O
sistema anti-plágio é um mecanismo de pesquisa especializado. Como convém a um mecanismo de pesquisa, com seu próprio mecanismo e índices de pesquisa. Nosso maior índice em termos de número de fontes está, é claro, na Internet em russo. Há muito tempo, decidimos colocar neste índice tudo o que é texto (e não uma imagem, música ou vídeo), é escrito em russo, tem um tamanho maior que 1 kb e não é uma “quase duplicata” de algo que já está no índice.
Essa abordagem é boa, pois não requer pré-tratamentos complexos e minimiza os riscos de "espirrar o bebê com água" - pulando um documento do qual o texto pode potencialmente ser emprestado. Por outro lado, como resultado, sabemos pouco quais documentos estão no final das contas.
À medida que o índice da Internet aumenta - e agora, por um segundo, já são mais de 300 milhões de documentos
apenas em russo - surge uma questão completamente natural: existem muitos documentos realmente úteis nesse lixão?
E como nós (
yury_chekhovich e
Andrey_Khazov )
adotamos essa reflexão, por que não respondemos ao mesmo tempo mais algumas perguntas? Quantos documentos científicos são indexados e quantos não científicos? Qual é a parcela de artigos científicos entre diplomas, artigos, resumos? Qual é a distribuição de documentos por assunto?

Como estamos falando de centenas de milhões de documentos, é necessário usar meios de análise automática de dados, em particular a tecnologia de aprendizado de máquina. Obviamente, na maioria dos casos, a qualidade da avaliação de especialistas é superior aos métodos de máquina, mas seria muito caro atrair recursos humanos para resolver uma tarefa tão extensa.
Então, precisamos resolver dois problemas:
- Crie um filtro "científico", que, por um lado, permita descartar automaticamente documentos que não estão em estrutura e conteúdo e, por outro lado, determine o tipo de documento científico. Faça imediatamente uma reserva que, de acordo com o "científico", não se refira de maneira alguma ao significado científico ou à confiabilidade dos resultados. A tarefa do filtro é separar documentos com a forma de artigo científico, dissertação, diploma, etc. de outros tipos de textos, nomeadamente ficção, artigos jornalísticos, notícias, etc.;
- Implemente uma ferramenta para rubricar documentos científicos que relacionem o documento a uma das especialidades científicas (por exemplo, Física e Matemática , Economia , Arquitetura , Estudos Culturais , etc.).
Ao mesmo tempo, precisamos resolver esses problemas trabalhando exclusivamente com o suporte textual de documentos, sem usar seus metadados, informações sobre a localização dos blocos de texto e imagens nos documentos.
Vamos ilustrar com um exemplo. Mesmo um olhar superficial é suficiente para distinguir um
artigo científico
de, por exemplo, um
conto de fadas infantil .

Mas se houver apenas uma camada de texto (para os mesmos exemplos), você deverá ler o conteúdo.
Filtro científico e classificação por tipo
Resolvemos as tarefas sequencialmente:
- Na primeira etapa, filtramos documentos não científicos;
- Na segunda etapa, todos os documentos identificados como científicos são classificados por tipo: artigo, dissertação de candidato, resumo de doutorado, diploma, etc.
