
Em um projeto relacionado à segurança dos sistemas Linux, precisávamos interceptar chamadas para funções importantes dentro do kernel (como abrir arquivos e processos em execução) para fornecer a capacidade de monitorar a atividade no sistema e bloquear preventivamente a atividade de processos suspeitos.
Durante o processo de desenvolvimento, conseguimos inventar uma abordagem muito boa, que nos permite interceptar convenientemente qualquer função no kernel por nome e executar nosso código em torno de suas chamadas. O interceptador pode ser instalado a partir de um módulo GPL carregável, sem reconstruir o kernel. A abordagem suporta os kernels versão 3.19+ para a arquitetura x86_64.
(Imagem do pinguim logo acima: © En3l com DeviantArt .)Abordagens conhecidas
API de segurança do Linux
O mais correto seria usar a
API de segurança do
Linux - uma interface especial criada especificamente para esses fins. Em locais críticos do código do kernel, localizam-se chamadas para funções de segurança, que, por sua vez, retornam chamadas definidas pelo módulo de segurança. O módulo de segurança pode examinar o contexto de uma operação e tomar uma decisão sobre se é permitido ou negado.
Infelizmente, a API de segurança do Linux tem algumas limitações importantes:
- módulos de segurança não podem ser carregados dinamicamente, fazem parte do kernel e exigem reconstrução
- pode haver apenas um módulo de segurança no sistema (com algumas exceções)
Se a posição dos desenvolvedores do kernel for ambígua em relação à multiplicidade de módulos, a proibição de carregamento dinâmico é fundamental: o módulo de segurança deve fazer parte do kernel para garantir a segurança constantemente, a partir do momento do carregamento.
Portanto, para usar a API de segurança, você deve fornecer seu próprio conjunto de kernel, além de integrar o módulo complementar ao SELinux ou AppArmor, que são usados por distribuições populares. O cliente não quis assinar essas obrigações, portanto essa rota foi fechada.
Por esses motivos, a API de segurança não nos convinha, caso contrário, seria uma opção ideal.
Modificação da tabela de chamadas do sistema
O monitoramento era necessário principalmente para ações executadas pelos aplicativos do usuário, para que, em princípio, pudesse ser implementado no nível das chamadas do sistema. Como você sabe, o Linux armazena todos os manipuladores de chamadas do sistema na tabela
sys_call_table . A substituição de valores nesta tabela leva a uma mudança no comportamento de todo o sistema. Assim, mantendo os valores antigos do manipulador e substituindo o nosso próprio manipulador na tabela, podemos interceptar qualquer chamada do sistema.
Essa abordagem tem algumas vantagens:
- Controle total sobre todas as chamadas do sistema - a única interface para o kernel para aplicativos do usuário. Ao usá-lo, podemos ter certeza de que não perderemos nenhuma ação importante executada pelo processo do usuário.
- Sobrecarga mínima. Há um investimento de capital único ao atualizar a tabela de chamadas do sistema. Além da carga útil inevitável do monitoramento, a única despesa é uma chamada de função extra (para chamar o manipulador de chamadas do sistema original).
- Requisitos mínimos de kernel. Se desejado, essa abordagem não requer opções de configuração adicionais no kernel; portanto, em teoria, ela suporta a maior variedade possível de sistemas.
No entanto, ele também sofre de algumas falhas:
- A complexidade técnica da implementação. Por si só, substituir ponteiros em uma tabela não é difícil. Porém, tarefas relacionadas exigem soluções não óbvias e uma certa qualificação:
- tabela de chamadas do sistema de pesquisa
- desvio de proteção de modificação de tabela
- substituição atômica e segura
Tudo isso é interessante, mas exige um tempo valioso de desenvolvimento, primeiro para implementação e, depois, para suporte e compreensão.
- Incapacidade de interceptar alguns manipuladores. Nos kernels anteriores à versão 4.16, o tratamento de chamadas do sistema para a arquitetura x86_64 continha várias otimizações. Alguns deles exigiram que o manipulador de chamadas do sistema fosse um adaptador especial implementado no assembler. Consequentemente, esses manipuladores às vezes são difíceis, e às vezes impossíveis de substituir pelos seus, escritos em C. Além disso, diferentes otimizações são usadas em diferentes versões do kernel, o que aumenta as dificuldades técnicas do mealheiro.
