Olá, nome de usuário! Todos os dias nos deparamos com uma pesquisa por vários dados. Quase todos os sites com muita informação agora têm uma pesquisa. A pesquisa está em computadores domésticos, em telefones celulares, em vários tipos de software. Obviamente, se você perguntar a qualquer desenvolvedor sobre a pesquisa em termos de tecnologia, pesquisa elástica, lucene ou esfinge será lembrada imediatamente. Hoje, quero olhar para você "sob o capô" de uma pesquisa de texto completo e descobrir uma primeira aproximação de como funciona, usando o exemplo de hh.ru.
 Isenção de responsabilidade: este artigo não é o único ponto de vista verdadeiro e serve apenas como um ponto introdutório para uma familiarização inicial com o trabalho de pesquisa de texto e algumas opções para implementar suas partes individuais.
Isenção de responsabilidade: este artigo não é o único ponto de vista verdadeiro e serve apenas como um ponto introdutório para uma familiarização inicial com o trabalho de pesquisa de texto e algumas opções para implementar suas partes individuais.Se você observar os detalhes da pesquisa, além da parte óbvia na forma de uma sequência de pesquisa, poderá ver muito mais:
- dica (ela sugere)
- contador de resultados de pesquisa (contador),
- vários tipos de classificação (classificação),
- facetas - características agrupadas dos documentos, por exemplo, o metrô em que a vaga está localizada, desempenhando também a função de filtros (filtros),
- sinónimos
- paginação
- snippet (snippet) - uma pequena descrição do documento na emissão,
- etc.

E tudo isso serve a um propósito - satisfazer a necessidade do usuário de encontrar as informações corretas o mais rápido e relevante possível. Por exemplo, a filtragem é importante para restringir os resultados da pesquisa; no nosso caso, pode ser um filtro por experiência, local ou emprego do candidato. As facetas são úteis para exibir quantas vagas existem em cada faixa salarial. Também é importante complementar as consultas e os documentos com sinônimos para que, a pedido do "desenvolvedor java", eles possam encontrar documentos "desenvolvedor java".
Além da pesquisa em si, sempre existem muitos componentes que facilitam a vida do usuário: um tutor responsável por corrigir erros ou um sajest que solicita consultas mais adequadas quando você interage com a barra de pesquisa. Em alguns casos, é importante poder reformular a solicitação. Por exemplo, mova uma parte da solicitação para filtros: da solicitação "Moscow programmer" Moscou pode ser removida para o filtro por cidade.
1. Básico
Agora ao ponto. A pesquisa em si é dividida em dois grandes estágios:
- indexação (processamento de documentos e disposição de acordo com estruturas de índice especiais, para que você possa executar rapidamente a própria pesquisa),
- pesquisa (aplicação de filtros, pesquisa booleana, classificação etc.).
1.1 Indexação
Uma ligeira digressão lírica. Além disso, apresentarei o conceito de termo - como é habitual chamar a unidade mínima de indexação e consulta. Esta é a mesma unidade que será armazenada no dicionário de índice. Pode ser uma palavra reduzida à sua forma normal de palavra ou base, número, email, letra n-gramas ou qualquer outra coisa. Normalmente, um termo inclui um campo no qual é indexado ou no qual uma pesquisa é realizada.
Primeiro, você precisa transformar os documentos de entrada em um conjunto de termos e filtrar as palavras de parada. Elas podem ser como palavras que ocorrem com frequência - preposições, conjunções, interjeições e outras coisas, por exemplo, caracteres especiais que não queremos pesquisar. Para que a pesquisa funcione com diferentes formas de palavras, durante o processo de indexação, geralmente trazemos todas as palavras para algum estado básico. Geralmente, um dos dois procedimentos é usado: derivação - o processo de isolar a base de uma palavra (desenvolvimento-> desenvolvimento) ou lematização - o processo de trazer uma palavra à forma normal (habilidades-> habilidade).
1.2 Estruturas de Índice
A maneira mais popular de representar um índice é um índice invertido. De fato, essa é uma espécie de tabela de hash, em que a chave é um termo e o valor é uma lista de documentos (geralmente uma lista de identificação de documento chamada lista de lançamentos) na qual esse termo está presente. Normalmente, um índice invertido consiste em duas partes - um dicionário (dicionário de termos) e listas de documentos para cada termo (lista de postagem):