Parece algo como isto:
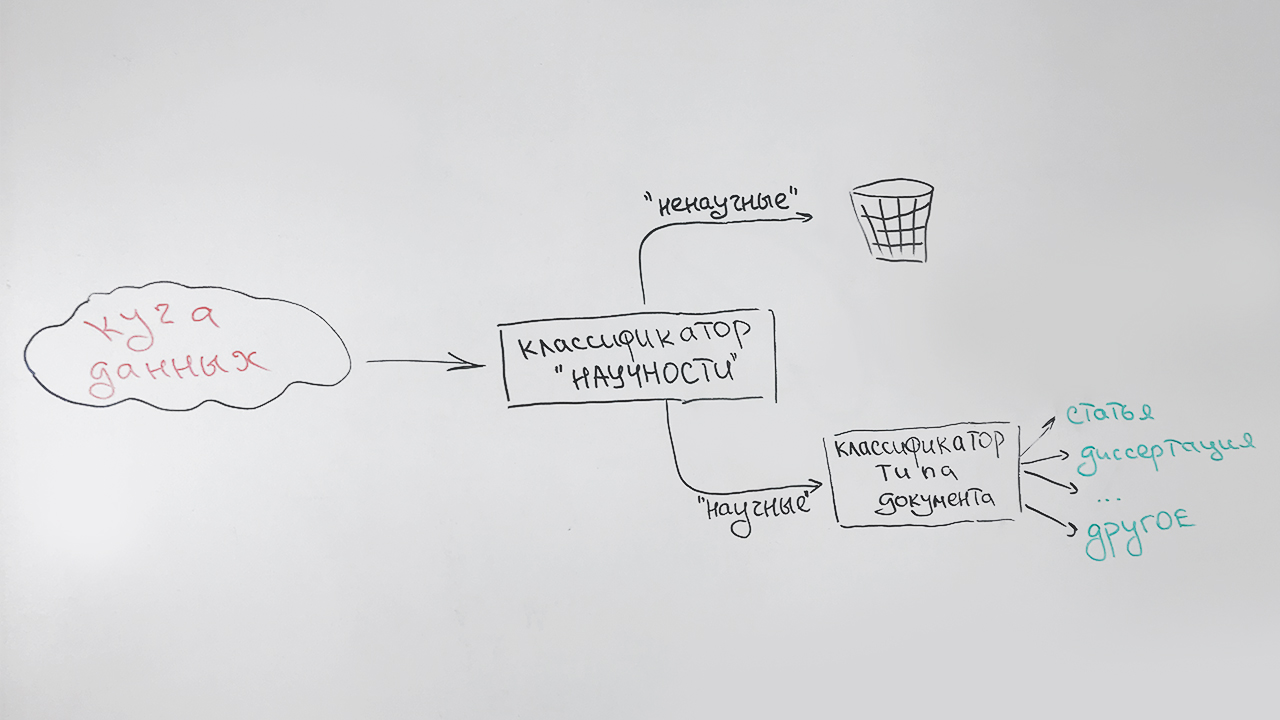
Um tipo especial (indefinido) é atribuído a documentos que não podem ser atribuídos com segurança a nenhum tipo (principalmente documentos curtos - páginas de sites científicos, resumos de resumos). Por exemplo, esta publicação será atribuída a esse tipo, que possui alguns sinais de cientificidade, mas não é semelhante a nenhum dos itens acima.
Há outra circunstância que deve ser levada em consideração. Essa é uma alta velocidade do algoritmo e baixos requisitos de recursos - no entanto, nossa tarefa é auxiliar. Portanto, usamos uma descrição indicativa muito pequena dos documentos:
- comprimento médio de uma frase em um texto;
- compartilhamento de palavras de parada em relação a todas as palavras do texto;
- índice de legibilidade ;
- porcentagem de sinais de pontuação em relação a todos os caracteres do texto;
- o número de palavras da lista ("resumo", "dissertação", "diploma", "certificação", "especialidade", "monografia" etc.) na parte inicial do texto (o atributo é responsável pela página de título);
- o número de palavras da lista (“lista”, “literatura”, “bibliográfico” etc.) na última parte do texto (o atributo é responsável pela lista de literatura);
- a proporção de letras no texto;
- comprimento médio das palavras;
- o número de palavras únicas no texto.
Todos esses sinais são bons, pois são rapidamente calculados. Como classificador, usamos o algoritmo de floresta aleatória (
floresta aleatória ), um método popular de classificação no aprendizado de máquina.
Com as avaliações de qualidade na ausência de uma amostra marcada por especialistas, é difícil, portanto, deixamos o classificador entrar na coleção de artigos da biblioteca eletrônica científica
Elibrary.ru . Assumimos que todos os artigos serão identificados como científicos.
Resultado 100%? Nada disso - apenas 70%. Talvez tenhamos criado um algoritmo ruim? Examinamos os artigos filtrados. Acontece que muitos textos não científicos são publicados em revistas científicas: editoriais, parabéns por aniversários, obituários, receitas e até horóscopos. A visualização seletiva de artigos que o classificador considerado científico não revela erros; portanto, reconhecemos o classificador como adequado.