- Somente chamadas do sistema são interceptadas. Essa abordagem permite substituir os manipuladores de chamadas do sistema, o que limita os pontos de entrada apenas a eles. Todas as verificações adicionais são realizadas no início ou no final, e temos apenas os argumentos da chamada do sistema e seu valor de retorno. Às vezes, isso leva à necessidade de duplicar verificações sobre a adequação de argumentos e verificações de acesso. Às vezes, isso gera sobrecarga desnecessária quando você precisa copiar a memória do processo do usuário duas vezes: se o argumento é passado por um ponteiro, primeiro precisamos copiá-lo, então o manipulador original copiará o argumento novamente por si mesmo. Além disso, em alguns casos, as chamadas do sistema fornecem uma granularidade muito baixa de eventos que precisam ser filtrados adicionalmente pelo ruído.
Inicialmente, escolhemos e implementamos com êxito essa abordagem, buscando os benefícios do suporte ao maior número de sistemas. No entanto, naquela época ainda não conhecíamos os recursos do x86_64 e as restrições nas chamadas interceptadas. Mais tarde, tornou-se crítico para nós suportar chamadas de sistema relacionadas ao início de novos processos - clone () e execve () - que são apenas especiais. Foi isso que nos levou à busca de novas opções.
Usando kprobes
Uma das opções consideradas foi o uso do
kprobes : uma API especializada projetada principalmente para depurar e rastrear o kernel. Essa interface permite que você defina pré e pós-processadores para
qualquer instrução no kernel, bem como manipuladores de entrada e retorno para a função. Os manipuladores têm acesso aos registros e podem alterá-los. Assim, poderíamos obter o monitoramento e a capacidade de influenciar o curso adicional do trabalho.
Benefícios do uso do kprobes para interceptar:
- API madura. Kprobes existem e melhoram desde tempos imemoriais (2002). Eles têm uma interface bem documentada, a maioria das armadilhas já foram encontradas, seu trabalho foi otimizado o máximo possível e assim por diante. Em geral, toda uma montanha de vantagens em relação às bicicletas experimentais feitas por si.
- Interceptação de qualquer lugar no núcleo. Os Kprobes são implementados usando pontos de interrupção (instruções int3) incorporados no código executável do kernel. Isso permite que você instale o kprobes literalmente em qualquer lugar de qualquer função, se conhecido. Da mesma forma, o kretprobes é implementado através da falsificação do endereço de retorno na pilha e permite que você intercepte o retorno de qualquer função (com exceção das que, em princípio, não retornam o controle).
Desvantagens dos kprobes:
- Dificuldade técnica. O Kprobes é apenas uma maneira de definir um ponto de interrupção em qualquer lugar do kernel. Para obter os argumentos de uma função ou os valores das variáveis locais, é necessário saber em quais registros ou onde estão localizados na pilha e extraí-los independentemente a partir daí. Para bloquear uma chamada de função, você deve modificar manualmente o estado do processo para que o processador pense que já retornou o controle da função.
- Jprobes estão obsoletos. O Jprobes é um complemento para o kprobes que permite interceptar convenientemente chamadas de função. Ele extrairá independentemente os argumentos da função dos registradores ou da pilha e chamará o manipulador, que deve ter a mesma assinatura da função conectada. O problema é que os jprobes são preteridos e cortados dos kernels modernos.
- Sobrecarga não trivial. Os pontos de interrupção são caros, mas únicos. Os pontos de interrupção não afetam outras funções, mas seu processamento é relativamente caro. Felizmente, a otimização de salto é implementada para a arquitetura x86_64, o que reduz significativamente o custo dos kprobes, mas ainda permanece mais do que, por exemplo, ao modificar a tabela de chamadas do sistema.
- Limitações de kretprobes. Os Kretprobes são implementados falsificando o endereço de retorno na pilha. Assim, eles precisam armazenar o endereço original em algum lugar para retornar após o processamento do kretprobe. Os endereços são armazenados em um buffer de tamanho fixo. Em caso de estouro, quando muitas chamadas simultâneas da função interceptada são executadas no sistema, o kretprobes pulará as operações.
- Extrusão desativada. Como o kprobes é baseado em registros de processadores de interrupções e malabarismos, para sincronização todos os manipuladores são executados com a preempção desativada. Isso impõe certas restrições aos manipuladores: você não pode esperar neles - aloque muita memória, faça E / S, durma em timers e semáforos e outras coisas conhecidas.