Além disso, o índice pode conter informações sobre as posições dos termos no documento (índice de posição), o que será útil ao procurar termos a uma certa distância, em particular com consultas frasais, sobre a frequência dos termos, o que ajudará na classificação e construção de um plano de consulta. Mas mais sobre isso abaixo.
1.2.1 Dicionário de termos
O dicionário armazena todos os termos existentes no índice e foi projetado para encontrar rapidamente links para uma lista de documentos. Existem várias opções para armazenar um dicionário:
- Uma tabela de hash, em que o termo é a chave e o valor é um link para uma lista de documentos desse termo.
- Uma lista ordenada pela qual você pode pesquisar por pesquisa binária.
- Árvore de prefixos (trie).
A melhor maneira é a última opção, porque Tem várias vantagens. Primeiro, em um grande número de termos, a árvore de prefixos ocupará muito menos memória, porque as partes repetidas dos prefixos serão armazenadas apenas uma vez. Em segundo lugar, imediatamente temos a oportunidade de fazer solicitações de prefixo. E em terceiro lugar, essa árvore pode ser compactada combinando partes não ramificadas.
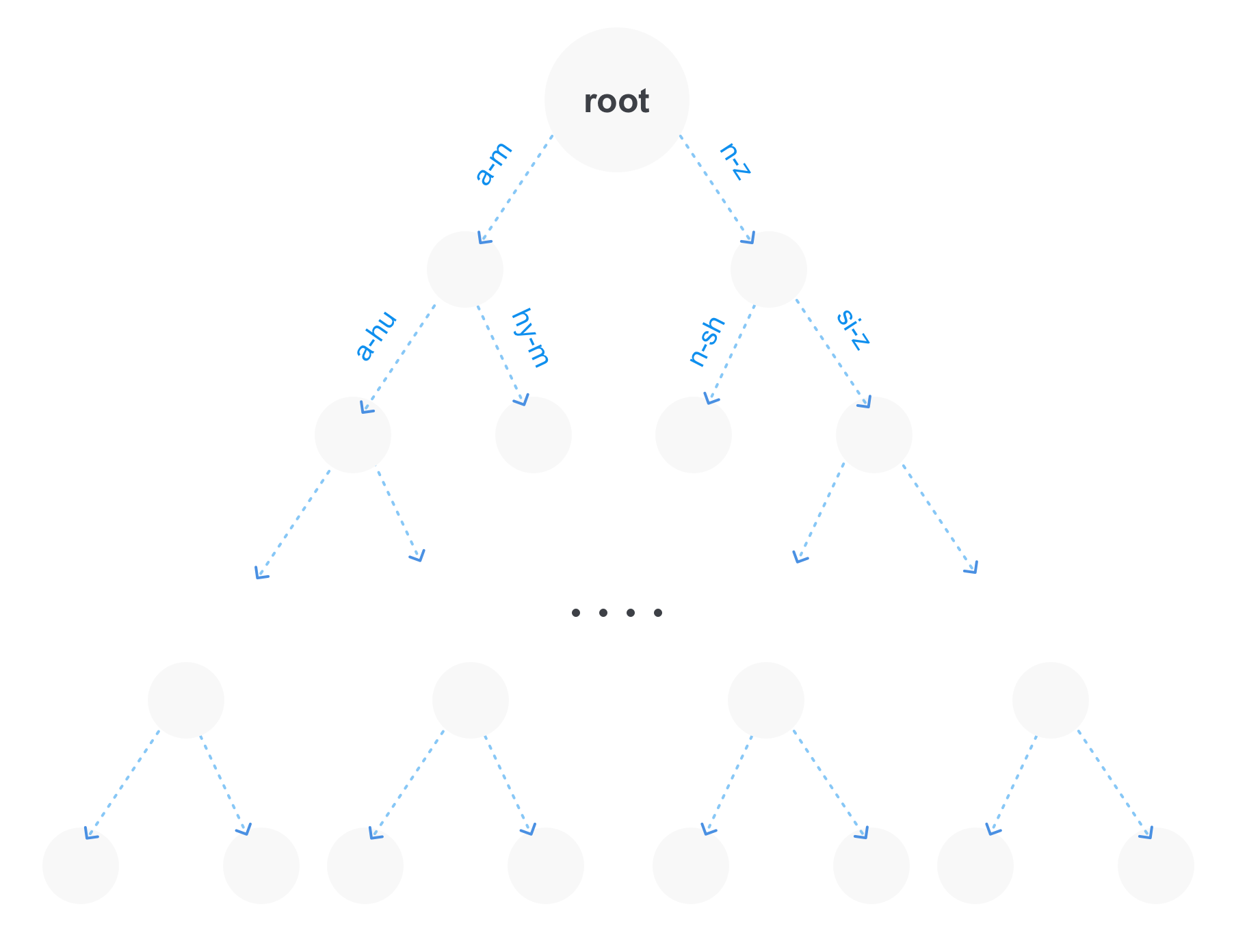
Obviamente, uma árvore de prefixos pode não ser a única estrutura para armazenar termos em um índice. Por exemplo, uma árvore de sufixos também pode estar próxima, o que, por sua vez, será mais ideal para consultas com curingas (consultas no formato po * sql).
1.2.2 Lista de lançamentos
A lista de documentos é uma lista ordenada de identificadores de documentos, que permite que algumas otimizações sejam feitas com ele. Normalmente, ele armazena em si não apenas uma lista de documentos em que o termo ocorre, mas também as posições (lançamentos) em que ocorre. Isso resolve vários problemas ao mesmo tempo: sabemos imediatamente quantas vezes uma palavra ocorre em um documento, podemos fazer frases e consultas com uma certa distância entre termos, cruzando várias listas de documentos de uma só vez e observando as posições dos termos.