Agora assumimos a segunda tarefa. Aqui você não pode prescindir de material de qualidade para treinamento. Pedimos aos avaliadores que preparem uma amostra. Recebemos um pouco mais de 3,5 mil documentos com a seguinte distribuição:
| Tipo de documento | O número de documentos na amostra |
|---|
| Artigos | 679 |
| Teses de doutorado | 250 |
| Resumos de teses de doutorado | 714 |
| Coleções de conferências científicas | 75 |
| Dissertações de doutorado | 159 |
| Resumos de dissertações de doutorado | 189 |
| Monografias | 107 |
| Guias de estudo | 403 |
| Teses | 664 |
| Tipo indefinido | 514 |
Para resolver o problema de classificação multiclasse, usamos a mesma floresta aleatória e os mesmos recursos para não calcular algo especial.
Temos a seguinte qualidade de classificação:
| Precisão | Completude | Medida F |
|---|
| 81% | 76% | 79% |
Os resultados da aplicação do algoritmo treinado aos dados indexados são visíveis nos diagramas abaixo. A Figura 1 mostra que mais da metade da coleção é composta por documentos científicos e, entre eles, mais da metade dos documentos são artigos.
 Fig. 1. Distribuição de documentos por “científico”
Fig. 1. Distribuição de documentos por “científico”A Figura 2 mostra a distribuição dos documentos científicos por tipo, com exceção do tipo "artigo". Percebe-se que o segundo tipo de documento científico mais popular é um livro didático e o tipo mais raro é uma dissertação de doutorado.
 Fig. 2. Distribuição de outros documentos científicos por tipo
Fig. 2. Distribuição de outros documentos científicos por tipoEm geral, os resultados estão alinhados com as expectativas. Do rápido classificador "áspero", não precisamos mais.
Definição do assunto do documento
Aconteceu que ainda não foi criado um classificador universal unificado e reconhecido de trabalhos científicos. Os mais populares atualmente são os títulos
VAK ,
GRNTI ,
UDC . Apenas no caso, decidimos categorizar documentos tematicamente em cada uma dessas categorias.
Para construir um classificador temático, usamos uma abordagem baseada na
modelagem de tópicos , uma maneira estatística de construir um modelo para uma coleção de documentos de texto, na qual para cada documento é determinada sua probabilidade de pertencer a determinados tópicos. Como ferramenta para a construção de um modelo temático, usamos a biblioteca aberta
BigARTM . Já usamos essa biblioteca e sabemos que ela é ótima para modelagem temática de grandes coleções de documentos de texto.
No entanto, há uma dificuldade. Na modelagem temática, determinar a composição e a estrutura dos tópicos é o resultado da solução de um problema de otimização em relação a uma coleção específica de documentos. Não podemos influenciá-los diretamente. Naturalmente, os temas resultantes do ajuste de nossa coleção não corresponderão a nenhum dos classificadores de destino.
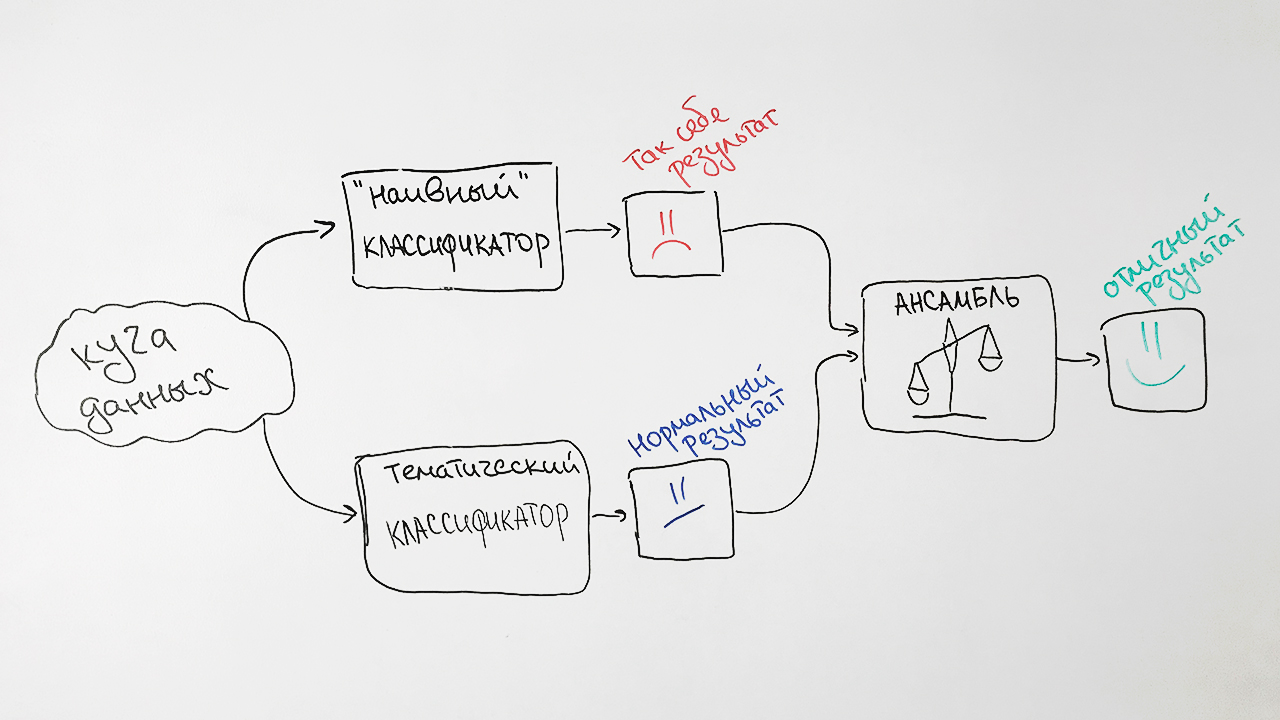