No processo de pesquisa do tópico, nossos olhos se
voltaram para a estrutura
ftrace , que pode substituir os jprobes. Como se viu, funciona melhor para nossas necessidades de interceptação de chamada de função. No entanto, se você precisar rastrear instruções específicas nas funções, o kprobes não deve ser descontado.
Emenda
Por uma questão de completude, também vale a pena descrever o método clássico de interceptar funções, que consiste em substituir as instruções no início da função por uma transição incondicional que leva ao nosso manipulador. As instruções originais são transferidas para outro local e executadas antes de retornar à função interceptada. Com a ajuda de duas transições, incorporamos (unimos) nosso código adicional à função, portanto, essa abordagem é chamada de
emenda .
É assim que a otimização de salto para kprobes é implementada. Usando emendas, você pode obter os mesmos resultados, mas sem custos adicionais para os kprobes e com controle completo da situação.
Os benefícios da emenda são óbvios:
- Requisitos mínimos de kernel. A emenda não requer nenhuma opção especial no kernel e funciona no início de qualquer função. Você só precisa saber o endereço dela.
- Sobrecarga mínima. Duas transições incondicionais - essas são todas as ações que o código interceptado precisa executar para transferir o controle para o manipulador e vice-versa. Tais transições são perfeitamente previstas pelo processador e são muito baratas.
No entanto, a principal desvantagem dessa abordagem obscurece seriamente a imagem:
- Dificuldade técnica. Ela rola. Você não pode simplesmente pegar e reescrever o código da máquina. Aqui está uma lista curta e incompleta de tarefas a serem resolvidas:
- sincronização da instalação e remoção da interceptação (e se a função for chamada diretamente no processo de substituição de suas instruções?)
- desvio de proteção na modificação de regiões de memória com um código
- Invalidação do cache da CPU após a substituição das instruções
- desmontar instruções substituíveis para copiá-las inteiras
- verificação da ausência de transições dentro da peça substituída
- verifique a capacidade de mover a peça substituída para outro local
Sim, você pode espionar kprobes e usar a estrutura intranuclear do livepatch, mas a solução final ainda é bastante complicada. É assustador imaginar quantos problemas de sono haverá em cada nova implementação.
Em geral, se você é capaz de chamar esse demônio, subordinado apenas aos iniciados, e está pronto para suportá-lo em seu código, o splicing é uma abordagem totalmente funcional para interceptar chamadas de função. Tive uma atitude negativa ao escrever bicicletas; portanto, essa opção permaneceu um backup para nós, caso não houvesse progresso algum com soluções prontas mais fáceis.
Nova abordagem com ftrace
O Ftrace é uma estrutura de rastreamento de kernel no nível da função. Foi desenvolvido desde 2008 e possui uma interface fantástica para programas de usuários. O Ftrace permite rastrear a frequência e a duração das chamadas de funções, exibir gráficos de chamadas, filtrar funções de interesse por modelo e assim por diante. Você pode começar a ler sobre os recursos
do ftrace a
partir daqui e seguir os links e a documentação oficial.
Ele implementa o ftrace com base nas teclas do compilador
-pg e
-mfentry , que inserem a chamada na função de rastreamento especial mcount () ou __fentry __ () no início de cada função. Normalmente, nos programas do usuário, esse recurso do compilador é usado pelos criadores de perfil para rastrear chamadas para todas as funções. O kernel usa essas funções para implementar a estrutura ftrace.
É claro que chamar ftrace de
cada função não é barato; portanto, a otimização está disponível para arquiteturas populares:
ftrace dinâmico . A conclusão é que o kernel conhece a localização de todas as chamadas para mcount () ou __fentry __ () e, nos estágios iniciais do carregamento, substitui o código da máquina por
nop - uma instrução especial que não faz nada. Quando o rastreamento é incluído nas funções necessárias, as chamadas ftrace são adicionadas novamente. Portanto, se o ftrace não for usado, seu impacto no sistema será mínimo.