Por exemplo, nesta lista pelo termo
scala no sexto documento do
título, a palavra ocorre 4 vezes, nas posições 2, 15, 18 e 25.
1.2.3 Documentos com vários campos
A maior parte do documento consiste em vários campos, pelo menos no nome do documento e seu corpo. Isso ajuda na pesquisa de partes individuais do documento e quando o termo é significativo na classificação (por exemplo, o termo que ocorre no título pode ser considerado mais significativo).
Além disso, no índice, geralmente não apenas os campos de texto são armazenados, mas também podem ser armazenados sinais de documentos, alguns valores numéricos etc. O armazenamento no índice geralmente assume a forma de {field-term}.

Por exemplo, se você tirar uma vaga, ela terá vários campos ao mesmo tempo: nome, descrição, empresa, folha de pagamento, cidade e a experiência necessária. Isso é necessário para que o usuário possa pesquisar convenientemente não apenas o nome e o texto da empresa, mas também possa filtrar por salário e experiência, ver quantas vagas existem na cidade e nas cidades vizinhas ou até procurar vagas para uma determinada empresa.
1.3 Compactação e otimização de índice
A velocidade do trabalho é importante para a pesquisa; portanto, a maioria das operações de pesquisa de índice geralmente é realizada na RAM. Para fazer isso, é muito importante aplicar uma série de otimizações ao índice, que o ajustará a um tamanho de memória limitado. Além disso, geralmente são aplicadas várias otimizações, que permitem que você mova o índice a uma velocidade mais alta ao pesquisar, ignorando partes desnecessárias.
1.3.1 Compressão Delta
Como lembramos que a lista de documentos por termo (também conhecida como lista de postagens) está ordenada, a primeira idéia de como compactá-la é fazer uma lista com os deslocamentos de identificação dos documentos em vez da lista com documentos de identificação. Em uma lista específica de 6 identificadores, será assim:

Assim, percorrendo a lista, sempre calcularemos o identificador atual a partir do valor anterior obtido. Por exemplo, ao segundo deslocamento 3, adicionamos o primeiro valor 2 e obtemos o id 5, ao terceiro 4 adicionamos 5 e obtemos 9 e assim por diante. Com um grande número de documentos, isso funciona muito bem, especialmente em conjunto com outro método de compactação - gravação de números de formato variável.
1.3.2 VarByte e VarInt
Essa é uma maneira de armazenar cada item da lista individual na memória, de modo a ocupar a quantidade mínima de espaço. Por exemplo, se os três primeiros deslocamentos caberem em apenas 1 byte, não será necessário mais. Considerando que nossa lista não contém documentos de identificação, mas deltas, a compactação será muito eficaz. Nesta representação de números, o primeiro bit de cada byte é o sinalizador se a representação do número atual termina nesse byte.

Se o primeiro bit do byte 0 for o último byte do número, se 1 não for.
1.3.3 Pular lista / pular tabela
Uma lista de ignorados é uma das estruturas para mover rapidamente uma lista de documentos de um determinado termo, ignorando uma parte desnecessária da lista. A idéia é armazenar links para elementos distantes da lista no disco em frente à própria lista, porque após a compactação não podemos dizer onde exatamente o documento 100 ou 200 estará localizado. Por exemplo, isso é conveniente quando há uma consulta de dois termos, onde um termo será encontrado com frequência e o segundo, pelo contrário, será raro, e a lista de documentos começará apenas com o 200º ID do documento. Então, se houver uma lista com passes para a primeira lista, podemos economizar tempo em mover e pular imediatamente o bloco desnecessário de identificadores.