Portanto, para obter o valor desconhecido final do rubricador de um documento de solicitação específico, precisamos realizar mais uma conversão. Para fazer isso, no espaço de tópicos do BigARTM, usando o algoritmo do vizinho mais próximo (
k-NN ), procuramos vários documentos que são mais semelhantes à consulta com valores conhecidos de rubricador e, com base nisso, atribuímos a classe mais relevante ao documento de consulta.
De uma forma simplificada, o algoritmo é mostrado na figura:

Para treinar o modelo, usamos documentos de código aberto, bem como dados fornecidos pelo Elibrary.ru com especialidades conhecidas da Comissão de Atestado Superior, SRSTI, UDC. Removemos da coleção os documentos que estão vinculados a posições muito gerais dos rubricadores, por exemplo,
problemas gerais e complexos das ciências naturais e exatas , uma vez que esses documentos afetam bastante a classificação final.
A coleção final continha cerca de 280 mil documentos para treinamento e 6 mil documentos para teste para cada uma das rubricas.
Para nossos propósitos, basta prever os valores dos títulos do primeiro nível. Por exemplo, para um texto com um valor GRNTI de
27.27.24: Funções harmônicas e suas generalizações, a previsão da seção
27: Matemática está correta.
Para melhorar a qualidade do algoritmo desenvolvido, adicionamos algumas abordagens baseadas no bom e velho classificador
Naive Bayes . Como sinais, ele usa a frequência das palavras que são mais características para cada um dos documentos com um valor específico do cabeçalho HAC.
Por que é tão difícil? Como resultado, pegamos as previsões de ambos os algoritmos, ponderamos e produzimos uma previsão média para cada solicitação. Essa técnica no aprendizado de máquina é chamada de
montagem . Essa abordagem nos dá um aumento notável na qualidade. Por exemplo, para a especificação SRSTI, a precisão do algoritmo original era de 73%, a precisão do ingênuo classificador Bayes era de 65% e suas associações eram de 77%.
Como resultado, obtemos esse esquema do nosso classificador:
Observamos dois fatores que influenciam os resultados do classificador. Primeiro, qualquer documento pode receber mais de um valor de rubricador por vez. Por exemplo, os valores do cabeçalho da Comissão de Atestado Superior 25.00.24 e 08.00.14 (geografia
econômica ,
social e política e
economia mundial ). E isso não será um erro.
Em segundo lugar, na prática, os valores das rubricas são colocados habilmente, isto é, subjetivamente. Um exemplo impressionante é de tópicos aparentemente diferentes, como
Engenharia Mecânica e
Agricultura e Silvicultura . Nosso algoritmo classificou os artigos com o título
“Máquinas para desbaste da floresta” e
“Pré-requisitos para o desenvolvimento de uma série de tratores de tamanho padrão para as condições da zona noroeste” para engenharia mecânica e, de acordo com o layout original, eles se referiam precisamente à agricultura.