Descrição das funções necessárias
Cada função interceptada pode ser descrita pela seguinte estrutura:
struct ftrace_hook { const char *name; void *function; void *original; unsigned long address; struct ftrace_ops ops; };
O usuário precisa preencher apenas os três primeiros campos: nome, função e original. Os campos restantes são considerados um detalhe de implementação. A descrição de todas as funções interceptadas pode ser montada em uma matriz e as macros podem ser usadas para aumentar a compactação do código:
#define HOOK(_name, _function, _original) \ { \ .name = (_name), \ .function = (_function), \ .original = (_original), \ } static struct ftrace_hook hooked_functions[] = { HOOK("sys_clone", fh_sys_clone, &real_sys_clone), HOOK("sys_execve", fh_sys_execve, &real_sys_execve), };
Wrappers sobre funções interceptadas são os seguintes:
static asmlinkage long (*real_sys_execve)(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp); static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
Como você pode ver, funções interceptadas com um mínimo de código extra. A única coisa que requer atenção cuidadosa são as assinaturas de função. Eles devem corresponder um a um. Sem isso, obviamente, os argumentos serão passados incorretamente e tudo ficará ladeira abaixo. Para interceptar chamadas do sistema, isso é menos importante, porque seus manipuladores são muito estáveis e, por eficiência, recebem argumentos na mesma ordem que o sistema chama a si próprio. No entanto, se você planeja interceptar outras funções, lembre-se de que
não há interfaces estáveis dentro do kernel .
Inicialização Ftrace
Primeiro, precisamos encontrar e salvar o endereço da função que iremos interceptar. O Ftrace permite rastrear funções pelo nome, mas ainda precisamos saber o endereço da função original para chamá-la.
Você pode obter o endereço usando
kallsyms - uma lista de todos os caracteres no kernel. Esta lista inclui
todos os caracteres, não apenas exportados para os módulos. Obter o endereço da função viciada é algo como isto:
static int resolve_hook_address(struct ftrace_hook *hook) { hook->address = kallsyms_lookup_name(hook->name); if (!hook->address) { pr_debug("unresolved symbol: %s\n", hook->name); return -ENOENT; } *((unsigned long*) hook->original) = hook->address; return 0; }
Em seguida, você precisa inicializar a estrutura
ftrace_ops . É obrigatório
o campo é apenas
func , indicando um retorno de chamada, mas também precisamos
defina algumas sinalizações importantes:
int fh_install_hook(struct ftrace_hook *hook) { int err; err = resolve_hook_address(hook); if (err) return err; hook->ops.func = fh_ftrace_thunk; hook->ops.flags = FTRACE_OPS_FL_SAVE_REGS | FTRACE_OPS_FL_IPMODIFY; }
fh_ftrace_thunk () é o nosso retorno de chamada que o ftrace chamará ao rastrear uma função. Sobre ele mais tarde. As bandeiras que definimos serão necessárias para concluir a interceptação. Eles instruem o ftrace a salvar e restaurar os registros do processador, cujo conteúdo podemos alterar no retorno de chamada.
Agora estamos prontos para ativar a interceptação. Para fazer isso, primeiro você deve habilitar o ftrace para a função de interesse usando ftrace_set_filter_ip () e, em seguida, permitir que o ftrace chame nosso retorno de chamada usando register_ftrace_function ():
int fh_install_hook(struct ftrace_hook *hook) { err = ftrace_set_filter_ip(&hook->ops, hook->address, 0, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); return err; } err = register_ftrace_function(&hook->ops); if (err) { pr_debug("register_ftrace_function() failed: %d\n", err); ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); return err; } return 0; }
A interceptação é desativada da mesma forma, apenas na ordem inversa:
void fh_remove_hook(struct ftrace_hook *hook) { int err; err = unregister_ftrace_function(&hook->ops); if (err) { pr_debug("unregister_ftrace_function() failed: %d\n", err); } err = ftrace_set_filter_ip(&hook->ops, hook->address, 1, 0); if (err) { pr_debug("ftrace_set_filter_ip() failed: %d\n", err); } }
Após a chamada para unregister_ftrace_function (), a ausência de ativações do retorno de chamada instalado no sistema (e com ele nossos wrappers) é garantida. Portanto, podemos, por exemplo, descarregar calmamente o módulo interceptador, sem medo de que em algum lugar do sistema nossas funções ainda estejam sendo executadas (porque, se desaparecerem, o processador ficará chateado).
Executando um gancho de função
Como a interceptação é realmente realizada? Muito simples O Ftrace permite alterar o estado dos registros após a saída de um retorno de chamada. Alterando o registro% rip - um ponteiro para a próxima instrução executável - alteramos as instruções que o processador executa - ou seja, podemos forçá-lo a executar uma transição incondicional da função atual para a nossa. Assim, assumimos o controle.