1.4 Pedidos
1.4.0 Consulta de termos
O tipo mais simples de solicitação em que precisamos encontrar a lista apropriada de documentos e emitir documentos classificados após a classificação.
Por exemplo, desta maneira, encontramos uma lista de posições para
java :

1.4.1 Consultas booleanas (e, ou, não)
A pesquisa booleana é uma das partes mais importantes na recuperação de informações que encontramos em todos os lugares. Toda a pesquisa booleana é baseada em uma combinação de AND, OR e NOT. Por exemplo, quando procuramos uma consulta em duas palavras:
java android , na verdade, em uma pesquisa simples, ela será convertida em
java AND android . E isso significa que queremos encontrar todos os documentos que contêm as duas palavras.
Vale mencionar imediatamente como você se move pela lista de documentos. Como as listas de documentos para cada termo são classificadas, geralmente há duas maneiras de percorrer as listas: percorrer os documentos sequencialmente, passando-os um por um ou movendo-os diretamente para um documento específico, ignorando aqueles que não são necessários (por exemplo, quando a primeira lista é muito menor , e não precisamos passar por um grande bloco de documentos na segunda lista). Nesse caso, primeiro usamos o ponteiro de pular ponteiros para a segunda lista para mover o mais próximo possível do ID do documento desejado e, em seguida, linearmente.
No momento da pesquisa, acontece o seguinte: no índice dos termos java e android são listas de documentos, é feita uma interseção neles - ou seja, encontramos documentos que contêm os dois termos. Com esta pesquisa, os dois métodos de percorrer as listas são usados para atravessar mais rapidamente.

