadas
diretas para funções dinâmicas são mais difíceis de organizar, pois exigem alterações de código durante a execução. No meu benchmark, montei um
pequeno compilador JIT para gerar uma chamada direta.
O truque é que nas transições explícitas x86-64 são limitadas a um intervalo de 2 GB devido ao operando assinado de 32 bits (assinado imediatamente). Isso significa que o código JIT deve ser colocado quase ao lado da função de destino,
empty() . Se o código JIT precisar chamar duas funções dinâmicas diferentes, divididas por mais de 2 GB, é impossível fazer duas chamadas diretas.
Para simplificar a situação, minha referência não está preocupada com a escolha exata ou muito cuidadosa do endereço do código JIT. Depois de receber o endereço da função de destino, ele simplesmente subtrai 4 MB, arredonda para a página mais próxima, aloca um pouco de memória e grava código nela. Se tudo for feito como deveria, então, para procurar um local, é necessário verificar suas próprias representações do programa na memória, e isso não pode ser feito de maneira limpa e portátil. O Linux
requer a análise de arquivos virtuais em / proc .
É assim que minha alocação de memória JIT se parece. Ele pressupõe
um comportamento razoável para transmitir uintptr_t :
static void jit_compile(struct jit_func *f, void (*empty)(void)) { uintptr_t addr = (uintptr_t)empty; void *desired = (void *)((addr - SAFETY_MARGIN) & PAGEMASK); unsigned char *p = mmap(desired, len, prot, flags, fd, 0); }
Duas páginas se destacam aqui: uma para escrita e a outra com código não gravável. Como na minha
biblioteca de fechamentos , aqui a página inferior é gravável e contém uma variável em
running que é redefinida para alarme. Esta página deve estar ao lado do código JIT para fornecer acesso efetivo ao RIP, como uma função nos outros dois benchmarks. A página superior contém este código de montagem:
jit_benchmark: push rbx xor ebx, ebx .loop: mov eax, [rel running] test eax, eax je .done call empty inc ebx jmp .loop .done: mov eax, ebx pop rbx ret
call empty é a única instrução gerada dinamicamente, é necessário preencher corretamente o endereço relativo (menos 5 é indicado em relação ao
final da instrução):
// call empty uintptr_t rel = (uintptr_t)empty - (uintptr_t)p - 5
Se a função
empty() não estiver no objeto geral, mas no mesmo arquivo binário, essa é essencialmente uma chamada direta que o compilador irá gerar para
plt_benchmark() , assumindo que, por algum motivo, ele não tenha construído
empty() .
Ironicamente, chamar um código compilado por JIT requer uma chamada indireta (por exemplo, através de um ponteiro de função), e não há como contornar isso. O que posso fazer aqui, JIT-compila outra função para uma chamada direta? Felizmente, isso não importa, porque apenas uma chamada direta é medida em um loop.
Nenhum segredo
Diante desses resultados, fica claro por que o LuaJIT gera chamadas mais eficientes para funções dinâmicas que o PLT,
mesmo que permaneçam chamadas indiretas . No meu benchmark, as chamadas indiretas sem PLT foram 28% mais rápidas que com o PLT, e as chamadas diretas sem PLT foram 43% mais rápidas que com o PLT. Essa pequena vantagem dos programas JIT em relação aos programas nativos antigos simples é alcançada devido à rejeição absoluta da troca de código entre processos.