O retorno de chamada para ftrace é o seguinte:
static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); regs->ip = (unsigned long) hook->function; }
Usando a macro container_of (), obtemos o endereço da nossa
struct ftrace_hook no endereço da
struct ftrace_hook incorporada nela, após o que substituímos o valor do registro% rip na
struct pt_regs pelo endereço do nosso manipulador. Só isso. Para arquiteturas diferentes de x86_64, esse registro pode ser chamado de maneira diferente (como IP ou PC), mas a ideia é em princípio aplicável a elas.
Observe o
qualificador notrace adicionado ao retorno de chamada. Eles podem sinalizar recursos que não podem ser rastreados usando o ftrace. Por exemplo, é assim que as funções do ftrace em si envolvidas no processo de rastreamento são marcadas. Isso ajuda a impedir que o sistema congele em um loop infinito ao rastrear todas as funções no kernel (o ftrace pode fazer isso).
O retorno de chamada ftback normalmente chama com a extrusão desativada (como kprobes). Pode haver exceções, mas você não deve confiar nelas. No nosso caso, no entanto, essa restrição não é importante; portanto, apenas substituímos oito bytes na estrutura.
A função de wrapper, chamada posteriormente, será executada no mesmo contexto que a função original. Portanto, você pode fazer o que é permitido fazer na função interceptada. Por exemplo, se você interceptar um manipulador de interrupções, ainda não conseguirá dormir em um invólucro.
Proteção de chamadas recursivas
Existe um problema no código acima: quando nosso invólucro chama a função original, ele entra novamente no ftrace, que novamente chama nosso retorno de chamada, que transfere novamente o controle para o invólucro. Essa recursão infinita precisa ser interrompida de alguma forma.A maneira mais elegante que nos ocorreu é usar parent_ipum dos argumentos do retorno de chamada ftrace, que contém o endereço de retorno para a função que chamou a função rastreada. Normalmente esse argumento é usado para construir um gráfico de chamadas de função. Podemos usá-lo para distinguir a primeira chamada da função interceptada da repetida.De fato, ao chamar novamenteparent_ipdeve apontar para dentro do nosso invólucro, enquanto estiver no primeiro lugar - em outro lugar do kernel. O controle deve ser transferido apenas quando a função é chamada pela primeira vez, todos os outros devem ter permissão para executar a função original.A verificação de entrada pode ser realizada com muita eficiência, comparando o endereço com as bordas do módulo atual (que contém todas as nossas funções). Isso funciona muito bem se no módulo apenas o wrapper chama a função interceptada. Caso contrário, você precisará ser mais seletivo.No total, o retorno de chamada ftrace correto é o seguinte: static void notrace fh_ftrace_thunk(unsigned long ip, unsigned long parent_ip, struct ftrace_ops *ops, struct pt_regs *regs) { struct ftrace_hook *hook = container_of(ops, struct ftrace_hook, ops); if (!within_module(parent_ip, THIS_MODULE)) regs->ip = (unsigned long) hook->function; }
Características / vantagens distintas dessa abordagem:- Baixa sobrecarga. Apenas algumas subtrações e comparações. Sem spinlocks, passes de lista e assim por diante.
- . . , .
- . kretprobes , ( ). , .