Com consultas OR do formulário java OR scala, onde precisamos encontrar todos os documentos que contenham pelo menos um dos termos, a situação é diferente - aqui não precisamos que o termo esteja em todas as listas de documentos de uma só vez. Mas há consultas com vários operadores OR e, em seguida, a condição para um número mínimo de correspondências pode ocorrer, por exemplo, pode haver uma consulta java OR scala OU cotlin OR clojure com pelo menos duas correspondências e, em seguida, devemos mostrar todos os documentos que contenham pelo menos duas palavras da consulta .
Nesse caso, o heap funciona com mais eficiência. Podemos armazenar nele links para iteradores de cada lista e obter o elemento mínimo por tempo constante. Depois de pegar o elemento mínimo, removemos o iterador do heap, avançamos e o adicionamos novamente ao heap. Você pode armazenar separadamente o candidato atual a ser adicionado ao resultado e ao contador, quantas vezes ele se encontrou e, no momento em que o candidato for diferente do elemento mínimo na pilha, veja se passamos pelo número mínimo de correspondências na operação. E adicione à lista final de resultados ou descarte o documento.
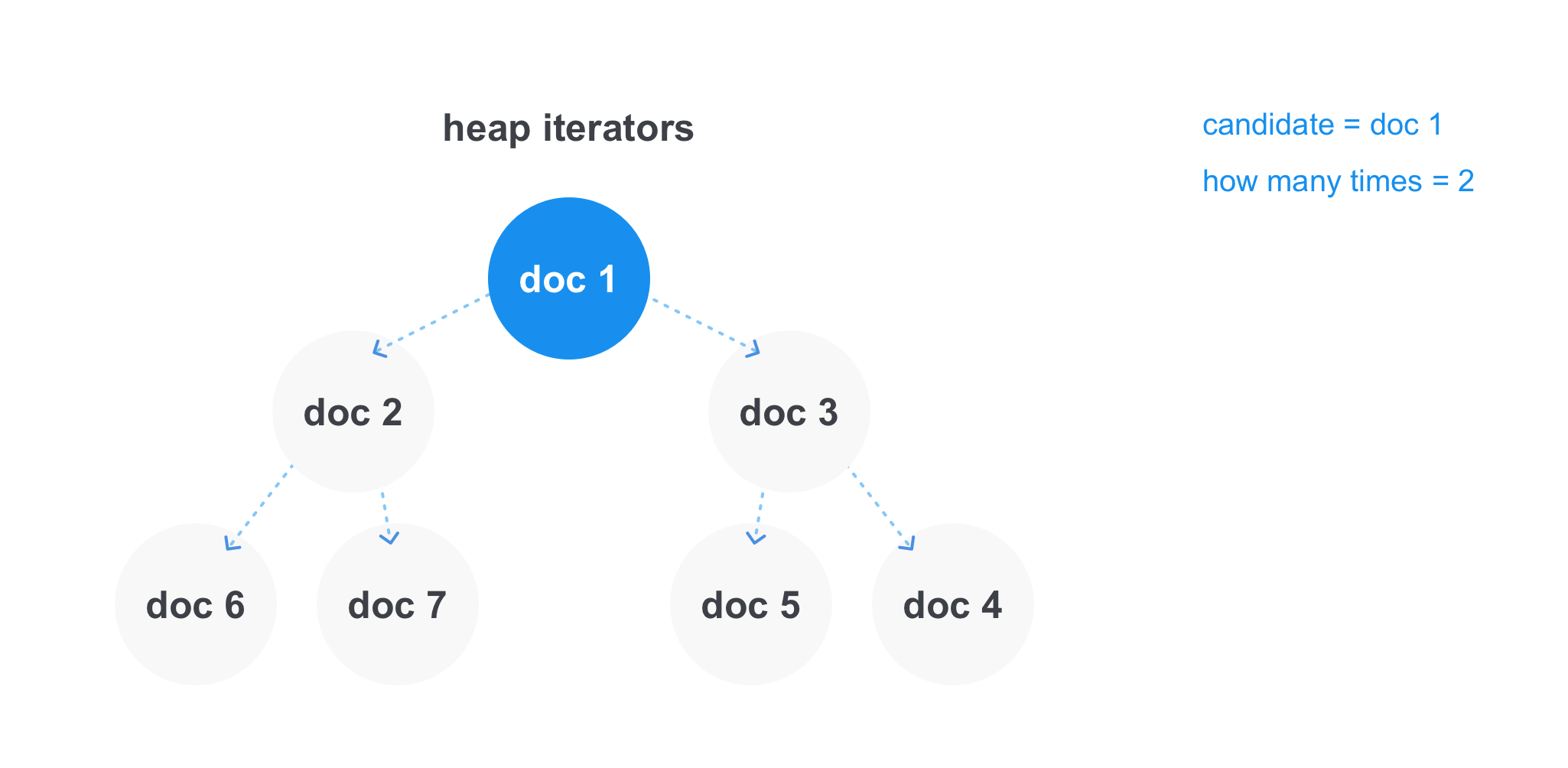
1.4.2 Prefixo / Coringas
Às vezes, queremos encontrar todos os documentos que contenham uma palavra que comece com um prefixo específico. Nesses casos, a solicitação de prefixo nos ajudará, que se parecerá com
jav * . Uma solicitação de prefixo funciona muito bem quando o dicionário é implementado em uma árvore de prefixos, e então chegamos ao aninhamento do prefixo e pegamos todos os termos abaixo.
1.4.3 Consultas sobre frases e consulta próxima
Há momentos em que você precisa encontrar a frase inteira, por exemplo, “desenvolvedor java” ou encontrar palavras entre as quais não haverá mais do que algumas palavras, por exemplo, “java” e “desenvolvedor”, entre as quais não mais que 2 palavras, para que você possa encontrar Documentos que contêm java android kotlin developer. Para isso, são usadas adicionalmente listas de posições de palavras em cada documento.