Portanto, decidimos exibir os três principais valores mais prováveis de cada uma das categorias. Por exemplo, para o artigo
“Tolerância de professores profissionais (no exemplo da atividade de um professor de russo de uma escola multiétnica)”, as probabilidades dos valores do cabeçalho da Comissão de Atestado Superior foram distribuídas da seguinte forma:
| Valor do rubricador | Probabilidade |
|---|
| Ciências pedagógicas | 47% |
| Ciências psicológicas | 33% |
| Ciência cultural | 20% |
A precisão dos algoritmos resultantes foi:
| Rubricator | Precisão dos 3 principais |
|---|
| SRSTI | 93% |
| VAK | 92% |
| UDC | 94% |
Os diagramas mostram os resultados de um estudo sobre a distribuição de tópicos de documentos no índice da Internet na língua russa para todos (Figura 3) e somente para documentos científicos (Figura 4). Percebe-se que a maioria dos documentos se refere às ciências humanas: as especificações mais frequentes são economia, direito e pedagogia. Além disso, entre apenas documentos científicos, sua participação é ainda maior.
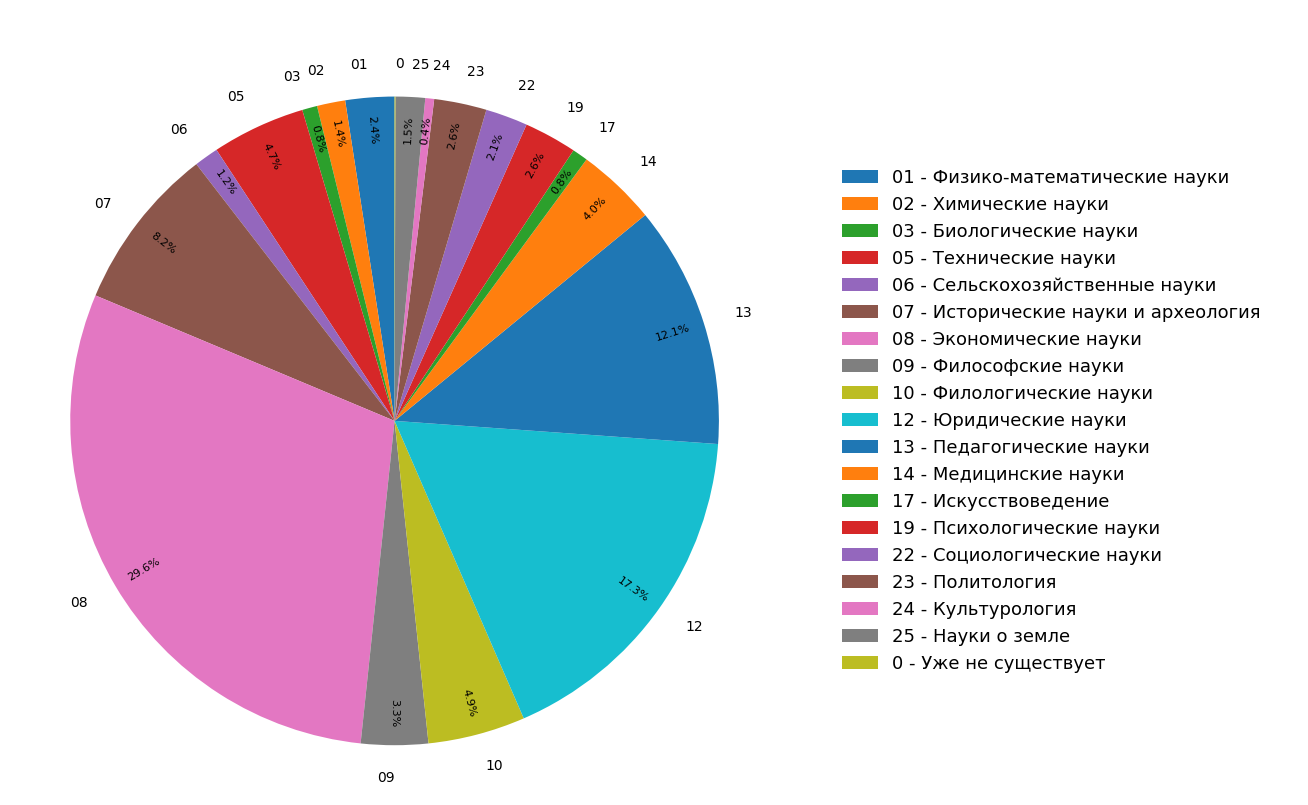 Fig. 3. Distribuição de tópicos por todo o módulo de pesquisa
Fig. 3. Distribuição de tópicos por todo o módulo de pesquisa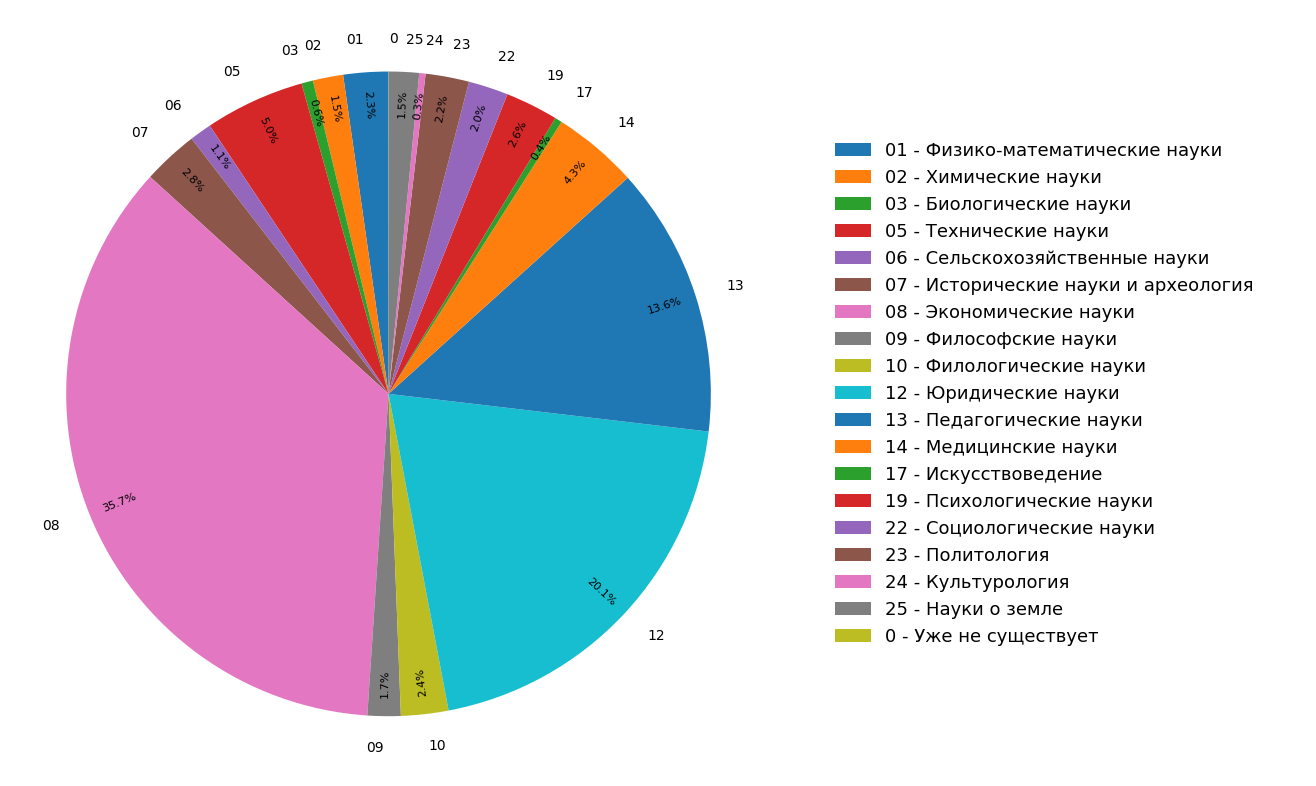 Fig. 4. A distribuição de tópicos de documentos científicos.
Fig. 4. A distribuição de tópicos de documentos científicos.Como resultado, literalmente, a partir dos materiais em questão, não apenas aprendemos a estrutura temática da Internet indexada, mas também criamos funcionalidades adicionais com as quais você pode “classificar” um artigo ou outro documento científico em três categorias temáticas ao mesmo tempo.

A funcionalidade descrita acima agora está sendo implementada ativamente no sistema antiplágio e em breve estará disponível para os usuários.