Vejamos um exemplo: você digitou o comando ls no terminal para ver uma lista de arquivos no diretório atual. O shell (digamos Bash) usa um par tradicional de funções fork () + execve () da biblioteca padrão C para iniciar um novo processo . Internamente, essas funções são implementadas pelas chamadas de sistema clone () e execve (), respectivamente. Suponha que interceptemos a chamada do sistema execve () para controlar o início de novos processos.Em forma gráfica, a interceptação da função manipuladora se parece com a seguinte: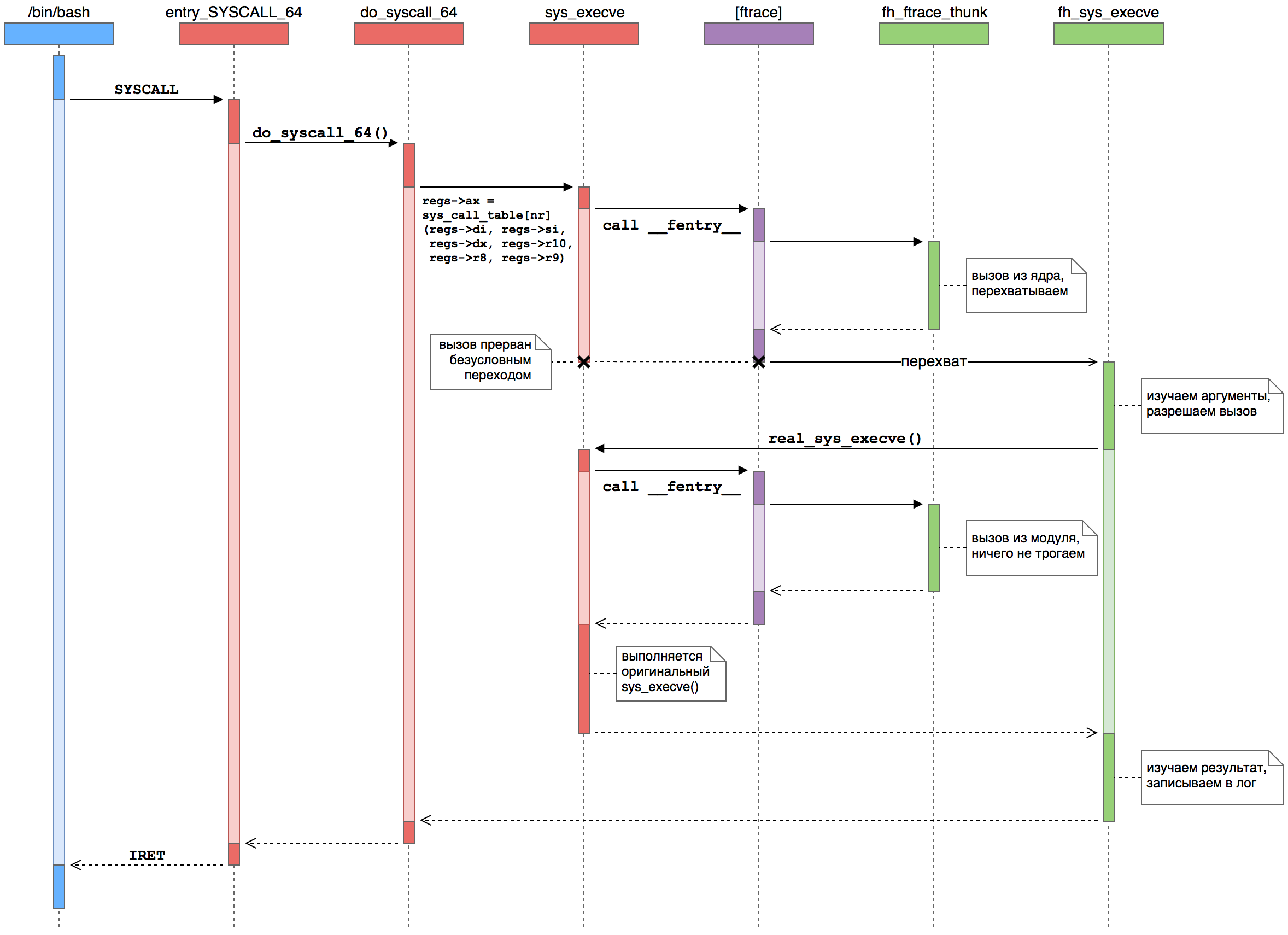 Aqui vemos como o processo do usuário ( azul ) faz uma chamada do sistema para o kernel ( vermelho), onde a estrutura ftrace ( roxa ) chama funções do nosso módulo ( verde ).
Aqui vemos como o processo do usuário ( azul ) faz uma chamada do sistema para o kernel ( vermelho), onde a estrutura ftrace ( roxa ) chama funções do nosso módulo ( verde ).- O processo do usuário executa SYSCALL. Usando esta instrução, o modo do kernel é transferido e o controle é transferido para o manipulador de chamadas de nível inferior do sistema - entry_SYSCALL_64 (). Ele é responsável por todas as chamadas de sistema de programas de 64 bits em kernels de 64 bits.
- . , , do_syscall_64 (), .
sys_call_table — sys_execve ().
- ftrace. __fentry__ (), ftrace. , , nop , sys_execve() .
- Ftrace . ftrace , . , %rip, .
- .
parent_ip , do_syscall_64() — sys_execve() — , %rip pt_regs .
- Ftrace . FTRACE_SAVE_REGS, ftrace
pt_regs . ftrace . %rip — — .
- -. - sys_execve() . fh_sys_execve (). , do_syscall_64().