No momento de cruzar as listas de documentos, tudo é igual à operação AND. Porém, depois que o documento é encontrado nas duas listas, é feita uma verificação adicional - se os termos estão à distância certa um do outro, pela diferença de posição (posição).
1.4.4 Plano de solicitação
Geralmente, antes da execução da própria solicitação, seu plano é construído. Isso acontece para otimizar a execução da solicitação e fazer otimizações como uma lista com omissões para a lista de documentos.
A maneira mais fácil de otimizar sua consulta é cruzar as listas de documentos em ordem crescente de tamanho. Portanto, não desperdiçaremos o desperdício de documentos de grandes listas que não estão em pequenas listas.
Por exemplo, vamos analisar a
consulta android AND java AND sql . Digamos que existem 10 documentos na lista do Android, em sql - 20 e em java - 100. Nesse caso, é melhor cruzar primeiro as listas menores, e a consulta otimizada será semelhante a
(android AND sql) AND java .
No caso de OR, o mais simples é contar o número de documentos na interseção como a soma de duas listas potencialmente interceptadas.
1.4.5 Extensão de consulta - Sinônimos
Além do que o usuário digita na barra de pesquisa, geralmente a pesquisa tenta expandir a consulta para encontrar documentos mais relevantes. Muito pode ser usado para expandir a pesquisa: o histórico de consultas do usuário, alguns dados personalizados sobre ele e muito mais. Mas, além de tudo isso, também existe uma maneira universal de expandir a solicitação - sinônimos.
Nesse caso, ao gravar documentos no índice, o termo é substituído por um "link" no dicionário de sinônimos:
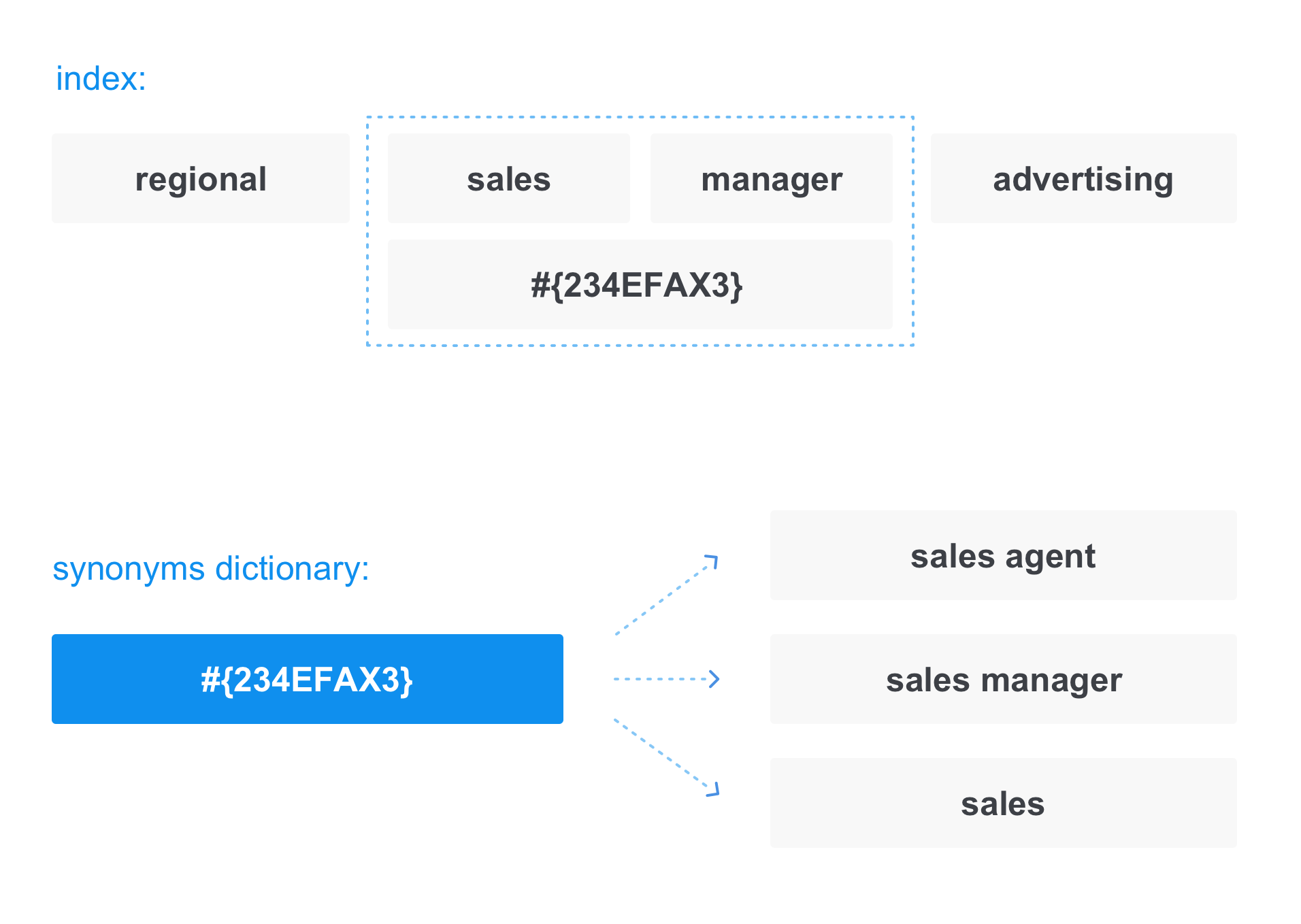
O mesmo acontece ao converter uma solicitação. Por exemplo, quando solicitamos um
gerente de vendas , a solicitação realmente se parece com:

Assim, na resposta, receberemos não apenas os documentos que contêm o gerente de vendas, mas também aqueles que contêm o agente de vendas e as vendas.
1.5 Filtragem
1.5.1 Filtro de alcance rápido
Às vezes, queremos filtrar algo por uma gama de valores, por exemplo, pela experiência em anos. Suponha que desejemos encontrar todas as vagas com a experiência exigida de 3 a 11 anos. A primeira decisão é fazer uma solicitação com todas as opções do intervalo, combinando-as por meio do OR. Mas o problema é que pode haver muitos valores. Uma maneira de resolver esse problema é registrar o valor com várias precisão ao mesmo tempo:

Nesse caso, armazenaremos 5 valores de precisão: um ano (consideraremos isso como o valor inicial), dois, quatro, oito e dezesseis.
Então, ao gravar, ocorrerá o seguinte: por exemplo, ao gravar um documento com um requisito de experiência de 6 anos, registramos o valor imediatamente com toda a precisão:

Ao filtrar "de 3 a 11 anos", acontece o seguinte: selecionamos apenas os valores necessários na precisão necessária, obtemos apenas 3 valores em vez de 8 e obtemos a consulta
(valor real == 3) OR (precisão 4 == 4) OU (precisão 4 == 8)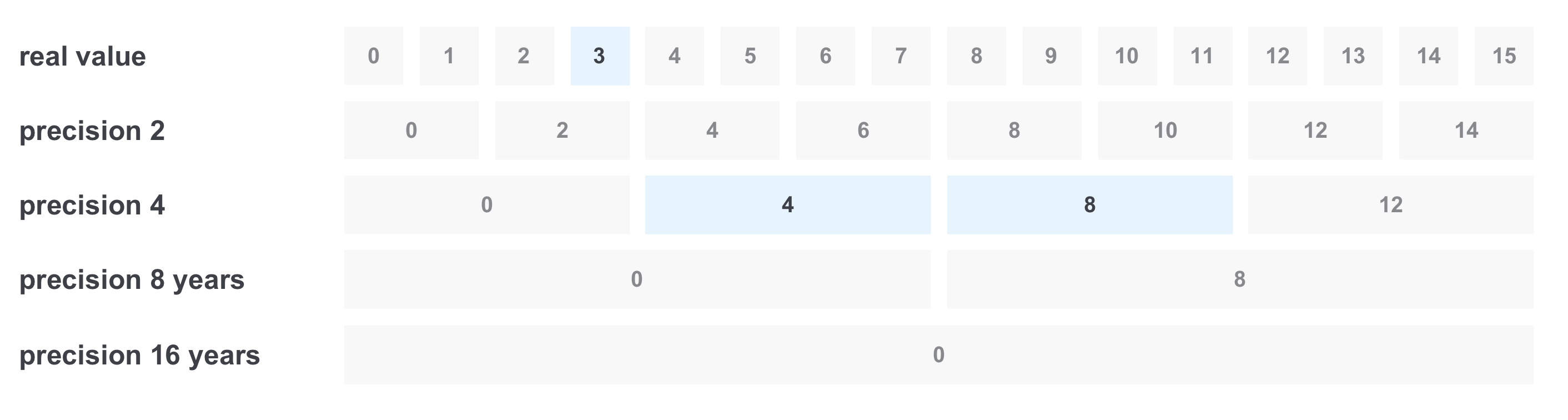
1.5.2 Máscaras de bits
Máscaras de bits são parte integrante de um índice. O uso mais importante é filtrar documentos excluídos. Quando você exclui um documento do índice, a exclusão física não ocorre imediatamente. Uma estrutura especial é gravada ao lado do índice, onde cada bit significa o ID do documento no índice e, quando excluído, um bit é aumentado e, ao pesquisar, esses documentos são filtrados e não caem na saída.
Você também pode usar máscaras de bits para definir permissões para cada usuário para determinados documentos e para armazenar em cache filtros populares individuais. Normalmente, as máscaras de bits são armazenadas separadamente do índice.
Por exemplo, temos filtros populares: a cidade de Moscou, apenas em período parcial, sem experiência profissional. Antes da solicitação, podemos obter as máscaras de bits já salvas para esses documentos, adicioná-las e obter a máscara de bits final - quais documentos passam por todos esses três filtros, economizando tempo na filtragem.

2. Classificação
Como lembramos, a principal tarefa da pesquisa é obter as informações mais relevantes no menor tempo possível. E nisso seremos ajudados pela classificação dos documentos, depois que filtramos os documentos por consulta de texto e aplicamos os filtros e direitos necessários.
A maneira mais fácil e barata de classificar é simplesmente classificar os documentos por data. Em alguns sistemas, isso foi feito anteriormente, por exemplo, nas notícias ou nos anúncios imobiliários, para que o usuário recebesse os documentos mais recentes.
Às vezes, um modelo de classificação pelo número de palavras encontradas em um documento pode ser usado, por exemplo, quando não há tantos documentos, e queremos encontrar todos os documentos nos quais pelo menos uma das palavras de consulta foi encontrada. Nesse caso, os documentos em que todas as palavras da consulta ou mais delas forem encontradas serão mais relevantes.
É claro que, atualmente, esses métodos já se tornaram irrelevantes e podem ser atribuídos mais provavelmente à história do problema.
2.1 TF-IDF
TF-IDF (termo frequência - frequência inversa de documentos) é uma das fórmulas de classificação mais básicas e mais usadas. A essência da fórmula é diminuir os termos usados em todos os lugares, por exemplo, preposições e interjeições, e criar termos mais significativos e raros, mostrando assim os primeiros documentos com termos mais raros e mais significativos da consulta. Agora vamos dividir a fórmula em partes:
TF (termo frequência) é a frequência do termo que ocorre no documento. É calculado simplesmente:
TF term `java` = número de termo` java` no documento / número de todos os termos no documento
IDF (frequência inversa de documentos) - a inversa da frequência com que a palavra ocorre na coleção de documentos. Ajuda a reduzir o peso das palavras mais usadas.
IDF (`java`) = log (número de documentos na coleção / número de documentos em que o termo` java` ocorre)Além disso, para obter o TF-IDF do termo java, basta multiplicar os valores de TF e IDF obtidos. , , . , , developer , , java developer .
2.2
, , . , , , .
2.3 BM25 BM*
BM25 (Okapi best match 25) TF-IDF . BM25F, ( ).
2.4
, :
- DFR (divergence from randomness),
- IBS (information-based models),
- LM Dirichlet,
- Jelinek-Mercer.
2.5
, , . ,
.
2.6 Top k
, . , , .
, .
top k .
— . k, k
* . heap. n*log(n) k.
. , , , 10 12, score 10 score . , n — (n*page size) .
3.
3.1
— . , .
, : , , . , . . ( , ). (merge).
, , :

. , , , - .
3.2 (megre)
— . «» — . , , ( ).