- . . fh_sys_execve() ( ) . . — sys_execve() , real_sys_execve , .
- . sys_execve(), ftrace . , -…
- . sys_execve() fh_sys_execve(), do_syscall_64(). sys_execve() . : ftrace sys_execve() .
- . sys_execve() fh_sys_execve(). . , execve() , , , . .
- A gerência retorna ao núcleo. Finalmente, fh_sys_execve () termina e o controle passa para do_syscall_64 (), que assume que a chamada do sistema foi concluída como de costume. O núcleo continua seus negócios nucleares.
- O gerenciamento retorna ao processo do usuário. Finalmente, o kernel executa a instrução IRET (ou SYSRET, mas para execve () é sempre IRET), configurando registros para o novo processo do usuário e colocando o processador central no modo de execução do código do usuário. A chamada do sistema (e iniciando um novo processo) está concluída.
Vantagens e desvantagens
Como resultado, temos uma maneira muito conveniente de interceptar quaisquer funções no kernel, que possui as seguintes vantagens:- API . . , , . — -, .
- . . - , , , - . ( ), .
- A interceptação é compatível com o rastreamento. Obviamente, esse método não entra em conflito com o ftrace, portanto você ainda pode obter indicadores de desempenho muito úteis do kernel. O uso de kprobes ou splicing pode interferir nos mecanismos ftrace.
Quais são as desvantagens desta solução?- Requisitos de configuração do kernel. Para executar com êxito ganchos de função usando o ftrace, o kernel deve fornecer vários recursos:
- lista de caracteres de kallsyms para procurar funções por nome
- estrutura ftrace em geral para rastreamento
- opções de interceptação crítica do ftrace
. , , , , . , - , .
- ftrace , kprobes ( ftrace ), , , . , ftrace — , «» ftrace .
- . , . , , ftrace . , , .
- Chamada dupla ftrace. A abordagem de análise de ponteiro descrita acima
parent_ipresulta em uma chamada ftrace novamente para funções conectadas. Isso adiciona um pouco de sobrecarga e pode derrubar outros traços que receberão o dobro de chamadas. Essa desvantagem pode ser evitada aplicando um pouco de magia negra: a chamada ftrace está localizada no início da função; portanto, se o endereço da função original for movido para a frente em 5 bytes (o comprimento da instrução de chamada), você poderá pular através do ftrace.
Considere algumas das desvantagens em mais detalhes.Requisitos de configuração do kernel
Para iniciantes, o kernel deve suportar ftrace e kallsyms. Para fazer isso, as seguintes opções devem estar ativadas:- CONFIG_FTRACE
- CONFIG_KALLSYMS
Então, o ftrace deve suportar a modificação dinâmica do registro. A opção é responsável por isso.- CONFIG_DYNAMIC_FTRACE_WITH_REGS
Além disso, o kernel usado deve ser baseado na versão 3.19 ou superior para ter acesso ao sinalizador FTRACE_OPS_FL_IPMODIFY. Versões anteriores do kernel também podem substituir o% rip register, mas a partir da 3.19 isso deve ser feito somente após a configuração desse sinalizador. A presença de um sinalizador para kernels antigos levará a um erro de compilação, e sua ausência para novos levará a uma interceptação inativa.Finalmente, para executar a interceptação, a localização da chamada ftrace dentro da função é crítica: a chamada deve estar localizada no início, antes do prólogo da função (onde o espaço é alocado para variáveis locais e um quadro de pilha é formado). Esse recurso de arquitetura é levado em consideração pela opçãoA arquitetura x86_64 suporta essa opção, mas o i386 não. Devido às limitações da arquitetura i386, o compilador não pode inserir uma chamada ftrace antes do prólogo da função; portanto, quando o ftrace é chamado, a pilha de funções já está modificada. Nesse caso, para interceptar, não basta alterar o valor do registro% eip - você também deve reverter todas as ações executadas no prólogo que diferem de função para função.Por esse motivo, a interceptação ftrace não suporta a arquitetura de 32 bits x86. Em princípio, poderia ser implementado usando certas magias negras (gerando e executando um “antiprólogo”), mas a simplicidade técnica da solução sofrerá, o que é uma das vantagens do uso do ftrace.Surpresas não óbvias