, , , . :
4.
, , . , - (, . .). , , , .

4.1
(, hh , ), . .
, , . -, , . -, , , .
4.2
, . , .
, hh,
, , - :
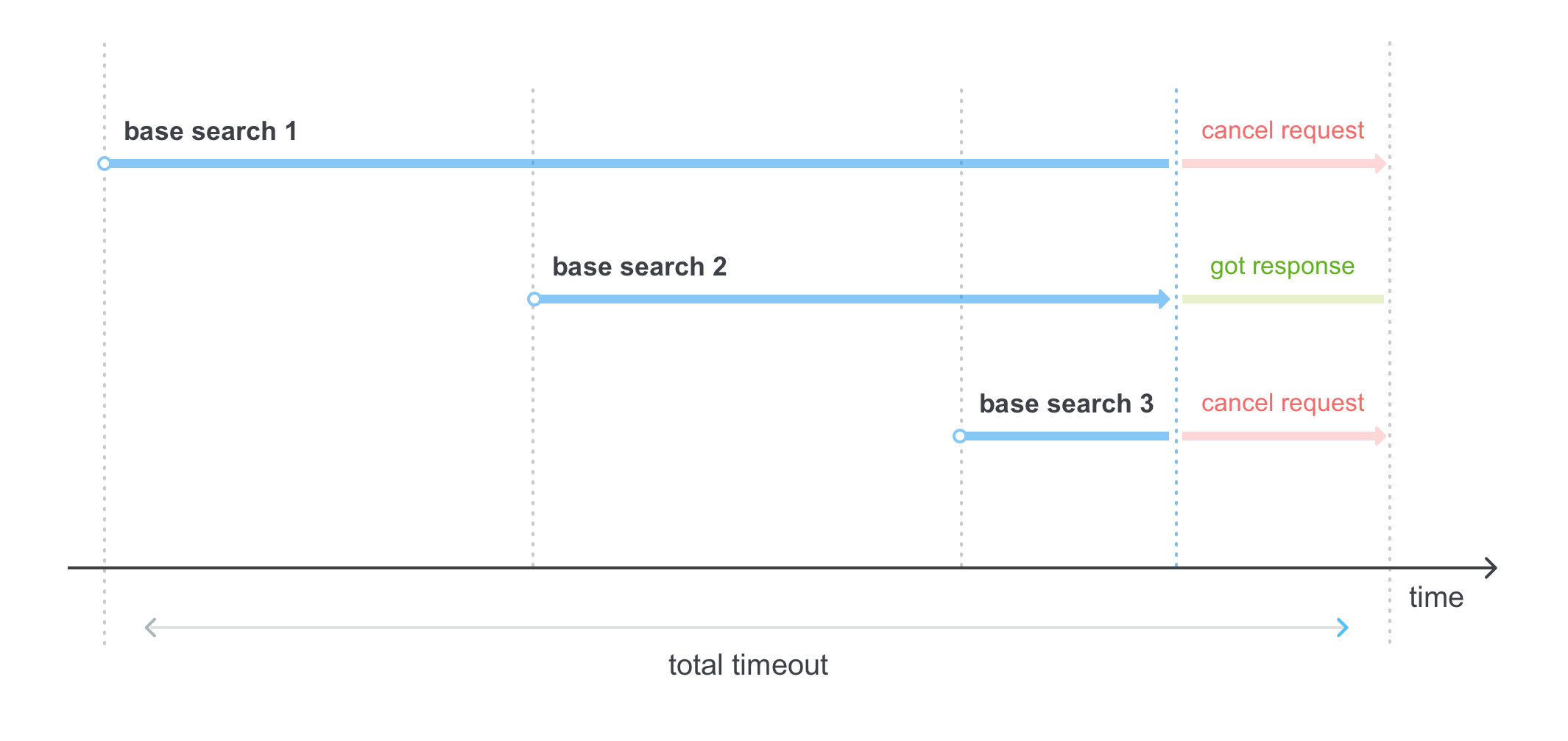
5. …
, , , . , : , , , , , (highlight), . , , , top k .
:
Isso é tudo, obrigado a todos pela atenção, é interessante ouvir seus comentários e perguntas.PS
Gostaria de expressar gratidão a gdanschin por me ajudar a escrever este artigo.