Durante o teste, deparamos com um recurso interessante : em algumas distribuições, as funções de conexão causavam uma falha no sistema. Naturalmente, isso aconteceu apenas em sistemas diferentes daqueles usados pelos desenvolvedores. O problema também não se reproduziu no protótipo original de interceptação, com nenhuma distribuição e versão do kernel.A depuração mostrou que o travamento ocorre dentro da função interceptada. Por alguma razão mística, quando a função original foi chamada dentro do retorno de chamada ftrace, o endereço parent_ipcontinuou sendo especificado no código do kernel, em vez do código da função do wrapper. Por isso, surgiu um loop sem fim, já que o ftrace chamava nosso invólucro repetidas vezes sem executar nenhuma ação útil.Felizmente, tínhamos código de trabalho e código quebrado à nossa disposição, portanto, encontrar as diferenças era apenas uma questão de tempo. Depois de unificar o código e jogar fora tudo o que é desnecessário, as diferenças entre as versões foram localizadas em uma função de wrapper.Esta opção funcionou: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_debug("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_debug("execve() returns: %ld\n", ret); return ret; }
mas este - desligou o sistema: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { long ret; pr_devel("execve() called: filename=%p argv=%p envp=%p\n", filename, argv, envp); ret = real_sys_execve(filename, argv, envp); pr_devel("execve() returns: %ld\n", ret); return ret; }
Como é que o nível de registro afeta o comportamento? Um estudo cuidadoso do código de máquina das duas funções rapidamente esclareceu a situação e causou a mesma sensação de culpa do compilador. Geralmente ele está na lista de suspeitos em algum lugar perto dos raios cósmicos, mas não desta vez.O fato é que as chamadas para pr_devel () são expandidas para o vazio. Esta versão da macro printk é usada para registro durante o desenvolvimento. Essas entradas de log não são interessantes durante a operação; portanto, elas são cortadas automaticamente do código se a macro DEBUG não for declarada. Depois disso, a função do compilador se transforma assim: static asmlinkage long fh_sys_execve(const char __user *filename, const char __user *const __user *argv, const char __user *const __user *envp) { return real_sys_execve(filename, argv, envp); }
E aqui a otimização entra em cena. Neste caso, ele trabalhou chamados chamadas cauda de otimização (cauda chamada de otimização). Ele permite que o compilador substitua uma chamada de função honesta por um salto direto em seu corpo se uma função chamar outra e retornar imediatamente seu valor. No código de máquina, uma chamada honesta é assim: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: ff 15 00 00 00 00 callq *0x0(%rip) b: f3 c3 repz retq
e não trabalhando - assim: 0000000000000000 <fh_sys_execve>: 0: e8 00 00 00 00 callq 5 <fh_sys_execve+0x5> 5: 48 8b 05 00 00 00 00 mov 0x0(%rip),%rax c: ff e0 jmpq *%rax
A primeira instrução CALL é a mesma chamada __fentry __ () inserida pelo compilador no início de todas as funções. Porém, no código normal, você pode ver a chamada para real_sys_execve (pelo ponteiro na memória) através da instrução CALL e retornar de fh_sys_execve () usando a instrução RET. O código quebrado vai diretamente para a função real_sys_execve () usando o JMP.A otimização de chamadas finais permite economizar um pouco de tempo na formação de um quadro de pilha "sem sentido", que inclui o endereço de retorno armazenado na pilha pela instrução CALL. No entanto, para nós, a correção do endereço de retorno desempenha um papel crítico - nós o usamos parent_ippara tomar uma decisão sobre interceptação. Após a otimização, a função fh_sys_execve () não salva mais o novo endereço de retorno na pilha, permanece o antigo - apontando para o kernel. Portanto,parent_ipcontinua a apontar para dentro do núcleo, o que leva à formação de um loop infinito.Isso também explica por que o problema só foi reproduzido em algumas distribuições. Ao compilar módulos, distribuições diferentes usam conjuntos diferentes de sinalizadores de compilação. Nas distribuições em dificuldades, a otimização da chamada de cauda foi ativada por padrão.A solução para o problema foi desativar a otimização da chamada de cauda para todo o arquivo com funções de wrapper: #pragma GCC optimize("-fno-optimize-sibling-calls")
Conclusão
O que mais posso dizer ... É divertido desenvolver código de baixo nível para o kernel do Linux. Espero que esta publicação poupe a alguém um pouco de agonia, o que usar para escrever o seu melhor antivírus no mundo.Se você quiser experimentar a interceptação, o código completo do módulo do kernel pode ser encontrado no Github .